







 本文详细介绍了决策树的学习原理,包括信息熵、信息增益、信息增益率、基尼值等概念,并探讨了决策树的剪枝方法。接着,文章讲解了随机森林的Bagging策略及其改进,指出随机森林通过并行生成多棵树以提高泛化能力。最后,通过代码示例展示了如何使用决策树和随机森林进行手写数字的预测。
本文详细介绍了决策树的学习原理,包括信息熵、信息增益、信息增益率、基尼值等概念,并探讨了决策树的剪枝方法。接着,文章讲解了随机森林的Bagging策略及其改进,指出随机森林通过并行生成多棵树以提高泛化能力。最后,通过代码示例展示了如何使用决策树和随机森林进行手写数字的预测。
一、决策树
决策树学习是机器学习中一类常用的算法。在决策树中,根节点包含样本全集。每个非叶子节点表示一种对样本的分割,通常对应一个划分属性,其将样本分散到不同的子节点中。每个叶子节点对应于决策的结果。因此从根节点到每个叶子节点的路径对应了一个判定序列。
可与下图做比对:
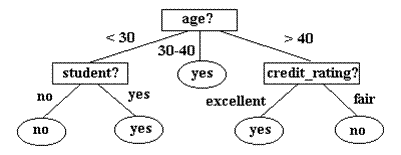
在上图的决策树中,划分属性有年龄、是否为学生、信用率。
划分属性一般采用样本的某个特征或多个特征的组合。
决策树学习是一种有监督学习,根据样本为基础,自顶向下通过递归的方法来对样本进行划分属性。其基本思想是以 信息熵 为度量来构造一棵熵值下降最快的树,直到叶子节点处的熵值为0。
二、信息熵
1. 定义
“信息熵”是度量样本集合纯度最常用的一种指标。假定在当前样本集合D中有k类样本(样本的标签有k类),其中第i类样本所占样本集合的比例为pi(i = 1,2,…..,k),则样本集合D的信息熵可定义为
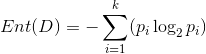

其中 
(熵:Entropy)
2. 信息熵与纯度的关系
由信息熵的公式,我们可以看出,当样本集合中只存在一类样本时,k=1,p1=1,这时信息熵Ent(D)的值为0;当样本集合存在2类样本时,若每类样本的概率为1/2,这时信息熵Ent(D)的值为1;…… 当信息熵Ent(D)的值越小,则样本集合D的纯度越高。
若我们需要的决策树是以 信息熵 为度量来构造一棵样本的熵值下降最快、结点纯度越来越高的树。那我们怎么对样本集合分割?如何选择我们的最优划分属性(特征)来作为我们分割样本集合时的非叶子节点?
于此,我们需要对样本的各个特征进行度量,选出当前最好的划分属性作为树的分隔结点,使得我们的分类最纯。
通常的度量方法有如下方法:
信息增益(ID3)
信息增益率(C4.5)
基尼系数(CART)
三、信息增益
1. 单个分支的信息熵
若样本中有某个离散特征 
在这k个分支节点中,第 i 个分支节点包含样本集合D中所有属性 
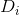
我们可以根据 信息熵 的公式计算出 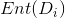
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









