







 本文介绍如何使用Python脚本处理CASIA手写汉字库中的.gnt文件,并将其转换为便于机器学习处理的numpy数组文件。同时提供了一个工具用于预览及保存.gnt文件中的图片。
本文介绍如何使用Python脚本处理CASIA手写汉字库中的.gnt文件,并将其转换为便于机器学习处理的numpy数组文件。同时提供了一个工具用于预览及保存.gnt文件中的图片。
此文章转自来源于网络,转自:不迟到,不早退,不加班 -> setEnabled(true)
2017.06.04 更新: 添加对大文件的支持并在GiiHub中添加了软件界面截图,现在会逐个汉字样本读入数据,对电脑内存几乎没有要求。详见GitHub。
2017.05.21 更新: 添加注释,将原python2.7脚本修改为兼容代码。有小伙伴表示GitHub的c++代码在电脑内存过小时无法处理大文件(7G以上),相应的c++代码会在两周内更新
CASIA手写汉字库是由模式识别国家重点实验室和中国科学院自动化研究所建立的手写汉字数据库,收录了7185个常用汉字及171个特殊符号。更详细的介绍见于数据库主页。
由于课程原因,用到了其中的脱机手写汉字库(HWDB1.1trn_gnt 与 HWDB1.1tst _gnt)的数据。这些数据以 .gnt格式存储,解码后可以得到3755个常用汉字的各300个样本。按照CASIA的建议,240个不同的书写者的样本作为training set,剩余60位书写者的样本作为testing set, 则共有897758个training sample, 223991个testing sample. 本文提供一段Python脚本,可以直接将其中的数据存储成numpy数组文件(.npy文件)。只是,由于图像位置及大小对齐处理的原因,代码效率不是很高,执行起来需要的时间有点久:
Intel Core i7-4710MQ
16GB DDR3L RAM
配置下,training set由.gnt文件转成.npy文件共花费 78 分钟。最终的结果文件有点大(training set 876MB, testing set 218M),可能存成.npy文件不如.h5文件更方便些。
另外,请大家在使用数据时遵守CASIA对于该数据库数据的使用要求。
gnt格式定义见下图:
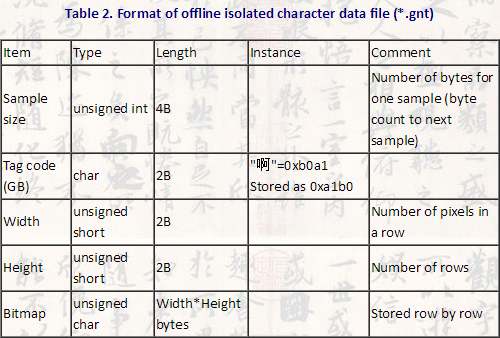
如图所示,文件的前4个字节记录了第一个字符数据与下一个字符数据之间的字节数,比如这4个字节是35656的话,第二个字符的数据就是从第35657个字节开始(下标35656)。接下来的两个字节存储该字符的GBK编码,再下面的4个字节记录了字符图片的宽度和高度,然后就是字符图片的数据(按行存储)。
所需依赖:
- opencv (>=2.0)
- numpy
具体代码如下:
# -*- coding: utf-8 -*-
from __future__ import print_function
import cv2
import numpy as np
import os
import struct
import sys
import zipfile
def gnt2npy(src_file, dst_file, image_size, map_file):
'''
将gnt文件存为npy格式
param src_file: 源文件名,gnt文件
param dst_file: 目标文件名, 若此参数设置为'xxx',则会生成xxx_images.npy 和 xxx_labels.npy
param image_size: 图片大小,设置为m时,最终文件的大小将为 m x m
param map_file: 由于汉字编码不连续,作为分类label并不合适,该文件保存汉字码和label的映射关系
'''
code_map = {}
if os.path.exists(map_file):
with open(map_file, 'r') as fp:
for line in fp.readlines():
if len(line) == 0:
continue;
code, label = line.split()
code_map[int(code)] = int(label)
fp.close()
images = []
labels = []
if zipfile.is_zipfile(src_file): #单体zip文件
zip_file = zipfile.ZipFile(src_file, 'r')
file_list = zip_file.namelist()
for file_name in file_list:
print("processing %s ..." % file_name)
data_file = zip_file.open(file_name)
total_bytes = zip_file.getinfo(file_name).file_size
image_list, label_list, code_map = readFromGnt(data_file, file_name, image_size, total_bytes, code_map)
images += image_list
labels += label_list
elif os.path.isdir(src_file): #包含gnt文件的文件夹
file_list = os.listdir(src_file)
for file_name in file_list:
file_name = src_file + os.sep + file_name
print("processing %s ..." % file_name)
data_file = open(file_name, 'rb')
total_bytes = os.path.getsize(file_name)
image_list, label_list, code_map = readFromGnt(data_file, image_size, total_bytes, code_map)
images += image_list
labels += label_list
else:
sys.stderr.write('Source file should be a ziped file containing the gnt files. Plese check your input again.\n')
return None
with open(map_file, 'w') as fp:
for code in code_map:
print(code, code_map[code], file=fp)
fp.close()
np.save(dst_file + '_images.npy', images)
np.save(dst_file + '_labels.npy', labels)
def readFromGnt(data_file, image_size, total_bytes, code_map):
'''
从文件对象中读取数据并返回
param data_file, 文件对象
param image_size: 图片大小,设置为m时,最终文件的大小将为m x m
param total_bytes: 文件总byte数
param code_map: 由于汉字编码不连续,作为分类label并不合适,该dict保存汉字码和label的映射关系
'''
decoded_bytes = 0
image_list = []
label_list = []
new_label = len(code_map)
while decoded_bytes != total_bytes:
data_length, = struct.unpack('<I', data_file.read(4))
tag_code, = struct.unpack('>H', data_file.read(2))
image_width, = struct.unpack('<H', data_file.read(2))
image_height, = struct.unpack('<H', data_file.read(2))
arc_length = image_width
if image_width < image_height:
arc_length = image_height
temp_image = 255 * np.ones((arc_length, arc_length ,1), np.uint8)
row_begin = (arc_length - image_height) // 2
col_begin = (arc_length - image_width) // 2
for row in range(row_begin, image_height + row_begin):
for col in range(col_begin, image_width + col_begin):
temp_image[row, col], = struct.unpack('B', data_file.read(1))
decoded_bytes += data_length
result_image = cv2.resize(temp_image, (image_size, image_size))
if tag_code not in code_map:
code_map[tag_code] = new_label
new_label += 1
image_list.append(result_image)
label_list.append(code_map[tag_code])
return image_list, label_list, code_map
if __name__=='__main__':
if len(sys.argv) < 5:
sys.stderr.write('Please specify source file, target file, image size and map file \n')
sys.exit()
src_file = sys.argv[1]
dst_file = sys.argv[2]
image_size = int(sys.argv[3])
map_file = sys.argv[4]
gnt2npy(src_file, dst_file, image_size, map_file)
命令格式举例: python gnt2npy.py src target img_size map_file,以上参数中,gnt2npy为脚本文件名,可任意更改。src为源文件名,可以是只包含.gnt文件的zip包,也可以是将压缩文件解压后的文件夹名称,target为目标文件名,假设该值为train则脚本执行后会生成train_images.npy与trian_labels.npy两个文件,分别为图像数据和对应的label。图像的大小则可以通过第三个参数img_size指定,假设该值为32则图像文件大小为32 x 32。另外,由于汉字的GBK编码并不是从零开始,也不完全连续,作为分类的label不是很合适,因此在保存label时根据一定的规则将GBK编码映射为数据的label,最后一个参数map_file则保存这种映射关系,第一次执行脚本时生成该文件,以后则可以通过该文件保证相同汉字,其label总是相同的。
请注意,HWDB1.1trn_gnt.zip包含的其实是一个ALZ压缩文件,因此请不要将该文件名直接作为参数传入以上代码,请将里面的ALZ文件解压后将文件夹的名字作为参数。
此外,这个Github链接提供了预览及保存图片文件的工具,同样可以用于该文件类型(.gnt)的数据提取,并且可以通过选择使用的框架(Caffe/CNTK/TensorFlow/NvidiaDigits)将图片文件按照不同的大小、格式保存。其中,win64_bianry.zip包含编译好的X64二进制文件和一份简单的使用说明,其他为源码及源码生成GUI需要用到的图片和一个qt项目文件gntDecoder.pro,有兴趣的话也欢迎大家下载源码随意修改。预编译的X64程序运行时可能要求”api-ms-win-crt-runtime-l1-1-0.dll”,出现该信息的话请通过微软官网或者机器中的Windows Update安装 KB2999226 补丁(通用C运行库)。

















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









