






一.逻辑回归优化
1.1 环境准备
在开始之前,请确保你的Python环境中安装了以下库:
numpy:用于数据处理。sklearn:提供机器学习算法和工具。
如果未安装,可以通过以下命令安装:
pip install numpy scikit-learn
1.2 代码实现
下面是一个完整的代码示例,从数据准备到模型训练,再到模型优化和评估。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV, KFold
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import numpy as np
# 示例数据
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1], [2, 2], [3, 3], [4, 4], [5, 5]]) # 特征
y = np.array([0, 1, 1, 0, 1, 1, 0, 0]) # 目标值
# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.25, random_state=42)
# 创建模型
model = LogisticRegression(max_iter=300) # 增加max_iter以确保模型可以收敛
# 参数调优
param_grid = {
'C': [0.1, 1, 10],
'solver': ['liblinear', 'lbfgs'],
'max_iter': [300] # 统一设置max_iter以避免不收敛的问题
}
grid_search = GridSearchCV(model, param_grid, cv=KFold(2), scoring='accuracy')
grid_search.fit(X_train, y_train)
# 最佳参数和模型
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
# 训练最佳模型
best_model.fit(X_train, y_train)
# 预测
X_new = np.array([[0, 0], [1, 1], [2, 2], [3, 3]]) # 新增预测数据
y_pred = best_model.predict(X_new)
# 模型评估
y_train_pred = best_model.predict(X_train)
y_test_pred = best_model.predict(X_test)
train_accuracy = accuracy_score(y_train, y_train_pred)
test_accuracy = accuracy_score(y_test, y_test_pred)
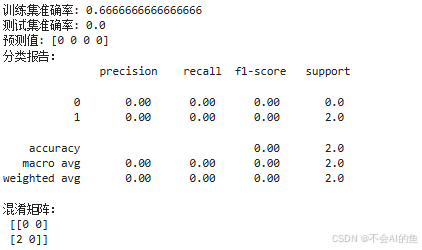
print(f"训练集准确率: {train_accuracy}")
print(f"测试集准确率: {test_accuracy}")
print(f"预测值: {y_pred}")
# 打印分类报告和混淆矩阵
print("分类报告:\n", classification_report(y_test, y_test_pred, zero_division=0))
print("混淆矩阵:\n", confusion_matrix(y_test, y_test_pred))
1.3 代码解释
- 导入库:我们导入了逻辑回归模型、数据预处理工具、模型选择工具和评估指标。
- 准备数据:我们创建了一个简单的二分类数据集,包括特征和目标值。
- 数据预处理:使用
StandardScaler对特征进行标准化处理。 - 划分数据集:将数据集划分为训练集和测试集。
- 创建模型:创建一个逻辑回归模型,并设置最大迭代次数以确保模型可以收敛。
- 参数调优:使用
GridSearchCV进行参数调优,寻找最佳的模型参数。 - 训练最佳模型:使用找到的最佳参数训练模型。
- 预测:对新数据进行预测。
- 模型评估:计算训练集和测试集的准确率,并打印分类报告和混淆矩阵。
二.逻辑回归模型的可视化分析
在机器学习的领域中,逻辑回归是一种基础且强大的分类算法,尤其适用于二分类问题。本文将通过一个完整的Python代码示例,展示如何使用逻辑回归对数据进行分类,并可视化其决策边界,帮助我们直观理解模型的分类效果。
1.1 环境搭建
在开始之前,请确保你的Python环境中已安装以下库:
numpy:用于数据处理。matplotlib:用于数据可视化。sklearn:提供机器学习算法和工具。
如果未安装,可以通过以下命令安装:
pip install numpy matplotlib scikit-learn
1.2 代码实现
以下是使用逻辑回归模型对随机生成的数据集进行分类并可视化决策边界的完整代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 设置随机种子以确保结果可复现
np.random.seed(0)
# 生成随机数据集
X = np.random.rand(100, 2) # 100个样本,每个样本2个特征
y = (X[:, 0] + X[:, 1] < 1).astype(int) # 根据特征和是否小于1生成标签
# 创建逻辑回归模型并训练
model = LogisticRegression()
model.fit(X, y)
# 绘制数据点
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='bwr', edgecolor='k', s=20)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 创建网格来评估模型
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = model.predict(xy).reshape(XX.shape)
# 绘制决策边界
plt.contour(XX, YY, Z, colors='k', levels=[0.5], linestyles=['-'], linewidths=2)
# 显示图形
plt.show()
2.3 代码解释
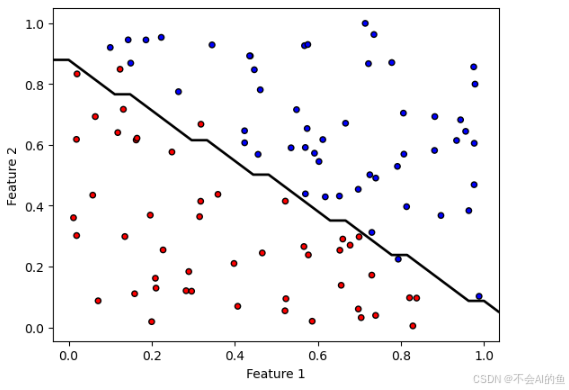
在这段代码中,我们首先导入了必要的库,并设置了随机种子以确保结果的可复现性。接着,我们生成了一个包含100个样本的随机数据集,每个样本有两个特征。标签y是根据这两个特征的和是否小于1来确定的,这为我们提供了一个简单的二分类问题。
我们创建了一个逻辑回归模型,并使用训练数据对其进行了训练。随后,我们使用matplotlib库绘制了数据点,其中不同的颜色代表不同的类别。为了更直观地展示模型的分类效果,我们绘制了决策边界。这个边界是通过创建一个网格并使用模型对网格中的每个点进行预测来实现的,最终我们得到了一条将两个类别分开的线。
三.结论
通过这篇文章,我们不仅学习了如何使用逻辑回归模型对数据进行分类,还掌握了如何通过可视化手段直观地展示模型的分类效果。这种可视化技术对于理解模型的工作原理和评估模型性能非常有帮助。希望这篇文章能够帮助你在机器学习的道路上更进一步,为你的技术探索之旅提供助力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









