







 本文记录了一次线上服务出现大量异常FGC的情况,通过分析JVM参数、GC日志、线程堆栈和数据库连接等,最终发现因未校验空字符串导致大查询占用大量内存。问题解决方法包括完善参数校验和优化DAO工具。
本文记录了一次线上服务出现大量异常FGC的情况,通过分析JVM参数、GC日志、线程堆栈和数据库连接等,最终发现因未校验空字符串导致大查询占用大量内存。问题解决方法包括完善参数校验和优化DAO工具。
前段时间线上的zzuser的服务模块出现大量的异常FGC情况,经过大量排查工作,最后锁定是因为一个sql的大查询导致的。这也给了我非常大的教训,同时我在这次问题的排查过程中也获益匪浅,所以把经过写下来或许能给其他处理JVM问题的同学一些启示或者借鉴,本文假设你对JVM有一定的了解,如果不了解,可以看另外一篇文章
问题现象及分析
JVM核心参数配置如下:
-Xms6g -Xmx6g -Xmn3g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0 -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:CMSInitiatingOccupancyFraction=80异常GC日志如下:

线程堆栈信息:
因为FGC后又自动恢复正常,所以jstack并不能打印出当时的真实情况,后面我写了一个脚本在FGC后马上打印线程堆栈信息,基本可以保留线程信息
大家可以看到我们的S区大小基本为空,因为我们的应用服务器都是是无状态的,所以理论上,每次YGC都能将对象回收,所以不需要在S区做任何停留,这在低并发时基本没有问题,但是高并发时就会出现YGC无法回收线程对象的情况,这时候S区为空,对象只能存储在Old区,导致高并发时old区突然暴涨的情况,从而产生大量FGC,但是这种配置即使发生了流量暴涨,也只是正常的YGC和FGC,不会突然在上位到达CMSInitiatingOccupancyFraction=80及Old区到百分之80使用率才进行FGC
可能原因分析
- 对象突然出现在old区,可能是因为有数量可观的大对象被创建,这些对象直接进入old区,导致old区突然增加,这种对象一般是流数据
- 可能是流量暴涨,创建突然对象增多,YGC无法回收,只能分配在old,虽然上文分析过流量暴涨引发的情况和需要解决的现象不同,但是开始是不清楚的
- CPU、内存等资源被其他进程占用,JVM没有足够的资源用以GC,我们的GC配置的是需要20个线程进行回收操作,还是比较耗费资源的。
- 在查找问题的过程中,有文章提到swap分区可能导致问题的产生
- 数据库连接异常,可能导致线程上的对象无法及时释放
分析了可能出现问题的原因,能重现问题,就是离解决问题不远了了,所以现在最重要的是能参考原因,重现异常
手动重现异常
大对象问题
因为我对zzuser业务模块不熟悉,所以请教了其他同学,zzuser模块并不存在流数据等大对象,所以第一个先搁置,实在找不到问题了再说(结果证明确实没有)
流量暴涨
要模拟流量暴涨还是比较容易的,前期我先使用TestNG调用几个方法进行压测,将压力突然调高,方法比较粗糙,后来让运维的同学给我们开了流量,使用tcpcopy将线上的流量引入到测试服务上,这种方式就非常准确科学了。
下图是流量突然增大时的GC情况
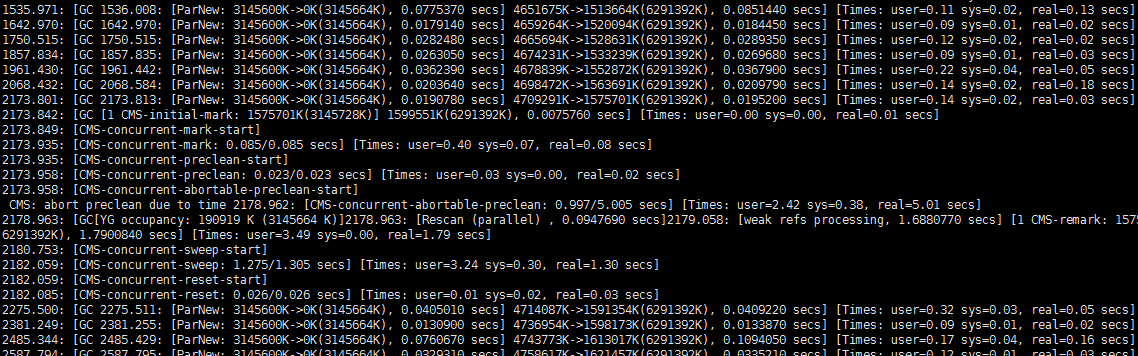
大家可以看到我们的S区大小基本为空,因为我们的应用服务器都是是无状态的,所以理论上,每次YGC都能将对象回收,所以不需要在S区做任何停留,这在低并发时基本没有问题,但是高并发时就会出现YGC无法回收线程对象的情况,这时候S区为空,对象只能存储在Old区,导致高并发时old区突然暴涨的情况,从而产生大量FGC,但是这种配置即使发生了流量暴涨,也只是正常的YGC和FGC,不会突然在上位到达CMSInitiatingOccupancyFraction=80及Old区到百分之80使用率才进行FGC
可以和异常日志红色部分对比,在异常FGC发生之前,会出现一次耗时非常长的YGC,对比之前正常YGC,这次YGC后old区发生了突然增长,然后触发了FGC。显然流量暴涨并不能导致异常FGC,这条路也走不通了。
CPU资源被其他进程占用
这里用到一个脚本,用来将cpu资源消耗光
#! /bin/bash
# filename killcpu.sh
endless_loop()
{
echo -ne "i=0;
while true
do
i=i+100;
i=100
done" | /bin/bash &
}
if [ $# !=  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









