






作者 | 自动驾驶专栏 编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

论文链接:https://arxiv.org/pdf/2501.04005
项目主页:https://ldkong.com/LargeAD

摘要

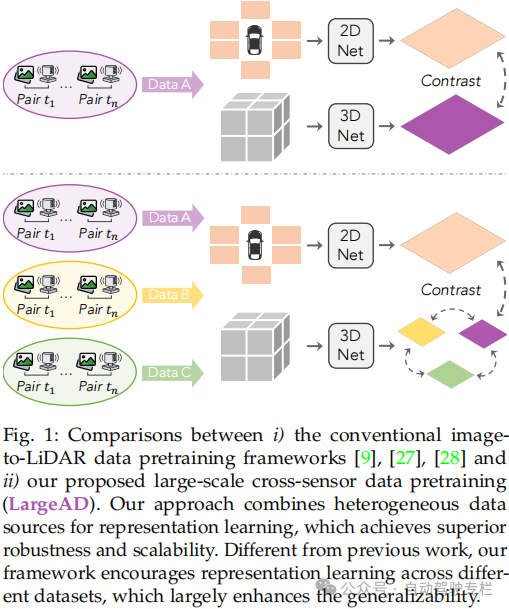
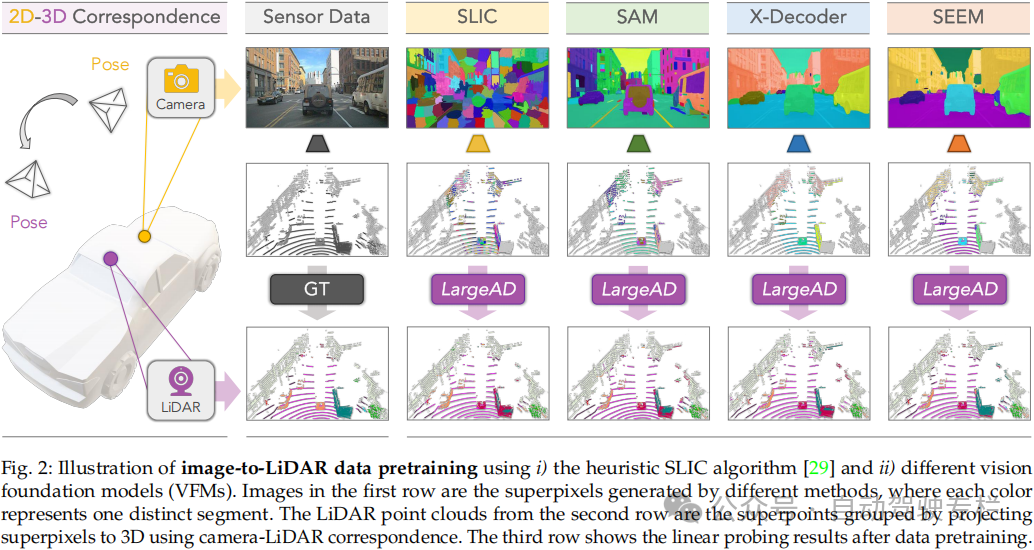
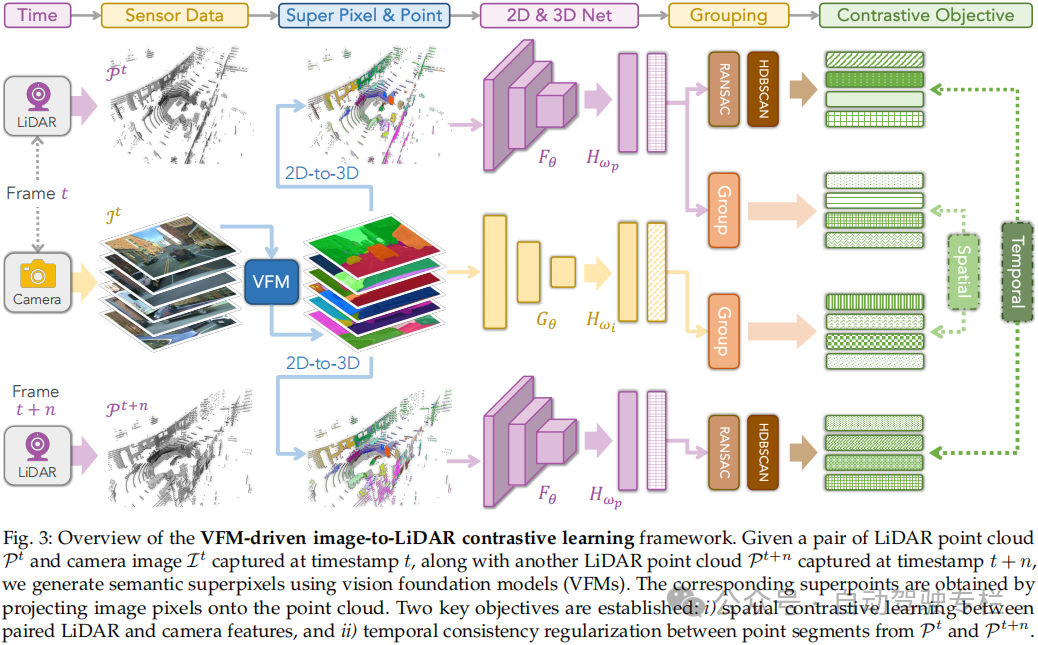
本文介绍了LargeAD:用于自动驾驶的大规模跨传感器数据预训练。视觉基础模型(VFMs)的最新进展彻底改变了2D视觉感知,但是它们在3D场景理解方面的潜力(特别是在自动驾驶应用中)仍然没有得到充分探索。本文引入了LargeAD,这是一种专门为跨不同现实世界驾驶数据集的大规模3D预训练而设计的多功能、可扩展框架。本文框架利用VFMs从2D图像中提取语义丰富的superpixels,它们与激光雷达点云对齐以生成高质量的对比样本。这种对齐有助于跨模态表示学习,增强2D和3D数据之间的语义一致性。本文引入了若干项关键创新:i)VFM驱动的superpixel生成,用于详细的语义表示;ii)VFM辅助的对比学习策略,用于对齐多模态特征;iii)superpoint时间一致性,以保持跨时间的稳定表示;iv)多源数据预训练,以在各种激光雷达配置上泛化。与最先进的方法相比,本文方法在基于激光雷达的分割和目标检测的线性探测和微调任务中均实现了显著的性能提升。在11个大规模多模态数据集上进行的大量实验突出了本文方法的卓越性能,证明了在现实世界自动驾驶场景中的适应性、效率和鲁棒性。

主要贡献

本文的贡献总结如下:
1)本文引入了LargeAD,这是一种可扩展、一致且可泛化的框架,专门为从车载传感器采集的数据进行大规模预训练而设计,解决了各种激光雷达配置所带来的挑战,并且提高了表示学习能力;
2)据作者所知,这是首项探索在多个大规模驾驶数据集上预训练的综合研究,利用跨数据集知识来提高模型对不同传感器设置和驾驶环境的泛化能力;
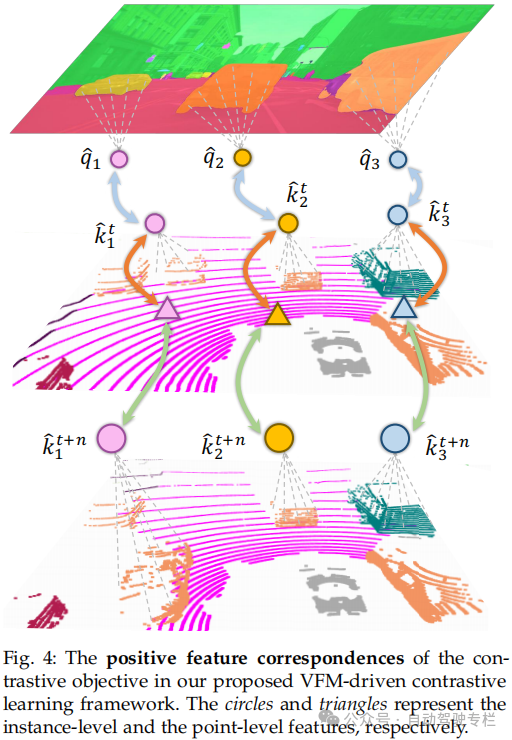
3)本文框架加入了若干项关键创新:i)基于VFM的superpixel生成,用于丰富语义表示;ii)VFM辅助的对比学习,以对齐2D-3D特征;iii)superpoint时间一致性,以稳定跨时间的点云表示;iv)多源数据预训练,以确保跨域鲁棒性;
4)与最先进的方法相比,本文方法具有显著性能优势。它在11个不同的点云数据集的线性探测和微调任务中均实现了更优的结果,展现了在现实世界应用中的适应性和效率。

论文图片和表格

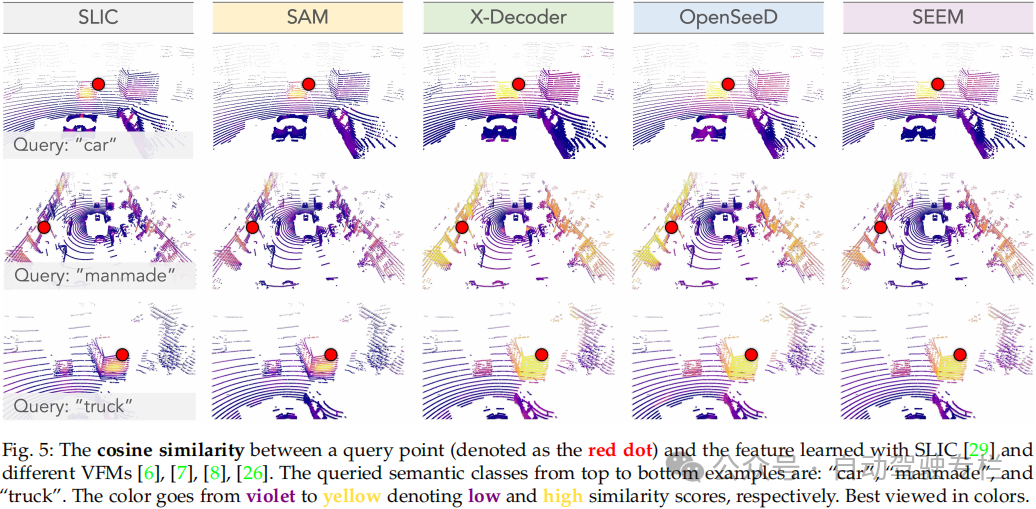
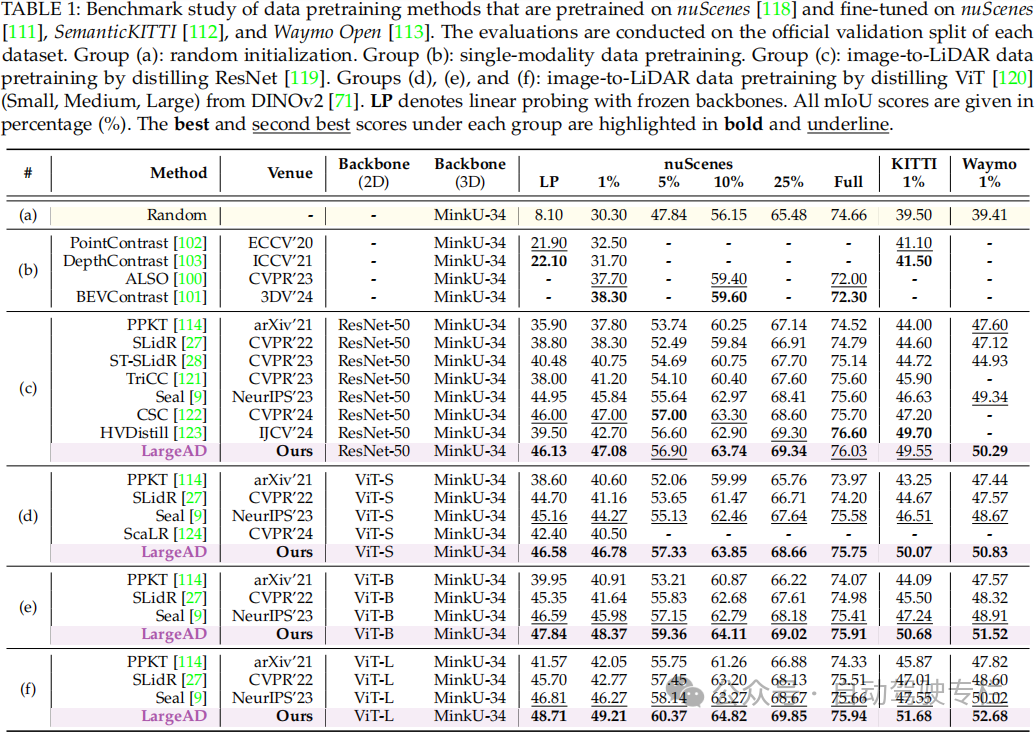
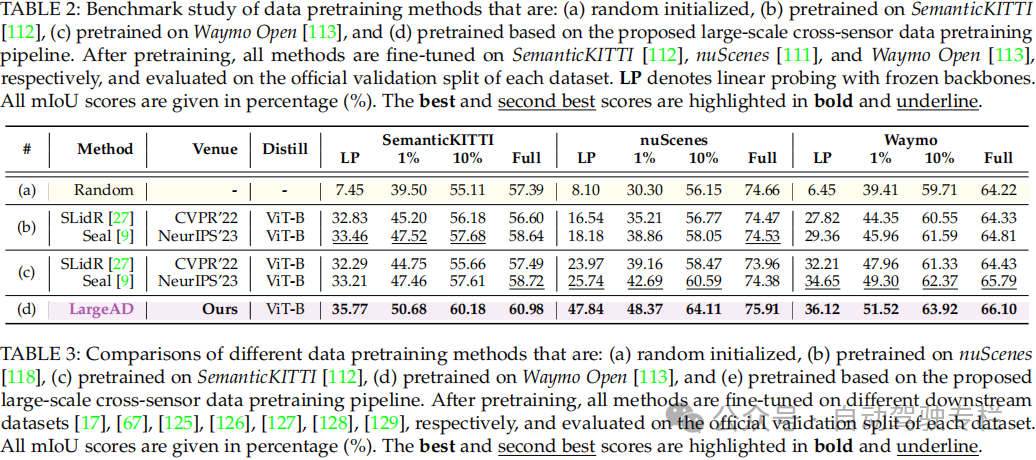
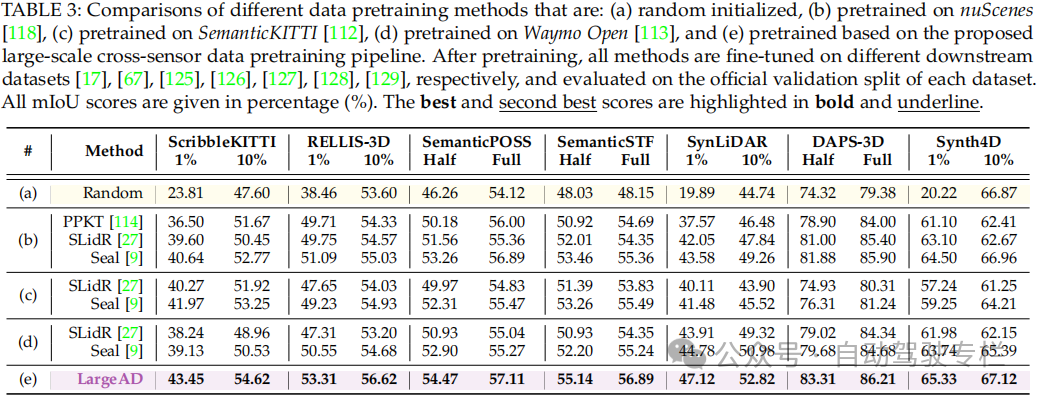
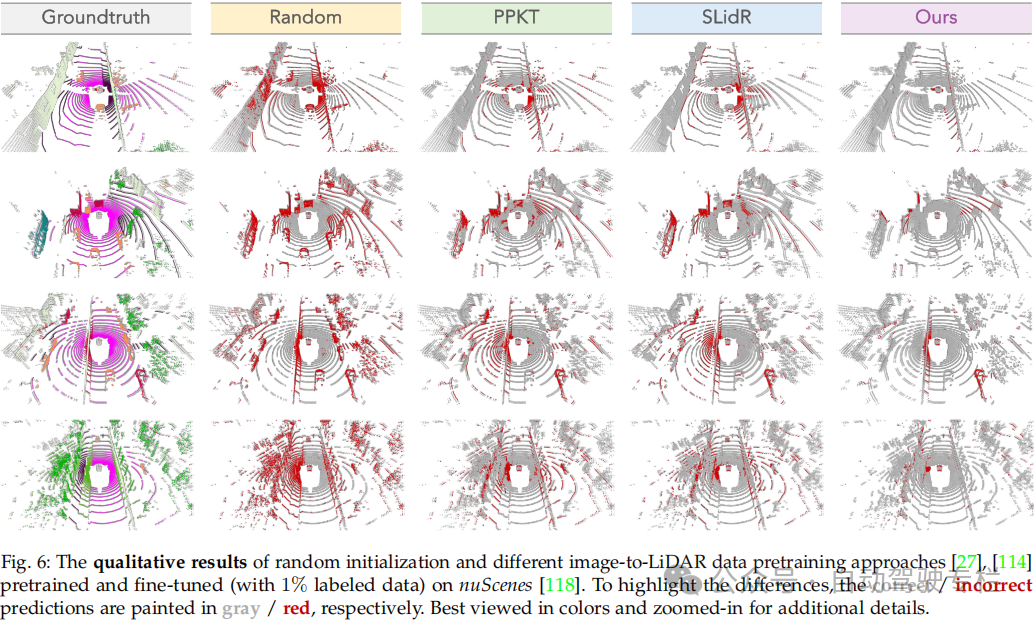
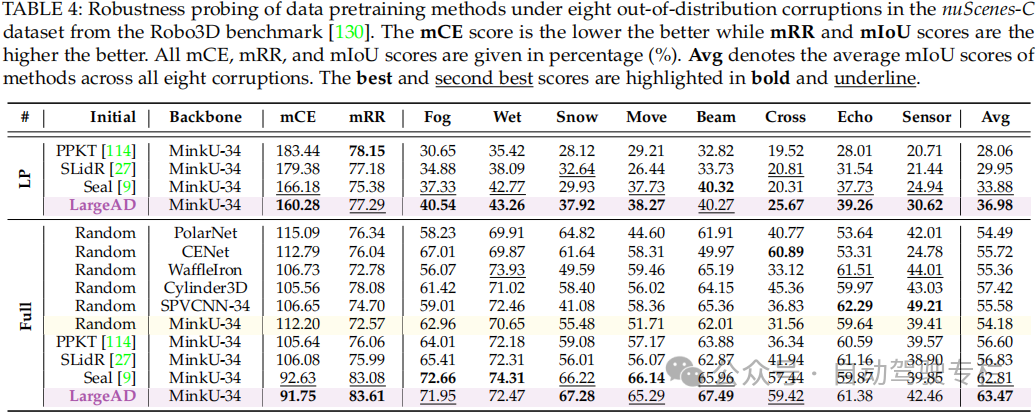
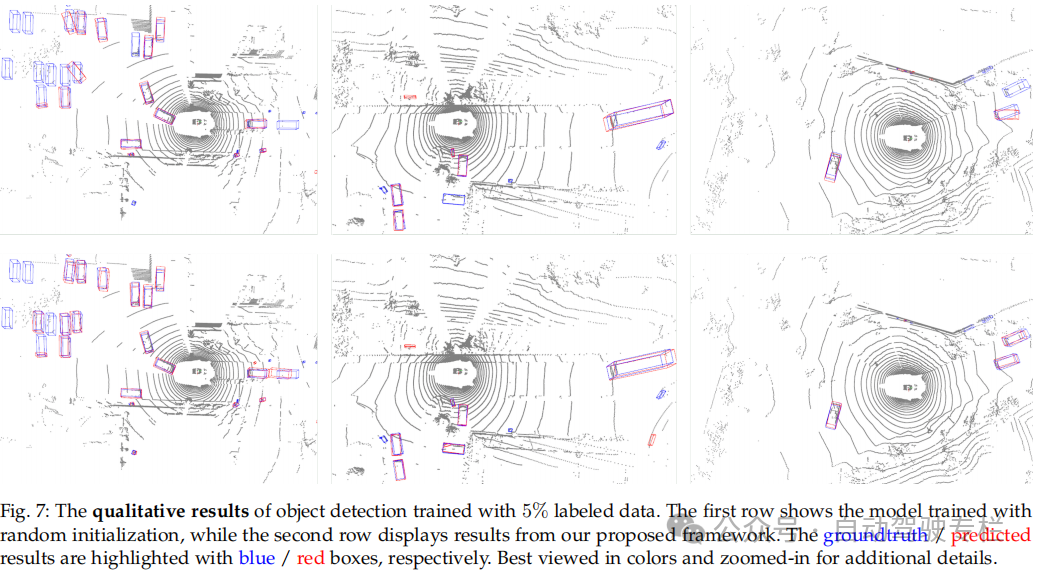
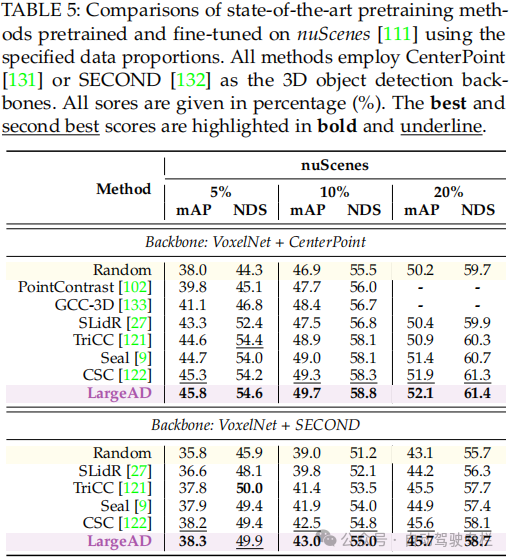
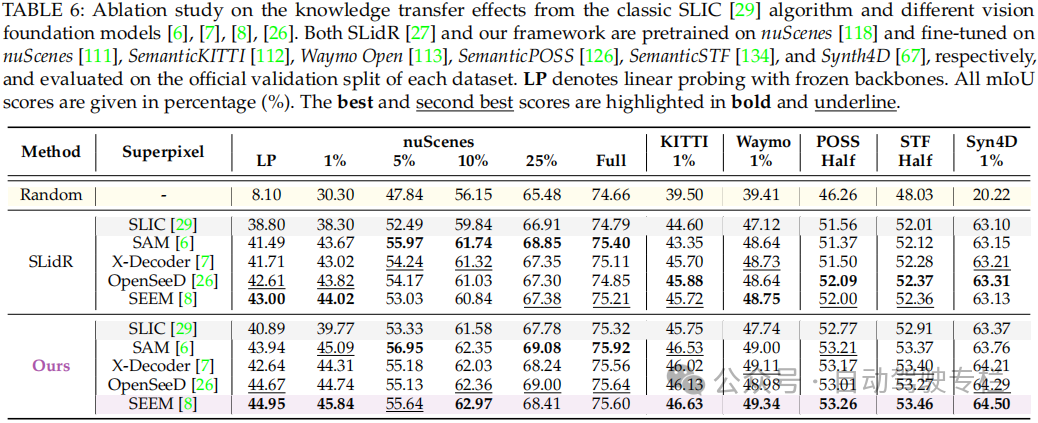
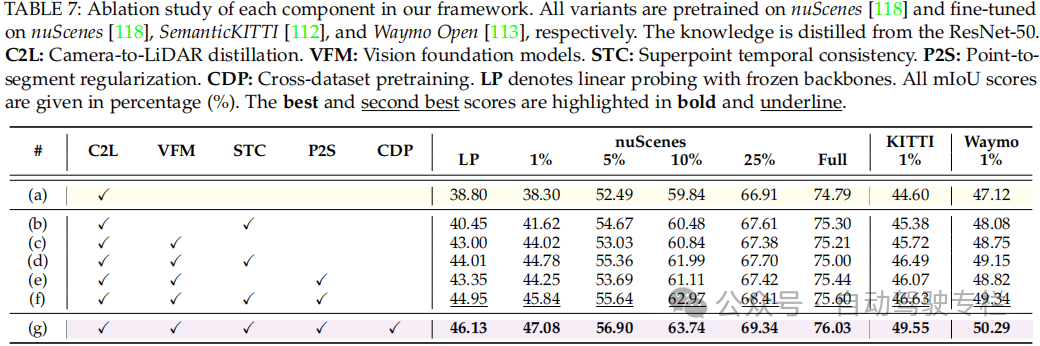
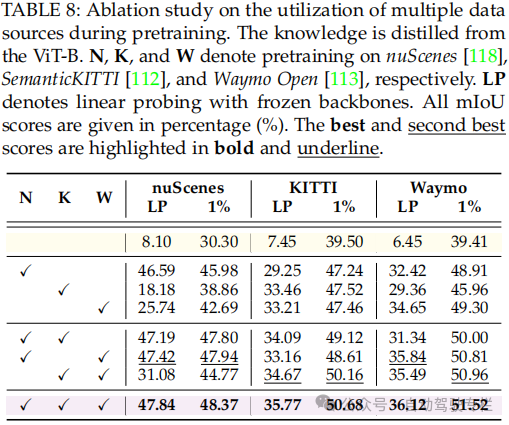

总结

本文引入了LargeAD,这是一种可扩展且可泛化的框架,专门为各种激光雷达数据集上的大规模预训练而设计。本文方法利用视觉基础模型(VFMs)来生成语义丰富的superpixels,将2D图像特征与激光雷达点云对齐以改进表示学习。通过结合VFM辅助的对比学习、superpoint时间一致性和多源数据预训练,本文框架在多项3D场景理解任务中实现了最先进的性能,包括基于激光雷达的语义分割和3D目标检测。在11个不同数据集上进行的大量实验突出了本文框架在域内和域外场景中的有效性。本文框架不仅在下游泛化方面表现出色,还在分布外条件下展现出更优的鲁棒性。消融研究进一步验证了本文设计选择的重要性,展现了在预训练阶段加入多个数据集的重要影响以及本文框架的每个单独组件的优势。研究结果突出了LargeAD推进现实世界自动驾驶应用的潜力,它提供了能够适应各种传感器配置和驾驶环境的更通用、更具适应性的模型。在未来工作中,本文旨在将该方法扩展,以加入额外的传感器模态(例如雷达和热成像),并且进一步扩大自动驾驶系统的跨模态预训练范围。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









