









核心思想:使用卷积神经网络提取视频光流运动信息

上图是抽象的网络结构描述,convolution network的前半段进行卷积和池化操作,输出特征图分辨率逐渐变小。Convolution network的后半段使用反卷积和特征concat融合操作,输出特征图分辨率逐渐变大。
网络结构:
FlowNetS:

FlowNetS直接把一对图像输入到卷积网络中,让网络自己学习提取运动特征,理论上只要网络规模足够大,是可以学习到光流特征的,FlowNetS输入的是两张图片,所以输入通道数是6。上图中箭头表示特征融合,将低维特征和高维特征进行融合,提取细粒度特征。
FlowNetC:
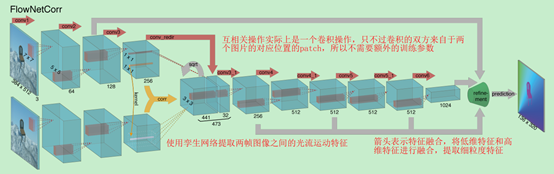
FlowNetC使用孪生网络提取两帧图像之间的光流运动特征,首先对两张图片进行相同的处理,然后将处理结果进行结合来提取光流特征。使用互相关层来比较两个特征图中的patch(比如3x3的区域)。使用特征图1上的每个patch区域和特征图2上的每个patch区域进行互相关操作,这个操作类似于将特征图1上的所有patch作为卷积kernel对特征图2进行卷积操作。上图中箭头表示特征融合,将低维特征和高维特征进行融合,提取细粒度特征。
单次互相关操作的表示如下:

上述公式其实等价于卷积操作中的一个计算步骤,这里没有卷积核,而是两个patch的图片,所以互相关操作没有需要训练的参数。每一个patch x只和其邻域内的一些patch进行互相关操作,邻域大小为D,每一次互相关操作得到一个标量值所以互相关的输出形状为D*D,所以两张图像互相关的输出大小为w*h*D*D。
特征融合,进行特征上采样得到细粒度特征:

在CNN中通过使用stride卷积和pooling操作提取抽象的高维特征,但是optical flow任务是pixel-wise的,所以太抽象了也不行。论文中采用反卷积操作提升特征图的分辨率,然后和相同分辨率的低维特征进行concat特征融合,最终输出的特征图大小是原始图像的1/4(长宽各缩小一半)。上图中由下往上的箭头conv5_1、conv4_1、conv3_1、conv2就是卷积网络下采样过程中的输出特征,然后和对应的反卷积特征将进行融合,实现细粒度的特征提取。
特征融合变体(还没看懂hhh):

参考:https://blog.csdn.net/jucilan3330/article/details/84331626














 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









