






📦点击查看-已发布目标检测数据集合集(持续更新)
| 数据集名称 | 图像数量 | 应用方向 | 博客链接 |
|---|---|---|---|
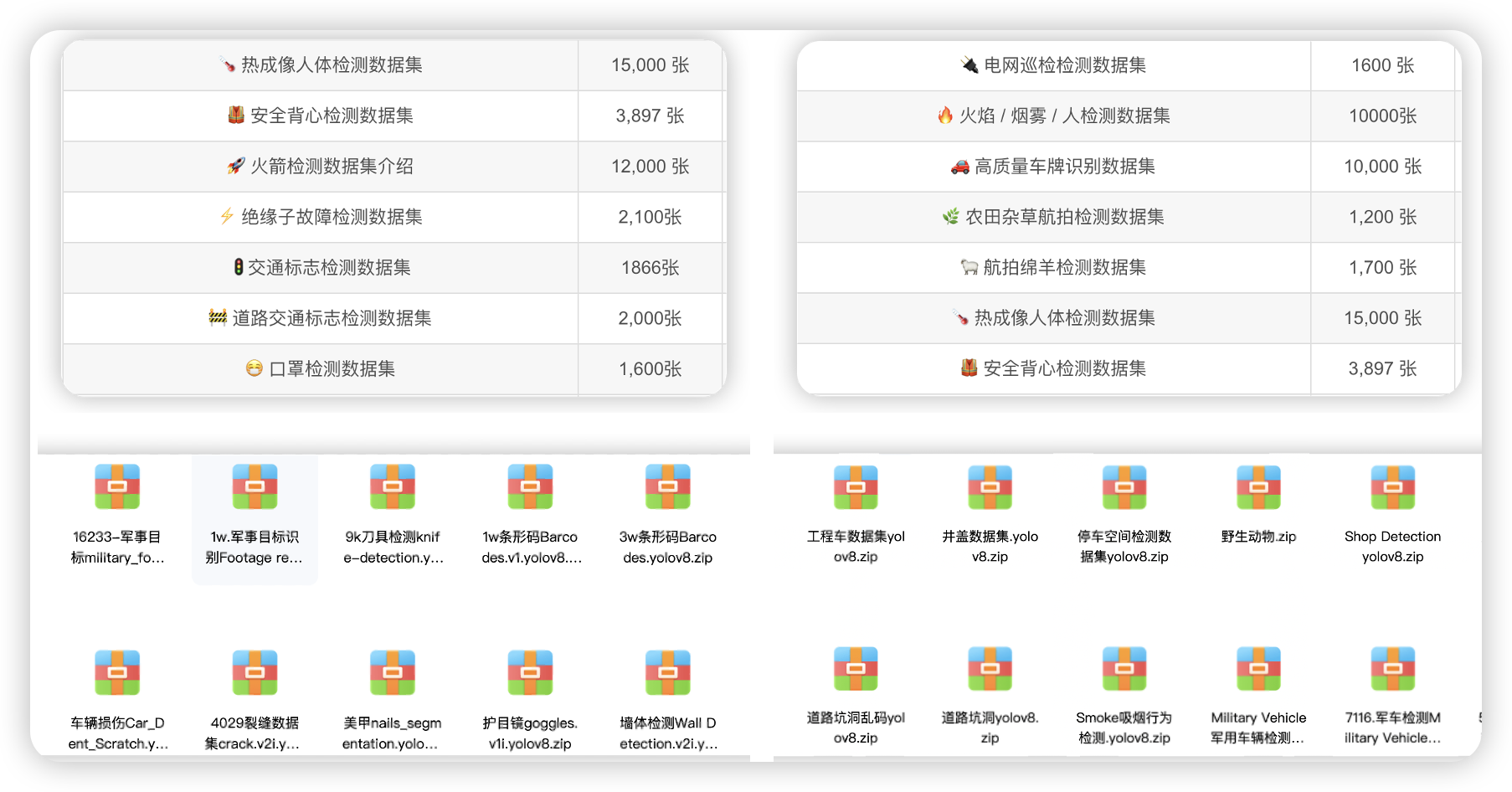
| 🔌 电网巡检检测数据集 | 1600 张 | 电力设备目标检测 | 点击查看 |
| 🔥 火焰 / 烟雾 / 人检测数据集 | 10000张 | 安防监控,多目标检测 | 点击查看 |
| 🚗 高质量车牌识别数据集 | 10,000 张 | 交通监控 / 车牌识别 | 点击查看 |
| 🌿 农田杂草航拍检测数据集 | 1,200 张 | 农业智能巡检 | 点击查看 |
| 🐑 航拍绵羊检测数据集 | 1,700 张 | 畜牧监控 / 航拍检测 | 点击查看 |
| 🌡️ 热成像人体检测数据集 | 15,000 张 | 热成像下的行人检测 | 点击查看 |
🔖 autism检测数据集介绍-3,039张图片-文章末添加wx领取数据集

🔖 autism检测数据集介绍
📌 数据集概览
本数据集为**自闭症(autism)**相关的计算机视觉分类任务数据集,涵盖不同年龄段儿童的面部图像,旨在辅助开发基于视觉识别的自动化辅助诊断和检测工具。该数据集共收录约 3,039 张图像,包含三类标注,适合用于图像分类模型的训练与评估。
- 图像数量:3,039 张
- 类别数:3 类
- 适用任务:图像分类(Image Classification)
- 适配模型:ResNet、EfficientNet、MobileNet、ViT 等主流深度学习架构
包含类别
| 类别 | 英文名称 | 描述 |
|---|---|---|
| 自闭症 | Autistic | 确诊或表现出自闭症特征的儿童 |
| 非自闭症 | Non_Autistic | 无自闭症表现的儿童 |
| 未标注 | Unlabeled | 尚未明确分类的儿童面部图像 |
该数据集覆盖不同性别与年龄段儿童的面部图像,具备较强的多样性与代表性,适合用于自动化检测自闭症相关视觉特征,提升辅助诊断的效率和准确性。
🎯 应用场景
-
医疗辅助诊断
结合计算机视觉技术,实现自闭症早期筛查,辅助医生进行快速判断,提高诊断效率。 -
心理健康监测
利用面部表情和细微特征变化监测儿童心理发展状况,提供持续的健康跟踪。 -
教育支持系统
为特殊教育提供数据支持,帮助设计个性化学习方案和互动评估工具。 -
临床研究分析
通过大数据分析不同人群面部特征,推动自闭症病因和表现形式的病理研究。 -
家庭护理辅助
开发便捷的家用智能监测设备,帮助家长及时发现儿童行为上的异常信号。 -
智能交互设备
结合自闭症特征识别,优化人机交互界面,使辅助设备更具响应性和适应性。
🖼 数据样本展示
以下展示部分数据集内的样本图片(均带有分类标签):


数据集包含以下特征:
- 丰富年龄跨度:涵盖婴幼儿到稍大儿童的多年龄层图像
- 多分类标签:清晰划分自闭症、非自闭症及未标注三类
- 高清面部图像:保证图像质量,便于提取细微特征
- 适合分类任务:数据结构明确,便于直接用于卷积神经网络训练
- 多样化样本来源:不同环境和光照条件下采集,提升模型泛化能力
该数据集以多样化的儿童面部图像为基础,有利于构建鲁棒性高的视觉识别模型,进而促进自闭症辅助诊断的自动化与智能化。
💡 使用建议
-
数据预处理优化
- 使用脸部关键点检测进行自动对齐和裁剪,提高特征聚焦精度
- 应用光照和颜色增强,提升模型对不同拍摄条件适应能力
- 采用数据均衡策略处理类别不平衡,防止过拟合偏向多数类
-
模型训练策略
- 结合迁移学习,利用预训练视觉模型提升特征提取效果
- 实施分层学习率调整,加快收敛同时稳定训练过程
- 引入正则化和早停机制,减少过拟合风险保障泛化能力
-
实际部署考虑
- 模型轻量化:针对边缘计算设备,压缩模型大小,满足实时识别需求
- 隐私保护:增强数据匿名化处理,确保个人隐私和法律合规
- 多模态融合:结合声音、行为等信息多源数据,提高诊断准确率
-
应用场景适配
- 临床环境专用:优化模型参数以适应医院或诊所内采集设备的图像特点
- 家庭使用场景:简化模型接口,支持智能手机或IoT设备应用
- 教育支持系统:构建易集成的API接口,便于学校辅助教学平台调用
-
性能监控与改进
- 建立持续反馈机制,根据实际应用数据不断细化模型训练集
- 定期进行准确率和召回率监控,确保系统稳定运行
- 结合专家审查结果,完善标签质量和纠错机制
🌟 数据集特色
- 类别多样:涵盖自闭症与非自闭症及未标注
- 数据量充足:含3,000+高质量面部图像
- 年龄跨度广:从婴幼儿到儿童多阶段覆盖
- 适配多模型:兼容主流深度学习架构
- 多样采集环境:多光照与场景条件下图像
📈 商业价值
- 医疗健康:推动智能辅助诊断系统商业化应用
- 特殊教育:支持个性化教学产品研发与普及
- 智能硬件:开发家用心理监测及健康管控设备
- 科研服务:为学术和企业提供数据标注与分析服务
🔗 技术标签
计算机视觉 图像分类 自闭症识别 深度学习 迁移学习 数据增强 面部识别 医疗辅助 模型优化 隐私保护 多模态分析 智能诊断
注意: 本数据集适用于研究、教育和商业用途。使用时请遵守医疗数据隐私法规,确保数据使用符合伦理要求。建议在实际应用中结合专业医学知识进行结果验证。
YOLOv8 训练实战
本教程介绍如何使用 YOLOv8 对目标进行识别与检测。涵盖环境配置、数据准备、训练模型、模型推理和部署等全过程。
📦 1. 环境配置
建议使用 Python 3.8+,并确保支持 CUDA 的 GPU 环境。
# 创建并激活虚拟环境(可选)
python -m venv yolov8_env
source yolov8_env/bin/activate # Windows 用户使用 yolov8_env\Scripts\activate
安装 YOLOv8 官方库 ultralytics
pip install ultralytics
📁 2. 数据准备
2.1 数据标注格式(YOLO)
每张图像对应一个 .txt 文件,每行代表一个目标,格式如下:
<class_id> <x_center> <y_center> <width> <height>
所有值为相对比例(0~1)。
类别编号从 0 开始。
2.2 文件结构示例
datasets/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
2.3 创建 data.yaml 配置文件
path: ./datasets
train: images/train
val: images/val
nc: 11
names: ['Bent_Insulator', 'Broken_Insulator_Cap', '', ...]
🚀 3. 模型训练
YOLOv8 提供多种模型:yolov8n, yolov8s, yolov8m, yolov8l, yolov8x。可根据设备性能选择。
yolo detect train \
model=yolov8s.pt \
data=./data.yaml \
imgsz=640 \
epochs=50 \
batch=16 \
project=weed_detection \
name=yolov8s_crop_weed
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model | 字符串 | - | 指定基础模型架构文件或预训练权重文件路径(.pt/.yaml) |
data | 字符串 | - | 数据集配置文件路径(YAML 格式),包含训练/验证路径和类别定义 |
imgsz | 整数 | 640 | 输入图像的尺寸(像素),推荐正方形尺寸(如 640x640) |
epochs | 整数 | 100 | 训练总轮次,50 表示整个数据集会被迭代 50 次 |
batch | 整数 | 16 | 每个批次的样本数量,值越大需要越多显存 |
project | 字符串 | - | 项目根目录名称,所有输出文件(权重/日志等)将保存在此目录下 |
name | 字符串 | - | 实验名称,用于在项目目录下创建子文件夹存放本次训练结果 |
关键参数补充说明:
-
model=yolov8s.pt- 使用预训练的 YOLOv8 small 版本(平衡速度与精度)
- 可用选项:
yolov8n.pt(nano)/yolov8m.pt(medium)/yolov8l.pt(large)
-
data=./data.yaml# 典型 data.yaml 结构示例 path: ../datasets/weeds train: images/train val: images/val names: 0: Bent_Insulator 1: Broken_Insulator_Cap 2: ... 3: ...
📈 4. 模型验证与测试
4.1 验证模型性能
yolo detect val \
model=runs/detect/yolov8s_crop_weed/weights/best.pt \
data=./data.yaml
| 参数 | 类型 | 必需 | 说明 |
|---|---|---|---|
model | 字符串 | 是 | 要验证的模型权重路径(通常为训练生成的 best.pt 或 last.pt) |
data | 字符串 | 是 | 与训练时相同的 YAML 配置文件路径,需包含验证集路径和类别定义 |
关键参数详解
-
model=runs/detect/yolov8s_crop_weed/weights/best.pt- 使用训练过程中在验证集表现最好的模型权重(
best.pt) - 替代选项:
last.pt(最终epoch的权重) - 路径结构说明:
runs/detect/ └── [训练任务名称]/ └── weights/ ├── best.pt # 验证指标最优的模型 └── last.pt # 最后一个epoch的模型
- 使用训练过程中在验证集表现最好的模型权重(
-
data=./data.yaml- 必须与训练时使用的配置文件一致
- 确保验证集路径正确:
val: images/val # 验证集图片路径 names: 0: crop 1: weed
常用可选参数
| 参数 | 示例值 | 作用 |
|---|---|---|
batch | 16 | 验证时的批次大小 |
imgsz | 640 | 输入图像尺寸(需与训练一致) |
conf | 0.25 | 置信度阈值(0-1) |
iou | 0.7 | NMS的IoU阈值 |
device | 0/cpu | 选择计算设备 |
save_json | True | 保存结果为JSON文件 |
典型输出指标
Class Images Instances P R mAP50 mAP50-95
all 100 752 0.891 0.867 0.904 0.672
crop 100 412 0.912 0.901 0.927 0.701
weed 100 340 0.870 0.833 0.881 0.643
4.2 推理测试图像
yolo detect predict \
model=runs/detect/yolov8s_crop_weed/weights/best.pt \
source=./datasets/images/val \
save=True
🧠 5. 自定义推理脚本(Python)
from ultralytics import YOLO
import cv2
# 加载模型
model = YOLO('runs/detect/yolov8s_crop_weed/weights/best.pt')
# 推理图像
results = model('test.jpg')
# 可视化并保存结果
results[0].show()
results[0].save(filename='result.jpg')
🛠 6. 部署建议
✅ 本地运行:通过 Python 脚本直接推理。
🌐 Web API:可用 Flask/FastAPI 搭建检测接口。
📦 边缘部署:YOLOv8 支持导出为 ONNX,便于在 Jetson、RKNN 等平台上部署。
导出示例:
yolo export model=best.pt format=onnx
📌 总结流程
| 阶段 | 内容 |
|---|---|
| ✅ 环境配置 | 安装 ultralytics, PyTorch 等依赖 |
| ✅ 数据准备 | 标注图片、组织数据集结构、配置 YAML |
| ✅ 模型训练 | 使用命令行开始训练 YOLOv8 模型 |
| ✅ 验证评估 | 检查模型准确率、mAP 等性能指标 |
| ✅ 推理测试 | 运行模型检测实际图像目标 |
| ✅ 高级部署 | 导出模型,部署到 Web 或边缘设备 |



















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









