







首先我使用的是
ubuntu 11.10
hadoop1.1.2
单机版的操作
1.安装ssh
sudo apt-get install ssh
2.安装rsync
sudo apt-get install rsync
3.配置ssh免登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
验证是否成功
ssh localhost
4.配置jdk环境和下载hadoop 1.1.2
5.修改hadoop配置文件,指定jdk安装路径
vi conf/hadoop-env.sh
export JAVA_HOME=/home/app/jdk1.6.0_30
添加
env|grep java
6.修改hadoop核心配置文件core-site.xml,配置hafs的地址和端口号
conf/core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property> 如果不配置的话每次重启电脑都需要格式化
<name>hadoop.tmp.dir</name>
<value>/home/wind/hadooptemp</value>
</property>
</configuration>
7.修改hadoop中,hdfs的replication配置
conf/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
8.修改hadoop中mapreduce的配置文件,配置jobtracker的地址和端口号
conf/mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
9.格式化hadoop的文件系统
bin/hadoop namenode -format
10.启动hadoop
bin/start-all.sh
最后打开浏览器来验证hadoop是否安装成功
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
hadoop集群的安装
1.准备2台服务器,分别为
机器名 IP地址 作用
main 192.168.1.102 NameNode,JobTracker,DataNode,TaskTracker
slave 192.168.1.107 DataNode,TaskTracker
注:两台机器必须使用相同的用户名运行hadoop
2.分别在这两个主机上,按照单机版的安装方法,安装hadoop
3.在/etc/hostname中修改主机名
在/etc/hosts中配置主机名和ip对应关系
192.168.1.102 main
192.168.1.107 slave
4.在main节点中的 ~/.ssh/id_dsa.pub文件拷贝到slave的~/.ssh目录下,然后在slave
的~/.ssh/目录下运行
cat ./id_dsa.pub >> authorized_keys
5.分别修改2台主机中的hadoop配置文件marsters和slaves
masters
main
slaves
main
slave
摘录:
grep required *.sh
grep required *.sh|wc
上面是单机和集群到配置,说到比较简单,使用hadoop1.1.2进行集群到配置参考了两篇文章,然后才配置成功了两台机器的hadoop学习集群
参考链接
http://blog.csdn.net/sourcefour/article/details/8889415
http://os.51cto.com/art/201211/363116.htm
非常感谢:在参考了上面两篇文章后发现各有长处总结步骤如下:
一. 搭建环境前的准备:
我的本机Ubuntu 12.04 32bit作为maser,就是上篇hadoop单机版环境搭建时用的那台机子,
还在KVM中虚拟了4台机子,分别起名为:
son-1 (ubuntu 12.04 32bit),
son-2 (ubuntu 12.04 32bit),
son-3 (centOS 6.2 32bit),
son-4 (redhat 6.0 32bit).
kvm的搭建详见:http://www.db89.org/post/2012-05-25/kvmxuniji
kvm的桥接设置详见:http://www.db89.org/post/2012-05-27/kvmnetset
Ubuntu12.04搭建hadoop单机版环境详见:http://www.db89.org/post/2012-06-03/hadoopdanjihuanjing
下来修改本机的host文件,
| sudo gedit /etc/hosts |
在后面添加内容为:
| 192.168.200.150 master 192.168.200.151 son-1 192.168.200.152 son-2 192.168.200.153 son-3 192.168.200.154 son-4 |
现在开始我们的打建之旅吧。
二 . 为本机(master)和子节点(son..)分别创建hadoop用户和用户组,其实ubuntu和centos下创建用户还多少还是有点区别的。
ubuntu下创建:
先创建hadoop用户组:
| sudo addgroup hadoop |
然后创建hadoop用户:
| sudo adduser -ingroup hadoop hadoop |
centos 和 redhat 下创建:
| sudo adduser hadoop |
注:在centos 和 redhat下直接创建用户就行,会自动生成相关的用户组和相关文件,而ubuntu下直接创建用户,创建的用户没有家目录。
给hadoop用户添加权限,打开/etc/sudoers文件;
| sudo gedit /etc/sudoers |
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
| hadoop ALL=(ALL:ALL) ALL |
三. 为本机(master)和子节点(son..)安装JDK环境。
ubuntu下一条命令即可:
| sudo apt-get install openjdk-6-jre |
centos和redhat建议下载源码安装。
详见:http://www.db89.org/post/2012-07-02/centosjava
四. 修改 本机(master)和子节点(son..)机器名
打开/etc/hostname文件;
| sudo gedit /etc/hostname |
分别修改为:master son-1 son-2 son-3 son-4。这样有利于管理和记忆!
五. 本机(master)和子节点(son..)安装ssh服务
主要为ubuntu安装,cents和redhat系统自带。
ubuntu下:
| sudo apt-get install ssh openssh-server |
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
六. 先为建立ssh无密码登录环境
做这一步之前首先建议所有的机子全部转换为hadoop用户,以防出现权限问题的干扰。
切换的命令为:
| su - hadoop |
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1. 创建ssh-key,,这里我们采用rsa方式;
| ssh-keygen -t rsa -P "" |
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的;
| cd ~/.ssh cat id_rsa.pub >> authorized_keys |
七. 为本机mater安装hadoop
我们采用的hadoop版本是:hadoop-0.20.203(http://www.apache.org/dyn/closer.cgi/hadoop/common/ ),因为该版本比较稳定。
1. 假设hadoop-0.20.203.tar.gz在桌面,将它复制到安装目录 /usr/local/下;
| sudo cp hadoop-0.20.203.0rc1.tar.gz /usr/local/ |
2. 解压hadoop-0.20.203.tar.gz;
| cd /usr/local sudo tar -zxf hadoop-0.20.203.0rc1.tar.gz |
3. 将解压出的文件夹改名为hadoop;
| sudo mv hadoop-0.20.203.0 hadoop |
4. 将该hadoop文件夹的属主用户设为hadoop,
| sudo chown -R hadoop:hadoop hadoop |
5. 打开hadoop/conf/hadoop-env.sh文件;
| sudo gedit hadoop/conf/hadoop-env.sh |
6. 配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径);
| export JAVA_HOME=/usr/lib/jvm/java-6-openjdk |
7. 打开conf/core-site.xml文件;
| sudo gedit hadoop/conf/core-site.xml |
编辑如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://master:9000</value>
- </property>
- </configuration>
8. 打开conf/mapred-site.xml文件;
| sudo gedit hadoop/conf/mapred-site.xml |
编辑如下:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>master:9001</value>
- </property>
- </configuration>
9. 打开conf/hdfs-site.xml文件;
| sudo gedit hadoop/conf/hdfs-site.xml |
编辑如下:
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- </configuration>
10. 打开conf/masters文件,添加作为secondarynamenode的主机名,这里需填写 master 就Ok了。
| sudo gedit hadoop/conf/masters |
11. 打开conf/slaves文件,添加作为slave的主机名,一行一个。
| sudo gedit hadoop/conf/slaves |
这里填成下列的内容 :
- son-1
- son-2
- son-3
- son-4
八. 要将master机器上的文件一一复制到datanode机器上(son-1,son-2,son-3,son-4都要复制):(这里以son-1为例子)
1. 公钥的复制
| scp ~/.ssh/id_rsa.pub hadoop@son-1:~/.ssh/ |
2. hosts文件的复制
| scp /etc/hosts hadoop@son-1:/etc/hosts |
注:这里如果不能复制,就先将文件复制到/home/hadoop下面,即为:
| /home/hadoophadoop@son-1: scp /etc/hosts |
再在datanode机器上将其移到相同的路径下面/etc/hosts .
3. hadoop文件夹的复制,其中的配置也就一起复制过来了!
| scp -r /usr/local/hadoop hadoop@son-1:/usr/local |
如果不能移动的话和上面的方法一样!
并且要将所有节点的hadoop的目录的权限进行如下的修改:
| sudo chown -R hadoop:hadoop hadoop |
这些东西都复制完了之后,datanode机器还要将复制过来的公钥追加到收信任列表:
在每个子节点的自己种都要操作。
| cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
还有很重要的一点,子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
还有要修改centos节点(son-3)和redhat节点(son-4)的java的环境变量地址,
配置centos节点(son-3)和redhat节点(son-4)的/usr/local/hadoop/conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径);这个环境不一,自己配置一下。
这样环境已经基本搭建好了,现在开始测试一下。
这个配置步骤不能在hadoop1.1.2下面使用,主要是配置的文件不对,我摘录另一篇文章到配置添加到这里。
-
配置集群关键文件
我们要配置的集群关键文件有六个:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、masters、slaves
hadoop-env.sh:
修改第9行,注意:一定要修改为你的JAVA_HOME
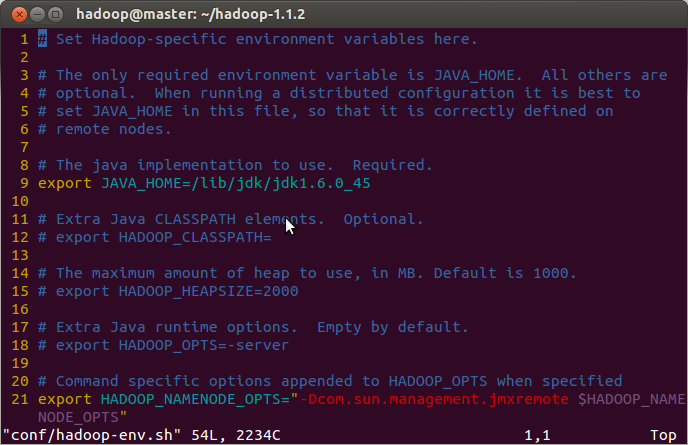
core-site.xml:
<?xml version="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!--Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/hadoop-${user.name}</value>
<description>A base for other temporarydirectories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>
hdfs-site.xml:
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!--Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication.
The actual number of replications can be specified when the file iscreated.
The default is used if replication is not specified in create time.
</description>
</property>
</configuration>
mapred-site.xml:
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!--Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
<description>The host and port that the MapReduce job trackerruns
at. If "local", then jobs are run in-process as a singlemap
and reduce task.
</description>
</property>
</configuration>
masters:
backup
slaves:
hadoop1
hadoop2
启动集群
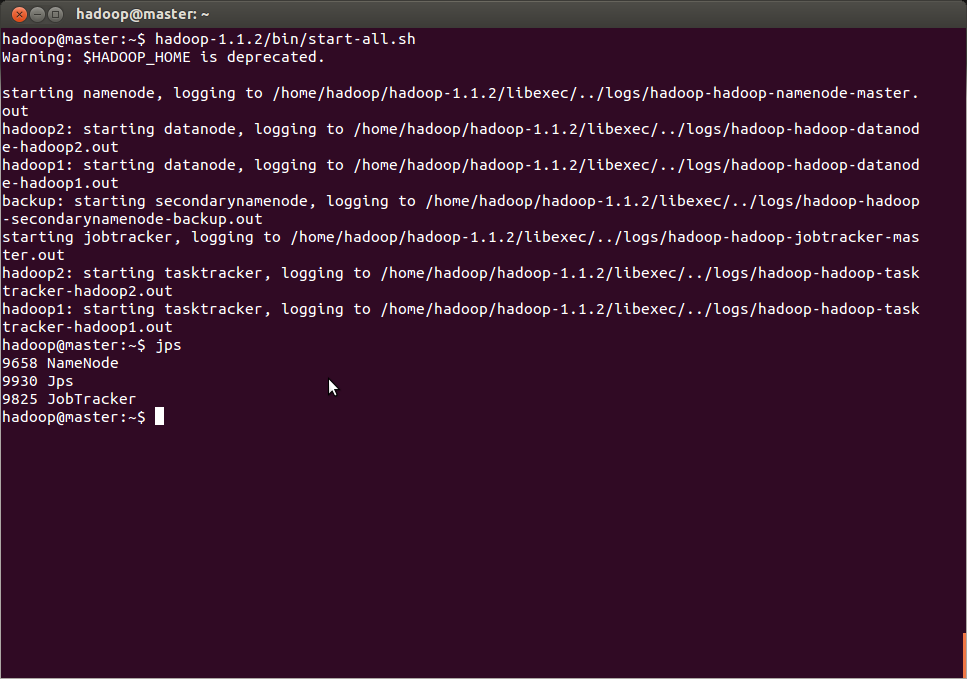
启动集群

这里可以通过ssh,在主机端来看各个分支是否正确。ssh slave
总体上就是这样:
1.在一个主要到机器上配置环境,并进行hosts的配置,hadoop的配置。
2.使用scp命令将相同到东西拷贝到各个子节点上。
3.进行测试。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









