







花了差不多一个星期,终于把《机器学习实战》这本书的第三章的决策树过了一遍,对于一个python渣渣来说,确实是着实不容易,好多代码都得一个一个的去查,所以整体上进度比较慢,再加上中间开了一篇关于自然语言处理和产品知识库构建的文章,导致进度及其之慢,但是总体上对代码的理解足够深刻,知道了整体决策树中ID3的一个具体编法和流程,但是得有一定决策树得基础,有兴趣得可以去看看南京大学周志华的《机器学习》和李航的《统计学习方法》,废话不多说,看文章。
【一】计算数据信息熵
这段代码主要是用于计算数据的每个特征信息熵,信息熵用于描述数据的混乱程度,信息熵越大说明数据包含的信息越多,也就是数据的波动越大。而ID3算法采用的是信息增益作为计算指标来评价每个特征所包含的信息的多少,而信息增益方法对可取数值较多的特征有所偏好,即本身可取数值较多的特征本身就包含更多的信息,为了减少这种偏好,又有C4.5和CART树,C4.5用信息增益率来衡量数据特征,从而摒除了这种偏好;CART树使用了“基尼指数”来衡量特征,基尼指数越小说明他的数据纯度就越高,选取特征时选取划分后使基尼指数最小的特征作为划分标准,即选取特征后使数据集变得更加纯,从而减少了数据集本身的混乱程度,本身决策树做的事情就是这个。
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 1 19:47:56 2018
@author: chenxi
功能:机器学习实战之决策树
"""
from math import log
import operator
import numpy as np
import matplotlib.pyplot as plt
def calshannonent(dataset): #计算信息熵
numentries=len(dataset)
labelcounts={}
for featvec in dataset: #对dataSet的每一个元素进行处理
currentlabel=featvec[-1] #//将dataSet的每一个元素的最后一个元素选择出来
if currentlabel not in labelcounts.keys():
labelcounts[currentlabel]=0 #//若没有该键,则使用字典的自动添加进行添加值为0的项,取0是因为下一行代码
labelcounts[currentlabel] +=1 #对currentlabel计数,每有一个key:currentlabel,就在对应的key的值上加一
shannonent=0
for key in labelcounts:
prob=float(labelcounts[key])/numentries
shannonent -=prob*log(prob,2)
return shannonent设样本集合D中第k类样本所占的比例pk,则信息熵的计算公式为:
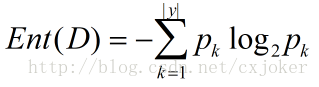 式(1-1)
式(1-1)
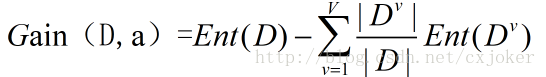 式
(1-2)
式
(1-2)
【二】做数据集转换
本文中我没有使用作者所提供的鱼的数据集,而是采用了UCI的机器学习数据集中的汽车评价数据集(http://archive.ics.uci.edu/ml/datasets/Car+Evaluation),里面有很多很好的数据集,建议做机器学习的同学多使用里面的数据。而UCI的数据集大部分都是txt格式的,所以写了段讲txt格式转换为矩阵的额外的代码。
def file2matrix(filename):
fr=open(filename)
lists=fr.readlines()
listnum=[]
for k in lists:
listnum.append(k.strip().split(','))
return listnum这段代码整体上比较简单,主要是用了readlines读取文本并且使用split对文本进行分割形成数据矩阵即可。
【三】划分数据集
选取特征的方法是计算每个特征的信息增益,然后再基于信息增益的值来选取信息增益最大的特征作为下一次决策树分类的一句,这样保证了每次选取的特征都能最大化程度的减少数据集的信息混乱程度。选取特征之后需要根据该特征下所包含的可能的取值将数据集进行切分,就是举个例子说西瓜中颜色特征有“青绿”、“乌黑”等,我们根据特征的取值将其划分为“青绿类”的西瓜和“乌黑类”的西瓜。
def splitdataset(dataset,axis,value): #按特征选取除该特征之外的特征数据
retdataset=[]
for featvec in dataset:
if featvec[axis]==value:
reducedfeatvec=featvec[:axis]
reducedfeatvec.extend(featvec[axis+1:])
retdataset.append(reducedfeatvec)
return retdataset抽取数据之后还牵扯到数据的添加,此段代码中用到了extend函数和append函数,都是做数据连接的,但是主要区别是append函数直接将连接的数据形成一个元素加入到列表中,而extend时将后段要加入的数据提取出其元素再加入到列表中去。举个栗子就是:
kk=['1','2','3']
bb=['4','5','6']
kk.append(bb)
kk
Out[40]: ['1', '2', '3', ['4', '5', '6']]aa=['1','2','3']
bb=['4','5','6']
aa.extend(bb)
aa
Out[44]: ['1', '2', '3', '4', '5', '6']【四】选取数据集特征进行数据划分
选取特征的方法是计算每个特征的信息增益值,然后找到具有信息增益值最大的特征作为划分的依据进行数据集划分,具体代码为:def choosebestfeaturetosplit(dataset): #就算出信息增益之后选取信息增益值最高的特征作为下一次分类的标准
numfeatures=len(dataset[0])-1 #计算特征数量,列表【0】表示列的数量,-1是减去最后的类别特征
baseentropy=calshannonent(dataset) #计算数据集的信息熵
bestinfogain=0.0;bestfeature=-1
for i in range(numfeatures):
featlist=[example[i] for example in dataset]
uniquevals=set(featlist) #确定某一特征下所有可能的取值
newentropy=0.0
for value in uniquevals:
subdataset=splitdataset(dataset,i,value)#抽取在该特征的每个取值下其他特征的值组成新的子数据集
prob=len(subdataset)/float(len(dataset))#计算该特征下的每一个取值对应的概率(或者说所占的比重)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1879
1879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









