









原创作品(陈晓爽 cxsmarkchan)
转载请注明出处
《Linux内核分析》MOOC课程学习笔记
操作系统中有大量进程在运行,而在单核CPU中,每个时刻只能有一个进程的指令在被执行。因此,操作系统需要不断进行进程切换,即分时工作。问题是:如果一个进程在执行过程中被中断,如何记录其中断位置?在下一次执行的时候,如何保证该进程的数据没有被破坏?这些都是进程切换时需要做的工作。本文从一个简单的时间片轮转多道程序内核代码为例,说明操作系统进程切换的原理。
本文为linux内核分析课程的学习笔记,实验在实验楼 Linux内核分析平台上完成。
本文分析的源代码来自https://github.com/mengning/mykernel/。
1 进程切换的原理
1.1 进程现场信息
1.1.1 数据结构
每个进程均包含代码段和堆栈段,代码段和堆栈段均存储在内存中。在进程切换时,要完成两方面工作:
1. 切换程序当前执行位置(即eip指针);
2. 切换程序的堆栈指针(即ebp指针和esp指针,其中ebp为堆栈底端,esp为堆栈顶端)。
因此,操作系统可以维护以下数据结构,以存储程序堆栈信息:
struct Thread{
unsigned long ip; //程序当前执行位置
unsigned long sp; //程序的堆栈顶端指针
};需要注意的是,堆栈的底端指针ebp在进程切换中不需要存储到该数据结构中,原因可见1.1.2节。
1.1.2 保存和恢复eip的方法
保存和恢复eip指针时,需要注意,eip指针不能通过汇编语言直接改变,只能通过call/ret语句间接访问。
有两种方案实现eip指针的保存:
1. 调用call f语句实现eip的压栈,在f:中执行popl ip将eip保存到ip中。
2. 把一个固定的位置作为返回位置,存入ip中,例如movl $1f, ip。该方法可用于每次返回都要执行固定代码的情况,本文即将分析的代码即属于该情况。
eip的恢复相对比较简单,只需将ip值压栈,然后调用ret,即可弹栈并跳转到指定的位置。
1.1.3保存和恢复堆栈信息的方法
初看上去,堆栈的顶端(esp)和底端(ebp)都需要存储,但实际上,操作系统只需维护esp的信息。这是因为:
1. 在切换进程前执行pushl %ebp将堆栈底端指针压栈,此时esp指向的内存地址即存储ebp的值。然后再将esp存储到Thread对象中,即可完成堆栈信息的保存。
2. 在切换回该进程的时候,只需恢复esp,然后执行popl %ebp弹栈,即可恢复ebp。
1.2 进程控制块(Process Control Block, PCB)
进程控制块是操作系统维护进程的单元。一个进程控制块可为如下结构:
struct PCB{
unsigned long pid; //进程id
volatile long state; //进程状态,-1表示未执行,0表示正在执行
char stack[STACK_SIZE]; //进程的堆栈空间,STACK_SIZE为最大的堆栈空间
struct Thread thread; //进程的现场信息
unsigned long task_entry; //进程的初始入口
struct PCB *next; //下一个进程(可构成进程链表。链表并非典型的操作系统进程管理方式,只是本博客采用该方法。)
};其中, 除了thread为进程现场信息,需要在进程切换中使用以外,其余信息均为进程初始化的时候使用。
2 一个简单的实验
2.1 实验设置
打开实验楼 Linux内核分析平台,选择第2个实验:完成一个简单的时间片轮转多道程序内核代码。在该实验平台上,我们采用qemu模拟一个操作系统。
进入实验后,在控制台输入如下命令:
cd LinuxKernel/linux-3.9.4
qemu -kernel arch/x86/boot/bzImage即可得到如下的输出结果:
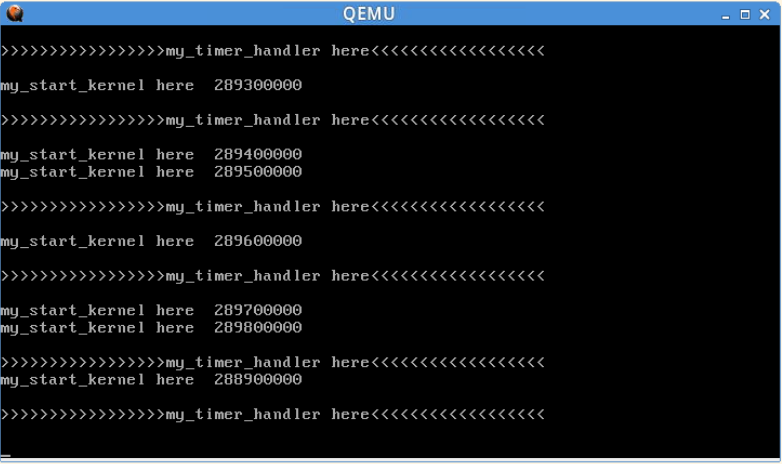
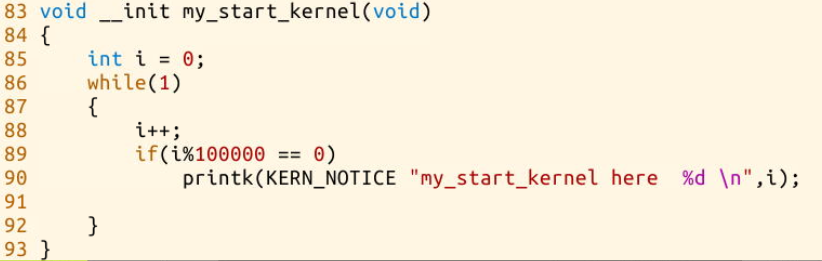
可以看出,该结果为两行程序的交替执行。进一步地,执行cd mykernel进入LinuxKernel/linux-3.9.4/mykernel文件夹,可以看到两个文件mymain.c和myinterrupt.c,在mymain.c可以看到my_start_kernel函数:
在myinterrupt.c中可以看到my_timer_handler函数:

将两段函数的代码和程序执行结果联系起来,我们已经可以得出如下结论:
1. my_start_kernel函数是一个无限循环,在程序运行后就一直在执行;
2. my_timer_handler是一个输出语句,但在执行结果中不断重复出现,可见该函数是在定时执行。
3. 因此,操作系统以my_start_kernel作为入口,同时含有一个定时中断,每隔一段时间就执行一次my_timer_handler函数,然后返回my_start_kernel
这里,对于操作系统的加载过程不做深究,仅通过改写这两个函数,实现操作系统的进程切换。
2.2 实验过程
用https://github.com/mengning/mykernel下的mymain.c和myinterrupt.c替换mykernel文件夹下的相应文件,并加入mypcb.h。再次切换到LinuxKernel/linux-3.9.4文件夹下运行qemu,可以得到如下运行结果:
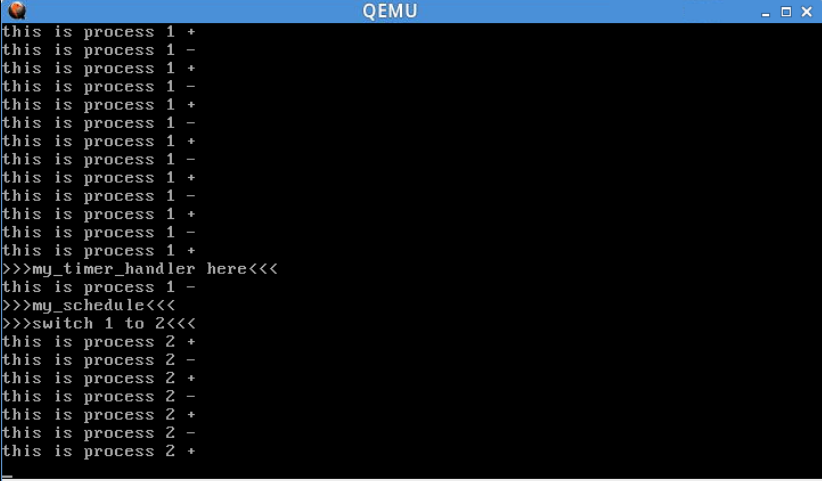
截图展示了部分运行结果。实际上,系统共维护4个进程,标号分别为0,1,2,3,每当my_timer_handler调用一次,就会进行一次进程切换。我们比较关系的,是进程切换中现场的保存和恢复,这些内容将在1.3节中详细说明。
3 源码分析
源码中,mypcb.h用于定义进程控制块,和1.2节内容基本相同,此处略去,重点分析mymain.c和myinterrupt.c中的相关内容。
3.1 全局变量声明
变量声明在mymain.c中,如下:
tPCB task[MAX_TASK_NUM]; //各个进程的进程控制块,MAX_TASK_NUM在mypcb.h中定义为4
tPCB *my_current_task = NULL;//当前进程控制块的指针
volatile int my_need_schedule = 0;//是否需要进行进程调度3.2 初始化内容
在my_start_kernel中进行进程的初始化。初始化代码及其注解如下:
void __init my_start_kernel(void)
{
int pid = 0;
int i;
//第一个进程的PCB初始化
task[pid].pid = pid;
task[pid].state = 0; //首个执行的进程,此处默认其已经执行
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;//进程入口为my_process
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE - 1]; //进程初始堆栈位置,初始在堆栈底端(即堆栈最高位)
task[pid].next = &task[pid];//构造循环链表,以便顺序执行
//其他进程PCB的初始化
for(i = 1; i < MAX_TASK_NUM; i++){
memcpy(&task[i], &task[0], sizeof(tPCB)); //复制第一个进程,再稍作修改
task[i].pid = i;
task[i].state = -1;//尚未执行的进程,其state默认为-1
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE - 1];//在这个简单的程序中,4个进程入口均为my_process,通过my_current_task得知当前进程。在真正的操作系统中应该不会这样。
task[i].next = task[i - 1].next;
task[i - 1].next = &task[i];//这两句是在循环链表中插入元素
}
pid = 0;
my_current_task = &task[pid]; //当前进程
//这段汇编代码用于装载第一个进程,这段代码按理说可以和进程切换部分的汇编代码相同(除去装载第一个进程时不需要保存现场以外),但很奇怪的是,源代码中这两段代码并不相同,这一点我也不太清楚原因。
asm volatile(
"movl %1, %%esp \n\t" //装载esp
"pushl %1 \n\t" //ebp(此时等于esp)压栈,为之后弹栈ebp做准备
"pushl %0 \n\t" //ip压栈
"ret \n\t" //跳转到给定的ip执行,这里是my_process的入口程序
"popl %%ebp\n\t" //该代码不会立即执行,具体执行时间也不太清楚。我总觉得这是一句错误代码Orz...anyway,并不会影响程序运行,因为堆栈操作都是走栈顶。
:
: "c"(task[pid].thread.ip), "d" (task[pid].thread.sp)
);
}3.3 进程执行部分和定时中断部分
进程执行部分my_process是4个进程共同的入口,代码如下:
void my_process(void){
int i = 0;
while(1){
i++;
if(i%100000000 == 0){
printk(KERN_NOTICE "this is process %d - \n", my_current_task->pid);
if(my_need_schedule == 1){
my_need_schedule = 0;
my_schedule();//在my_need_schedule为1的时候,调用进程切换函数。
}
printk(KERN_NOTICE "this is process %d + \n", my_current_task->pid);
}
}
}可见该函数是在一定次数的循环之后输出一条信息,并且检查my_need_schedule,如果为1,则将其置0,并调用进程切换函数切换进程。
my_need_schedule的置1则出现在定时中断中:
void my_timer_handler(void)
{
if(time_count %1000 == 0 && my_need_schedule != 1){
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_schedule = 1;//在一定时间后,将my_need_schedule置1,这样,my_process继续执行的时候,就会调用my_schedule进行进程切换。
}
time_count++;
}3.4 进程切换部分
进程切换部分my_schedule是本程序的关键,此处进行详细分析:
3.4.1 源代码
my_schedule源代码如下:
void my_schedule(void){
//这部分很简单,不再解释
tPCB *next, *prev;
if(my_current_task == NULL || my_current_task->next == NULL){
return;
}
printk(KERN_NOTICE ">>>my_schedule<<<\n");
next = my_current_task->next;//即将切换到的进程
prev = my_current_task;//当前进程
//state=-1表示第一次执行,state=0表示之前执行过被中断,现在继续执行
if(next->state == 0){
//以下为state==0时的代码,详见下文
}else{
//以下为state==-1时的代码,详见下文
//state==0或-1的区别只在恢复现场部分:state==0时,程序已经运行,可能有堆栈操作,因此需恢复ebp信息;state==-1时,程序第一次执行,ebp和esp相等。
}
}以上是代码的框架,state==0时代码如下:
//对于继续执行的代码,需要恢复堆栈信息,即popl %ebp
asm volatile(
//以下是跳转之前的操作
"pushl %%ebp\n\t" //保存现场:ebp压栈
"movl %%esp, %0 \n\t" //保存现场:esp存入PCB中
"movl %2, %%esp\n\t" //恢复现场:新进程的esp
"movl $1f, %1\n\t" //保存现场:这里强制将下一条指令放在1:处($1f在汇编时会指向1:的位置)
"pushl %3 \n\t" //恢复现场:新进程的eip
"ret \n\t" //跳转执行,以上为前一个进程的操作
//以下是跳转之后的操作
"1:\t" //这句代码标志了汇编代码中“1:”的位置
"popl %%ebp \n\t" //恢复执行后首先弹栈,得到ebp
:"=m" (prev->thread.sp), "=m" (prev->thread.ip)
:"m" (next->thread.sp), "m"(next->thread.ip)
);
//恢复执行后,执行以下两行语句,然后函数返回。
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid);state==-1时代码如下:
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid);
asm volatile(
"pushl %%ebp \n\t" //保存现场:ebp压栈
"movl %%esp, %0 \n\t" //保存现场:esp
"movl %2, %%esp \n\t" //初始化esp
"movl %2, %%ebp \n\t" //初始化ebp
"movl $1f, %1 \n\t" //保存现场:eip,这里的$1f仍指向1:处,即state==0中代码定义的位置
"pushl %3 \n\t" //存入程序入口
"ret \n\t" //跳转
:"=m" (prev->thread.sp), "=m"(prev->thread.ip)
:"m" (next->thread.sp), "m"(next->thread.ip)
);3.4.2 保存现场
3.4.1中已经进行了注解,保存现场一共有如下内容:
1. ebp压栈
2. esp存入PCB中
3. 将当前位置存入PCB中,本例简单地存入1:位置,恢复执行的时候都会从1:位置开始执行。
3.4.3 恢复现场
在state==-1时,恢复现场即初始化,比较简单,有如下操作:
1. 置入esp和ebp,两者相等,表示堆栈中无内容;
2. 程序入口ip压栈;
3. 通过ret弹栈并跳转。
- 这里有一个疑惑,在前面已经提到了:该段汇编代码按理说应和my_start_kernel中的汇编代码保持一致,但实际上并非如此,所以我并没有理解my_start_kernel中的代码的含义。
在state==0时比较有意思:
1. 置入esp;
2. 程序入口ip压栈;
3. 通过ret弹栈并跳转。
这里并没有置入ebp,那么ebp如何恢复呢?
答案是ret之后再恢复。在本例中,程序入口ip即为1:的位置,我们可以看到1:处的代码如下:
asm volatile("popl %%ebp\n\t");
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid);所以,在此处,程序进行了弹栈,而栈顶元素,正是在保存现场时压栈的ebp。因此,到这里,esp、ebp均已恢复,程序继续向下,即可正确执行。程序在执行完popl %ebp及其后方的两行代码后,即从my_schedule中跳出,进入my_process的大循环中。
5 小结和疑问
通过本文的分析,可以看出操作系统在进行进程切换时,保存现场和恢复现场的基本方法。值得注意的是,进程切换过程需要使用内联汇编的方法,这是因为进程切换无法通过C的结构化方法实现。也可以看出,在汇编代码中有很多ret/push/pop指令,这些指令并没有像正常函数调用那样,成对出现。因此,分析程序的跳转方式,是理解进程切换的关键所在。
最后再次贴出我对这段源程序的疑问:
- 3.2节初始化代码中的汇编部分,和3.4节进程切换代码中的state==-1部分,做的是同样的事情(除了保存现场),为什么代码内容不同?
- 3.2节中的代码,ret后的popl %ebp是在什么时候执行呢?
期待得到解答^_^















 8206
8206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









