







Flownet: Learning Optical Flow with Convolutional Networks
传统:基于变分能量模型的优化算法和基于块匹配的启发式算法
自监督
Flownet: Learning Optical Flow with Convolutional Networks
Flownet: 用卷积神经网络学习光流法
Abstract
卷积神经网络(CNNS)在各种计算机视觉任务中非常成功,特别是那些与识别相关的任务。光流估计也是CNNs成功的领域之一。在本文中,我们以监督学习的方式构建了一个CNNs用来解决光流估计问题。我们提出并比较了两种架构:一种是通用的架构,另一种则包含了一层不同图像位置特征向量关联层。因为当前的GT数据集的规模不够用来训练一个CNN,我们构建了一个大规模的合成数据集Flying Chairs dataset。我们证明了在这个合成的数据集上训练的网络仍然可以在其他数据集比如Sintel和KITTI上得到很好的效果,以帧率5到10FPS实现了富有竞争力的准确率。
1. Introduction
在很多计算机视觉领域,卷积神经网络已经成为一种选择。它们以前常被用于进行图像分类[25,24],但是近来很多用于像素预测的架构被提出来了,比如语义分割[28]或者单目深度估计[10]。在本文中,我们端对端地训练了一个CNNS用于从一对图像中预测光流场。
光流估计除了需要精确地像素级定位外,还需要在两张输入图片中进行特征匹配。这要求不仅仅需要对图像特征表示进行学习,还需要在两张图片中将不同位置的特征匹配起来。在这方面,光流估计与先前的CNNs应用有本质区别。
因为不确定这个任务是否可以用标准的CNN架构来解决,我们额外提出了一种包含关联层的架构来显式地提供匹配功能。这个架构会进行端对端的训练。这个想法利用卷积神经网络在不同范围和抽象上学习健壮的特征并帮忙找的这些特征中实际的联系。在关联层之上的层用于学习怎么从这些匹配中预测光流(这里应当指的是关联层之后的层)。令人惊讶的是,这种网络设计并不是必要的,甚至原来的网络可以以富有竞争力的准确率来预测光流。
训练一个预测通用光流估计的网络需要大规模的训练集。尽管图像增强有助于此,但是当前的光流估计数据集对于训练一个足以匹配当前最强SOTA算法的神经网络仍然太小了。并且,从现实视频材料中获得光流真实值非常难[17]。在逼真程度和规模上权衡之后,我们生产力一个合成的Flying Chairs数据集,其中包含了从Flickr获得的任意背景图像,并且覆盖上分割后的椅子[1]。这些数据与现实世界相差很大,但是我们可以按照自己的需要产生任意需要的样本。在这些数据集上训练的CNNs在真实的数据集上展现了很好的泛化性能,即便没有利用微调(fine-tuning)。
利用基于GPU的CNNs,我们的算法比大多数竞争者都要更快。我们的网络在全分辨率的Sintel数据集上实现了每秒10对图像的光流估计速率,在实时的工作的实现了SOTA精度。
3. 网络架构
众所周知,在给定足够标签数据的情况下卷积神经网络是一种学习输入-输出关系的很好的方法。因此,我们采用了一种端对端的学习方法来预测光流:给定一个包含图像对和GT光流的数据集,我们训练了一个神经网络直接从图像中预测 x − y x-y x−y光流场。但是什么样的网络架构最适合做这件事呢?
CNNs中的池化层(pooling)能够使得训练的计算量可行,并且,更本质地,可以聚合输入图像大范围内的信息。(这里应该是利用池化层来缩小feature map的尺寸,降采样)。但是池化层会导致分辨率的降低,为了提供稠密的像素预测我们需要重新细化粗糙的池化表示。因此,我们的网络包含了一个扩展模块用来机智地细化,得到高分辨率的流场。神经网络包含了比较和扩展模块被作为一个整体来进行反向传播。我们所用的架构在Figures 2 和3中展示出来了。我们现在更详细地描述一下网络中的这两个部分。
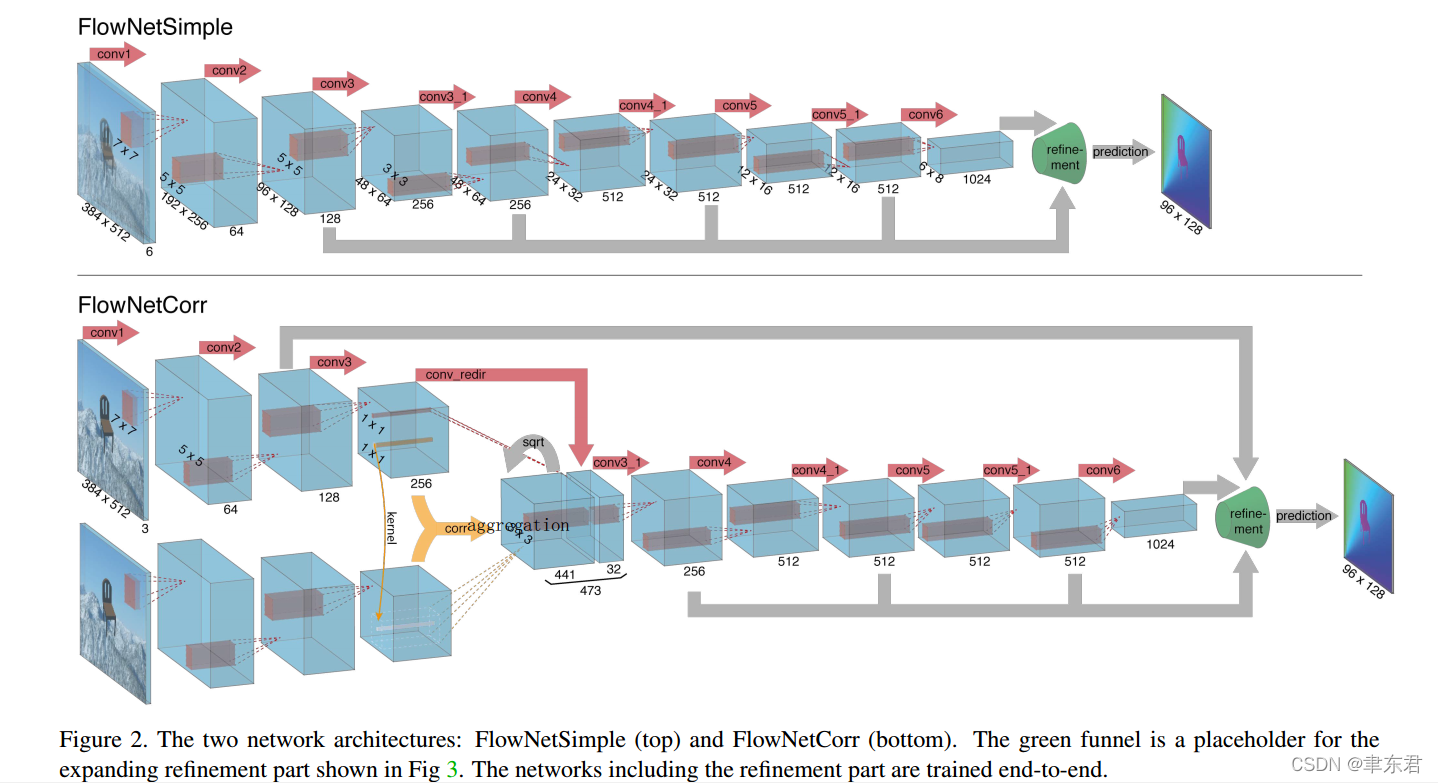
Figure 2. 两种网络架构:FlownetSimple(top)和FlowNetCorr(bottom)绿色的漏斗是为扩展细化模块所预留的位置,这在Fig 3中展示出来了。包含细化模块的神经网络被端对端的训练。
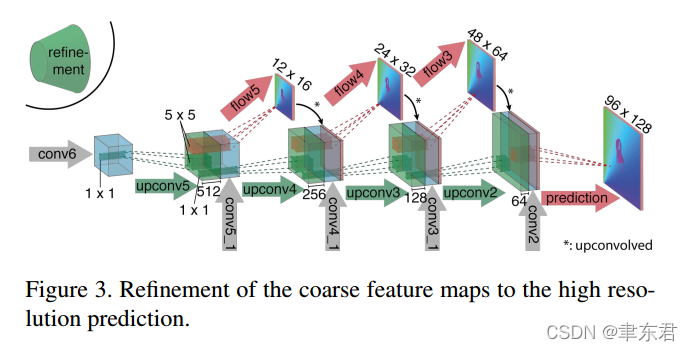
Figure 3. 特征图(feature map)从粗糙细化为高分辨率
比较模块(Contracting part)
(这里包含特征的提取、融合匹配;feature map的缩小)
一个简单的选择是把两张输入图像拼接在一起并且把它们输入一个相对通用的网络,使得网络自主决定如何处理图像对来提取运动信息。这被展示在Fig. 2(top)中。我们把这种只包含卷积层的架构称为‘“FlowNetSimple”。’
另一个方法是构建两个分开的特征提取模块,但是它们参数一致 ???,用来处理两张输入图像,并把它们后面添加一个步骤把它们结合起来,正如Fig. 2(bottom)所展示的那样。在这样的架构下,网络被限制为首先为两张图像分别产生有意义的表示然后再在一个更高的层次把它们结合起来。这种做法大致上像标准的匹配方法,也就是说首先从图像对中的块中提取特征然后再比较它们的特征向量。但是,给定两张图像的特征表示,网络该如何进行特征匹配呢?
为了在神经网络中实行匹配过程,我们引入了“关联层”(correlation layer),它可以在两个特征图间执行乘法块比较(multiplicative patch comparisons)。网络架构FlowNetCorr中包含的关联层在Fig. 2(bottom)有所展示。给定两个多通道的特征图 f 1 \pmb {f}_1 f1和 f 2 \pmb{f}_2 f2: R 2 {R^2} R2 -> R c {R^c} Rc, w w w, h h h和 c c c分别为它们的宽度、高度和通道数(这里符号表示有点奇奇怪怪,其实就是说两个特征图的尺寸都为(w,h,c)),我们的关联层使得网络可以比较 f 1 \pmb {f}_1 f1和 f 2 \pmb{f}_2 f2之间的每个小块(patch)。
现在我们考虑一下两个小块之间单独的比较。第一个特征图中的小块中心记为
x
1
x_1
x1,第二个特征图中的小块中心记为
x
2
x_2
x2,两个小块之间的关联(correlation)可以定义为:
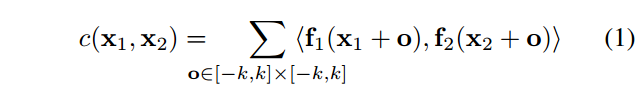
一个方形小块的边长为
K
:
=
2
k
+
1
K := 2k +1
K:=2k+1。注意Eq. 1等于于卷积神经网络中的一个卷积步骤。但是不同于采用一个滤波器来进行卷积,这里我们用一批数据对另一批数据进行卷积。因此,这里边没有可以训练的权重。(确实是这样,想象一下从第二个特征图中拿出一个小块作为卷积,然后把它覆盖第一个特征图的一个小块上做加权求和,对每个通道都做这样的操作,然后再把每个通道上的值相加,最后得到一个总和,这个过程实际上和上面的公式是等价的,也和一般的卷积是非常相像的,唯一区别就是卷积核的参数是固定的并且每个通道)
计算 c ( x 1 , x 2 ) c(x_1,x_2) c(x1,x2)包括了 c ⋅ K 2 c\cdot K^2 c⋅K2次乘法。由于特征图 f 1 \pmb f_1 f1的所有小块将会分别和 f 2 \pmb f_2 f2上的所有小块分别做上面的比较结合,所以共有 w 2 ⋅ h 2 w^2 \cdot h^2 w2⋅h2次上述计算。这回产生大量的结果并且使得原本效率很高的前向传播和反向传播难以为继。所以,为了计算量考虑,我们限制了最大的比较偏移量,同时在特征图对中引入了步幅。
给定一个最大的偏移量 d d d,对于第一个特征图中每个 x 1 x_1 x1的位置,我们只在一个尺寸为 D : = 2 d + 1 D := 2d +1 D:=2d+1的邻域内计算关联 c ( x 1 , x 2 ) c(x_1,x_2) c(x1,x2),从而限制了 x 2 x_2 x2的范围。我们采用步幅 s 1 s_1 s1和 s 2 s_2 s2来全局量化 x 1 x_1 x1和以 x 1 x_1 x1为中心的邻域内的 x 2 x_2 x2。
理论上,上述关联产生的结果是四个维度的:对于每两个2D位置我们通过结合可以获得一个关联值,也就是两个向量的内积,这两个向量分别包含各自小块中的所有值。(就是说把Eq. 1中的小块关联运算看做两个很长的向量的内积,向量是由小块中每个位置的向量拼接起来的,哎,就是换一种说法而已)在实践中,我们会组织通道间的相对偏移。这意味着我们获得的输出的尺寸将为 ( w × h × D 2 ) (w \times h \times D^2) (w×h×D2)。对于反向传播,我们相应实现对于每个底层数的导数。
(上面三段有点绕,总结一下就是原来的操作是,对于两个特征图,我们都会从以每个像素为中心裁剪出一个小块,也就是wh个小块,然后第一个特征图中的每个小块都会和第二个特征图中的每个小块进行关联计算,每个关联计算都会产生一个标量值。总共w * h * w * h次计算。
但是每个小块上的像素只可能在运动中偏移到其领域,不可能跑的非常远,所以两个距离非常远的小块的关联计算是没有必要的。
因此对于第一个特征图上的某个小块,我们不再把它和第二个特征图上所有小块进行关联计算,而只是把它和第二个特征图上对应位置附近的小块进行计算,小块的中心分布在以D为边长的正方形内,总共有D*D个小块。由此,关联计算的次数锐减为w * h * D^2。
对应到Fig 2 中,我们得到的输出特征图为w * h * 441,因此可以知道D=21。
但是对于上面所说的步幅,以及输出特征图后面接的32个通道不知道是什么?
)
扩展模块(Expanding part)
扩展层的主要组成是“上卷积层”(upconvolution),其中包含了“反池化层”(unpooling)(用以扩展特征图,与池化层正好相反)和一个卷积层。这样的层之前在[38,37,16,28,9]中也有用过。为了进行细化,我们对特征图应用了上卷积层,并且把它和来自比较模块的对应特征图,以及前面的上采样粗糙流场估计拼接在一起(如果有的话)。 通过这种方式我们同时保存了来自粗糙特征图的高层信息(指的是来自上一个特征图以及粗糙光流的信息)和来自低层特征图的细微局部信息(指的是比较模块那里来的特征图)。每个步骤将分辨率提高了两倍。我们重复了该步骤四次,但分辨率仍然比输入图像更小。Figure 3展示了整体的架构。我们发现更加深入的细化对效果的提升很少,但是计算量消耗却比较大,还不如直接利用双线性差值来上采样为完全的输入图像的分辨率。
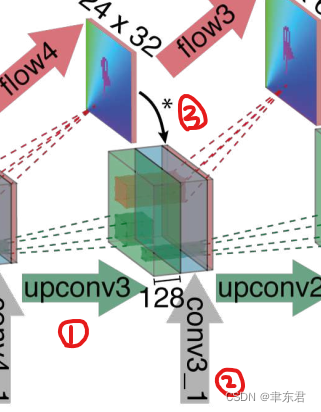
(可以看到某一层的输入特征图是由三部分组成的,即前一层特征图的上卷积+比较模块中同样尺寸的特征图+前一层特征图的预测流场的上卷积。由于前一层特征图的预测流场的大小小于本层特征图,所以也用上卷积处理了一下,也就是*号的操作)
问题:
汇入成分,与FPN的区别
与转置卷积的不同
没有直接得到与原图像同样大的分辨率,而是采用插值,为什么呢?语义分割可是得到了最后的分辨率
变分细化(Variational refinement)

Figure 4. 变分细化的作用。第一行中运动是比较小的,经过变分细化后流场变化是比较大的。第二行中,运动更大一些,变分细化并不能消除大的误差,但是流场更加平滑了,也可以使得EPE降低。
最为另一种选择,最后一个步骤中,我们可以不采用双线性插值,而是用[6]中的不带匹配项的变分方法:一开始流场的分辨率只有输入图像的四分之一,我们把由粗到细的的方法迭代了20遍使得流场达到全分辨率。最后,我们在全分辨率的流场上再迭代多五次。我们用[26]中的方法额外地检测图像边缘,并且通过替代光滑系数的方法来respect检测出来的边缘,即 α = e x p ( − λ b ( x , y ) k ) \alpha=exp(-\lambda b(x,y)^k) α=exp(−λb(x,y)k),其中 b ( x , y ) b(x,y) b(x,y)表示细边缘强度
4. Training Data
不像传统的方法,神经网络需要带有真实值的数据,不仅仅是用来优化参数,也是为了从零训练该任务。通常来讲,获得这种真实值是非常难的,因为在真实世界场景中准确的像素关联并不容易解出。当前可获得的数据集在Table 1中给出了。
4.1 Existing Datasets
Middlebury数据集[2]只包含8对用来训练的图像,真实的光流值是用4种不同的方法产生的。像素偏移值非常小,通常少于10个像素。
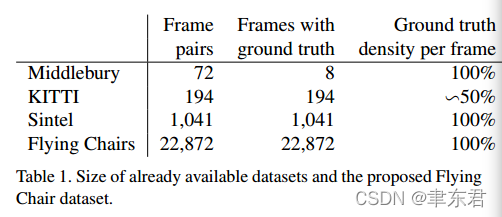
Table 1. 当前的数据集的规模和本文提出的Flying Chair数据集
KITTI数据集[14]更大(194对训练图像),同时也包含大的偏移,但是只包含一种非常特殊的运动类型。真实值是在实际场景中通过同时用相机和一个3D激光扫描仪记录的。假设了场景是刚体的同时运动来自于一个移动的观测者(这里应该是说运动只来自观测的相机,而被观测的场景中没有运动的物体)。同时,遥远物体的运动,比如说天空,并不能被捕捉,这导致稀疏的光流真实值。
MPI Sintel数据集包含了来自人工渲染的场景中的真实值,同时特别关注了现实图片的属性。有两个版本被提供:Final version包含了运动模糊和大气影响,比如雾,但Clean version并不包含这些影响。Sintel是可以获得的最大的数据集(每个版本有1041对训练图像),同时提供了小和大的偏移幅值的稠密真实值。
4.2 Flying Chairs
Sintel 数据集对于训练大的CNNs仍然太小了。为了提供足够的训练数据,我们创建了一个简单的合成数据集,叫做Flying Chairs,通过对来自Flicker和一个公开的3D椅子模型渲染集做仿射变换[1]。我们从Flickr中检测了964张分辨率为1024x768的图像,其中包含目录city(321),landscape(129)和mountain(514)。我们把图像剪裁为四个想先,也及时512x384的子图像,将它们作为背景。。对于前景物体,我们把多个来自来自[1]的椅子加入了背景。再在开始的输出的数据集中,我们移除了非常相似的椅子,最后剩下809种椅子和每种椅子62种视角。Figure 5中展示了例子。
为了产生运行,我们随机为背景和椅子随机抽样了2D仿射变换参数。椅子的变换是相对于背景的变换的,也就是说,相机和椅子都在运动。采用这些变换参数我们产生第二张图像,真实光溜值和遮挡区域。
每对图像的所有参数(数量,类型,尺寸和椅子的初始位置;变换参数)都是随机采样的。我们用这种方式调整这些参数的随机分布,这样它们的偏移直方图就会和Sintel的相似(附加材料中提供了更多细节)。通过这个这个过程,我们产生了一个带有22872图像对和光流场的数据集(我们重利用了每张背景图像很多次)。注意数据集的大小是任意选择的并且原则上可以更大。

Figure 5. Flying Chairs. 生成的图像对和颜色编码的流场(前三列),增强的图像对以及对象的颜色编码流场(后三列)。
4.3 Data Augmentation(数据增强)
一个广泛使用的神经网络泛化策略是数据增强[24,10]。即便Flying Chairs数据集已经相对很大了,我们发现采用增强仍然对于避免过拟合很重要。我们再网络训练期间在线地使用增强。我们使用的增强方法包括集和变换:平移、旋转和缩放,以及额外的高斯噪声和亮度、对比度、伽马矫正和颜色方面的变换。为了尽可能更快,这些操作都在GPU上处理。Fig. 5展示理论一些增强的例子。
我们不仅想要提高图片的多样性,同时还有流场的多样性,我们对一对图像提供了同样强的几何变换,但会额外地在两张图像上添加相对的变换。
特定地,我们从图像宽 x x x和 y y y的[-20%,20%]中抽样平移;从[-17°,17°]中抽样旋转;从[0.9,2.0]抽样缩放。高斯噪声的 σ \sigma σ从[0,0.04]中均匀抽样;对比度从[-0.8,0.4]中抽样;对于RGB通道的乘色变换(multiplicative color,不太清楚什么意思,每个通道乘以不同比例?)从[0.5,2]中抽样;伽马值从[0.7,1.5]中抽样并且用 σ \sigma σ为0.2的高斯变换进行额外的亮度变化。
5. Experiments
我们在Sintel、KITTI和Middlebury以及我们的合成的Flying Chairs数据集上报告了我们的网络的结果。我们也在Sintel数据上进行了网络微调实验以及预测光流场的变分细化。此外,我们报告了与其他网络相比,我们的网络的运行时间。
5.1 网络和训练细节
我们训练的网络的确切结构在Fig. 2中展示了。总的来说,我们试图保持不同网络的架构一致:它们有9层卷积层,其中6层步幅为2(用最简单的池化层实现的),在每一层之后又一个ReLU非线性函数。我们没有任务全连接层,这样输入图像的尺寸可以是任意的。随着网络层数的深入,卷积核的尺寸是逐渐变小的:第一层为7x7,随后两层为5x5,从第四层开始是3x3.输出的特征图的通道数在更深的层中有逐渐增加,大约在每个步幅为2的层后会翻倍。对于FlowNetC中的关联层(correlation layer),我们选择参数 k = 0 , d = 20 , s 1 = 1 , s 2 = 2 k=0,d=20,s_1=1,s_2=2 k=0,d=20,s1=1,s2=2。训练误差我们采用了endpoint error(EPE),这是一种标准的光流估计测量误差。它表示的是预测光流向量和真实光流向量之间的欧式距离,在所有像素中的平均值。
为了训练CNNs,我们用了一个caffe[20]修改版本。我们选择Adam[22]作为优化算法,因为我们的任务在Adam上比在带有动量的SGD上收敛更快。我们固定Adam的参数为推荐值[22]: β 1 = 0.9 \beta_1=0.9 β1=0.9和 β 2 = 0.999 \beta_2=0.999 β2=0.999。因为某种意义上将,每个像素都是一个训练样本,所以我们采用了相对小的8对图像一个mini-batches。我们一开始采用 λ = 1 e − 4 \lambda=1e-4 λ=1e−4的学习率然后在300k次迭代后每100k次迭代后将它除以2。在FlownetCorr中, λ = 1 e − 4 \lambda=1e-4 λ=1e−4导致了梯度爆炸。为了解决这个问题,我们一开始训练采用了一个比较小的学习率 λ = 1 e − 6 \lambda=1e-6 λ=1e−6,然后在10k次迭代后慢慢提升它为 λ = 1 e − 4 \lambda=1e-4 λ=1e−4,之后按照上面提到的方案进行。
为了检测训练和微调时的过拟合,我们将Flying chairs数据集分成训练集样本22232和测试集样本640;Sintel分为训练集样本908和验证集样本133.
我们发现在测试的时候提高输入图片的分辨率有助于提升表现。虽然最好的放大比例取决于具体的数据集,但是我们为网络固定一个放大比例用来应付所以任务。对于FlowNetS我们并没有放大,对于FlowNetC我们选择因子为1.25.
Fine-tuning 微调
5.2 实验结果
Sintel
KITTI
Flying Chairs
Timings
5.3 分析Analysis
这个环节和结果有什么区别
Training data
Comparing the architectures
6. 结论Conclusion
Note
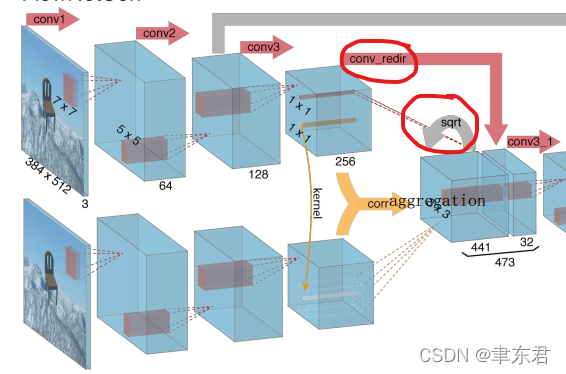
值得注意的是,我看很少人讨论过这里,就是在FlowNetCorr中,有conv_redir和sqrt两个步骤,但在论文中没有进行说明,我在github中查到了相关讨论,比较有道理。

简而言之,关联层本身主要是输出了两个输入图像的关联信息,而对图像原信息的保留比较少,因此在这里用conv_redir对第一张图像的特征图做一次卷积,把通道由256维压缩到32维,然后拼接到关联层输出的特征图后面。这里压缩到32维而不是直接拼接256维,我想是因为直接拼接后通道数太多,并且网络中关联信息是比原图信息重要很多的,因此压缩一下通道数也无妨。

我想sqrt操作是只对输出的前441个通道做的,因为这441个通道的值都是内积,做个开方能够得到模。至于为什么模才能发挥作用,可能是为了保持信息都是以像素为单位的吧,不开方就变成像素
2
^2
2了,不好和后面的拼接,我猜的⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄。
Appendix
<1> 评估指标
光流估计常用的评估指标有angular error(AE)和endpoint error(EPE)。假设某个像素的GT光流向量为 ( u 0 , v o ) (u_0,v_o) (u0,vo),估计的光流向量为 ( u 1 , v 1 ) (u_1,v_1) (u1,v1),则:
AE定义如下,意为俩向量的夹角
A
E
=
a
r
c
c
o
s
(
(
u
o
,
v
o
)
⋅
(
u
1
,
v
1
)
)
AE = arccos((u_o,v_o)\cdot(u_1,v_1))
AE=arccos((uo,vo)⋅(u1,v1))
EPE定义如下,意为俩向量末端距离
E
P
E
=
(
u
0
−
u
1
)
2
+
(
v
0
−
v
1
)
2
EPE=\sqrt{(u_0-u_1)^2+(v_0-v_1)^2}
EPE=(u0−u1)2+(v0−v1)2
<2> visualize optical flow 可视化光流
估计的光流向量可以表示为
(
u
,
v
)
(u,v)
(u,v),分别表示
x
x
x和
y
y
y方向上的偏移。我们可以把它转化为极坐标的形式
(
θ
,
ρ
)
(\theta,\rho)
(θ,ρ)。每个极坐标对应一种颜色,可以在下图找到。
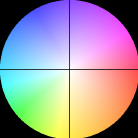
实际上,该图是用色调(hue)表示
θ
\theta
θ,用饱和度(saturation)表示
ρ
\rho
ρ,亮度则调到最大,便于观察。这种可视化方式既方便观看,又非常好看⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄。
Reference:
【1】https://github.com/philferriere/tfoptflow/blob/master/README.md
问题
Faster-RCNN中数据增强用在哪个步骤上
小卷积的情况,卷积核池化层的配合
池化层的作用:
降采样、上采样,FCN,Pooling,现在还是用Pooling?
卷积核大小对感受野和效果的影响
resnet:瓶颈层
logistic回归
corr运算 支路(U-net、DenseNet)
学习率降低
验证集避免过拟合
batch的设置()















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









