






jmeter环境搭建:
(1)安装JDK
下载(注意选择操作系统对应的位数32/64)
我这里是安装的1.8的
安装(一键式)
配置环境变量
电脑-属性-高级系统设置
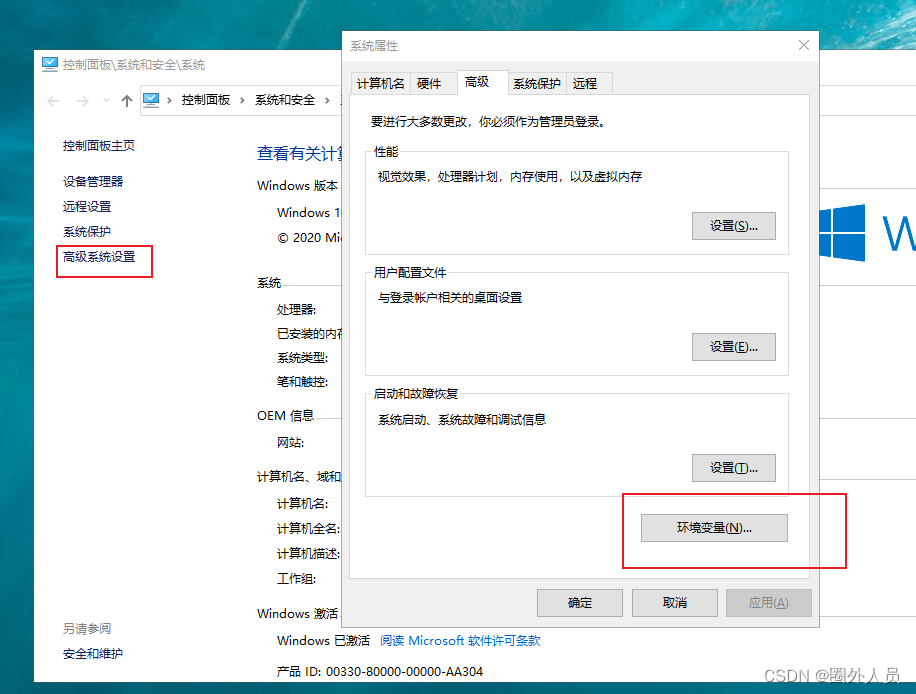
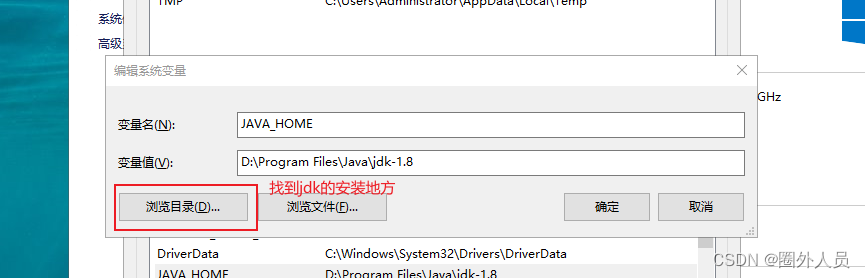
添加JAVA_HOME
然后添加Path,方便后续命令行窗口直接打开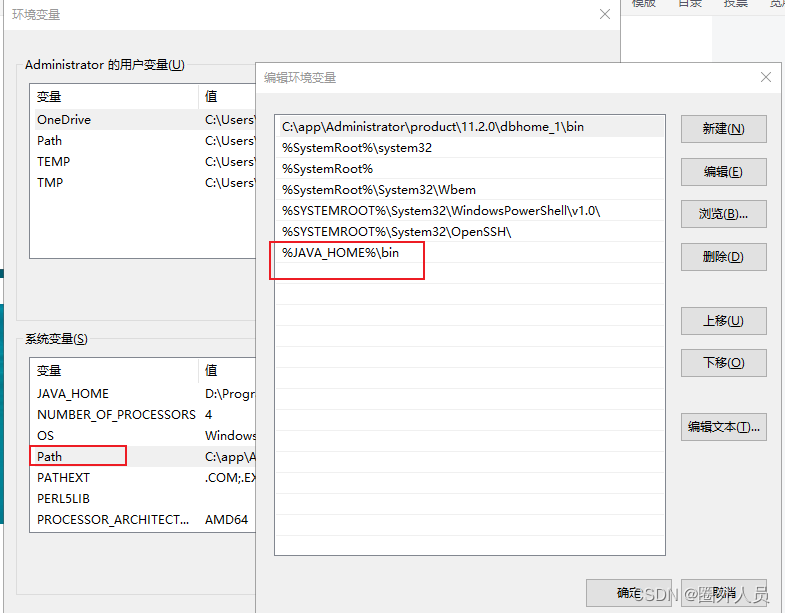
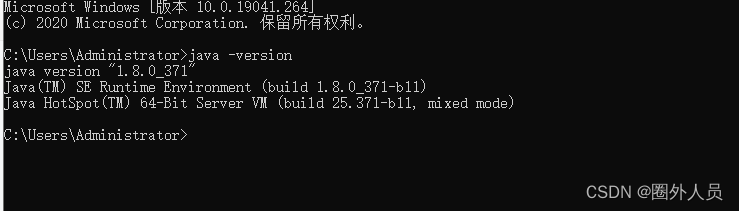
验证:java -version
(2)安装Jmeter
下载(注意下载的版本与JDK版本的对应关系)
安装(解压缩)
配置环境变量
Jmeter启动报错:Not able to find Java executable or version. Please check your Java installation

bat文件可以下载一个notepad++去进行编辑,在jmeter.bat文件最上面添加:
SET JAVA_HOME=D:\Program Files\Java\jdk-1.8
SET PATH=%SystemRoot%/system32;%SystemRoot%;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
添加好后,再次点击jmeter.bat就可以了
修改语言:
临时修改:
 永久修改:
永久修改:

jmeter元件及基本作用域:
基本元件:

取样器:发送请求。类似于自动化中的业务测试语句
逻辑控制器:控制元件执行顺序。类似于自动化中的逻辑控制语句
前置处理器:对发送的请求参数进行预处理。类似于自动化中的参数化。
后置处理器:对收到的响应数据进行处理。类似于自动化中获得对应的测试结果。
定时器:等待一定时间。类似于自动化中的sleep语句
测试片段:封装的脚本,供其他脚本调用。类似于自动化中封装的函数
配置元件:测试前的环境及数据配置。类似于自动化中的初始化动作
监听器:查看测试的结果。类似于自动化中的日志和报告。
作用域的原理:
按照jmeter测试计划的树形结构来定义作用域(有点儿类型python的缩进)
作用域的原则:
- 取样器是jmeter的核心,不作用于其他的组件
- 逻辑控制器,只对子节点起作用
- 对于其他的组件
- 如果父节点是取样器的话,则只对父节点起作用,
- 如果父节点不是取样器的话,则对父节点下的所有组件起作用
Jmeter三个重要组件:
Jmeter的第一个案例:
- 启动Jmeter
- 在“测试计划”下添加“线程组”
- 在“线程组”下添加“HTTP请求”取样器
- 填写“HTTP请求”的相关请求数据
- 在“线程组”下添加“察看结果树”监听器
- 点击“启动”按钮运行,并查看结果
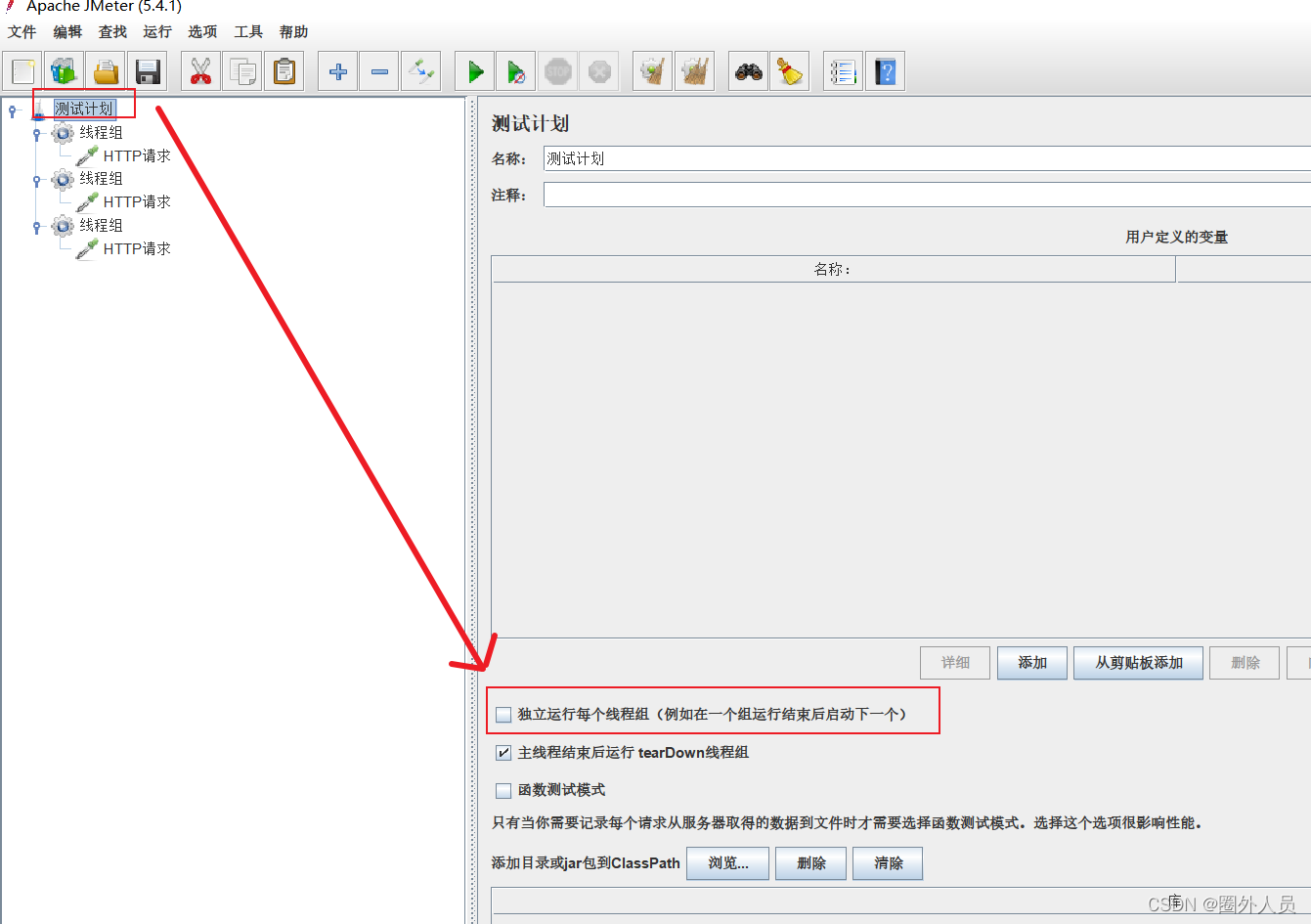
模拟多人操作

- 如果有多个线程组时,可以并行或者串行执行
如下图,“独立运行每个线程组”勾选,则所有的线程组按照添加顺序串行执行;
如果未勾选,则并行执行(先后顺序无法保证)
线程组的分类:
普通线程组:用于发送业务请求的线程组(受并行、串行配置的影响)
setup线程组:在所有的线程组之前执行(不受并行、串行配置的影响)
teardown:在所有的线程组之后执行(不受并行、串行配置的影响)
线程组的属性:
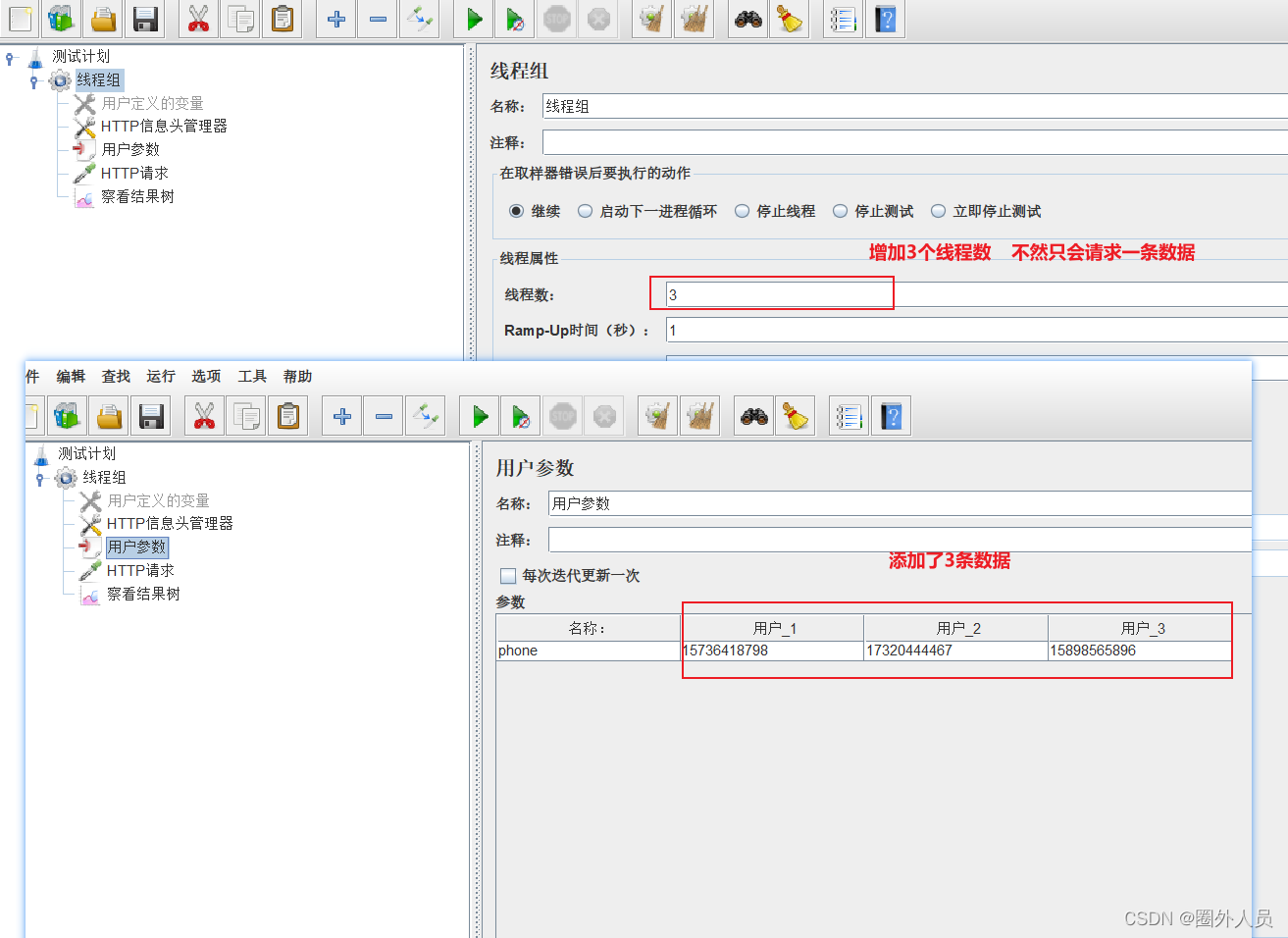
线程数:需要模拟的虚拟用户数。
ramp-up time:模拟的虚拟用户数全部启动所需要的时间。
- 目的:为了模拟性能测试的场景,更接近用户的使用习惯(用户慢慢接入系统)
循环次数:
- 设置为固定次数n时:脚本运行时发送请求的次数为n
- 设置循环次数为“永远”时,脚本会一直运行下去,不停止
调度器:
- 一般与循环次数为“永远”的设置配合使用
- 持续时间设置为n时:脚本的请求发送的时间为n秒
- 延迟启动设置为n时:脚本的请求发送在等待n秒后再进行
延迟创建线程直到需要:当启动线程发送请求时,才分配资源;如果暂未启动该线程,则不分配。如果不勾选,在jmeter点击运行时立即分配(使用不多,了解即可,无法观察效果)
线程数m和循环次数n的关系:
- 如果同时配置,实际发送的HTTP请求数应该为m*n
- 虽然发送请求的次数相同,但是不能相互替换
- 线程数:代表并发用户数,体现服务器的负载
- 循环次数:代表执行时间
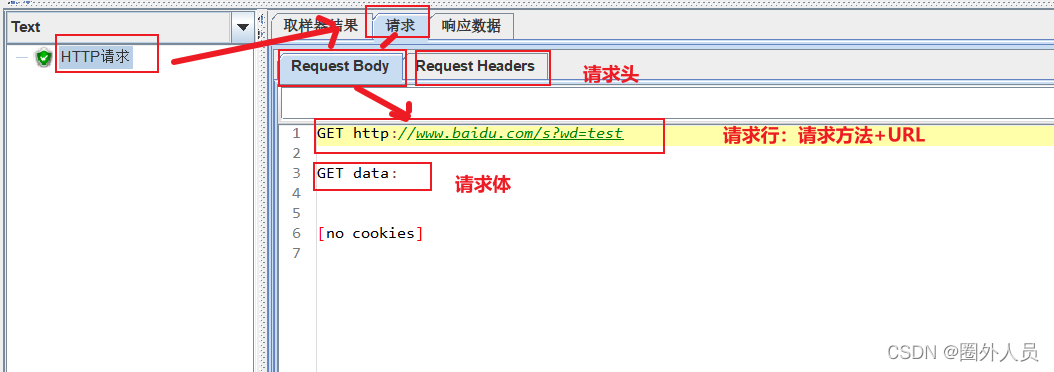
HTTP请求:
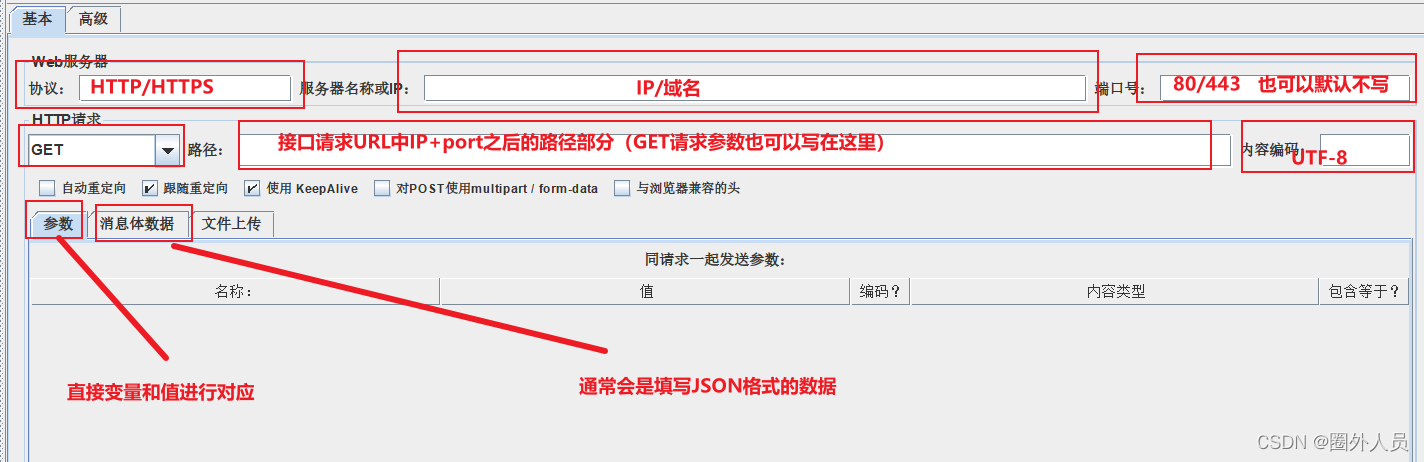
案例1:发送请求时:
- 协议未填写,则默认为HTTP协议
- 端口未填写,则默认为80端口
- 将GET请求参数放在路径中填写
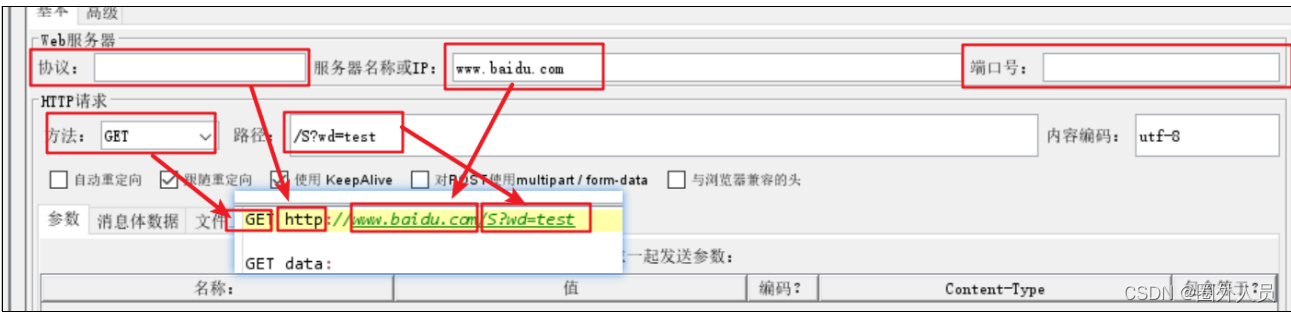
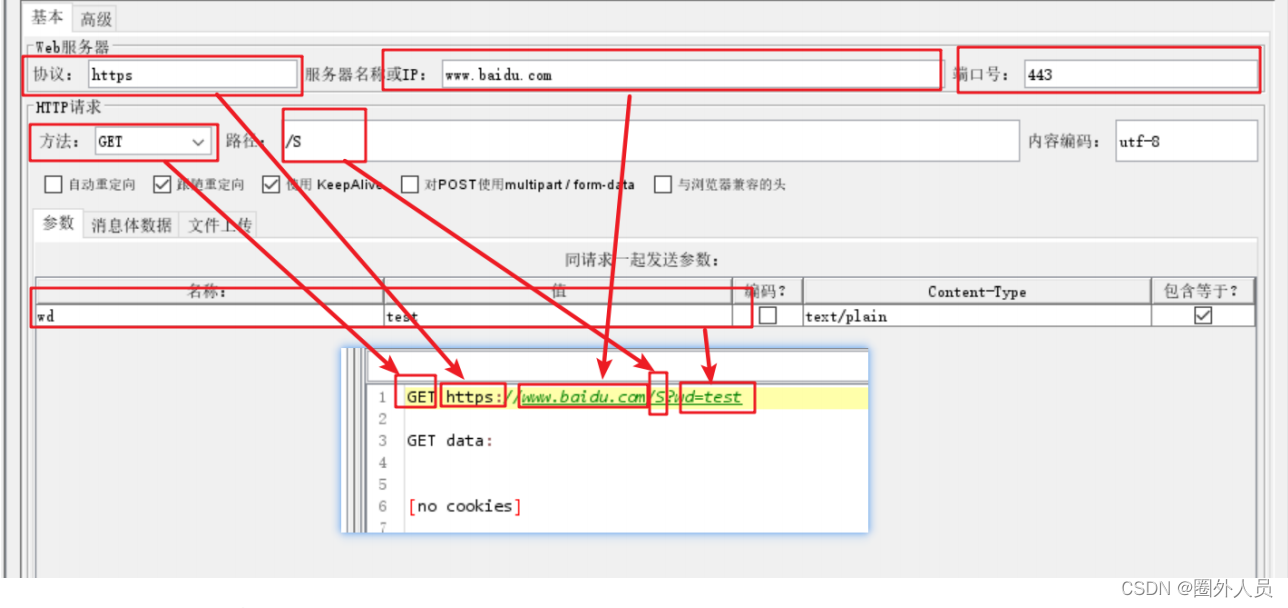
案例2:发送请求时:
- 协议选择HTTPS,
- 端口号为443
- 将GET请求参数放在下面的参数列表中进行填写
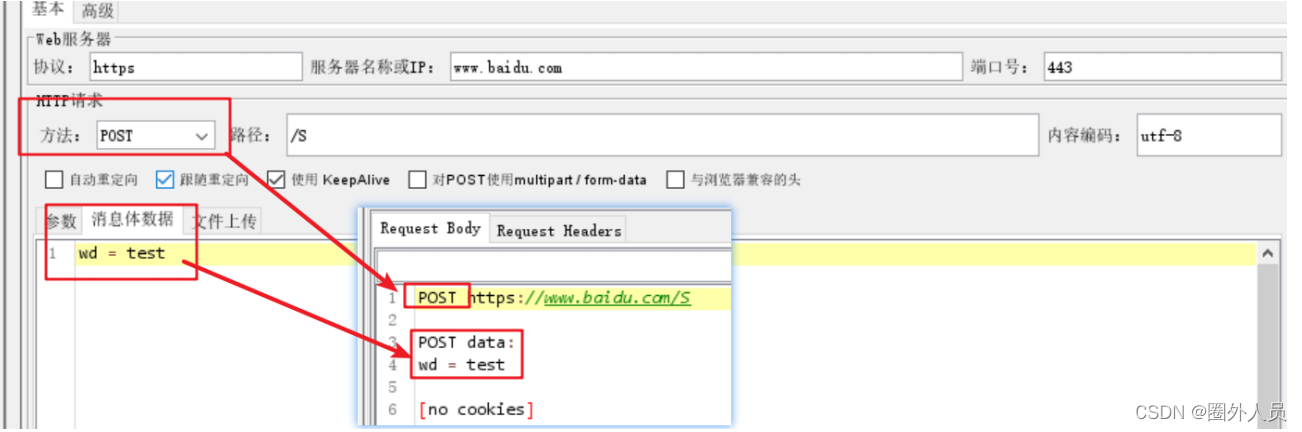
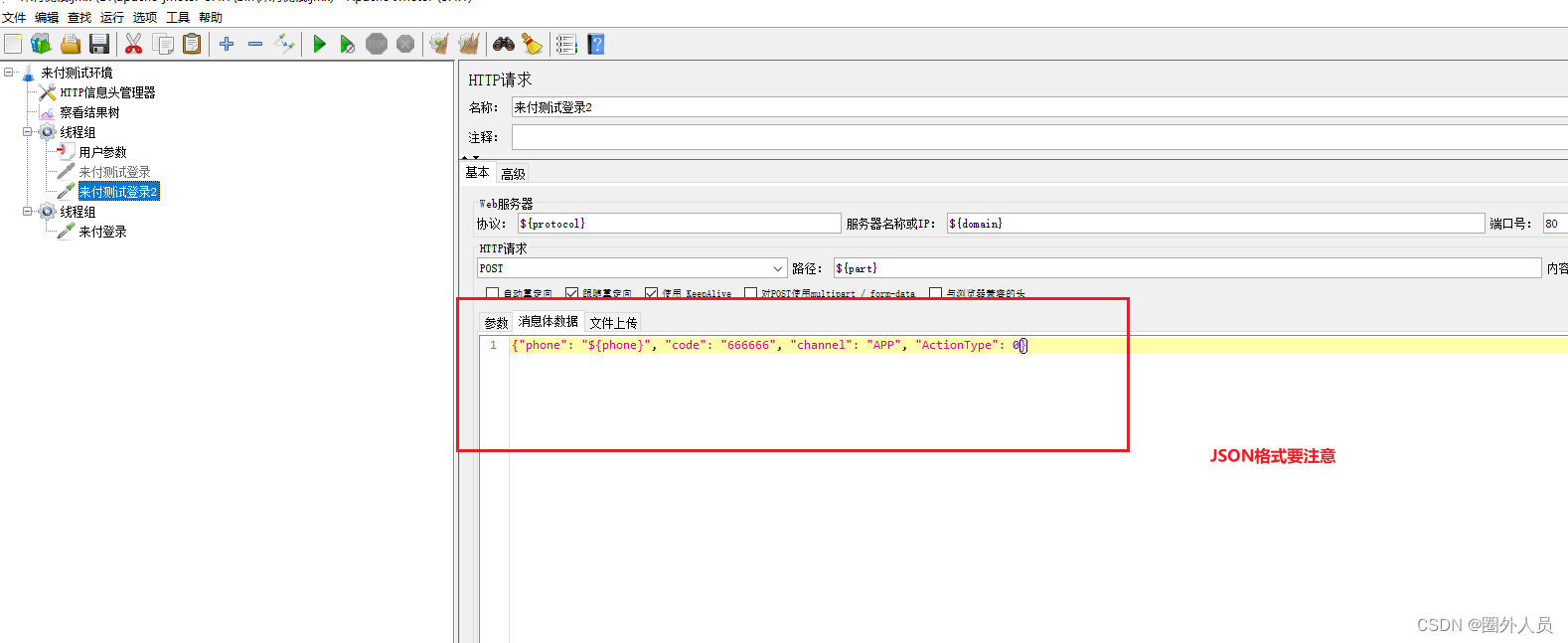
案例3:发送POST请求
- 方法选择POST 将参数内容放入到消息体数据中
- 在发送时参数会添加到请求体中发送
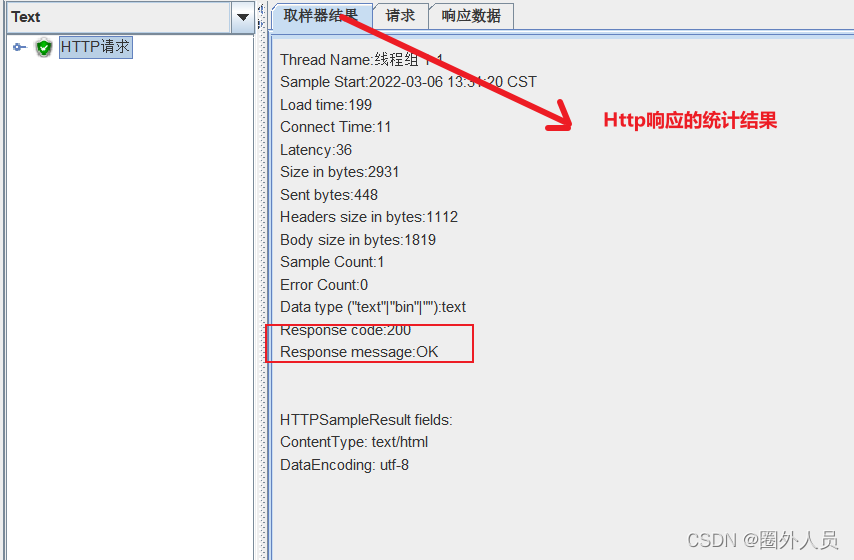
查看结果树:
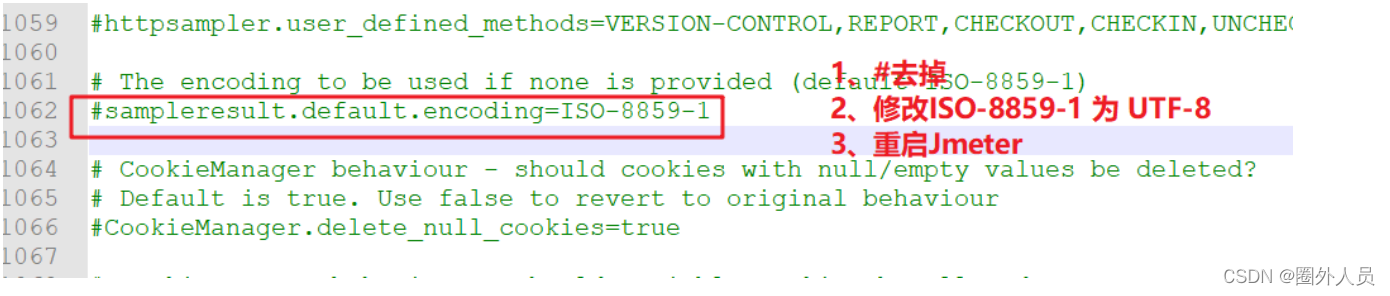
jmeter响应中出现乱码时:
修改配置文件jmeter.properties(bin目录下)中的内容:
Jmeter参数化
用户定义的变量:
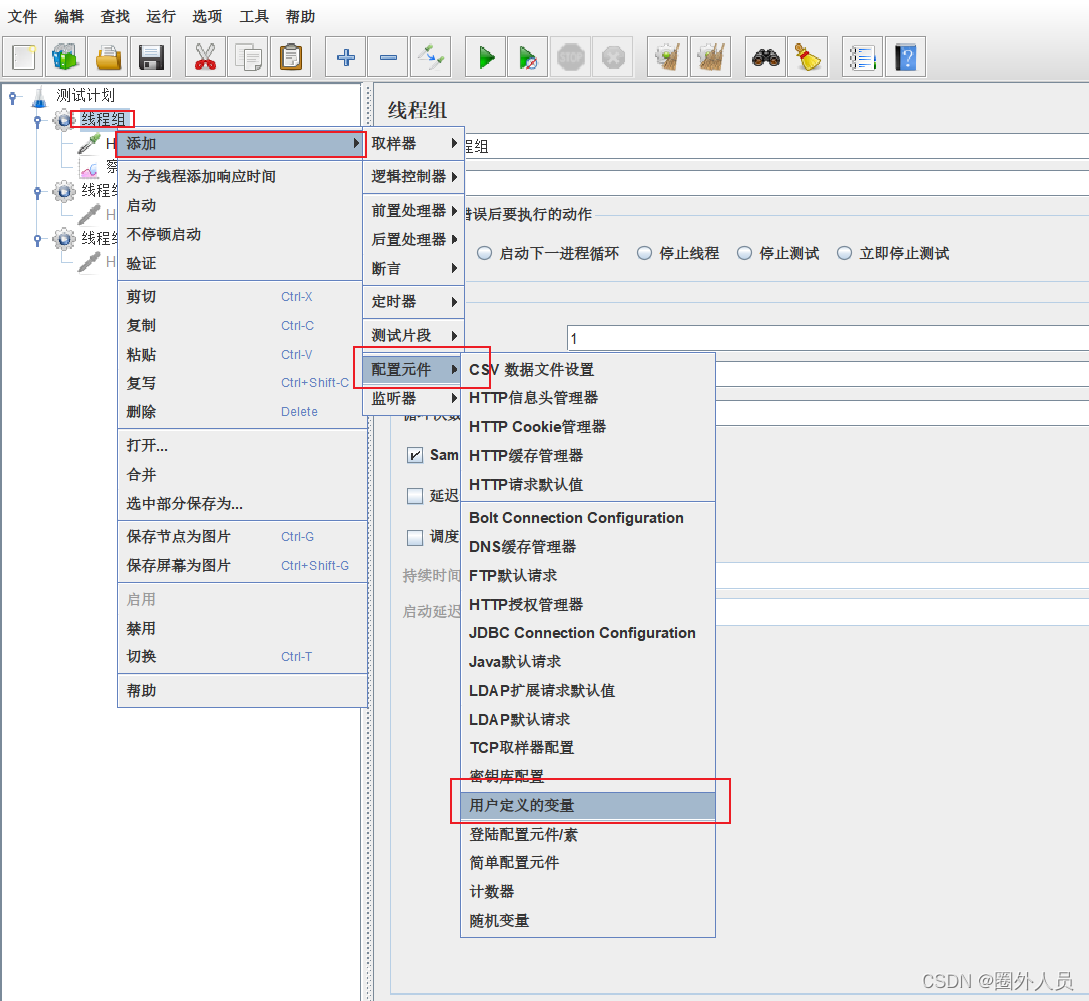
配置方法1:配置元件中配置
- 添加路径:测试计划——线程组——配置元件——用户定义的变量
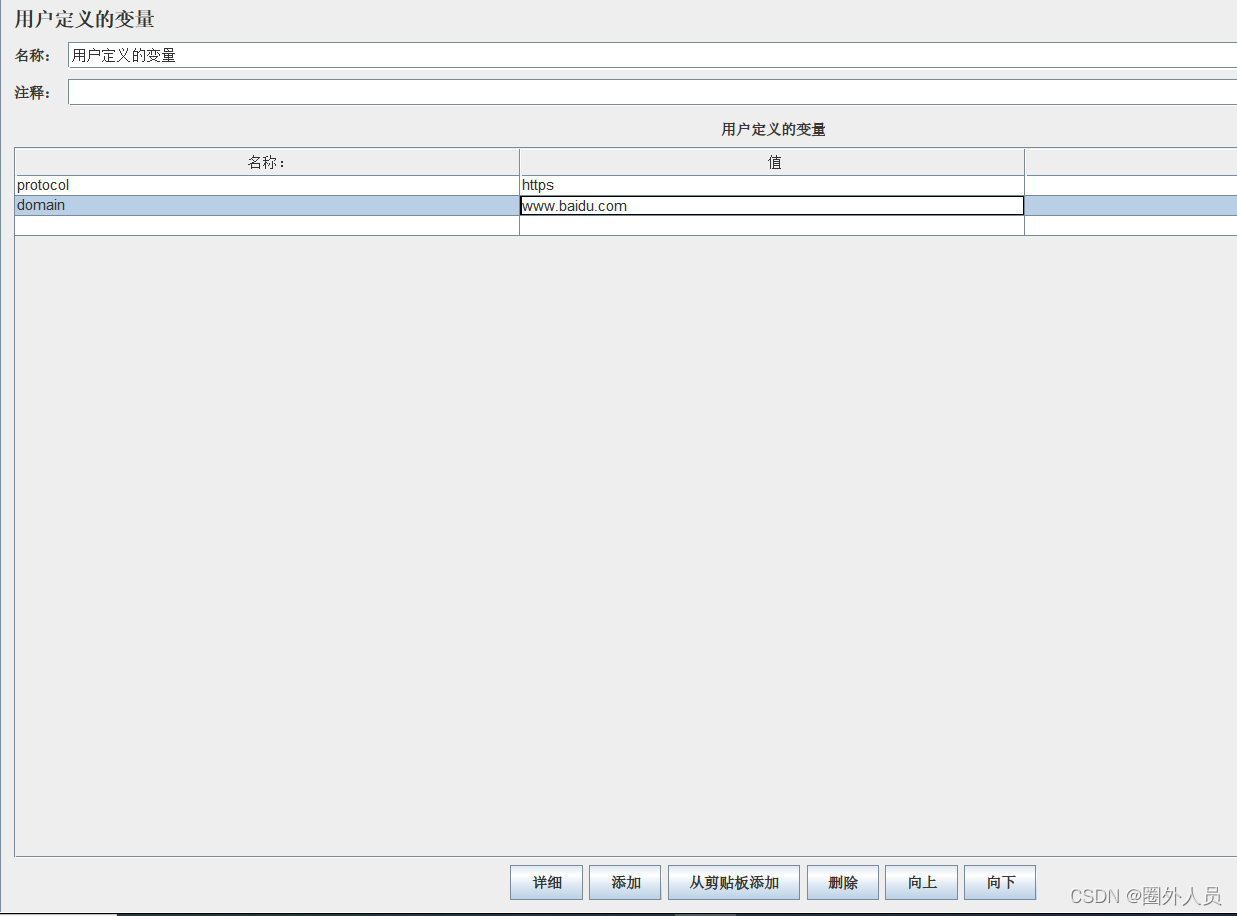
- 参数设置:
- 参数名:参数值
在HTTP取样器中应用:${参数名}
线程组下配置的用户定义的变量,在线程组下生效,与测试计划中配置的变量冲突时,以线程组下的为准
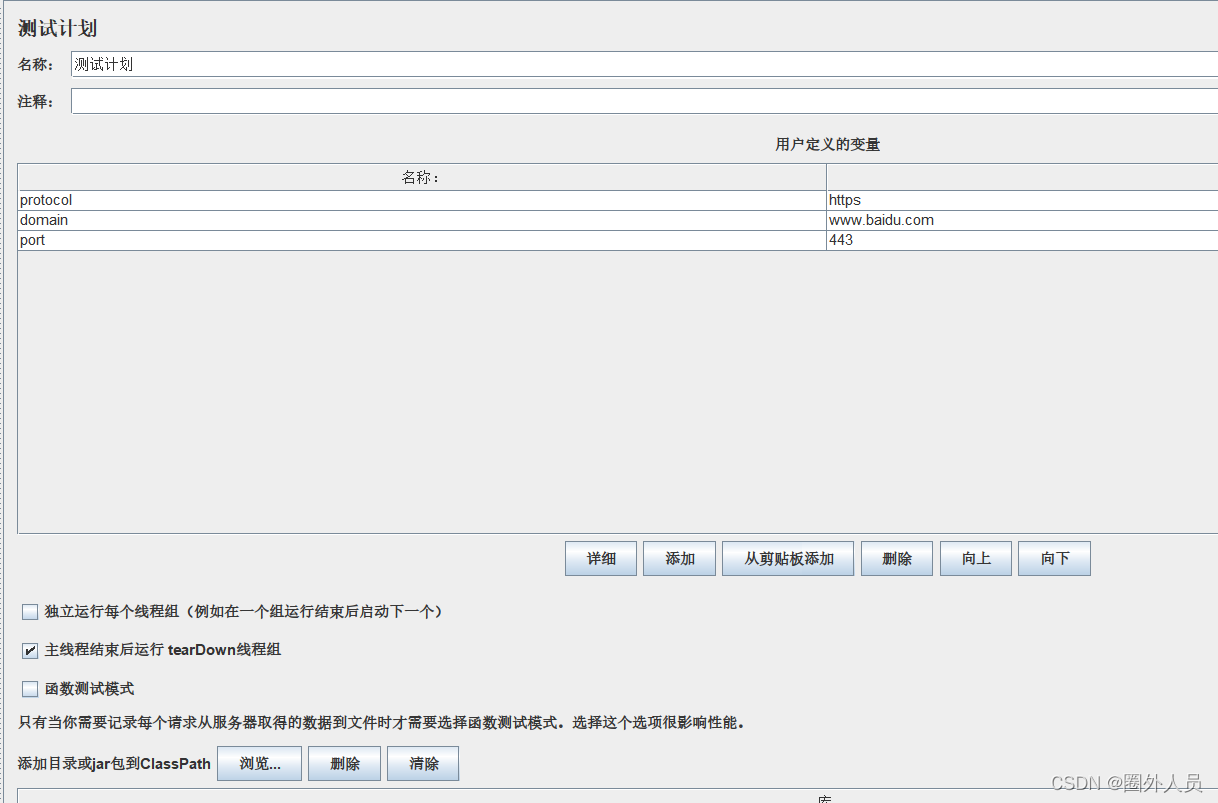
配置方法2:在测试计划中配置(全局生效)
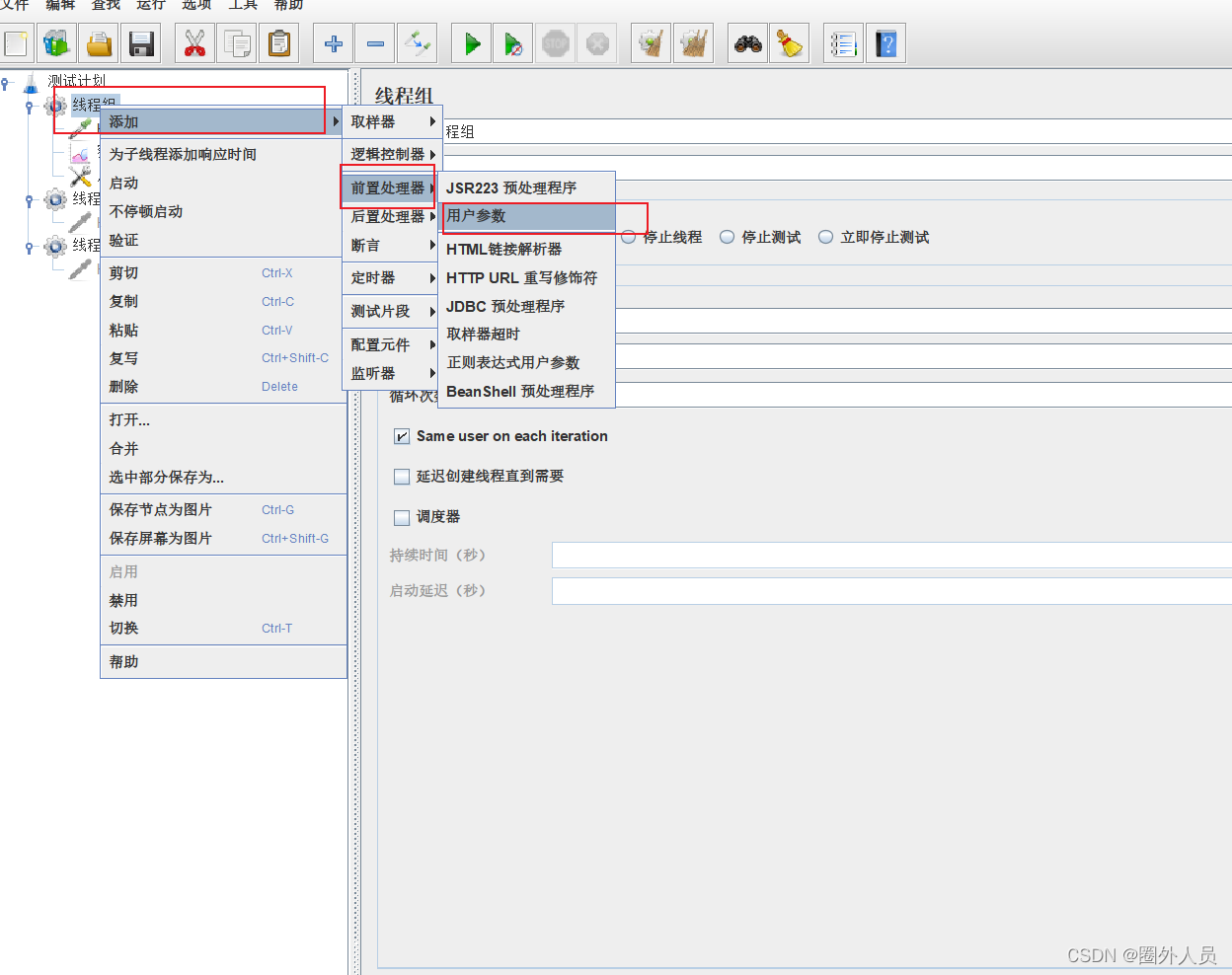
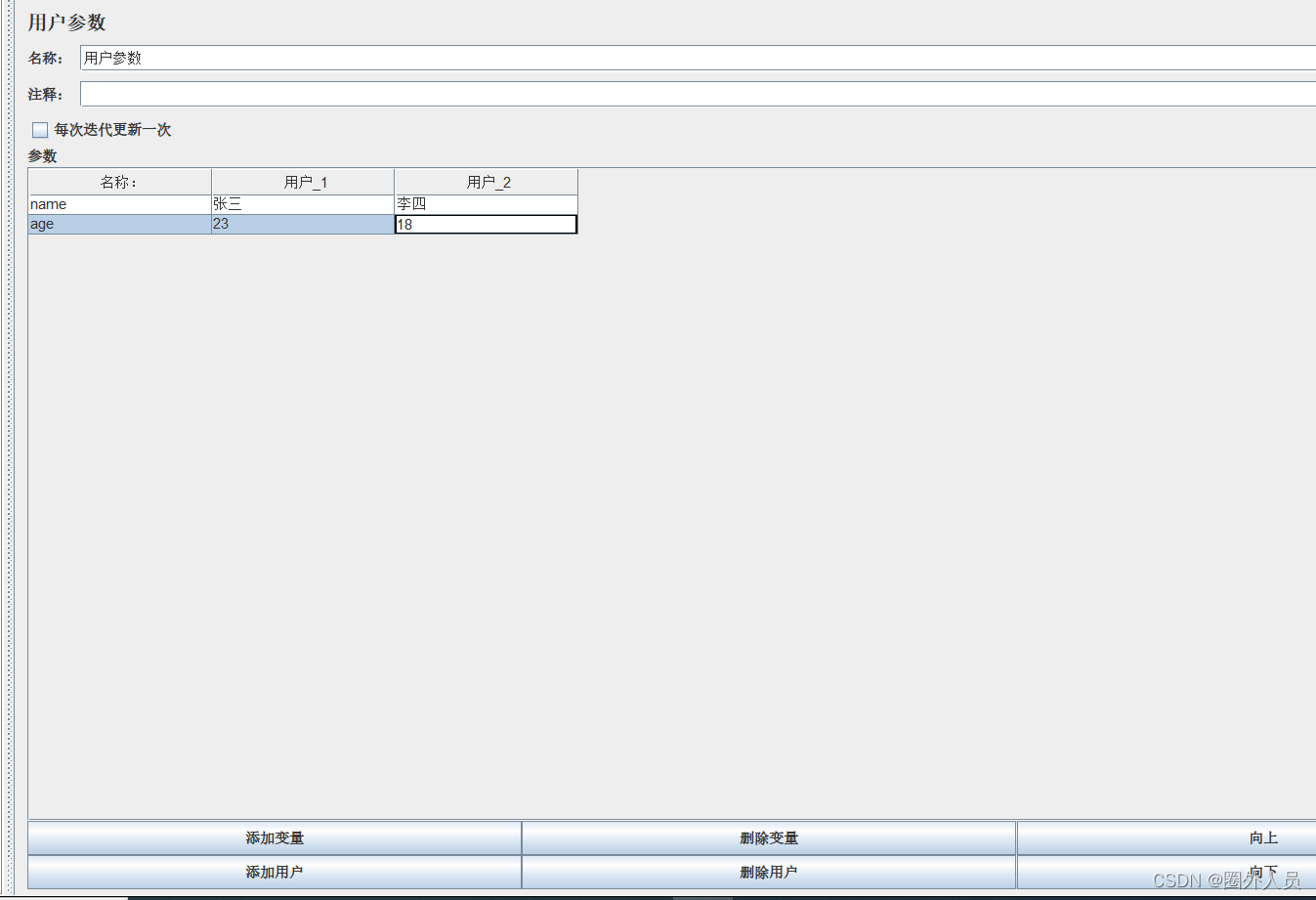
 用户参数:
用户参数:
使用用户定义的变量时,不同的用户在访问时,读取的参数值完全相同,如果希望每个用户在访问时的变量不同,可以使用用户参数。
配置方法:
- 添加位置:线程组——前置处理器——用户参数
- 添加用户:可以添加多组用户
- 添加参数:针对每个用户添加多个参数
CSV数据文件设置:
使用用户参数时,每个用户可以取不同的数据,但是同一用户的多次循环时读取的数据是不变的。如果想让同一用户多次循环读取时的数据也不同,需要使用CSV数据文件设置的方式。
1、定义CSV数据文件

2、添加线程组
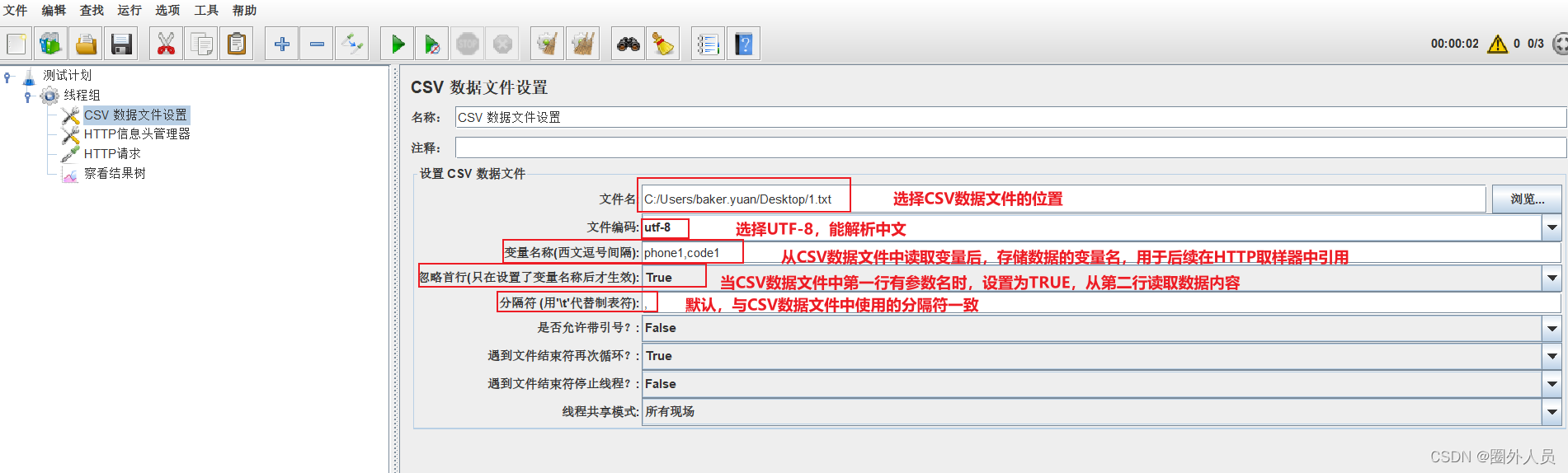
3、配置CSV数据文件设置
- 添加位置:线程组——配置元件——CSV数据文件设置
- 参数配置:
4、添加HTTP请求
引用参数值时,使用时CSV数据文件中定义的变量名
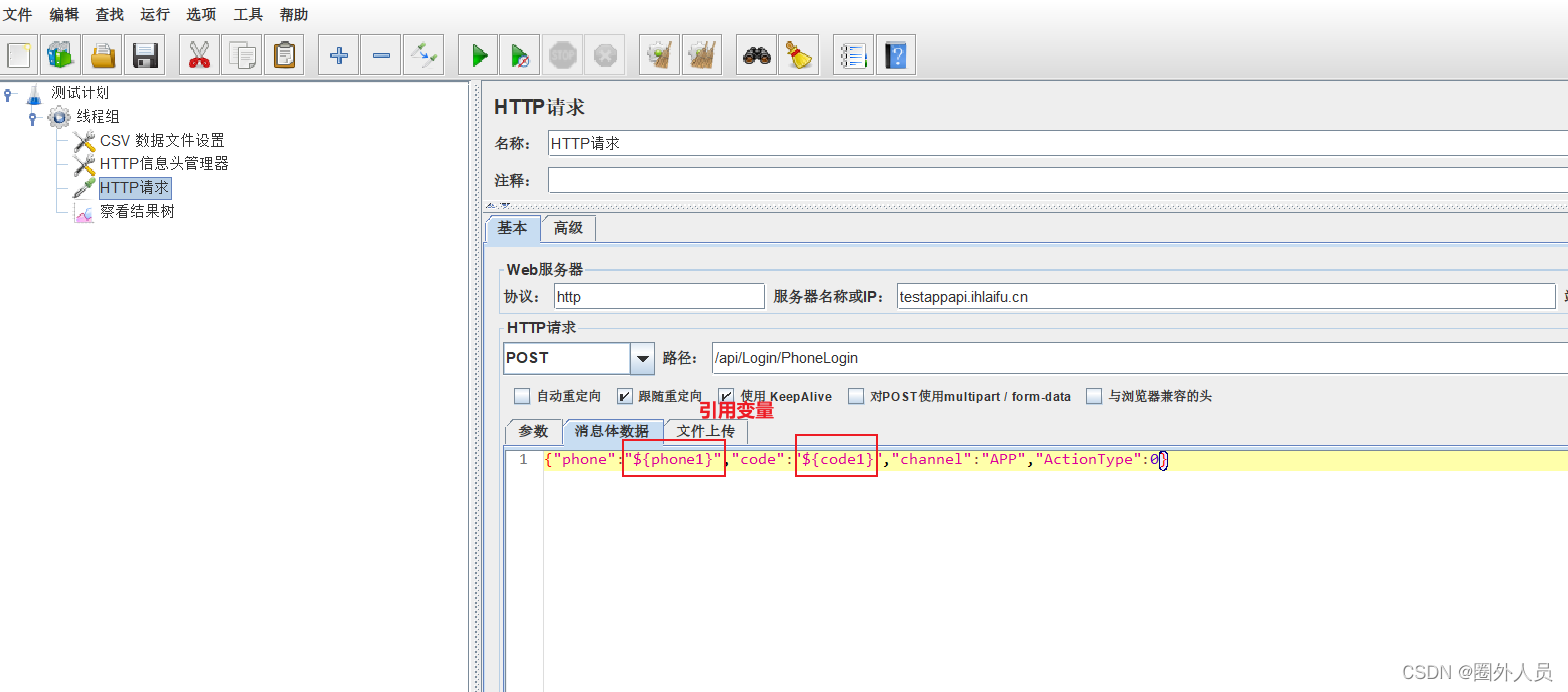
5、查看结果树
函数:
通过counter函数在生成动态变化的数值
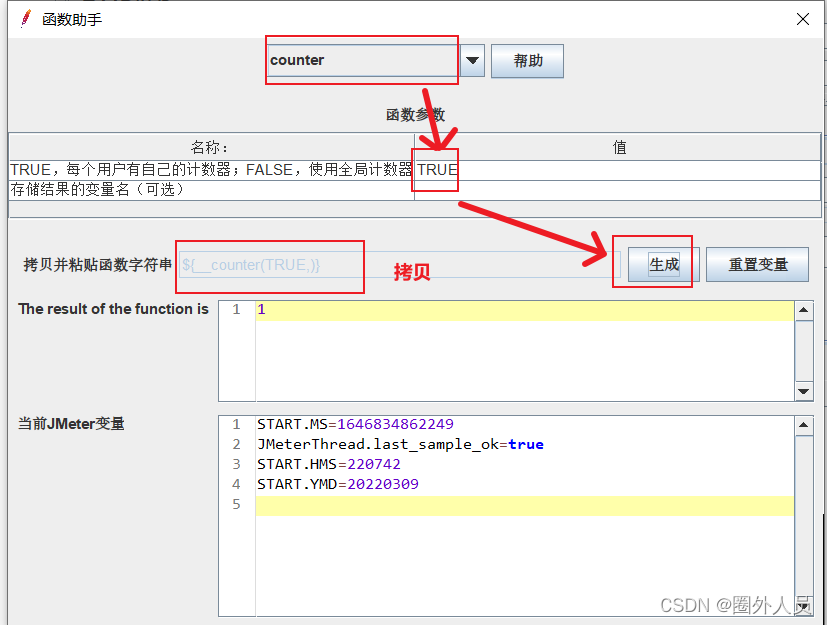
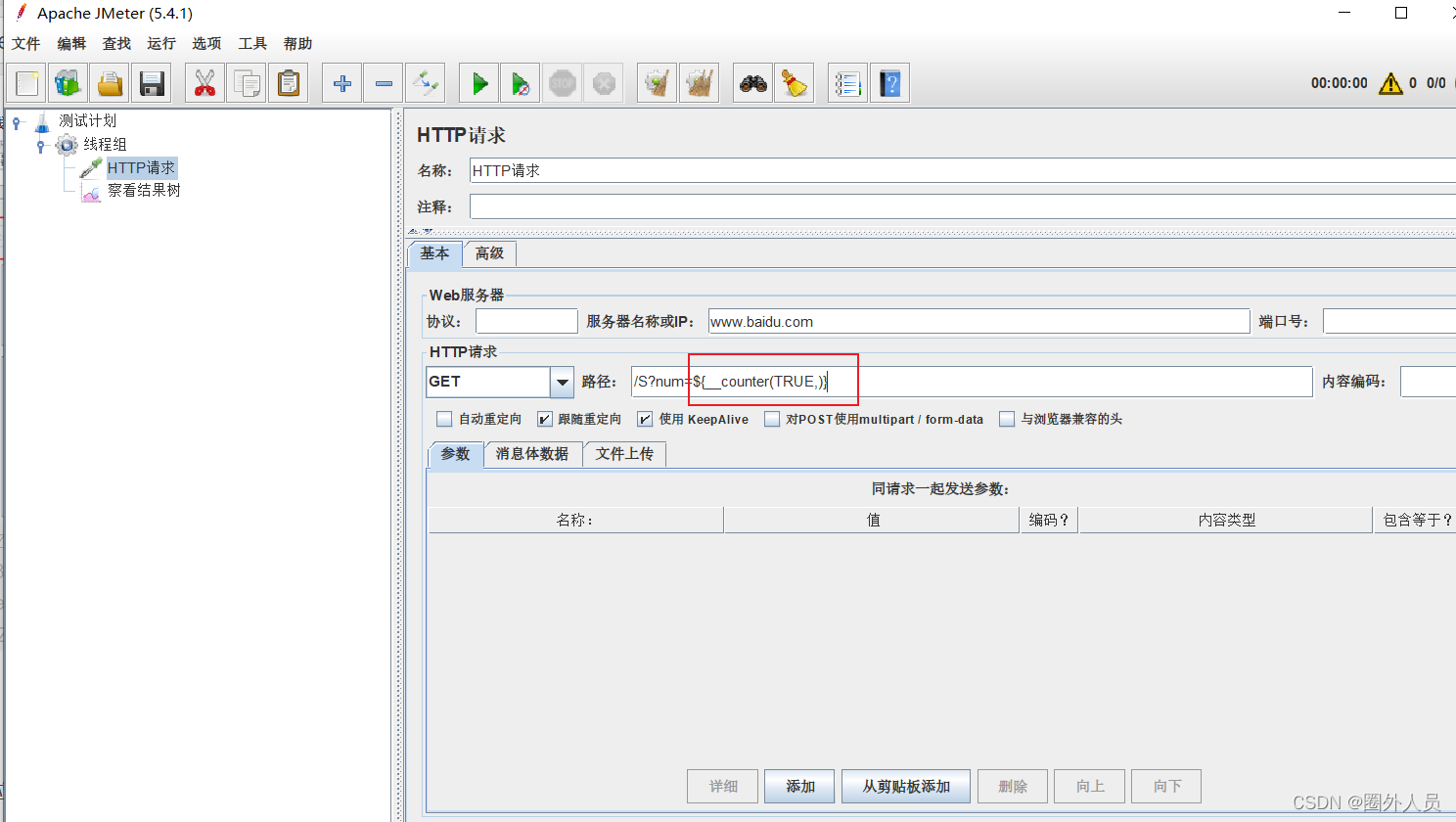
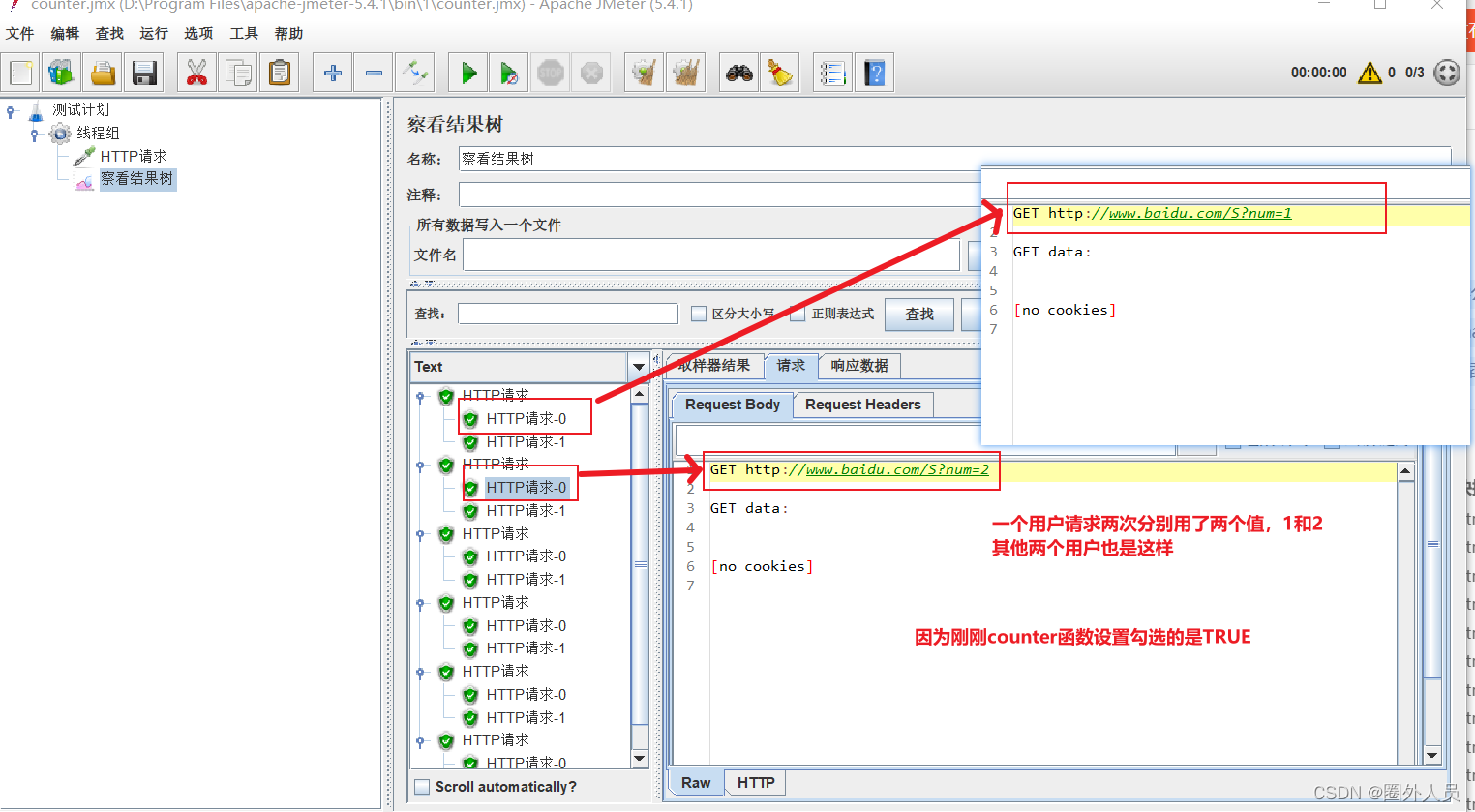
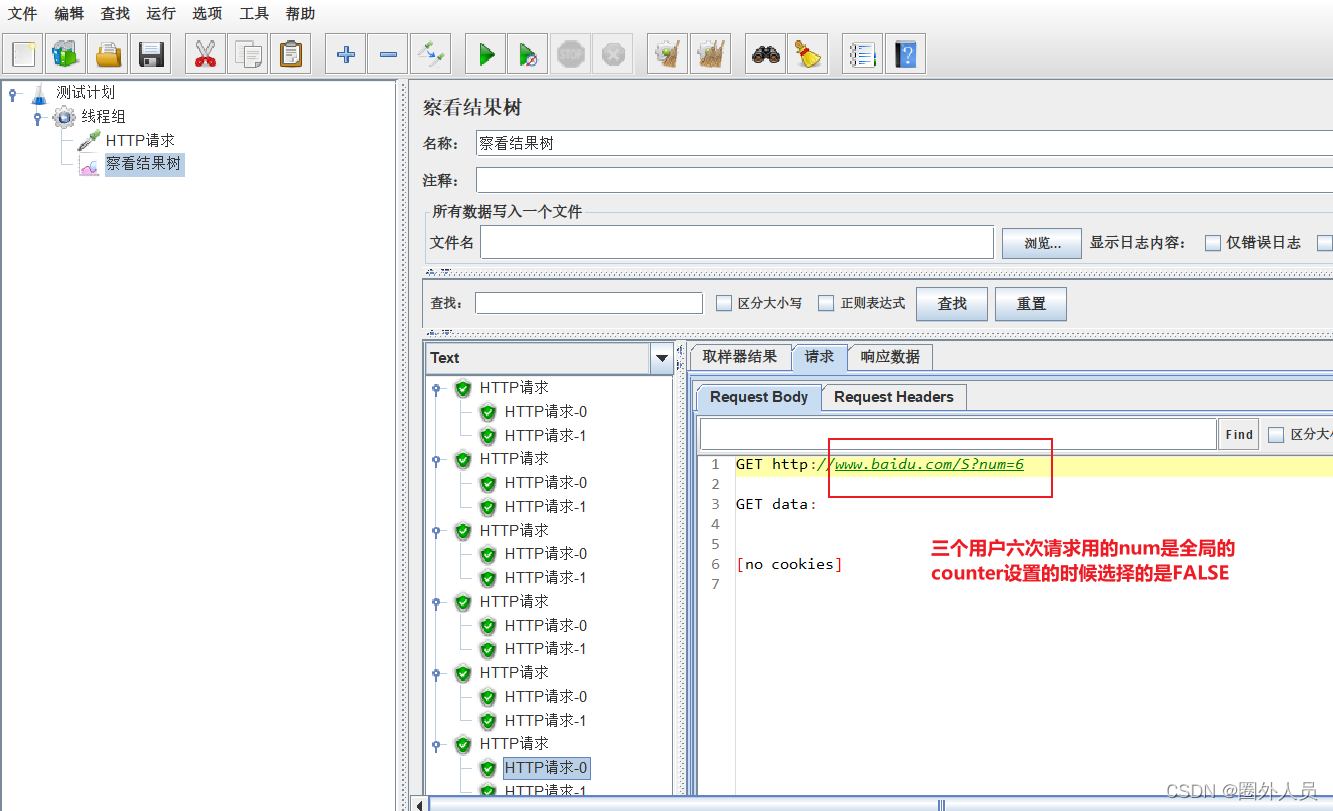
在HTTP取样器中,应用counter函数生成的函数字符串,就可以读取counter函数生成的数值。
- 如果counter参数设置为:TRUE,则每个用户分别从1开始计算,每循环一次加1
- 如果counter参数设置为:FALSE,则所有用户公用一个计数器,每发送一个请求时,取值加1
Jmeter断言:
通过自动化的手段对请求的响应数据进行自动校验
响应断言:
添加:线程组——HTTP取样器——断言——响应断言(断言一定是在HTTP请求的子节点下)
配置介绍:
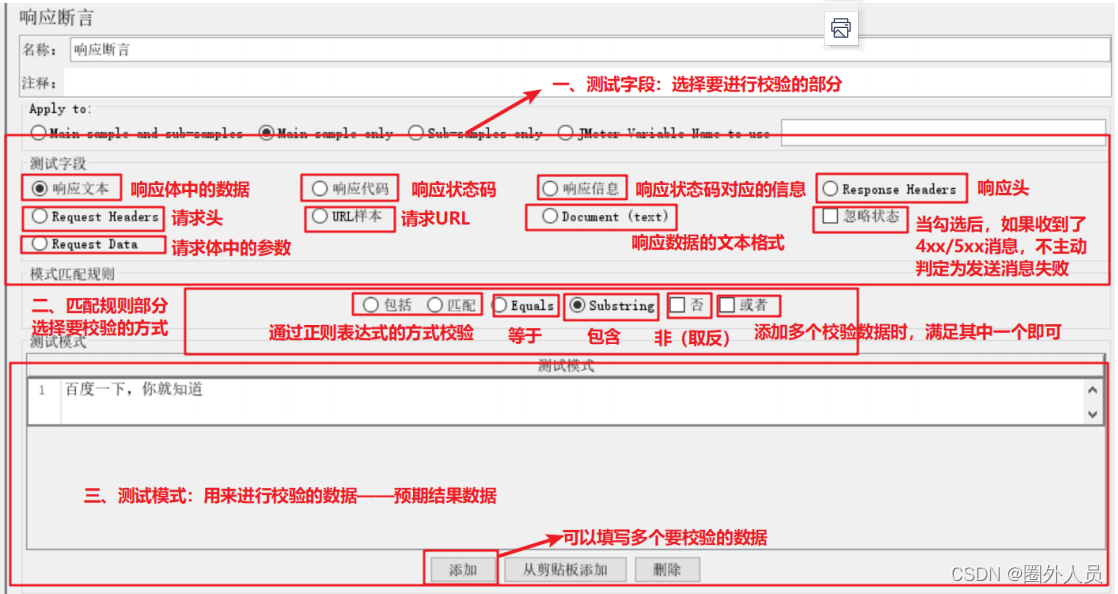
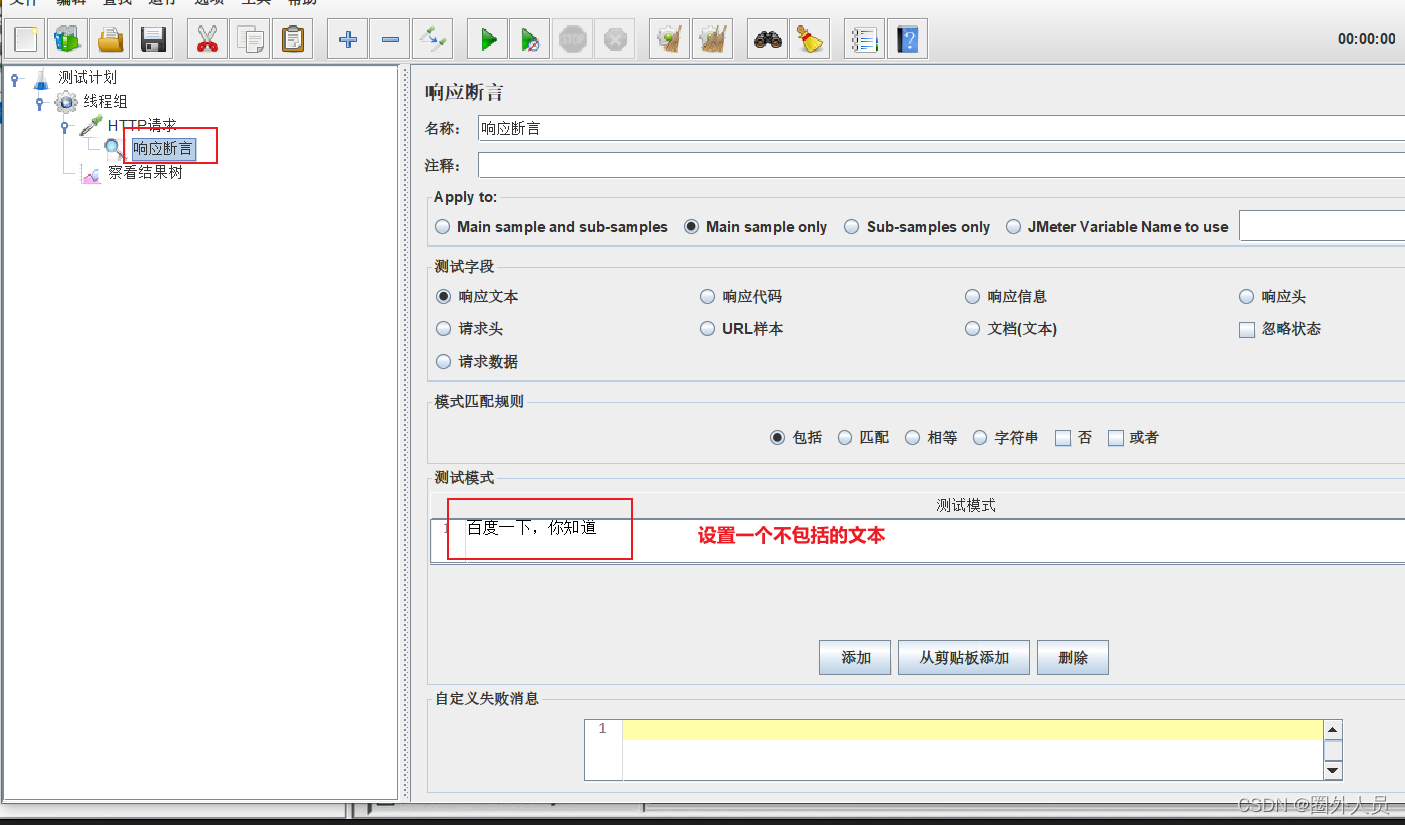
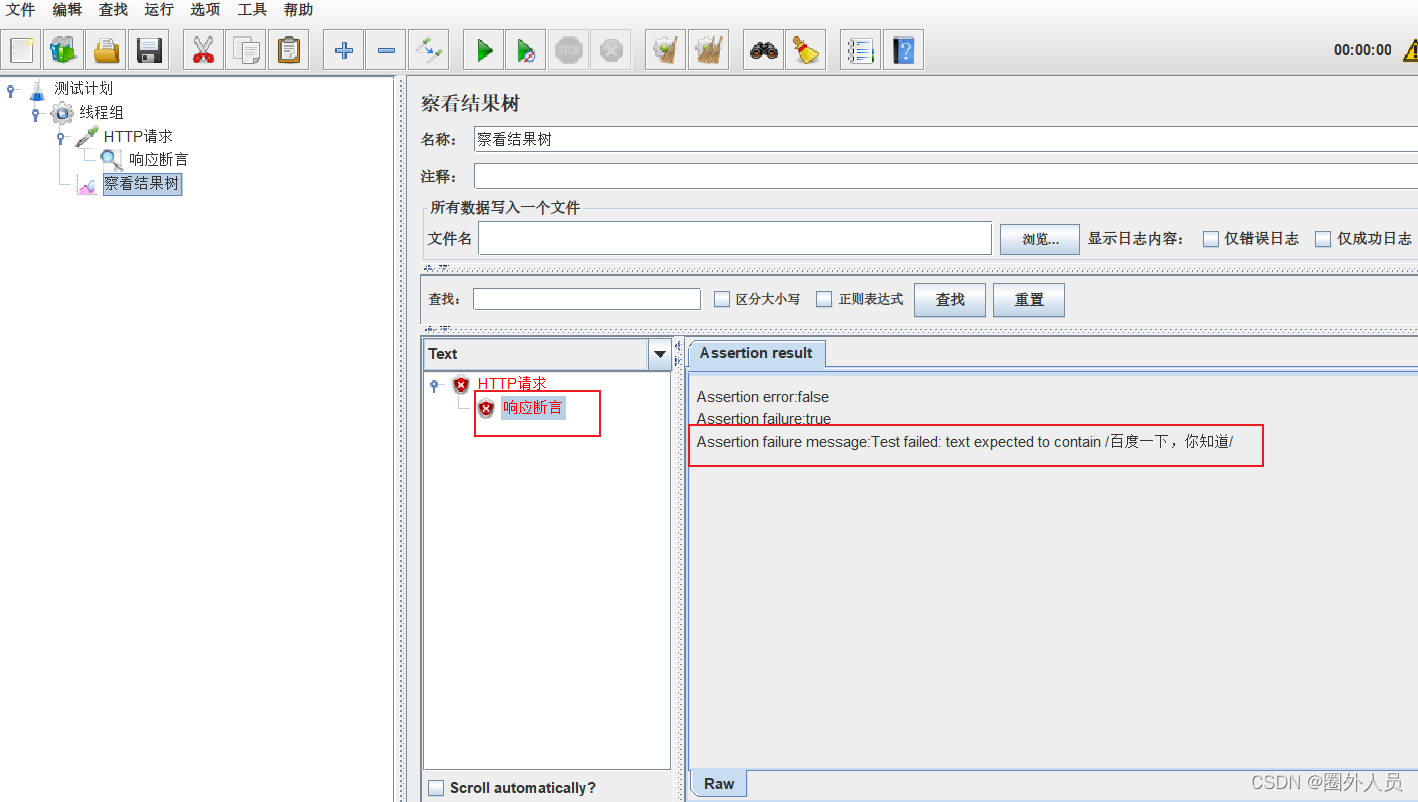
类似于assertEqual(response.json,”success“)
- assertEqual :校验的方式
- response.json:要校验的部分
- success:用来校验的数据
可以在同一个HTTP请求下包含多个响应断言
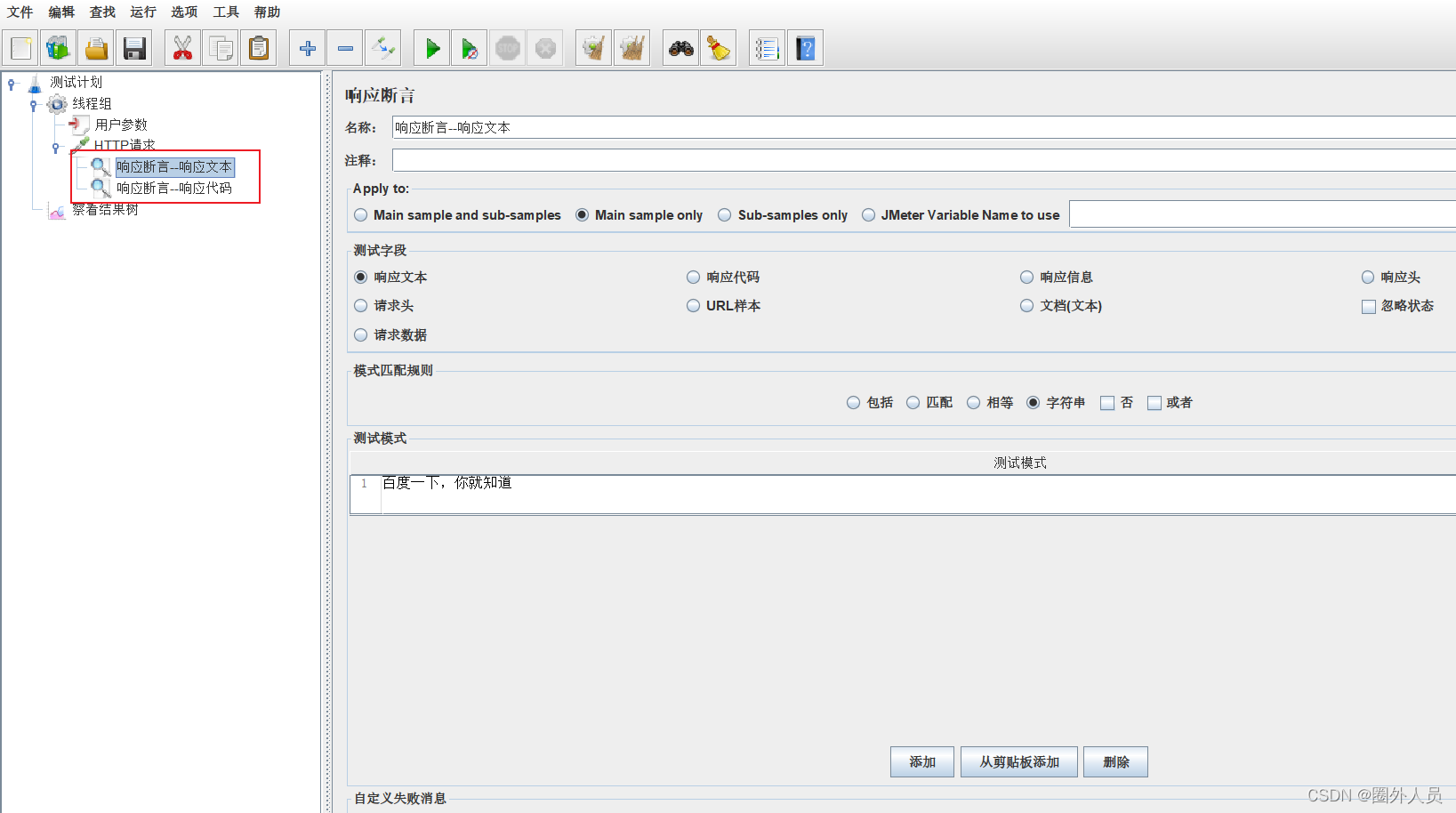
JSON断言:
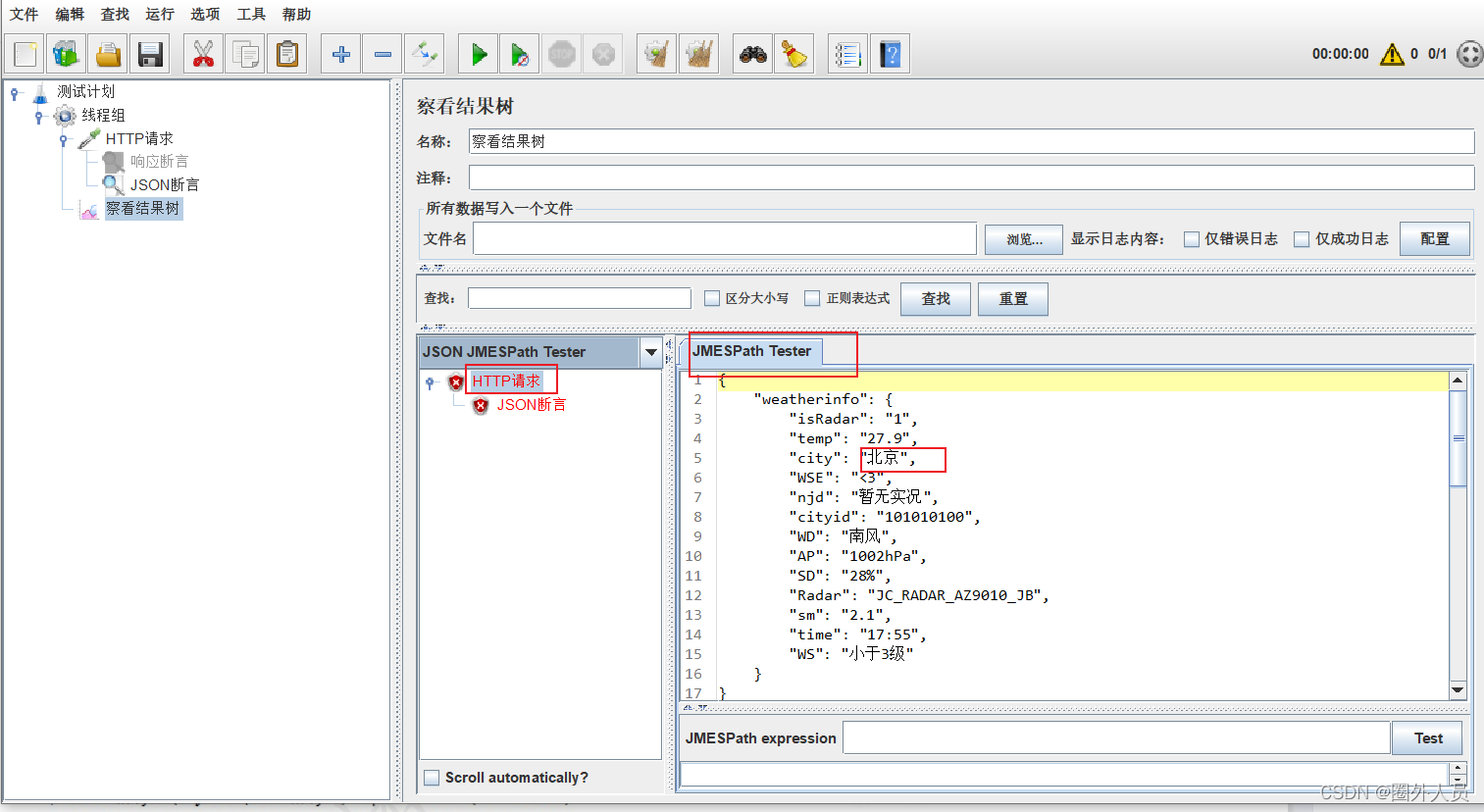
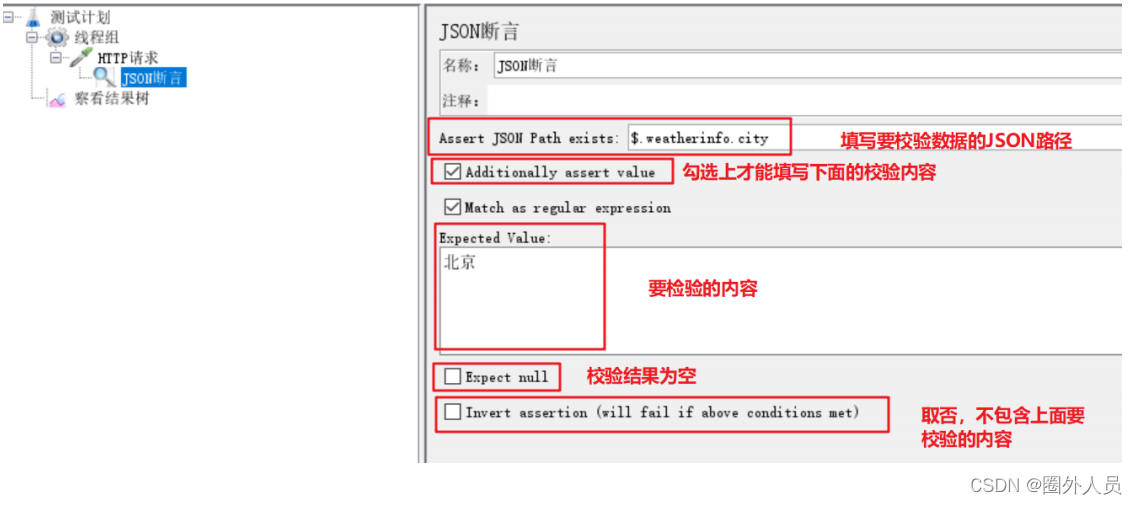
断言持续时间:
客户端发送请求,到收到服务器的响应的时间,要求不超过指定的时间。
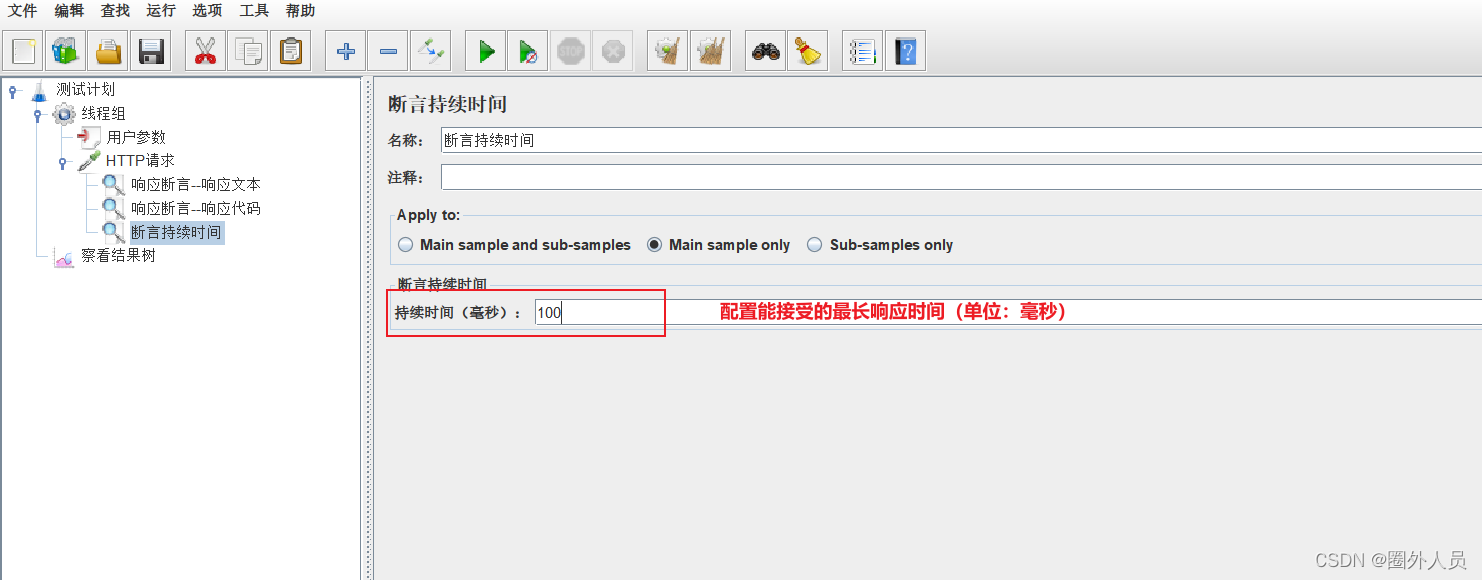
实际时间,是统计的取样器结果中的load time
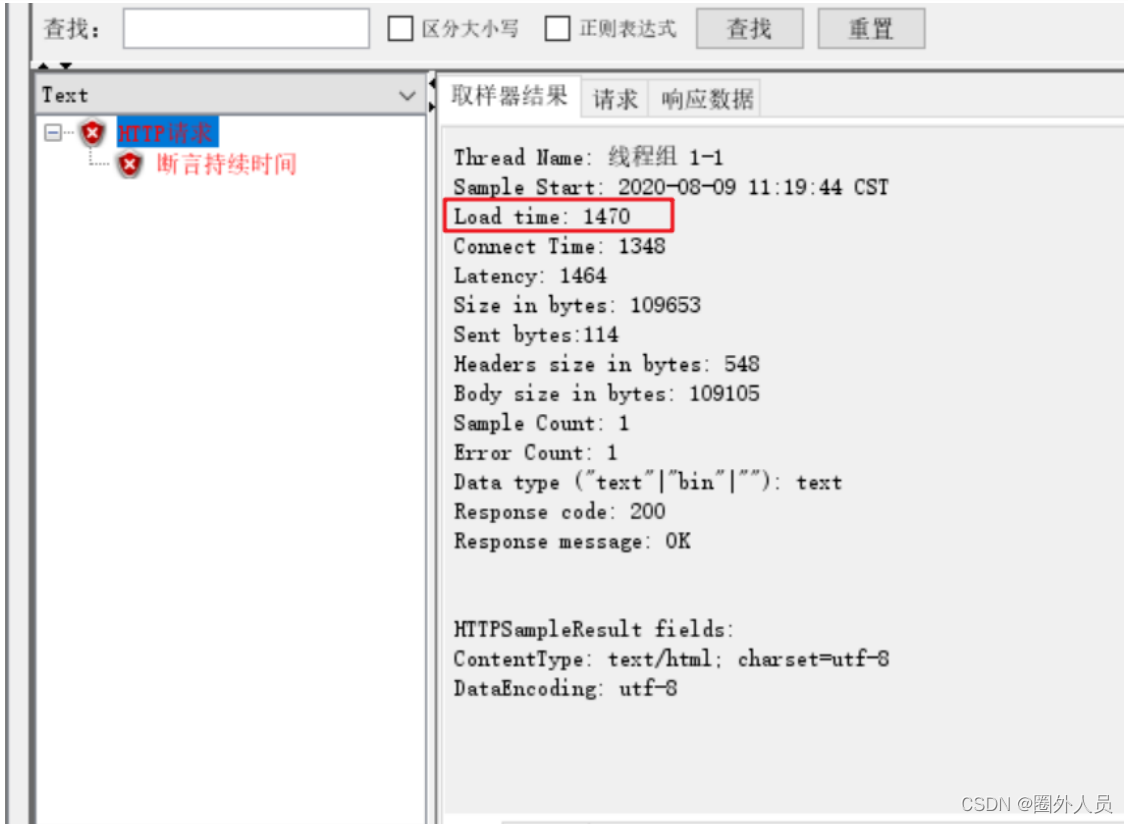
Jmeter关联:
当请求之间有依赖关系,一个请求的入参,需要使用到之前请求的响应数据时,需要使用关联。
 所有提供关联功能的元件都在后置处理器中:
所有提供关联功能的元件都在后置处理器中:
- 正则表达式提取器
- xpath提取器
- JSON提取器
正则表达式介绍:
<title>百度一下,你就知道</title><title>百度一下,你就知道</title> <title>.*?</title> .:是通配符,可以代表任意字符(除换行回车) *: 代表前面的字符出现0次或者多次 .*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来 ?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找 左边界和右边界 左边界(.*?)右边界:可以提取出想要获取的数据内容
正则表达式提取器:
应用场景:正则表达式提取器可以提取任意格式的响应数据
参数介绍:
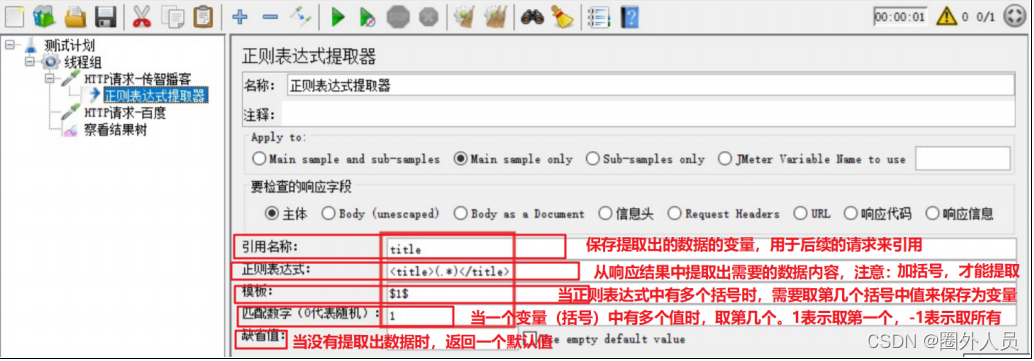
模板:正则表达式可能匹配多组值,通过模板的编写来保存指定的值到变量中

正则表达式提取器的步骤:
1、添加线程组
2、添加HTTP请求 - 传智播客的首页
3、添加正则表达式提取器并配置
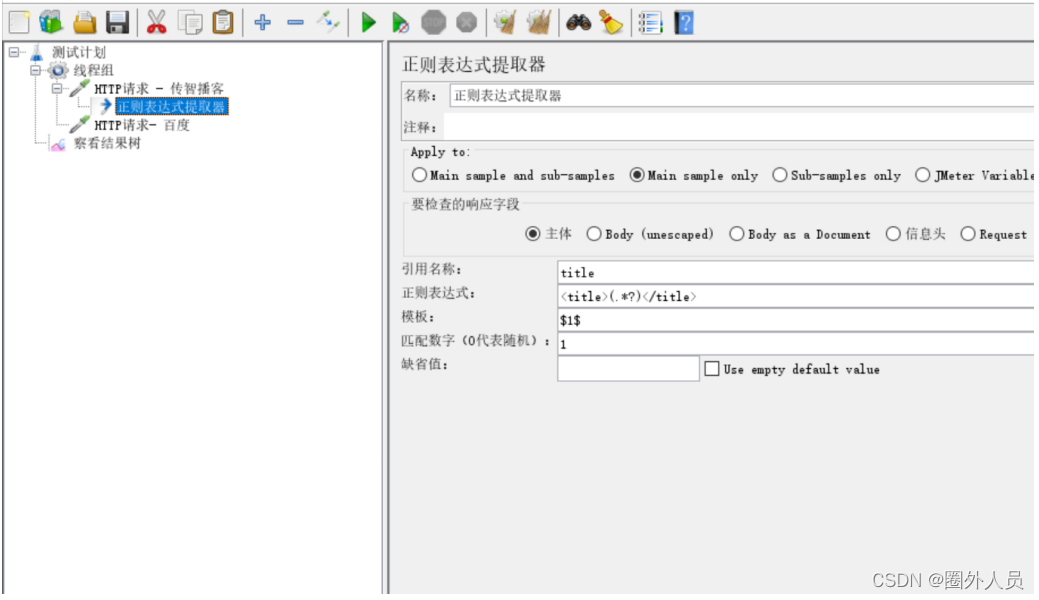
4、添加HTTP请求 —— 百度,在参数中引用正则表达式提取器中定义的变量title:${title}
5、添加查看结果树。
案例2:获取传智播客首页的地址,并作为参数传递
xpath提取器:
应用场景:只能适用于响应消息为HTML格式的情况
参数介绍:
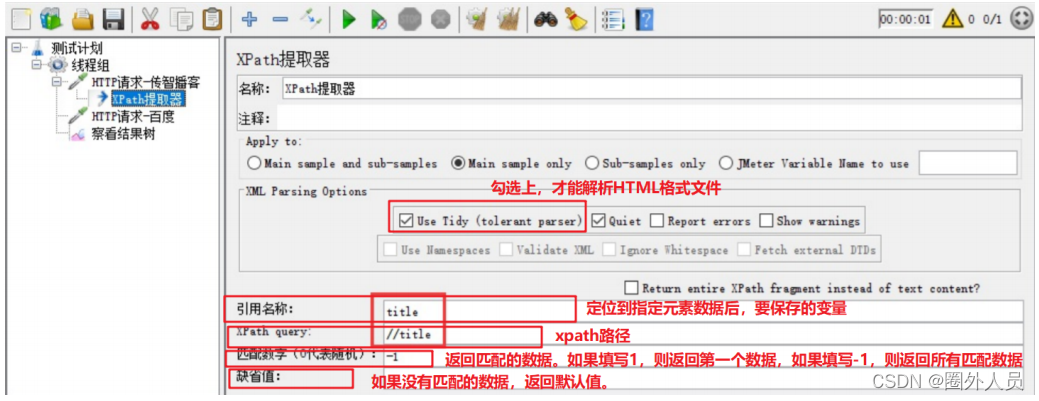
步骤:
1、添加线程组
2、添加HTTP请求——传智播客首页
3、添加xpath提取器
- 勾选Use Tidy
- 填写引用名称:参数名
- Xpath路径
4、添加HTTP请求——百度首页
- 引用xpath提取器中定义的参数名:${参数名}
5、添加查看结果树
json提取器:
应用场景:适用于返回的数据类型为JSON格式的情况
参数介绍:
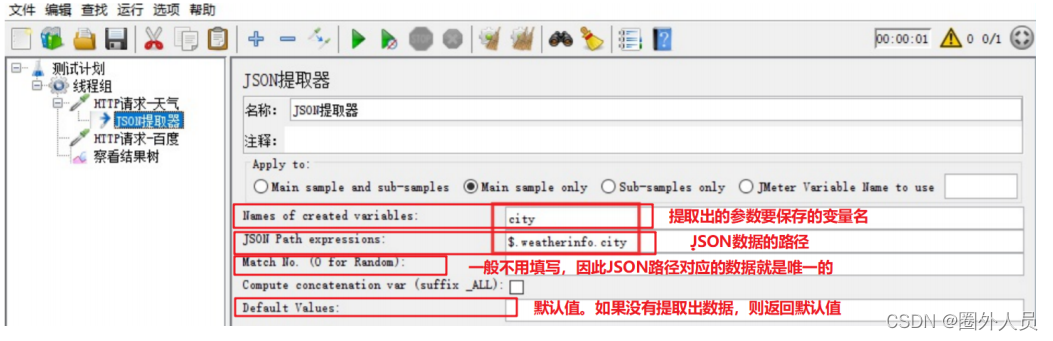
步骤:
1、添加线程组
2、添加HTTP请求——登录
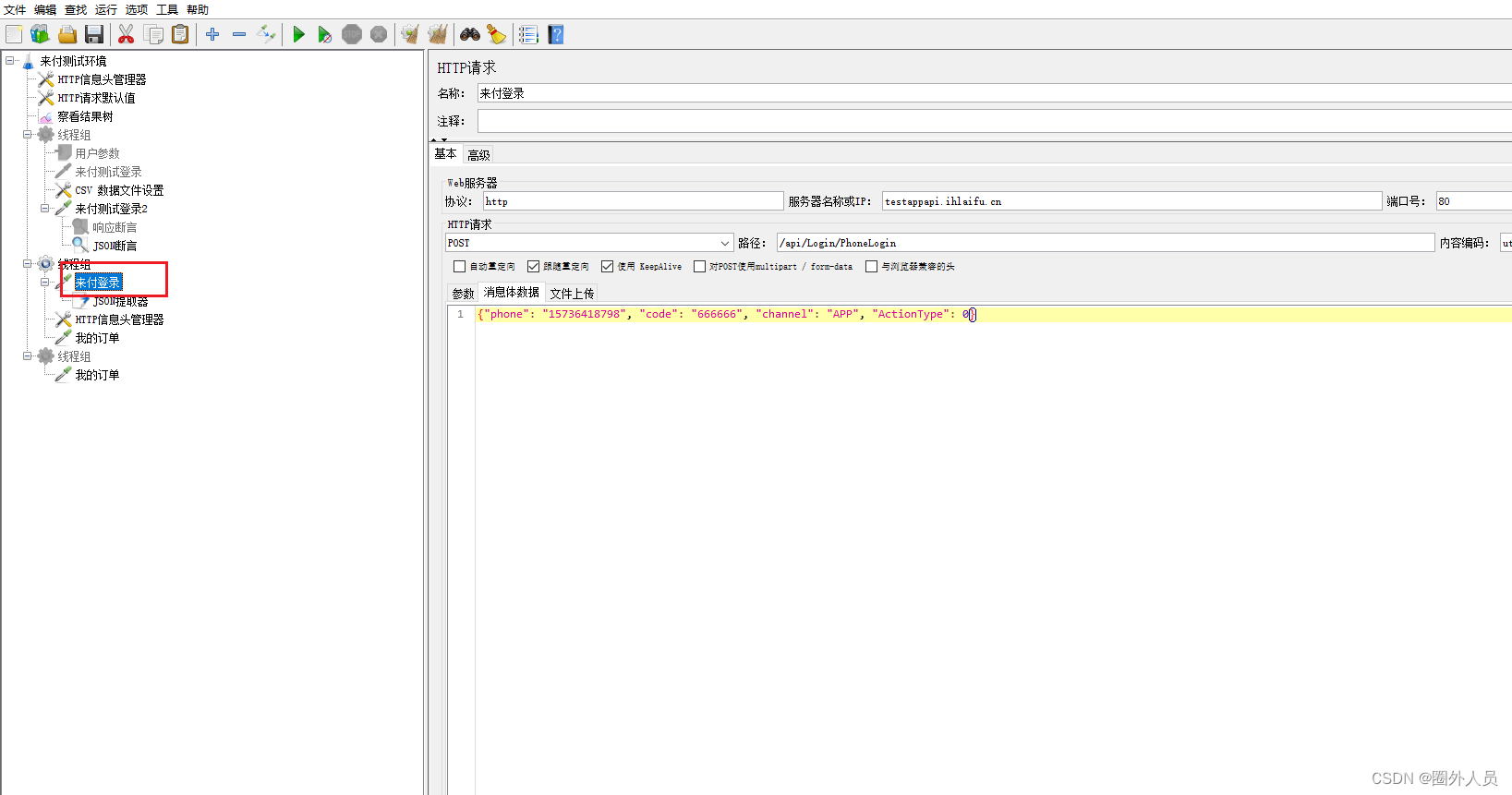
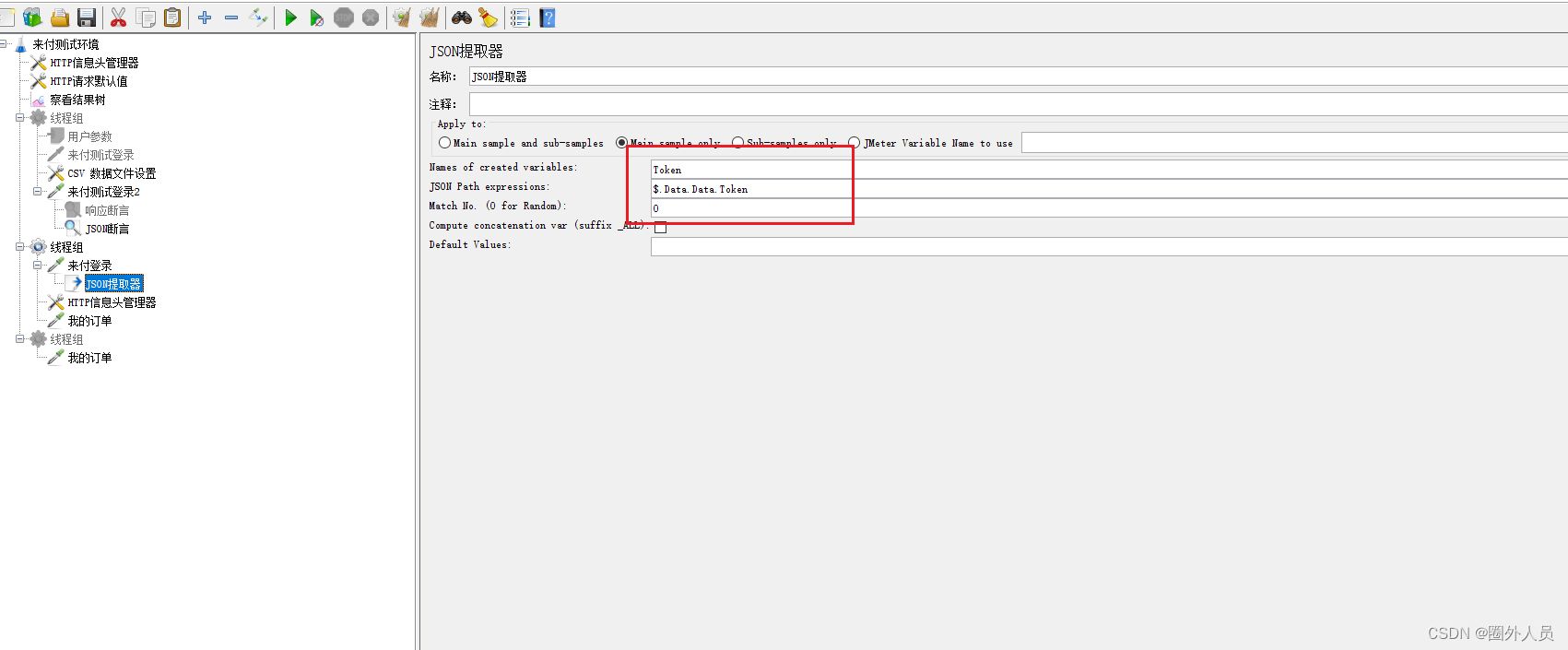
3、添加JSON提取器
- 参数名
- JSON路径
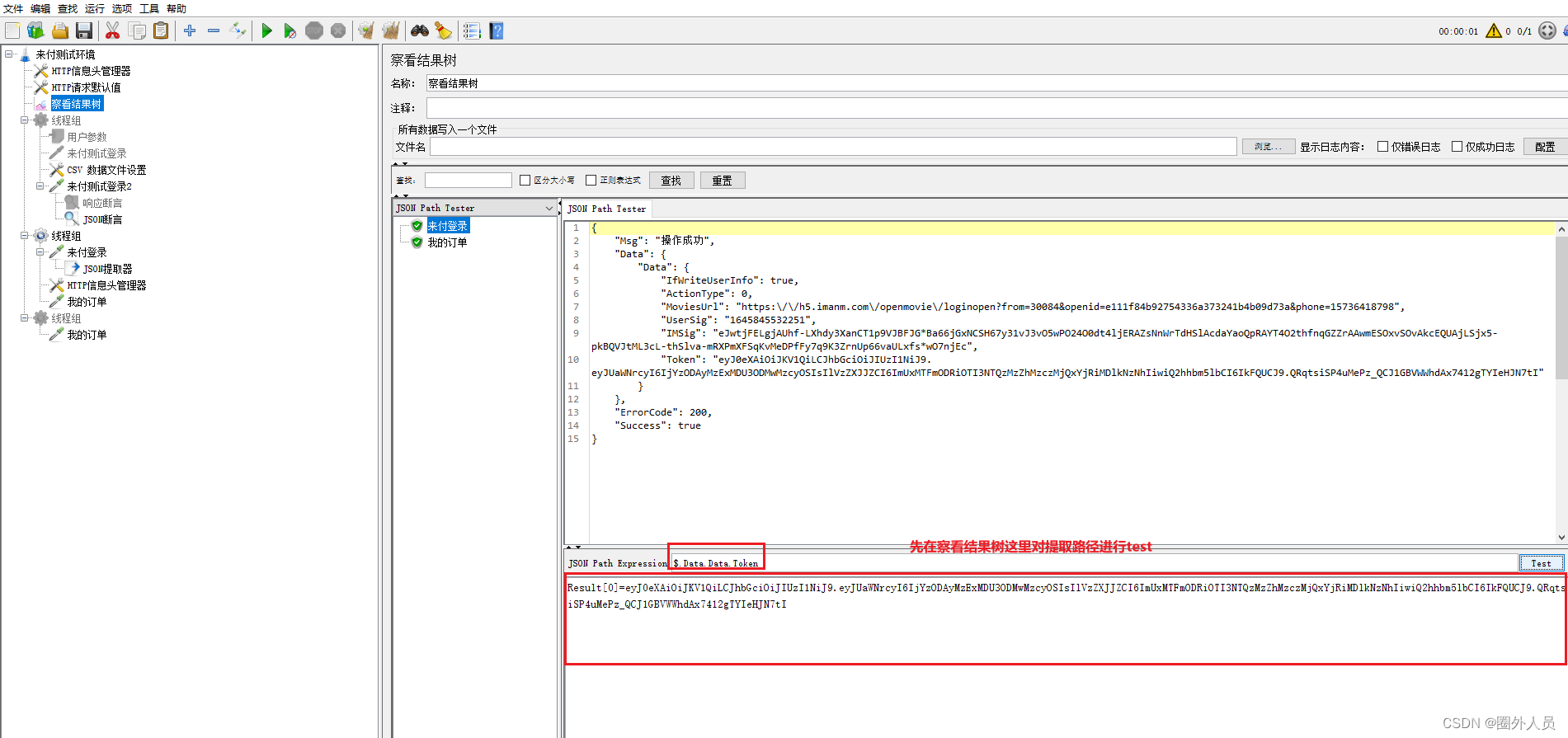
4、添加HTTP请求——我的订单,
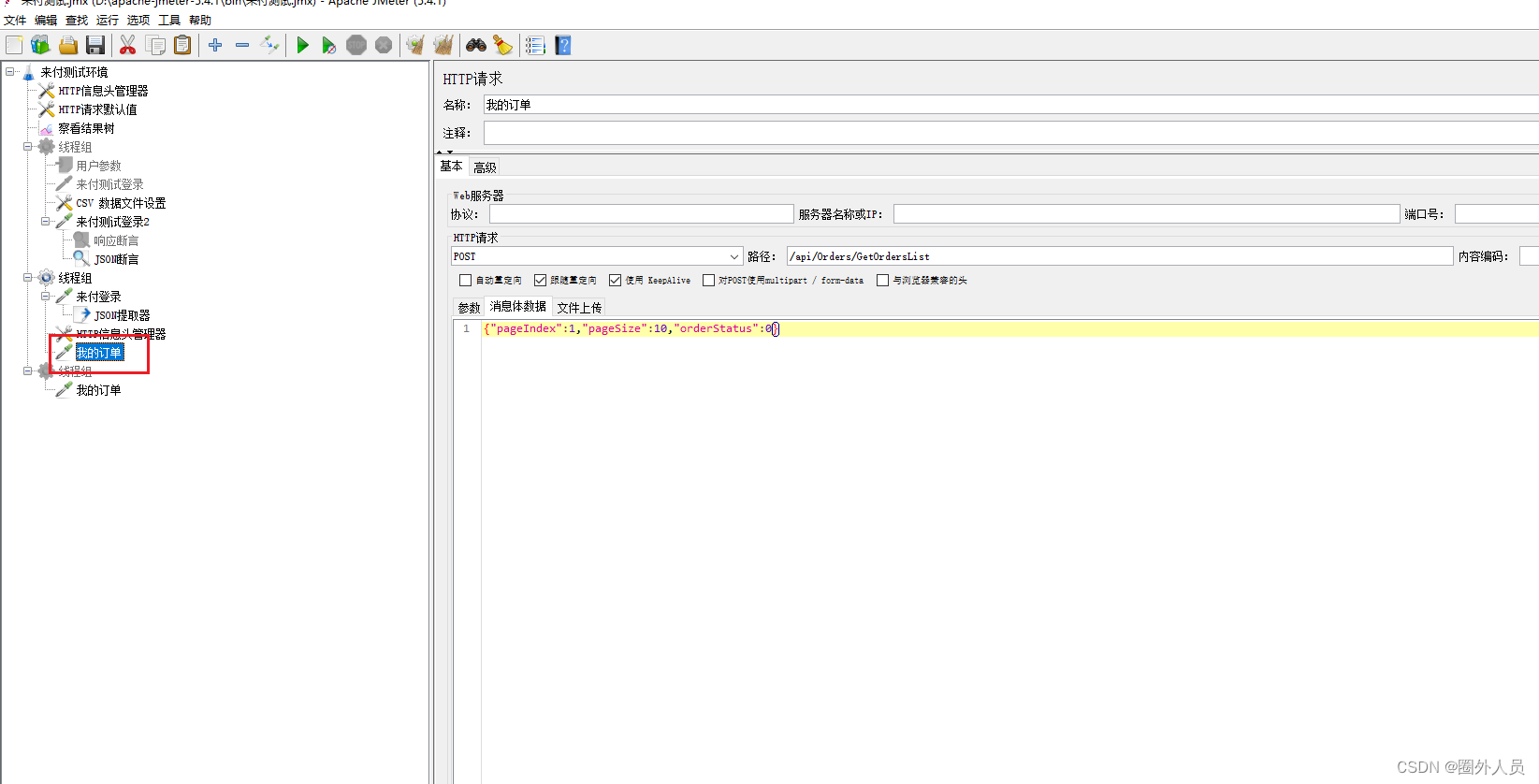
- 应用JSON提取器中定义的参数名
5、添加查看结果树。
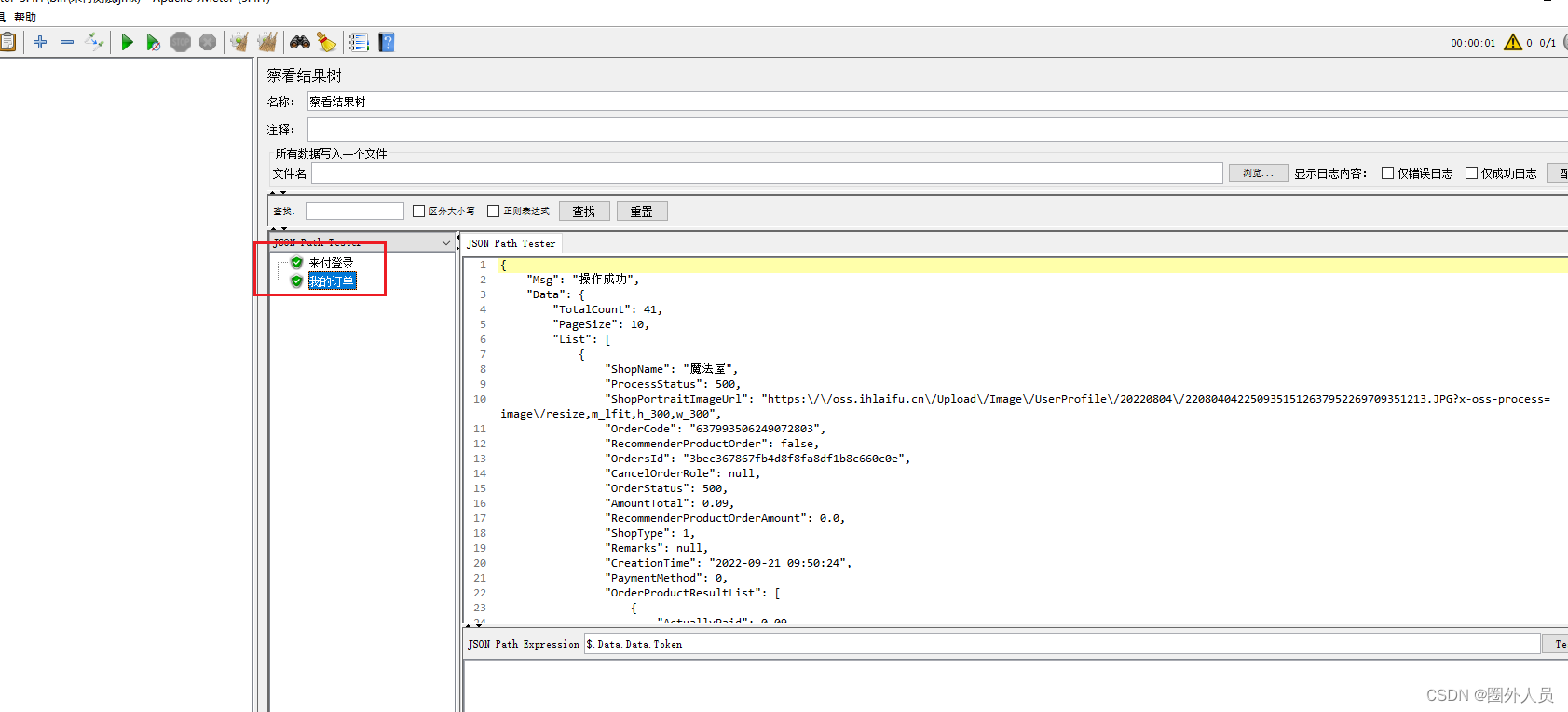
跨线程组关联:
跨线程组关联指的是多个请求之间有关联关系(即一个请求的参数需要使用前面请求的响应),但是两个请求不在一个线程组内,此时使用提取器无法完成关联,需要使用Jmeter属性来完成数据的传递。
原理:
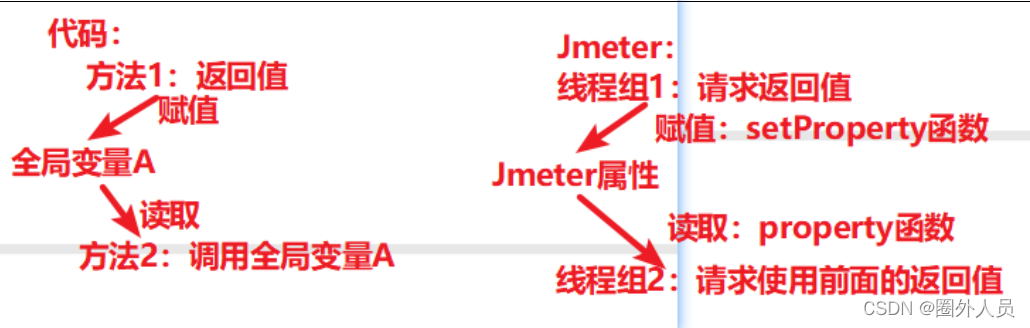
步骤:
1、添加线程组1,添加HTTP请求——登录
2、添加JSON提取器
3、添加Bean Shell取样器(填写setProperty函数——将提取器提取出来的值赋值给Jmeter属性)
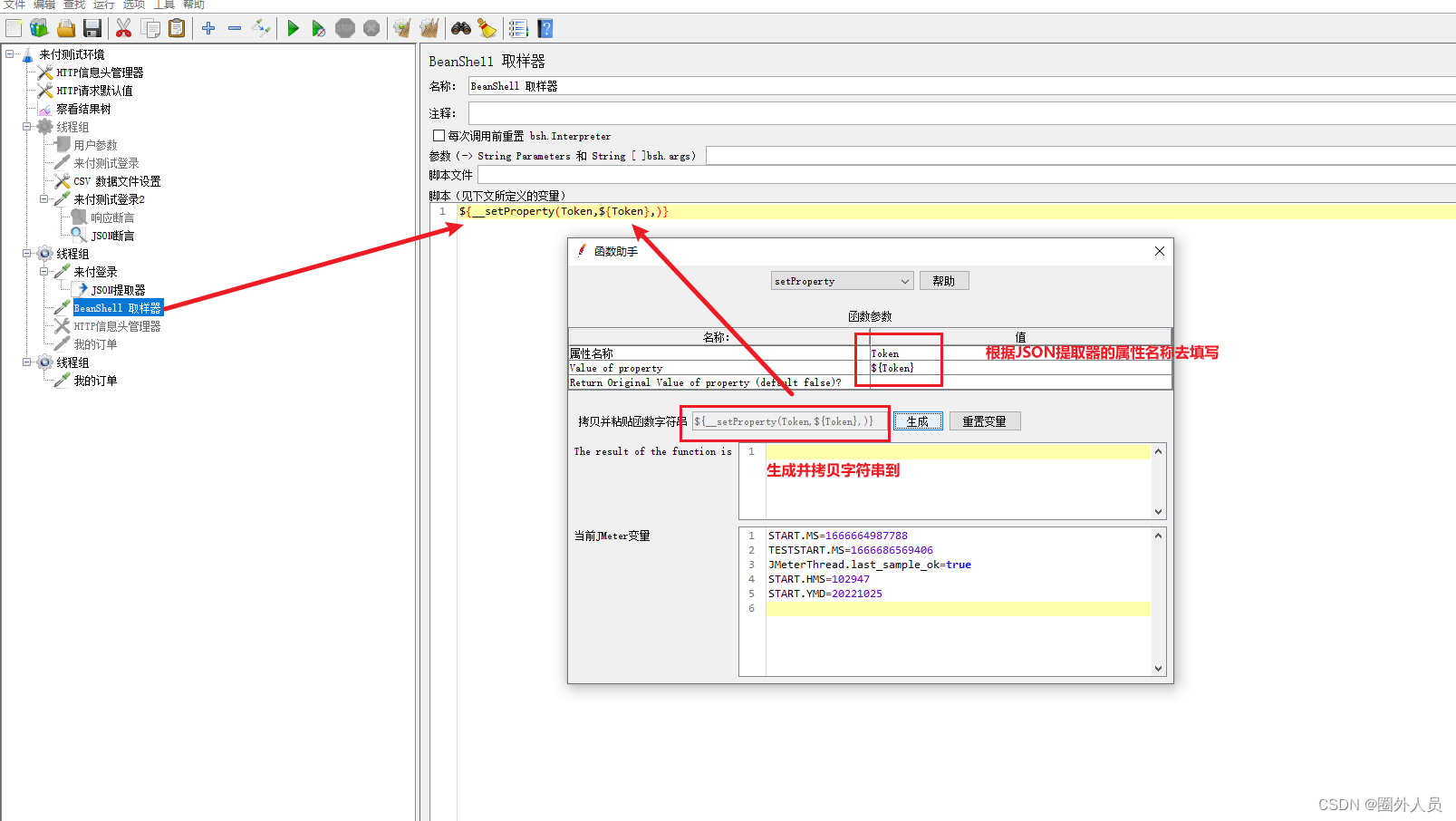
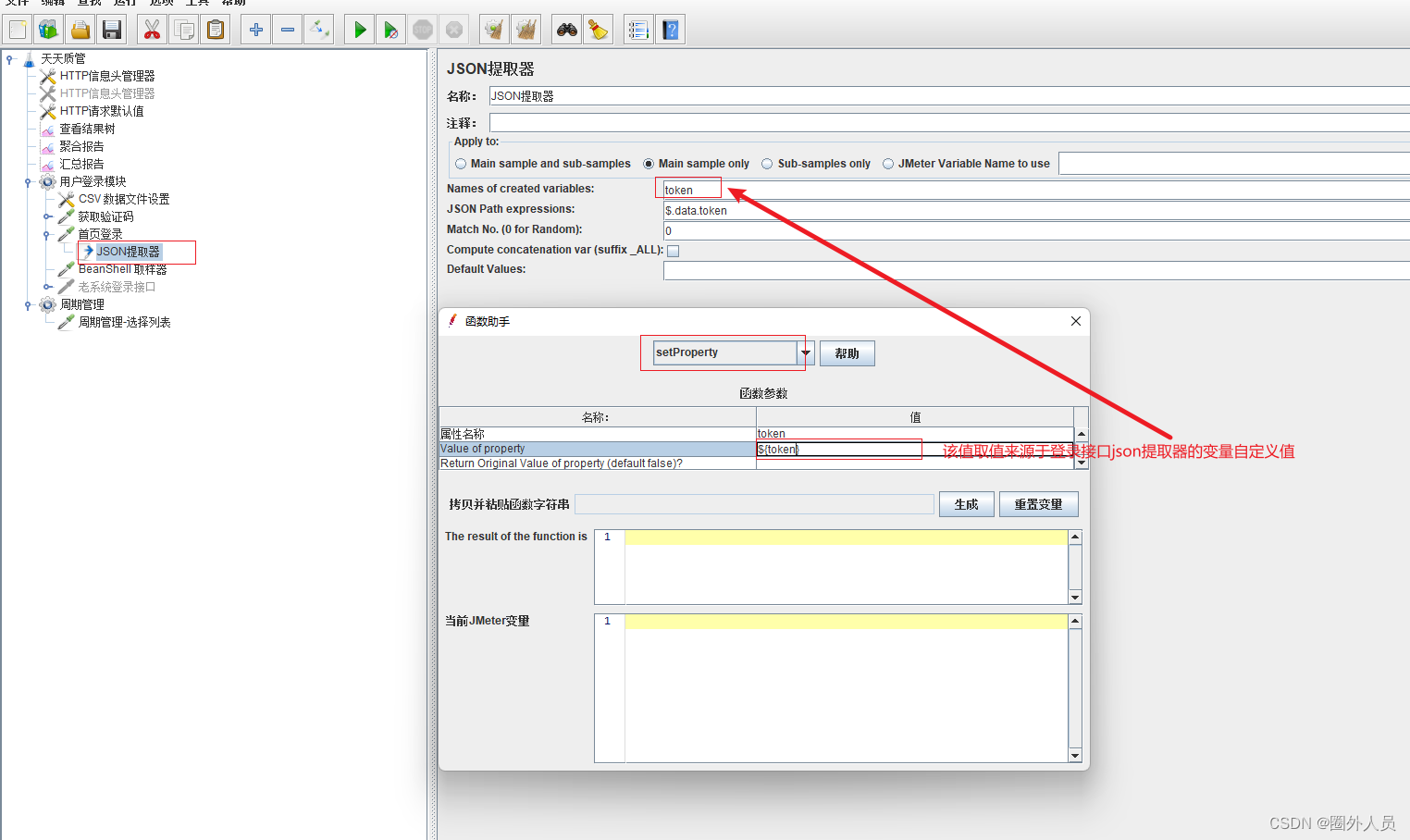
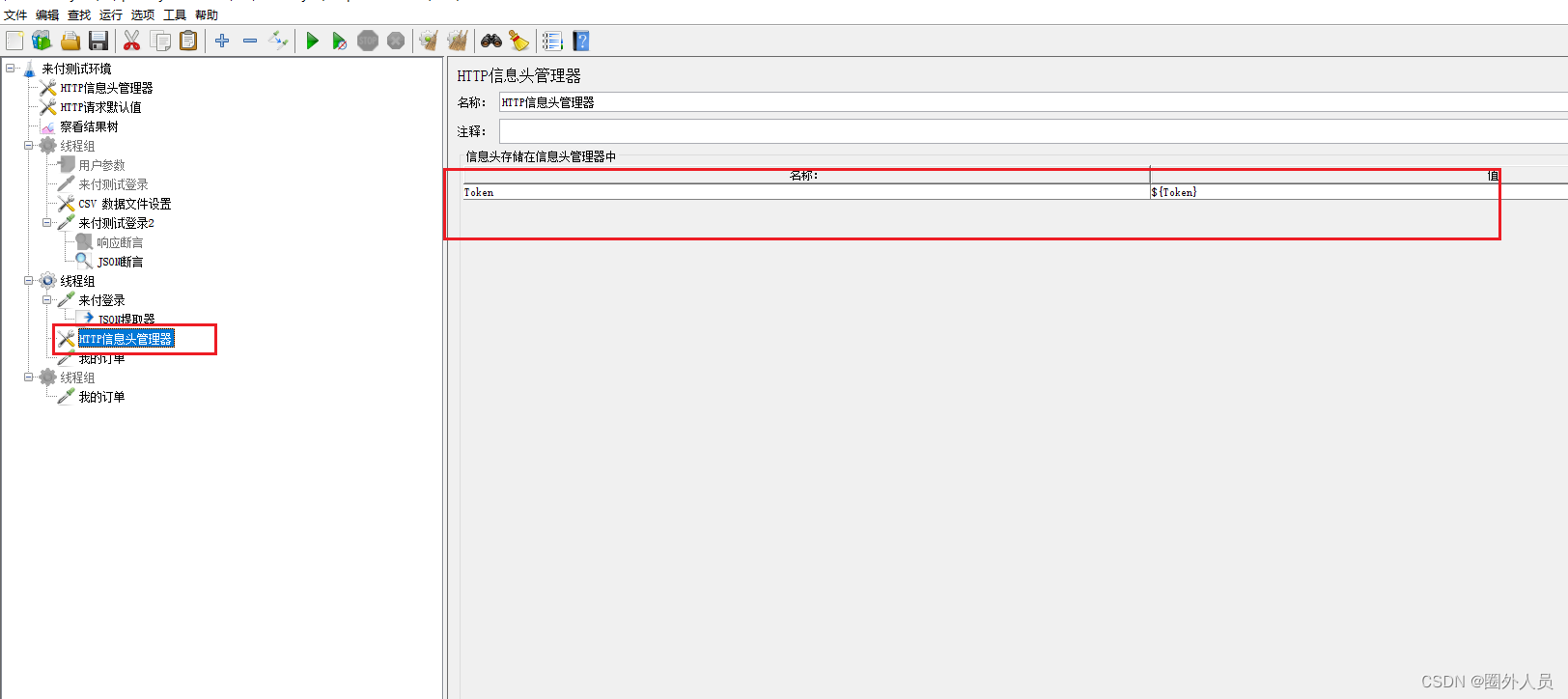
4、添加线程组2,添加HTTP请求——我的订单
- 引用前面返回的token信息(使用property函数——将Jmeter属性值读取出来)
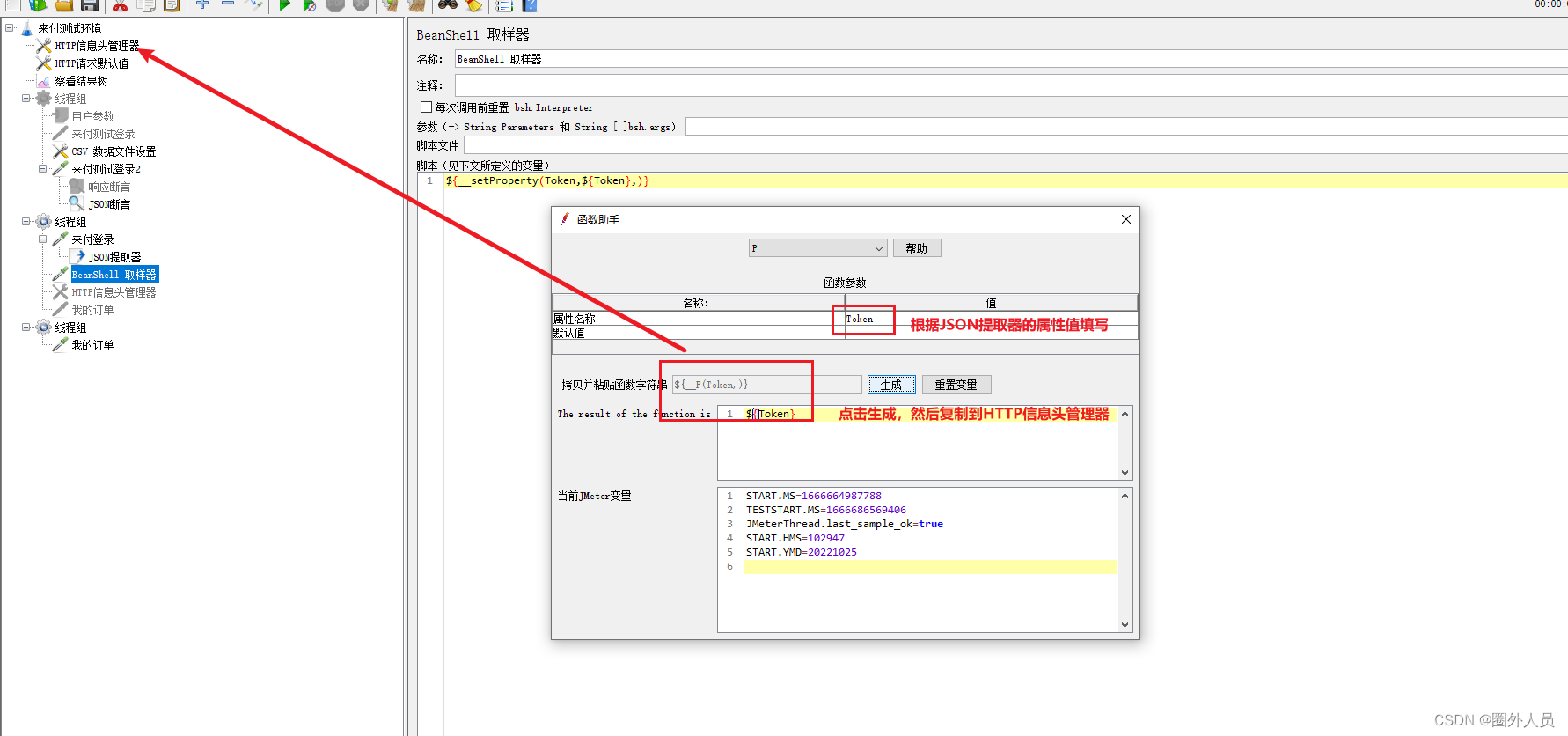 5、添加查看结果树
5、添加查看结果树
全局变量跨线程组引用:
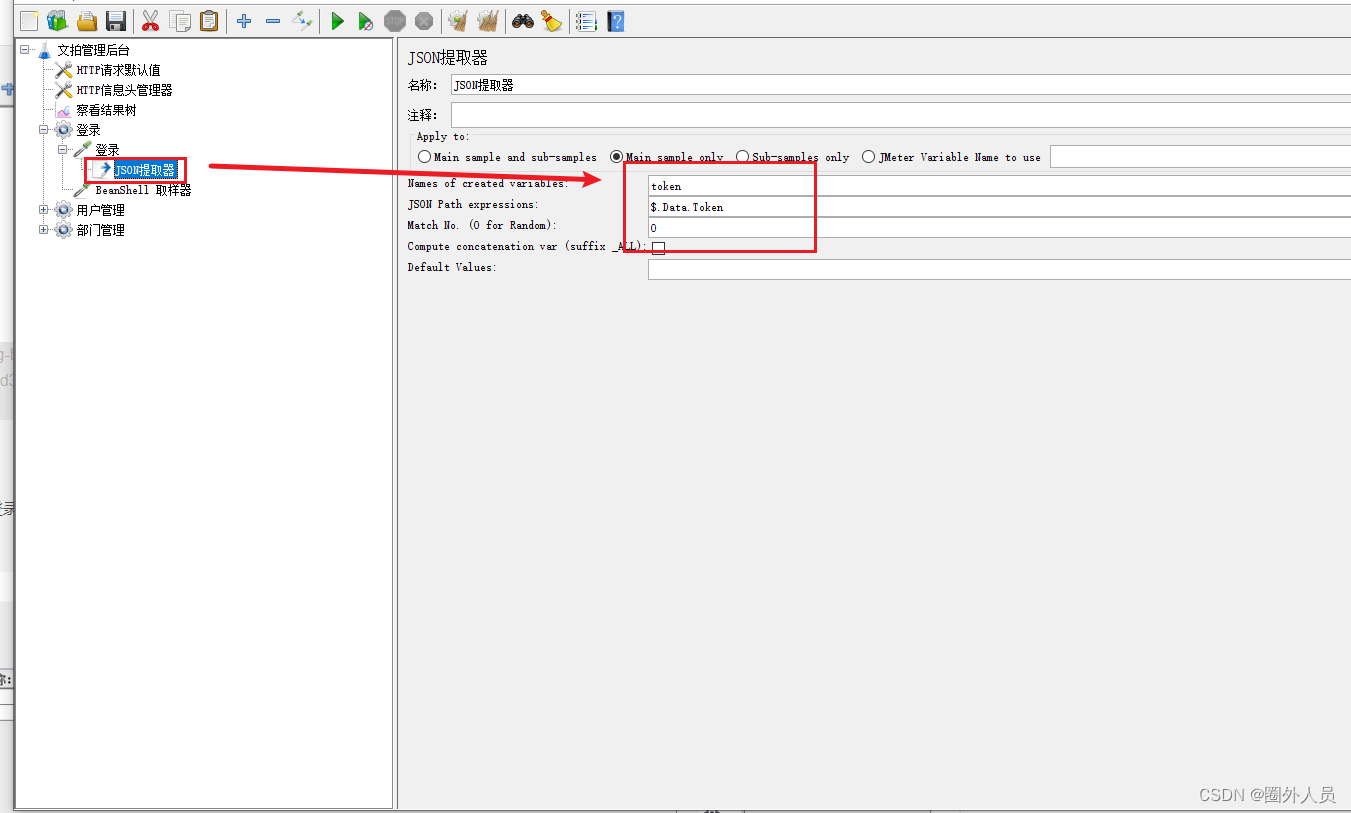
这时候就要用到P函数
第一步:利用JSON提取器提取登录请求token
第二步:添加一个BeanShell 取样器,把setproperty函数助手里面的东西复制到BeanShell 取样器里面
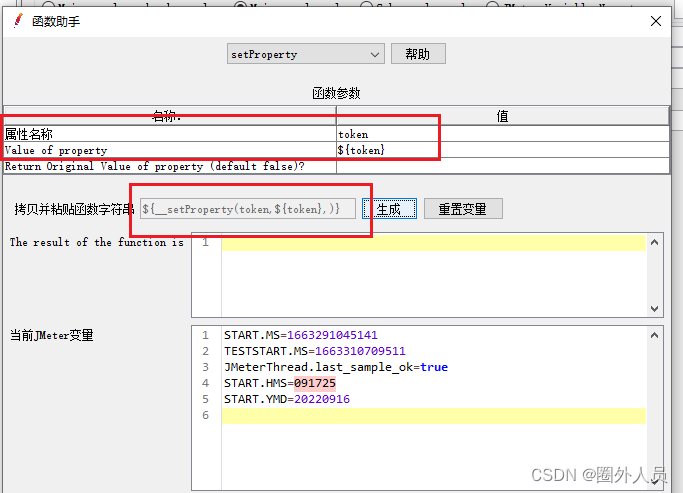
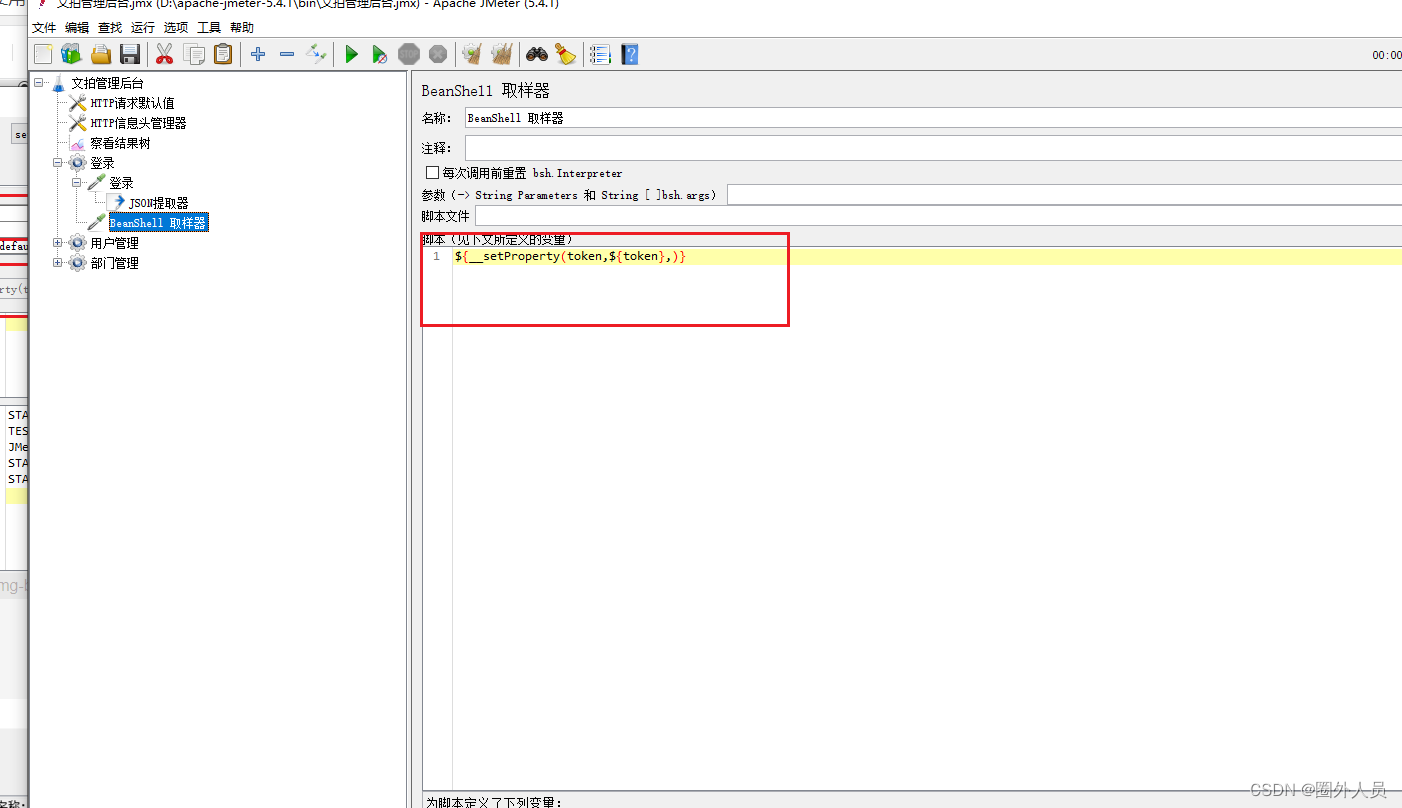 第三步:利用函数助手里面的P函数,把值放在请求信息头里面
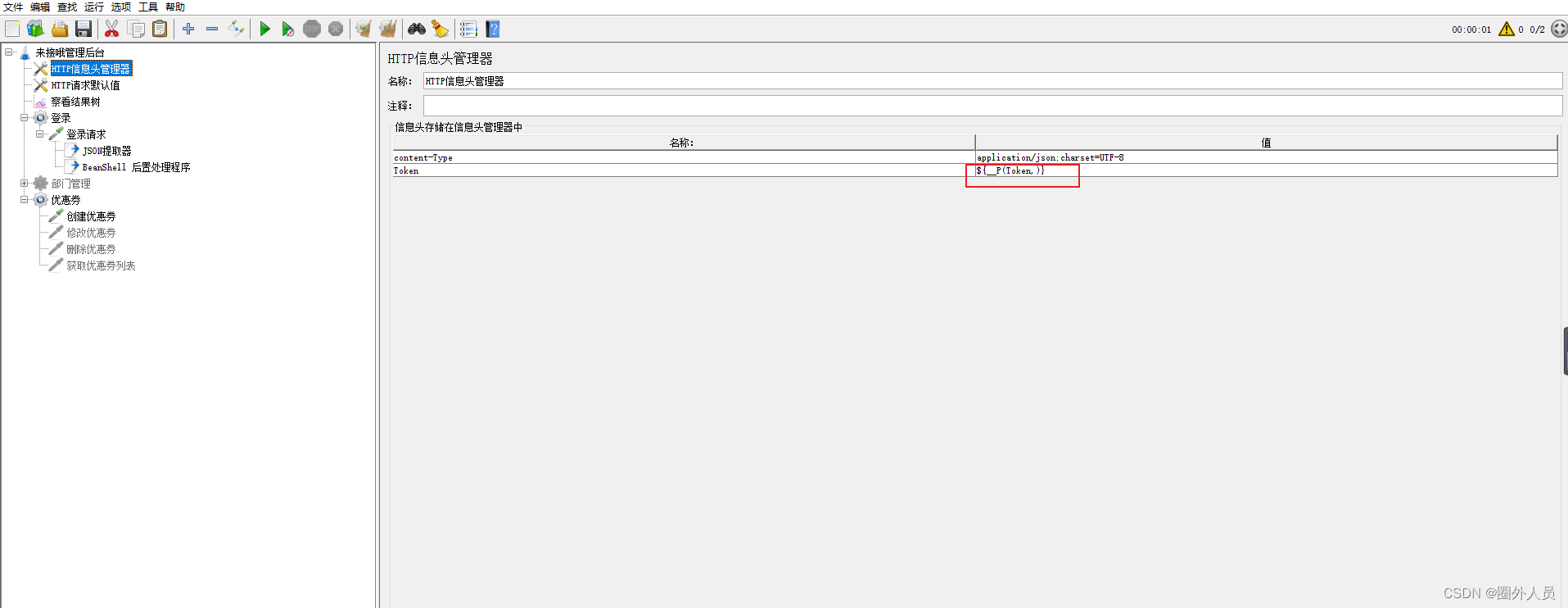
第三步:利用函数助手里面的P函数,把值放在请求信息头里面

在信息头里引用拷贝复制的字符串就可以了
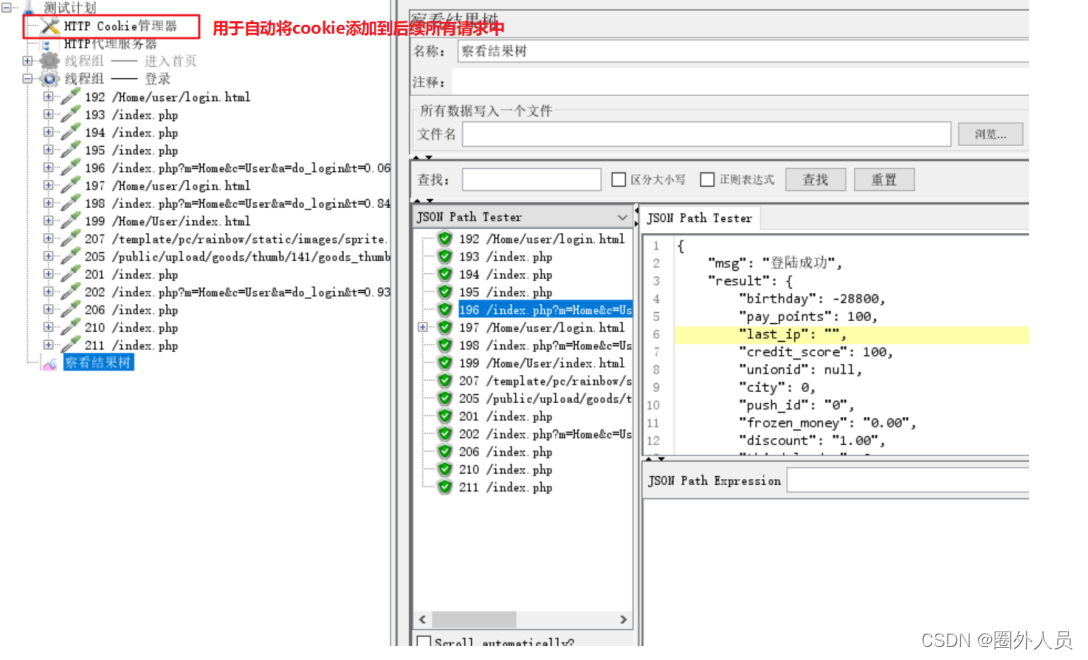
Cookie管理器:
管理cookie:自动将cookie信息添加到后续的所有请求中。
登录及后续的相关操作时,需要提前添加HTTP Cookie管理器
逻辑控制器:
控制jmeter脚本的执行顺序
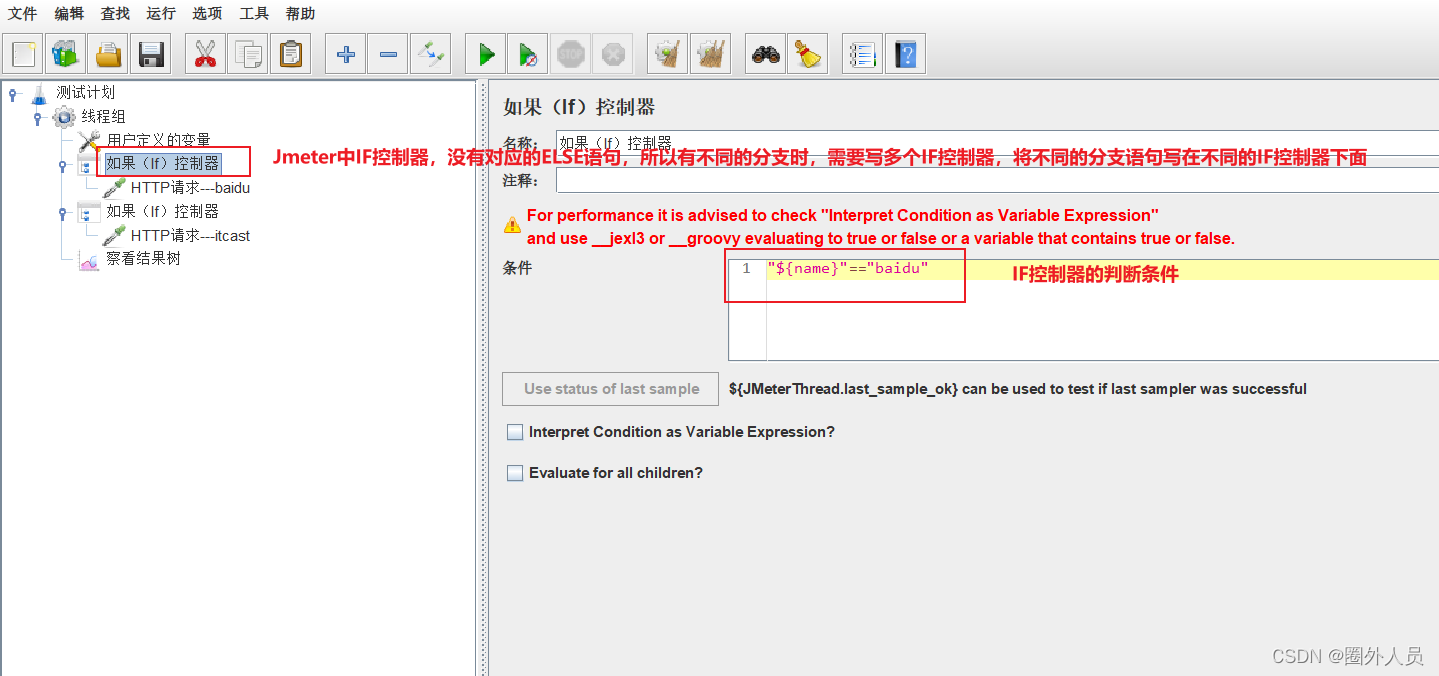
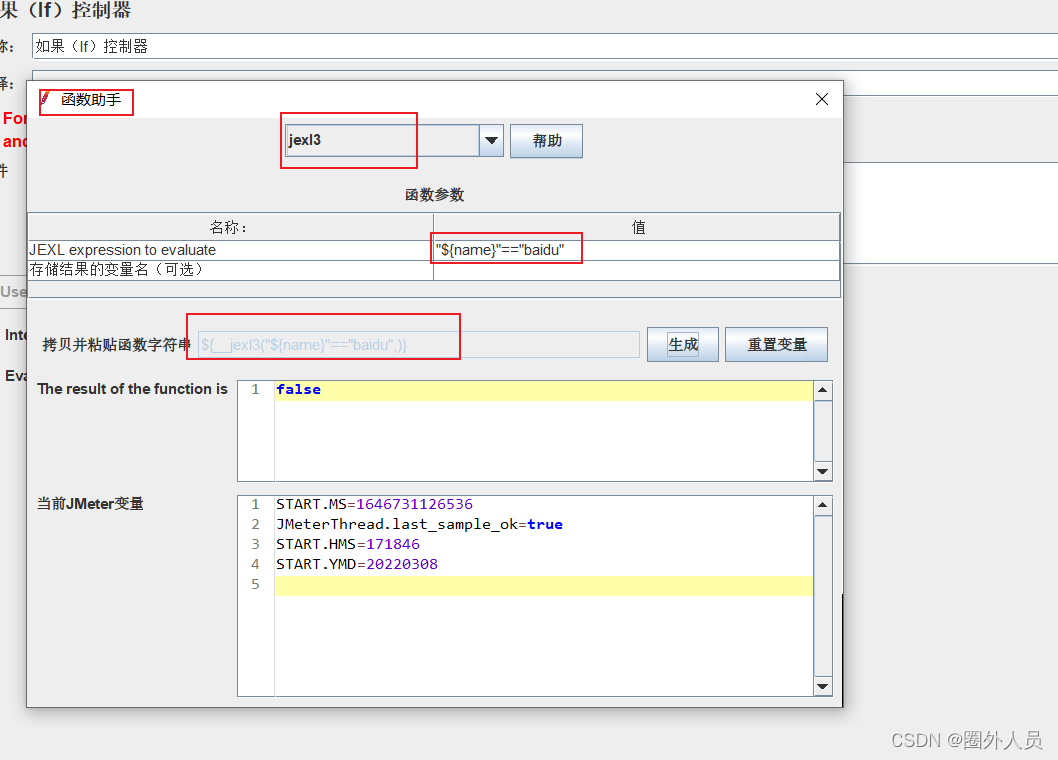
如果(if)控制器:
第一种配置方法:
第二种配置方法:
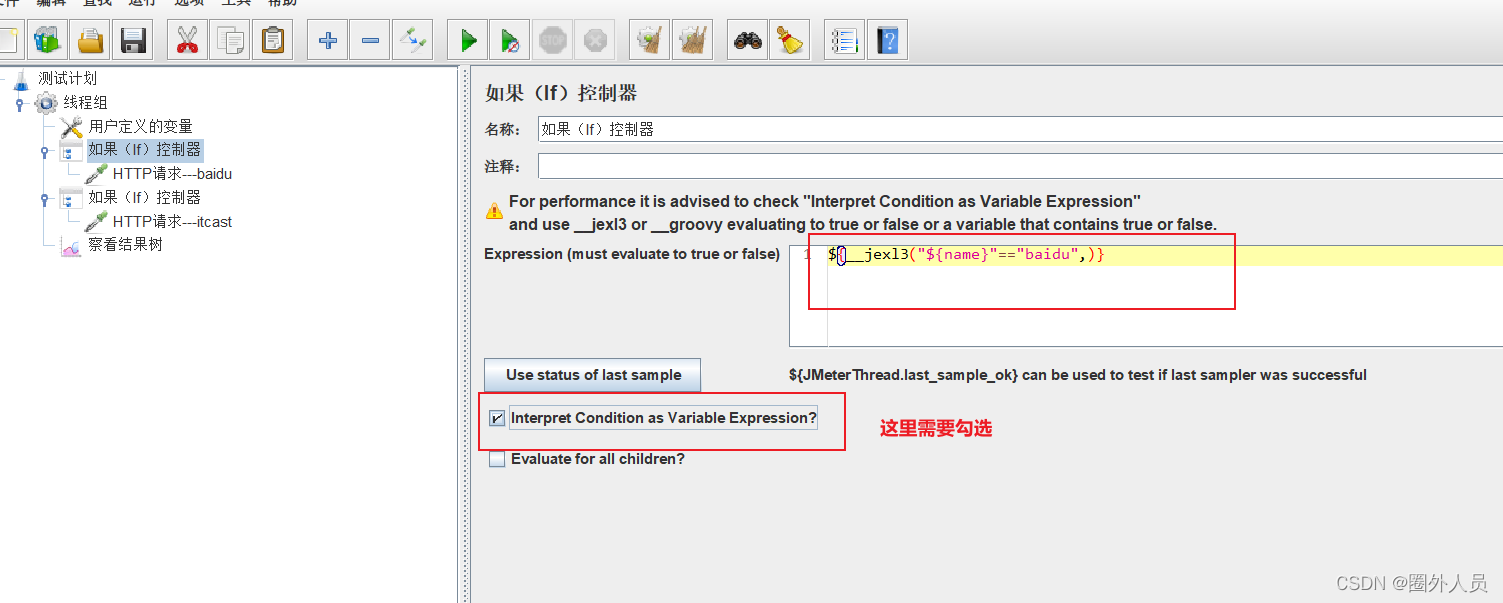
勾选上Interpret Condition as Variable Expression,判断条件需用使用jexl3函数。
(使用这个函数来进行判定时,Jmeter自身的执行效果要高一些)
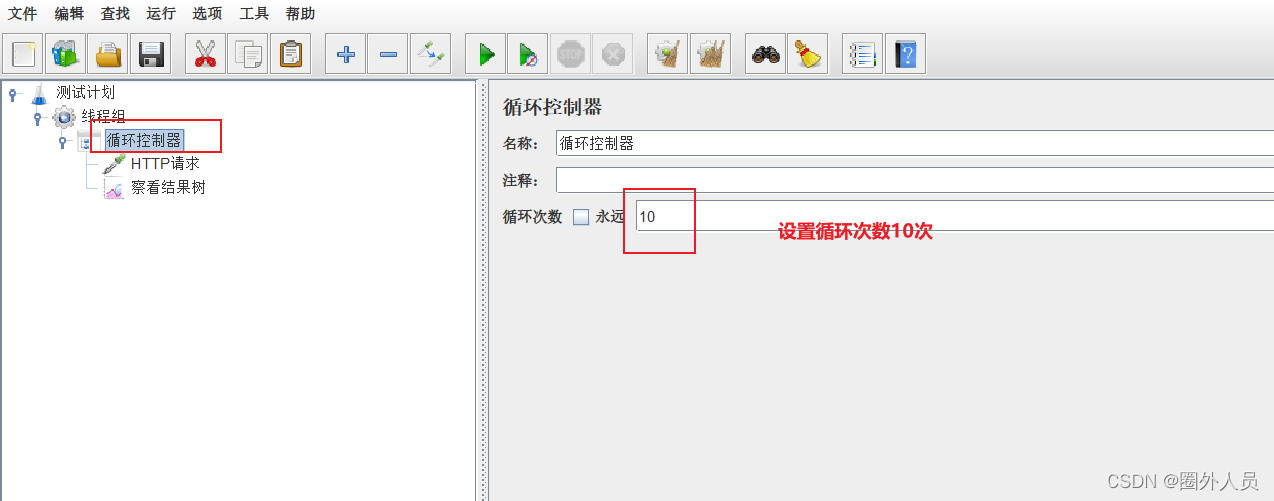
循环控制器:
控制子节点下的HTTP请求的执行次数
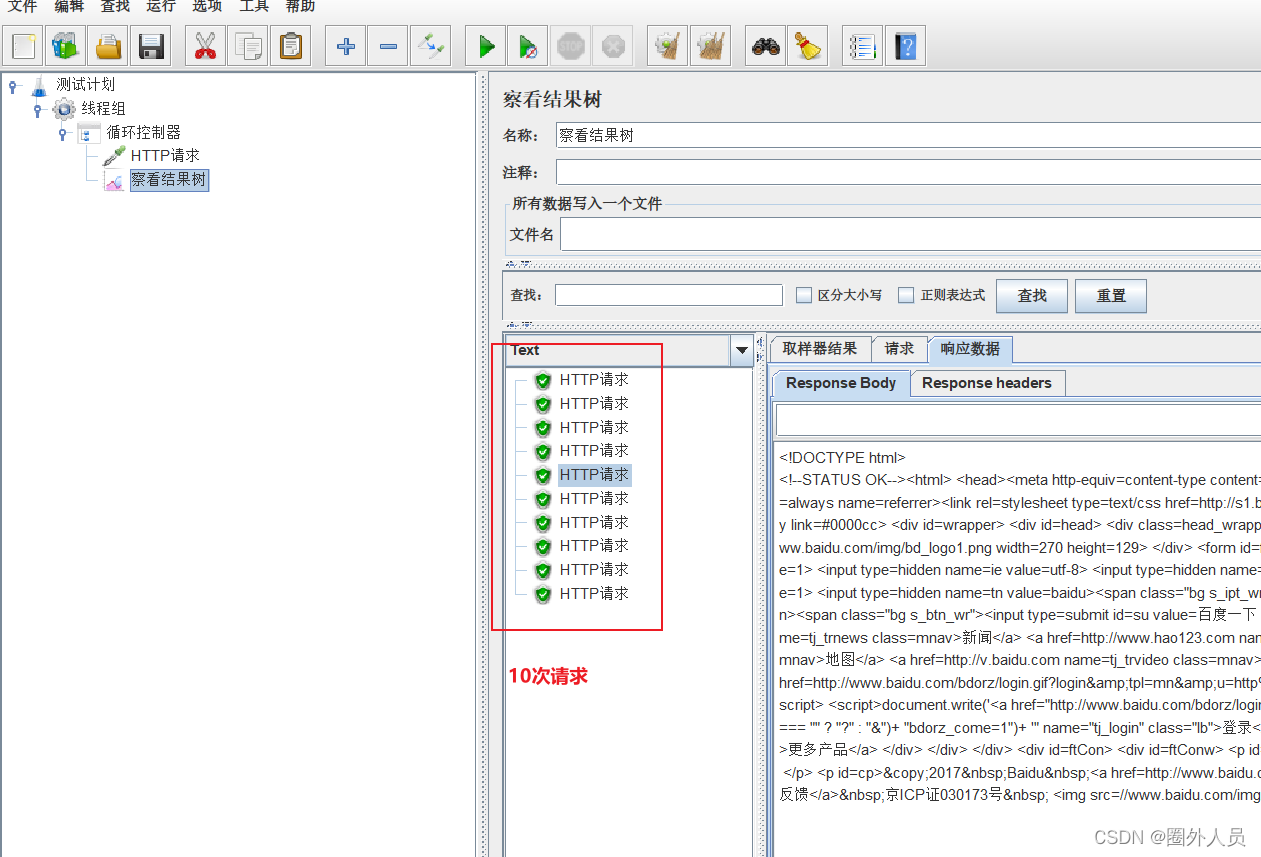
循环控制器与线程组中的循环次数的对比:
循环控制器只控制其子节点下的HTTP请求,线程组对所有的请求都有效
假如线程组循环次数为2,循环控制器次数为3,则循环控制器下的请求执行次数为:2*3
ForEach控制器:
与用户定义的变量或者正则表达式提取器配合使用,循环读取用户定义的变量或者正则表达式结果中的
所有数据。
配置参数:
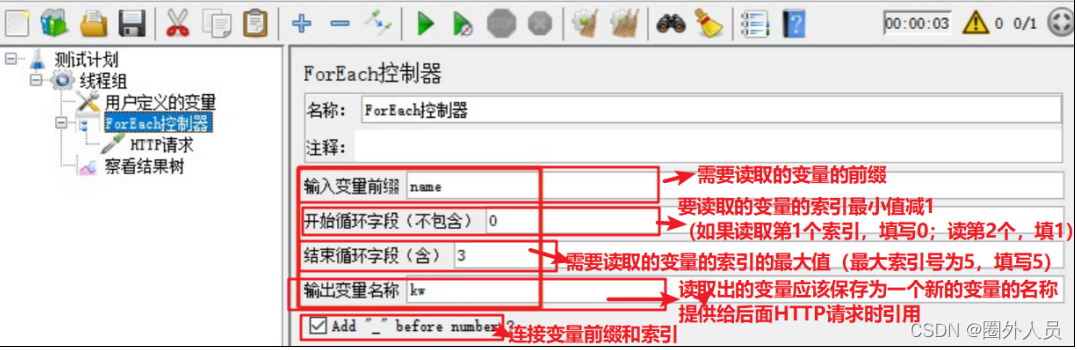
与用户定义的变量配合使用:
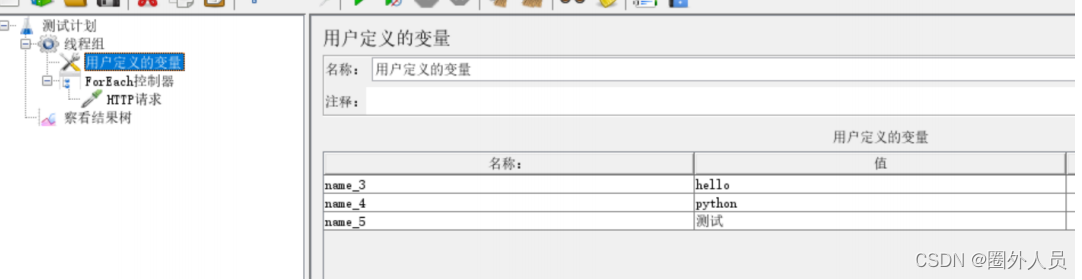
1、添加用户定义的变量:
- 参数名:固定前缀 + 连续的数字后缀
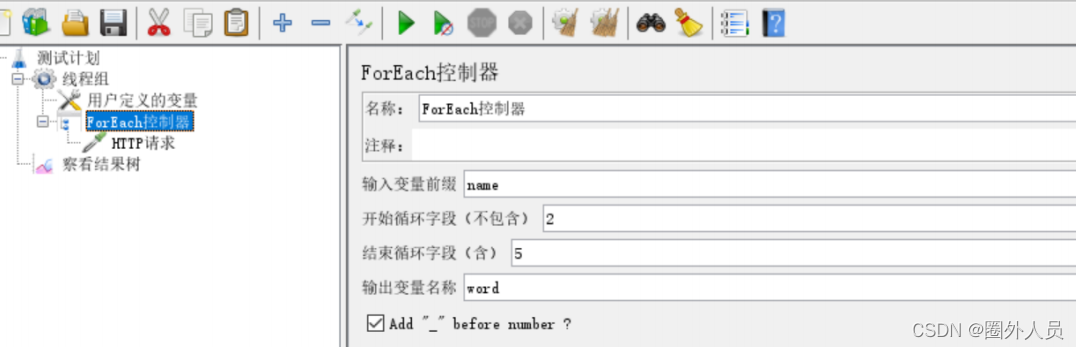
2、添加ForEach控制,并配置
 3、在ForEach控制器下方添加HTTP请求,并引用ForEach读取的数据${word}
3、在ForEach控制器下方添加HTTP请求,并引用ForEach读取的数据${word}
4、添加查看结果树
与正则表达式配合使用:
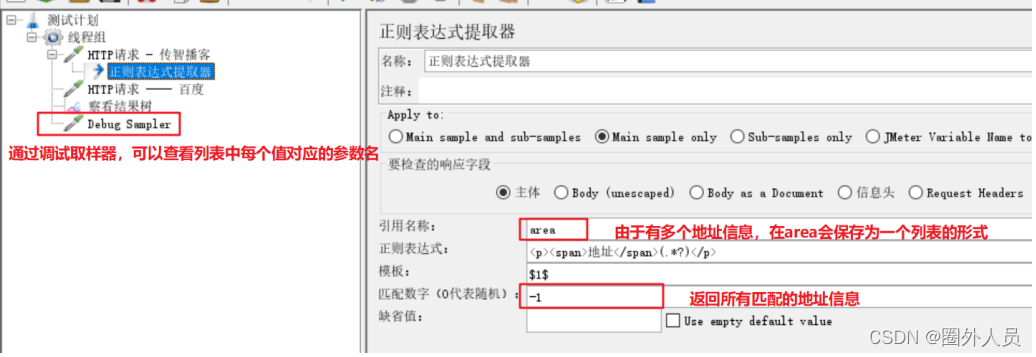
1、添加HTTP请求——itcast首页
2、添加正则表达式提取器,提取出itcast响应中所有的地址相关的数据,并保存为参数area(列表数据)

3、添加ForEach控制器,循环提取area列表中的每一个地址信息
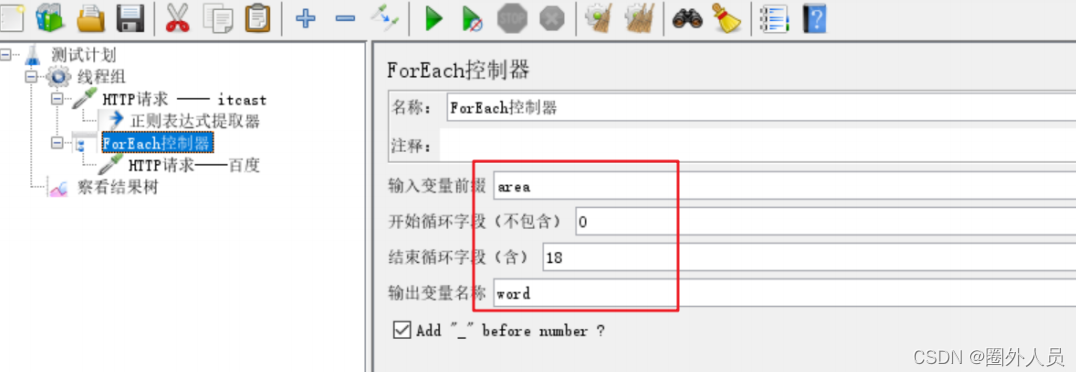
4、在ForEach控制器下添加一个HTTP请求——百度,引用ForEach控制器中定义的变量${word},作为
参数
5、添加查看结果树
各类定时器的使用:
同步定时器:
又叫做集合点(LR的叫法),保证大量的请求在同一时间进行发送,形成绝对的并发
实现原因:设置同步定时器,有请求要发出时,同步定时器会暂缓请求发送,一直到积攒的请求数达到要的数量时,将所有的请求同步发送出去,形成绝对的并发(更大的压力负载)
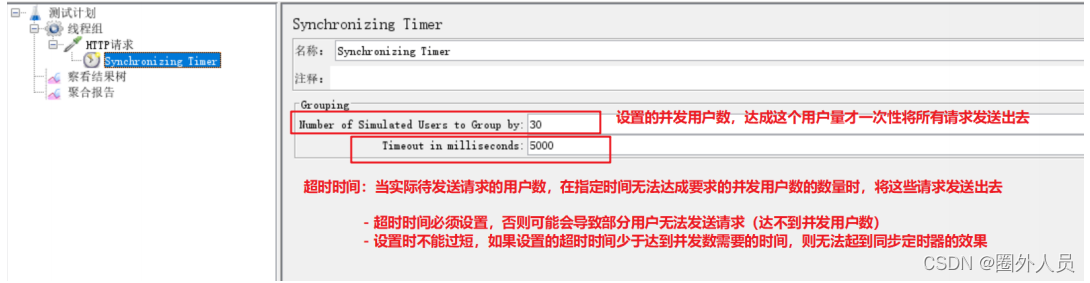


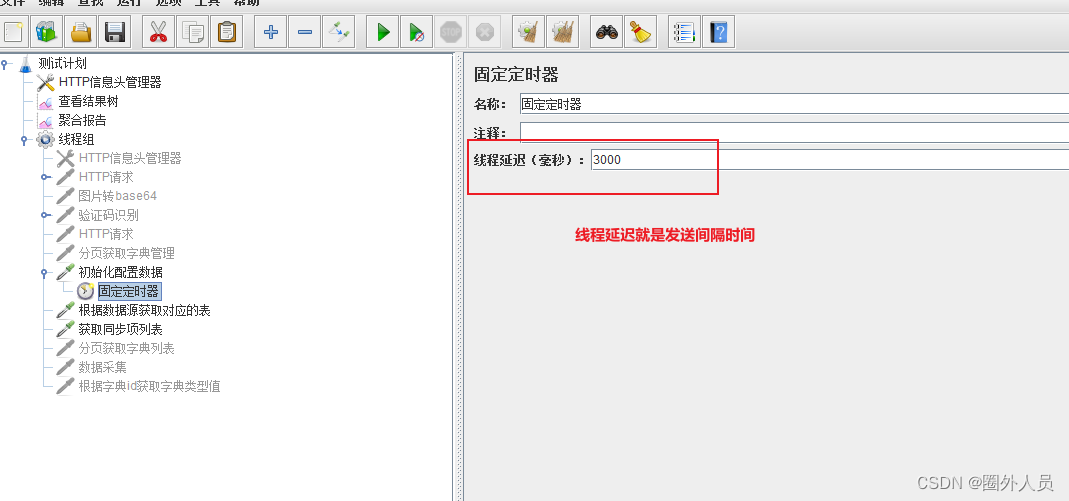
固定定时器:
使用场景:同一个线程组下的多个请求同时发送,间隔一定的时间多次发送
步骤:添加固定定时器在第一个请求后面。固定定时器的线程延迟就是它的请求发送间隔时间
三个线程分为一组,一组内的每个请求的时间都是一致的
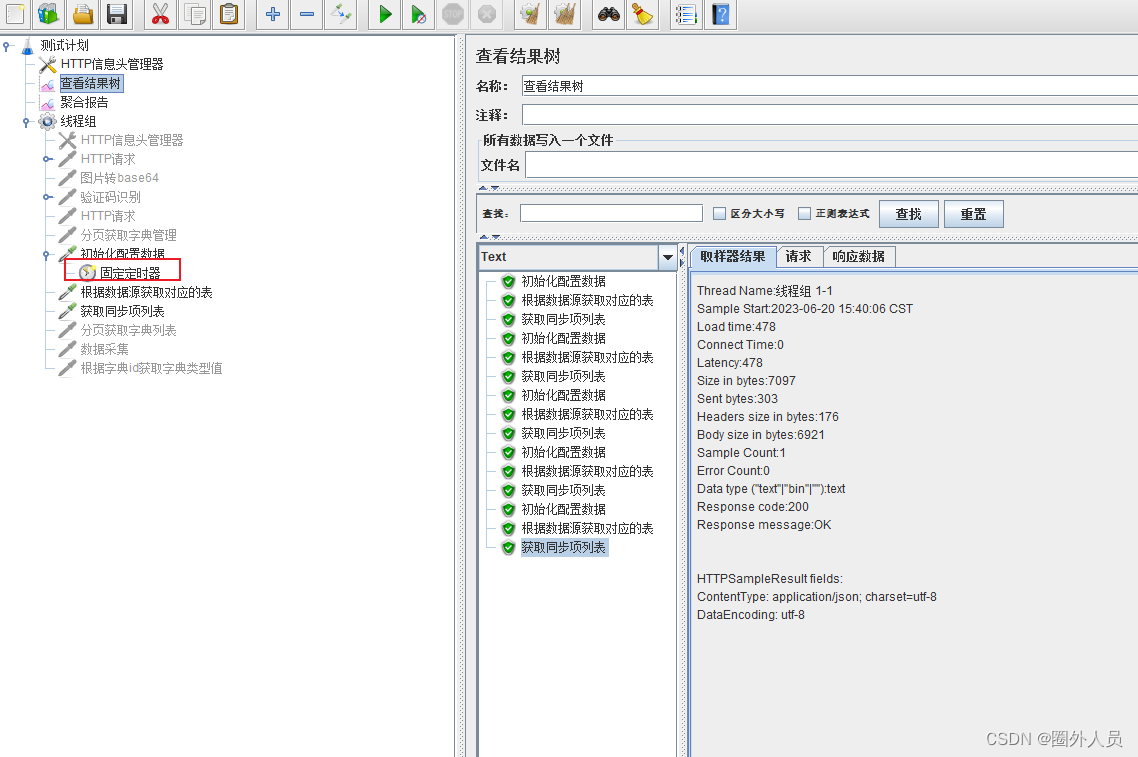
从下图可以看出挨着的三个请求时间都是一致的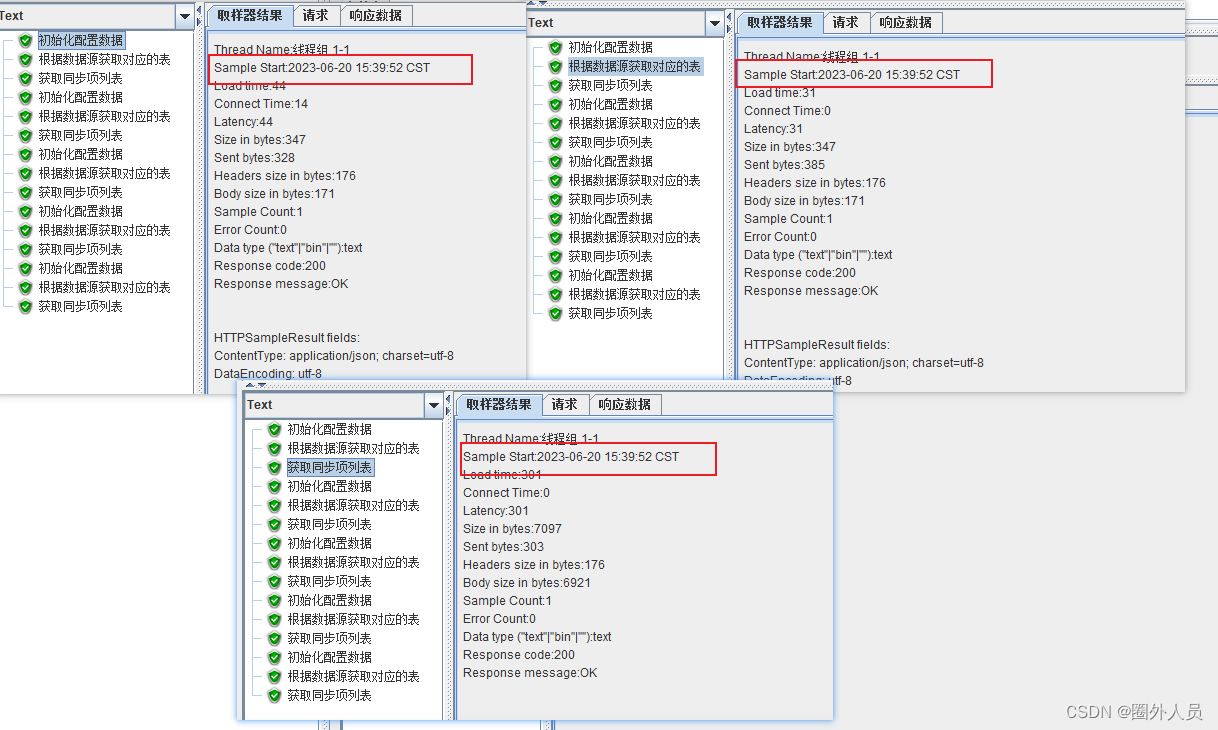
固定定时器放的位置决定它的请求间隔
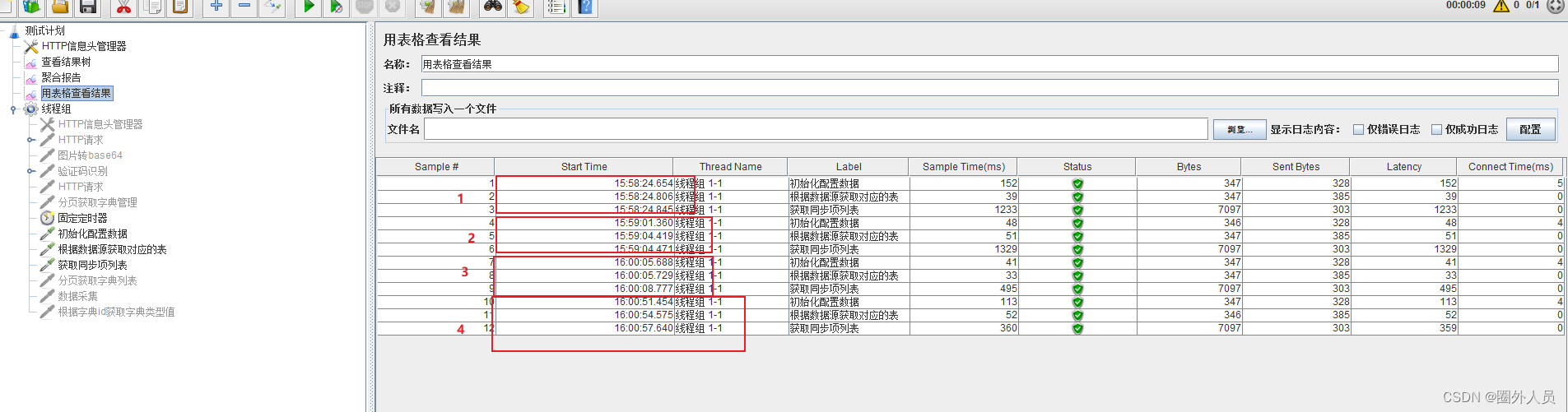
如下每种情况和对应场景
1、固定定时器放在第一个请求后面,三个请求同时执行
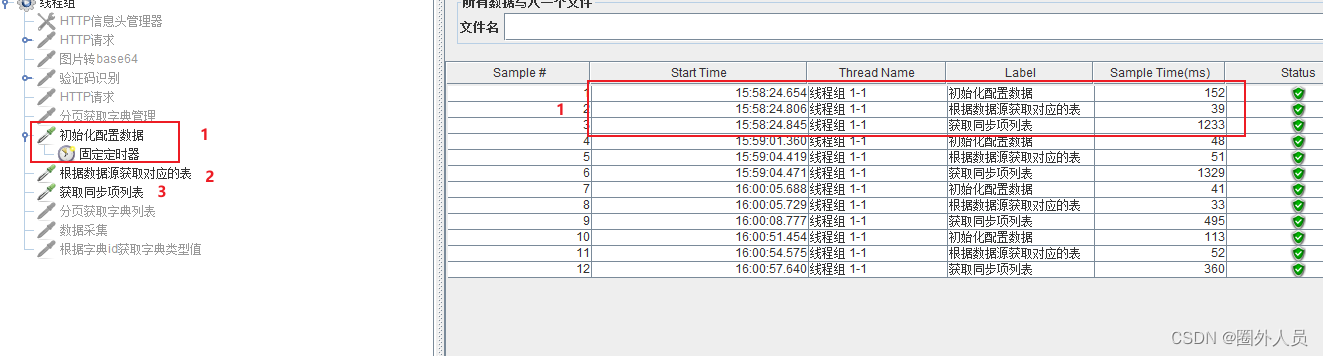
2、固定定时器放在第二个请求后面,请一个开始执行三秒后,第二和第三个请求会同时执行
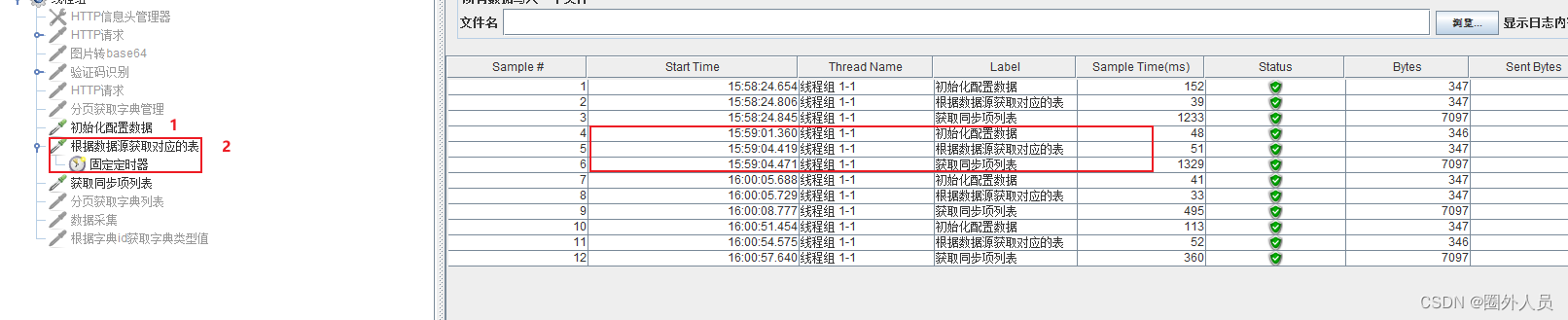
3、固定定时器放在第三个请求后面,第一和第二个请求会同时执行,执行三秒后,第三个请求才会开始执行

4、固定定时器放在外面的话,第一、第二、第三会依次间隔三秒后执行

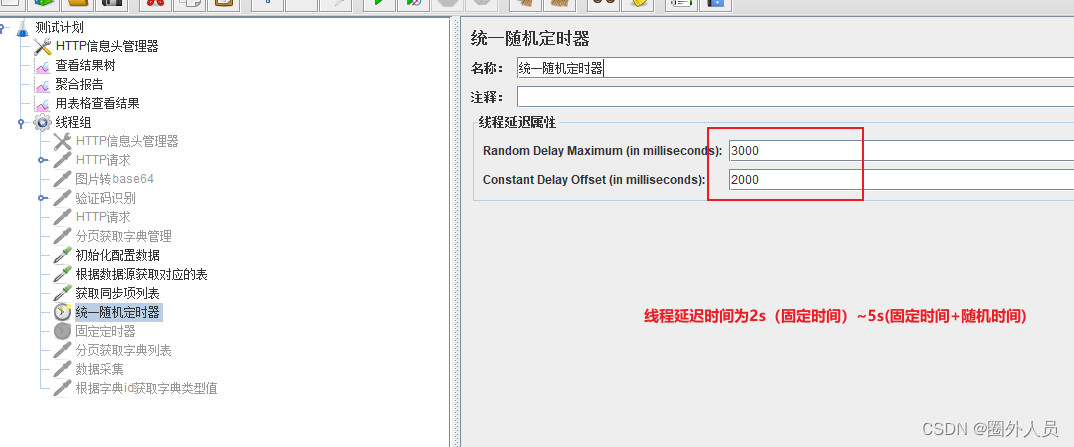
统一随机定时器:
Random Delay Maximum (in milliseconds) - 随机延迟毫秒数
Constant Delay Offset (in milliseconds) - 固定延迟毫秒数
//请求的延迟时间将在[固定延迟, 固定延迟+随机延迟]区间
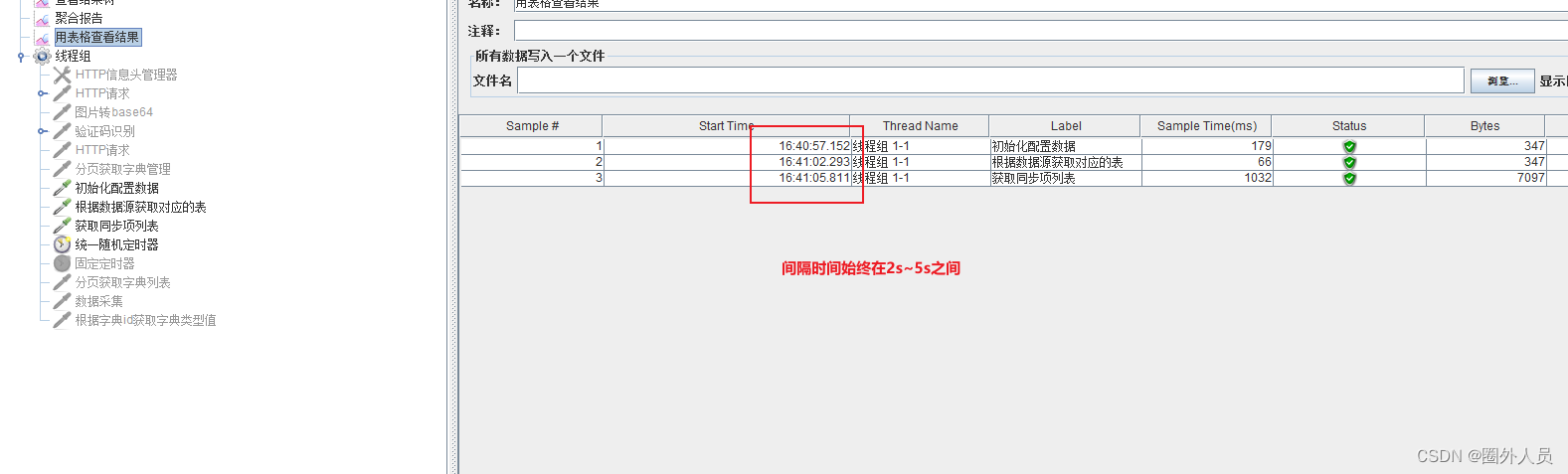
泊松随机定时器:
Lambda (in milliseconds) - 泊松分布值,大部分时间位于该区间
Constant Delay Offset (in milliseconds) - 固定延迟毫秒数
//请求的延迟时间将在[固定延迟, 固定延迟+泊松分布值]区间
大部分请求在延迟4秒左右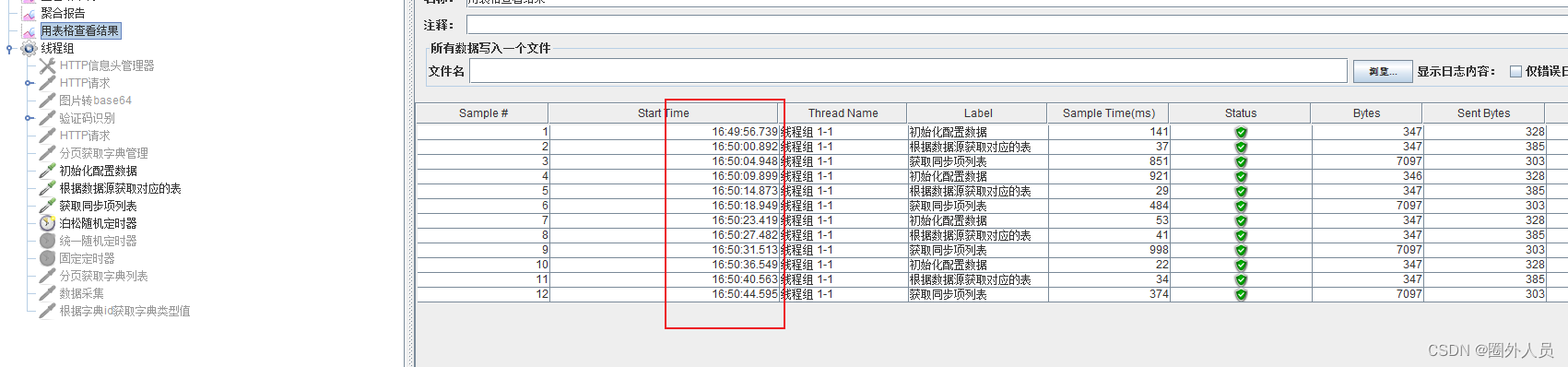
常数吞吐量定时器:
设置Jmeter以指定的吞吐量速度往服务器发送HTTP请求。
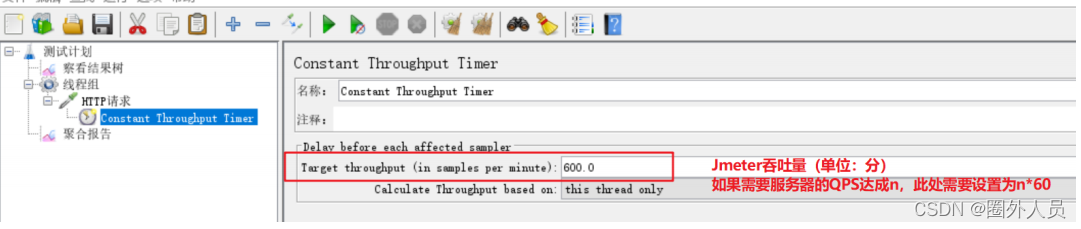
注意:常数吞吐量定时器只是帮忙达到性能测试的负载(压力)要求,本身不代表性能有bug/无bug
对于bug的分析需要通过响应时间来判断
jmeter报告:
聚合报告:
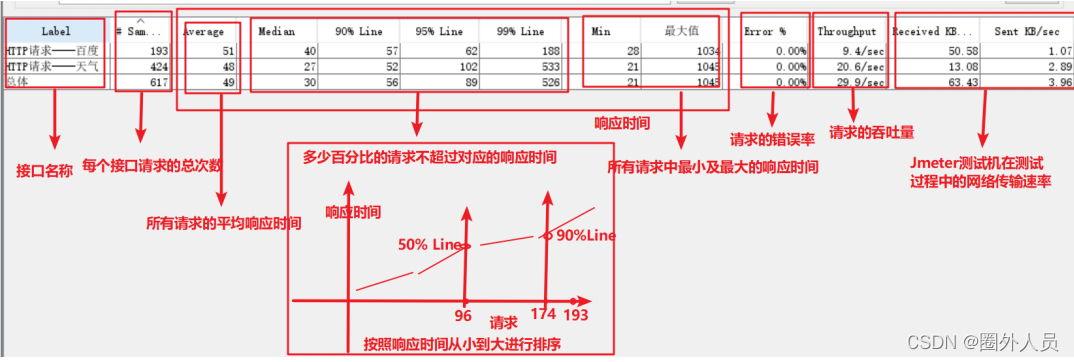
重点关心的性能指标:
- 响应时间
- 观察当前的最大最小值的波动范围
- 如果波动范围不大,以平均响应时间作为最终的性能响应时间结果
- 如果波动范围很大,以90%(经验)的响应时间作为最终性能响应时间结果
- 错误率
- 吞吐量

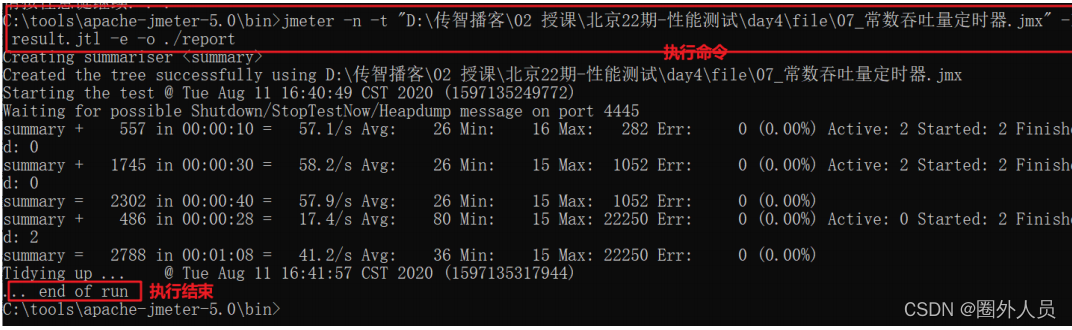
步骤:
1、在bin目下执行上述命令
2、等待脚本执行完成后,进行report文件夹下,打开index.html,可以看到性能测试的详细数据
统计
阶梯式压测:
下载配置:
Stepping Thread Group
是jmeter插件的一种,其作用就是模拟实际的生产情况,不断对服务器施加压力,直至到某个值,然后持续运行一段时间。
下载地址:Download :: JMeter-Plugins.org

将这个文件下载到jmeter文件目录下,并将文件里的JMeterPlugins-Standard.jar文件放到jmeter文件ext目录下
下载一个jmeter的插件管理工具 http://jmeter-plugins.org/get/,jmeter-plugins-manager-1.8.jar放到jmeter文件ext目录下
重启jmeter就可以了

打开jmeter:测试计划——添加——线程(用户)——jp@gc-Stepping Thread Group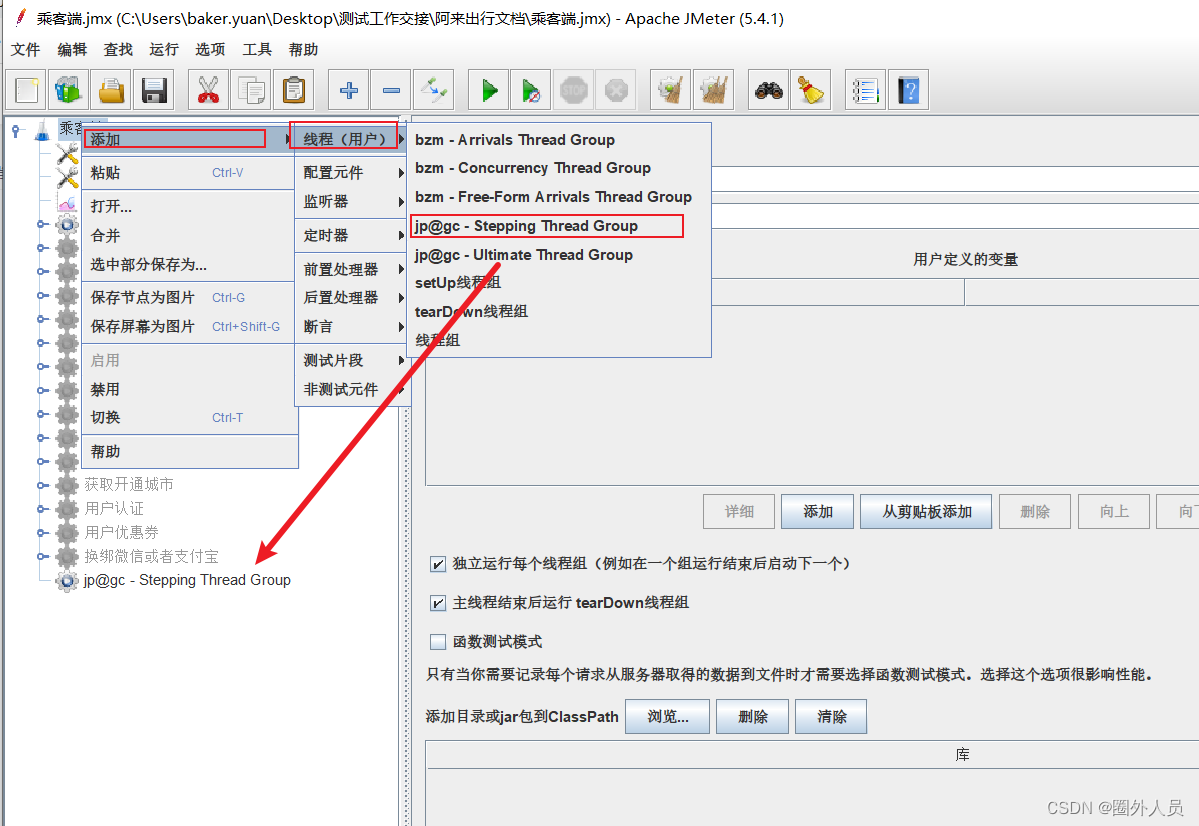

添加监听器:(Active Threads Over Time、Response Times Over Time、Transactions per Second)

插件含义(此处只统计了常用的一些插件):
jp@gc - Active Thread Over Time:不同时间活动用户数量展示
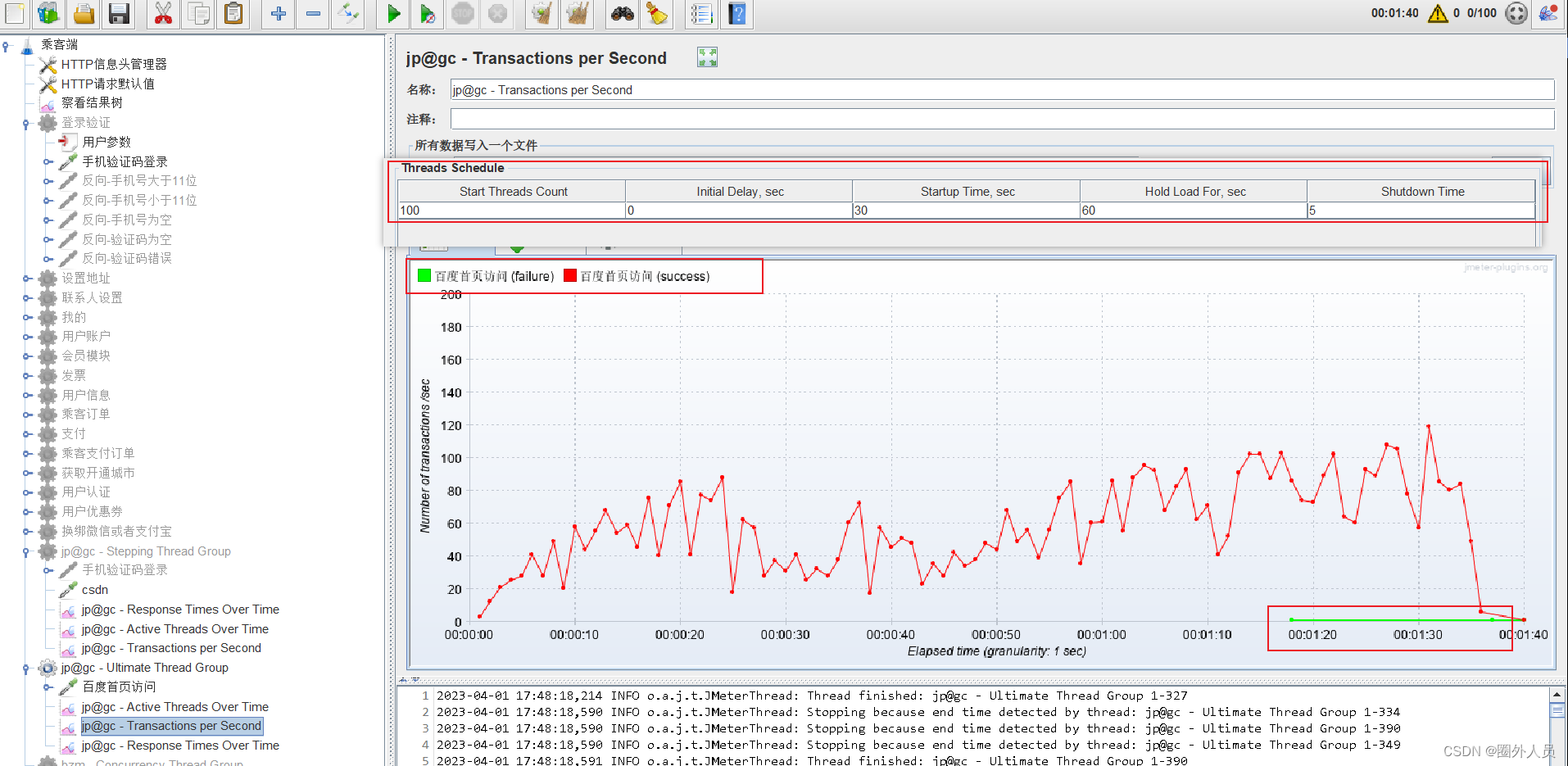
jp@gc - Transactions per Second(简称TPS):每秒事务数【常用】
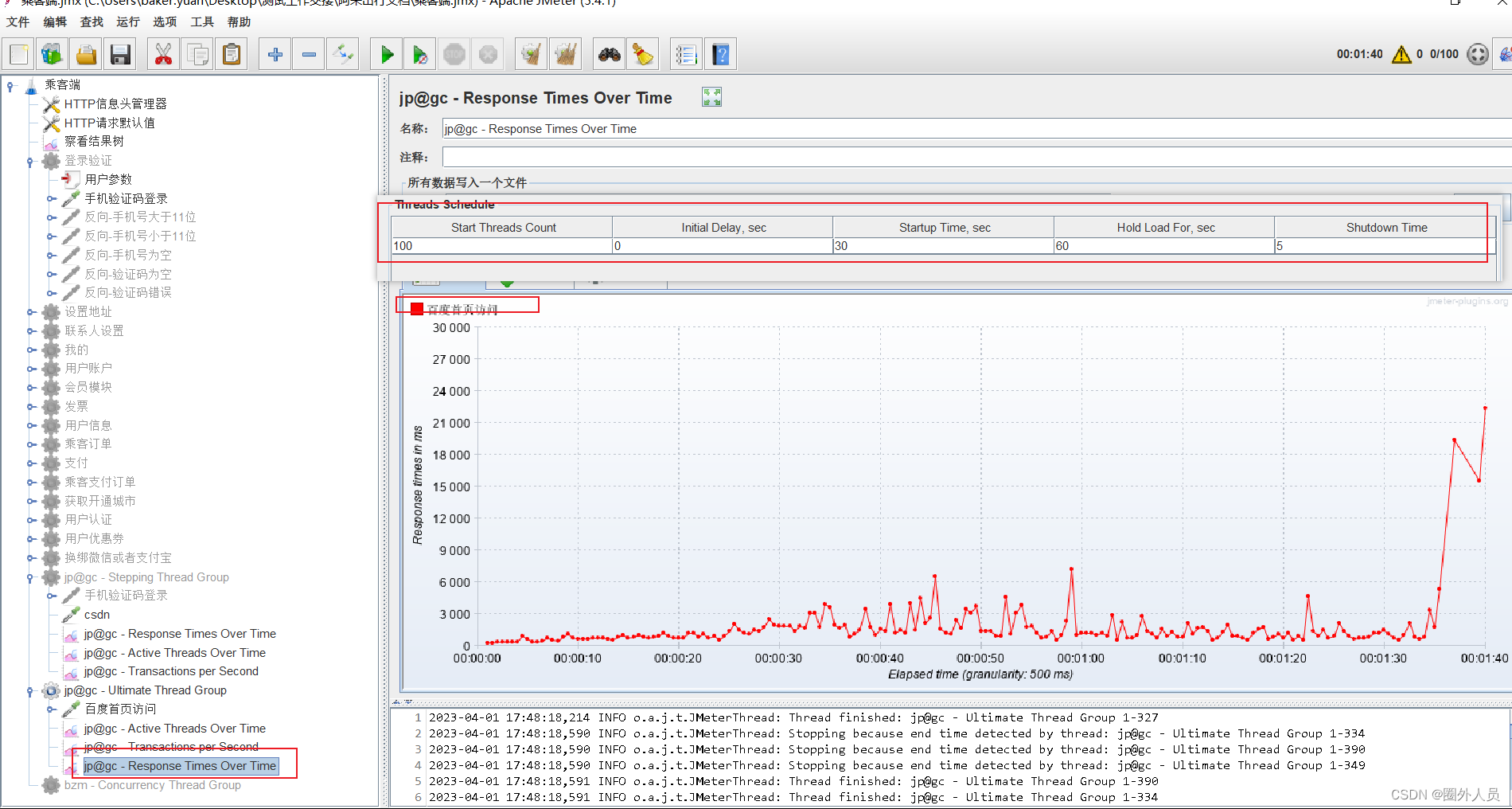
jp@gc - Response Times Over Time(简称TRT):事务响应时间【常用】
jp@gc - PerfMon Metrics Collector:服务器性能监控数据采集器,需要配合ServerAgent监控插件使用
jp@gc - Ultimate thread group:阶梯压测线程组设置(多用于负载测试)
jp@gc - Throughput shaping timer :用来模拟指定的系统吞吐量
jp@gc - Intel - Thread Communication PerProcessor:前置处理跨线程组传递数据
jp@gc - Intel - Thread Communication PostProcessor:后置处理跨线程组传递数据
2、Ultimate thread group:
添加:
参数配置:
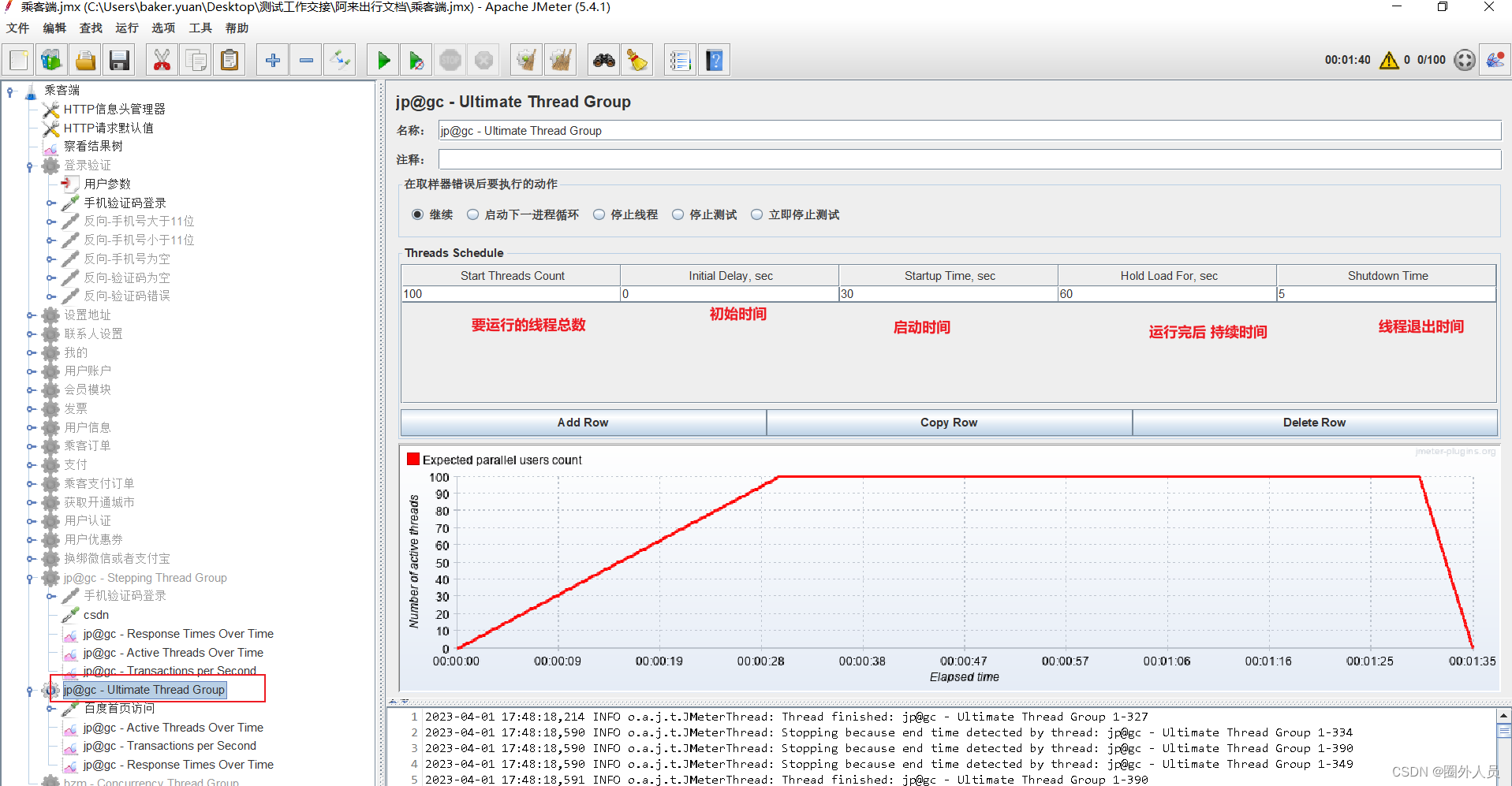
监听器查看:
jp@gc - Active Thread Over Time
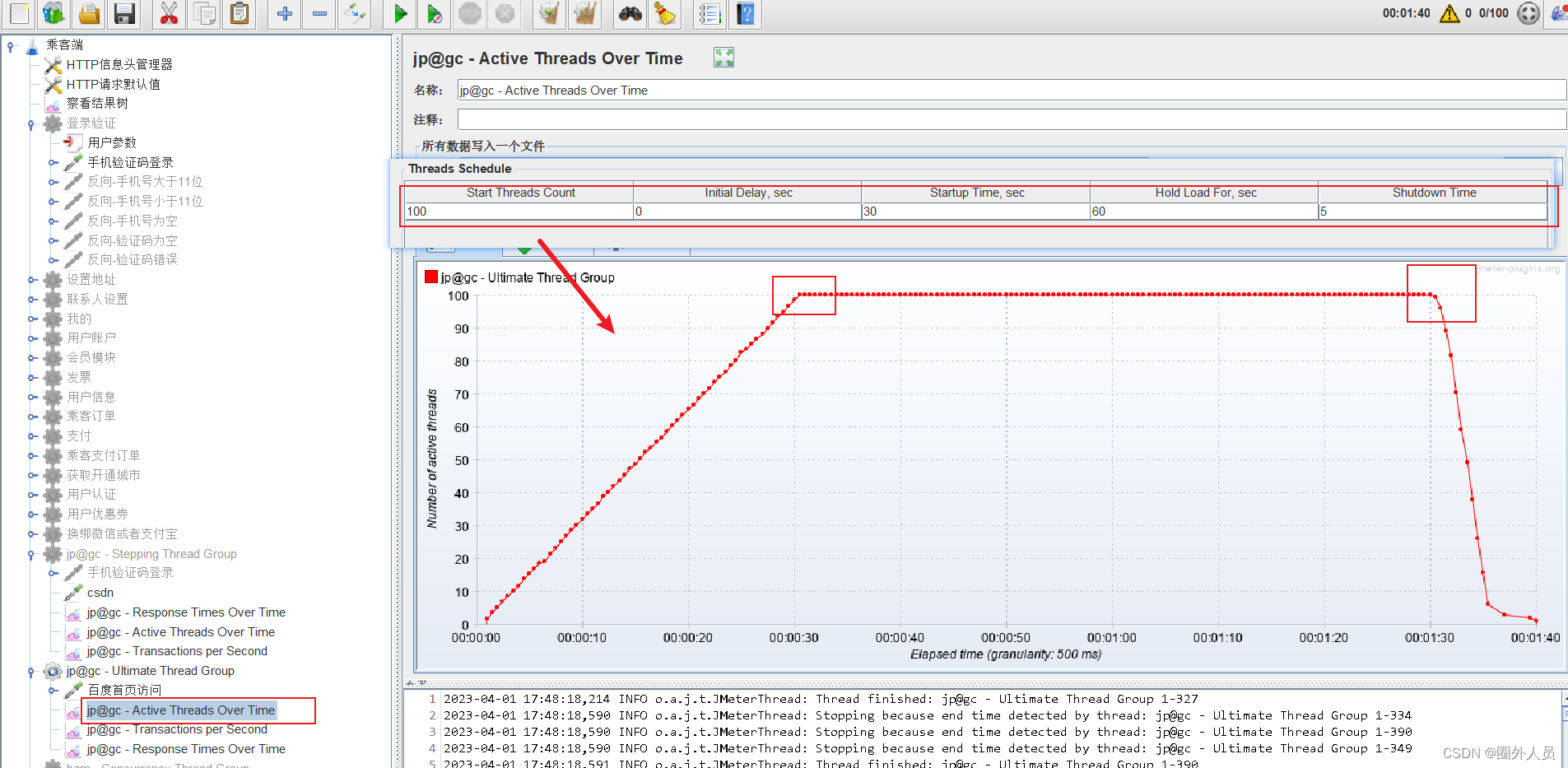
jp@gc - Transactions per Second(简称TPS)
jp@gc - Response Times Over Time(简称TRT)
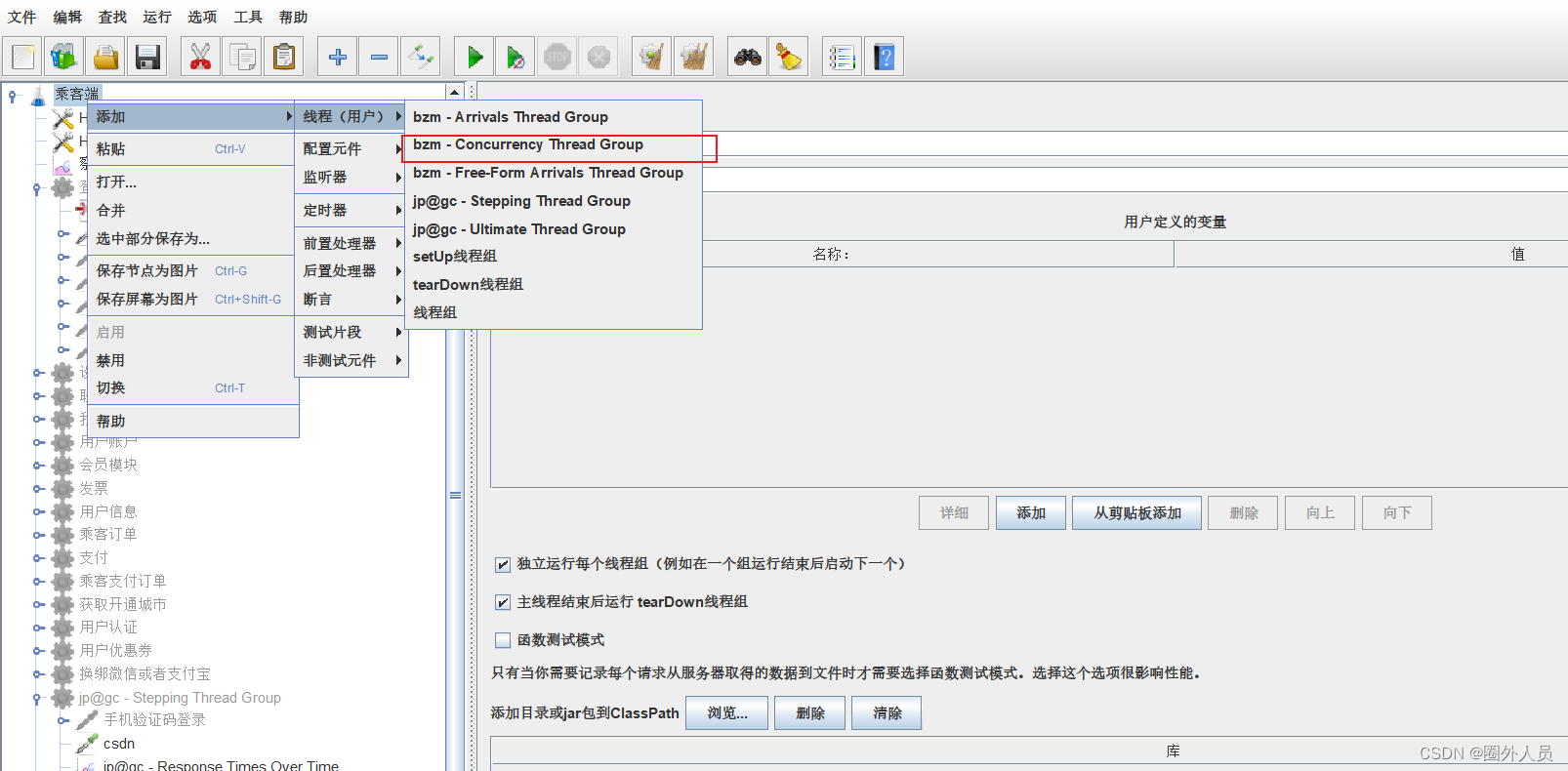
3、Concurrency Thread Group
添加:
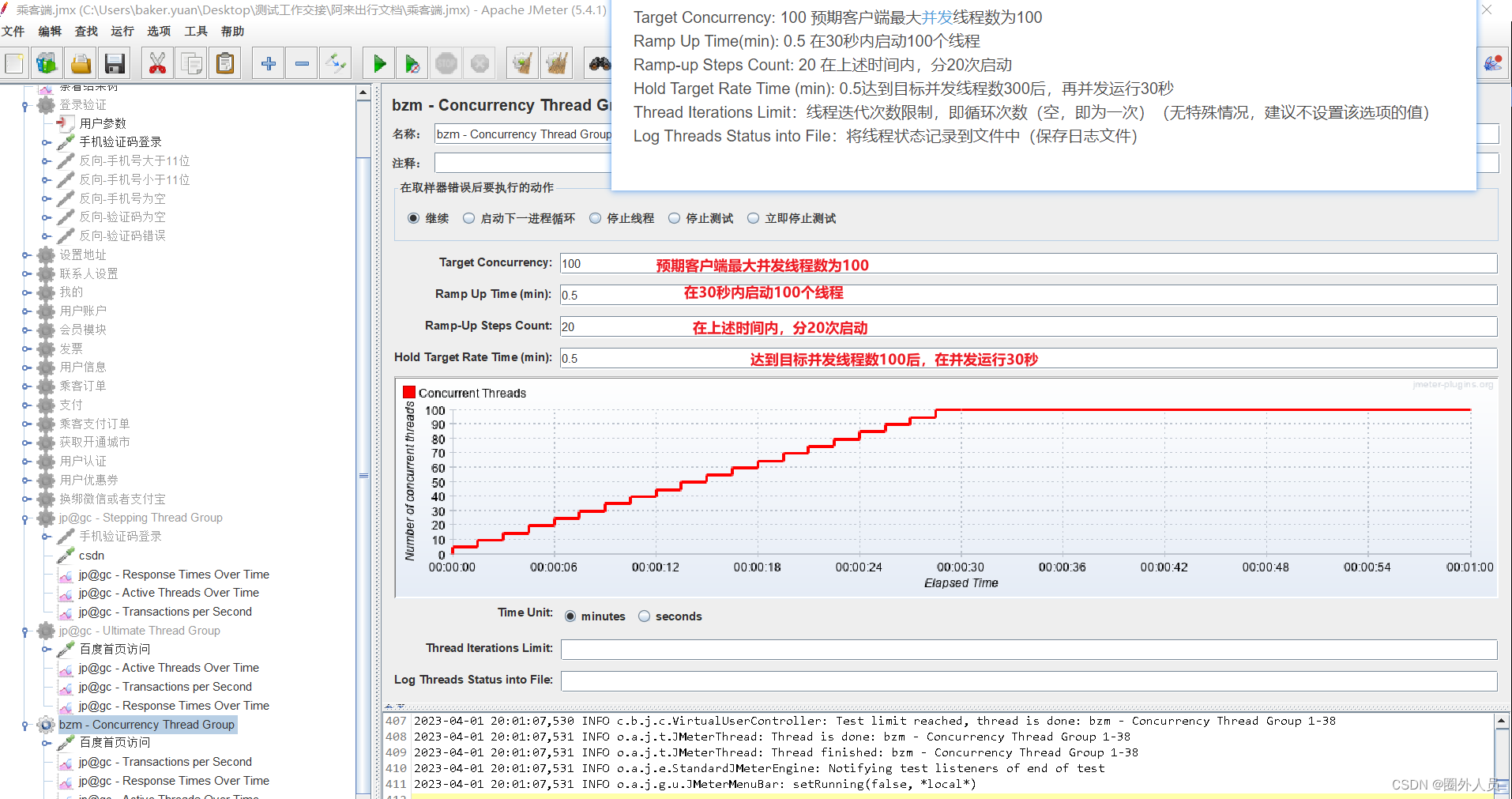
Target Concurrency: 100 预期客户端最大并发线程数为100
Ramp Up Time(min): 0.5 在30秒内启动100个线程
Ramp-up Steps Count: 20 在上述时间内,分20次启动
Hold Target Rate Time (min): 0.5达到目标并发线程数300后,再并发运行30秒
Thread Iterations Limit:线程迭代次数限制,即循环次数(空,即为一次)(无特殊情况,建议不设置该选项的值)
阶梯加压找到性能拐点:
在我们实际工作中,压力通常用RPS来表示。RPS(Request Per Second)每秒钟的请求数,它代表对服务器实际发出压力的大小。
RPS由并发数,和服务器的响应时间(RT)决定,他们之间的计算公式为:并发数=RPS*RT
添加一个线程组:
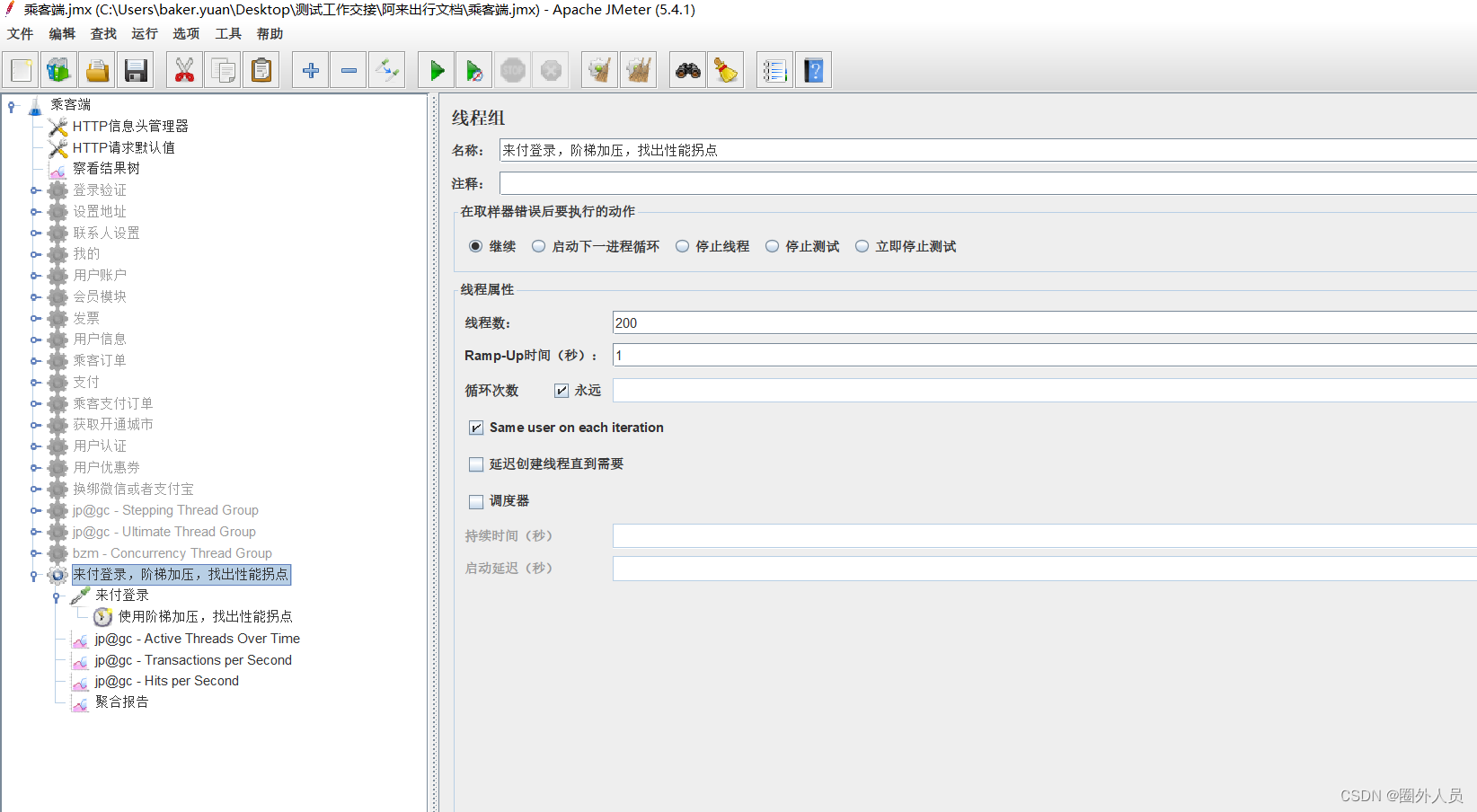
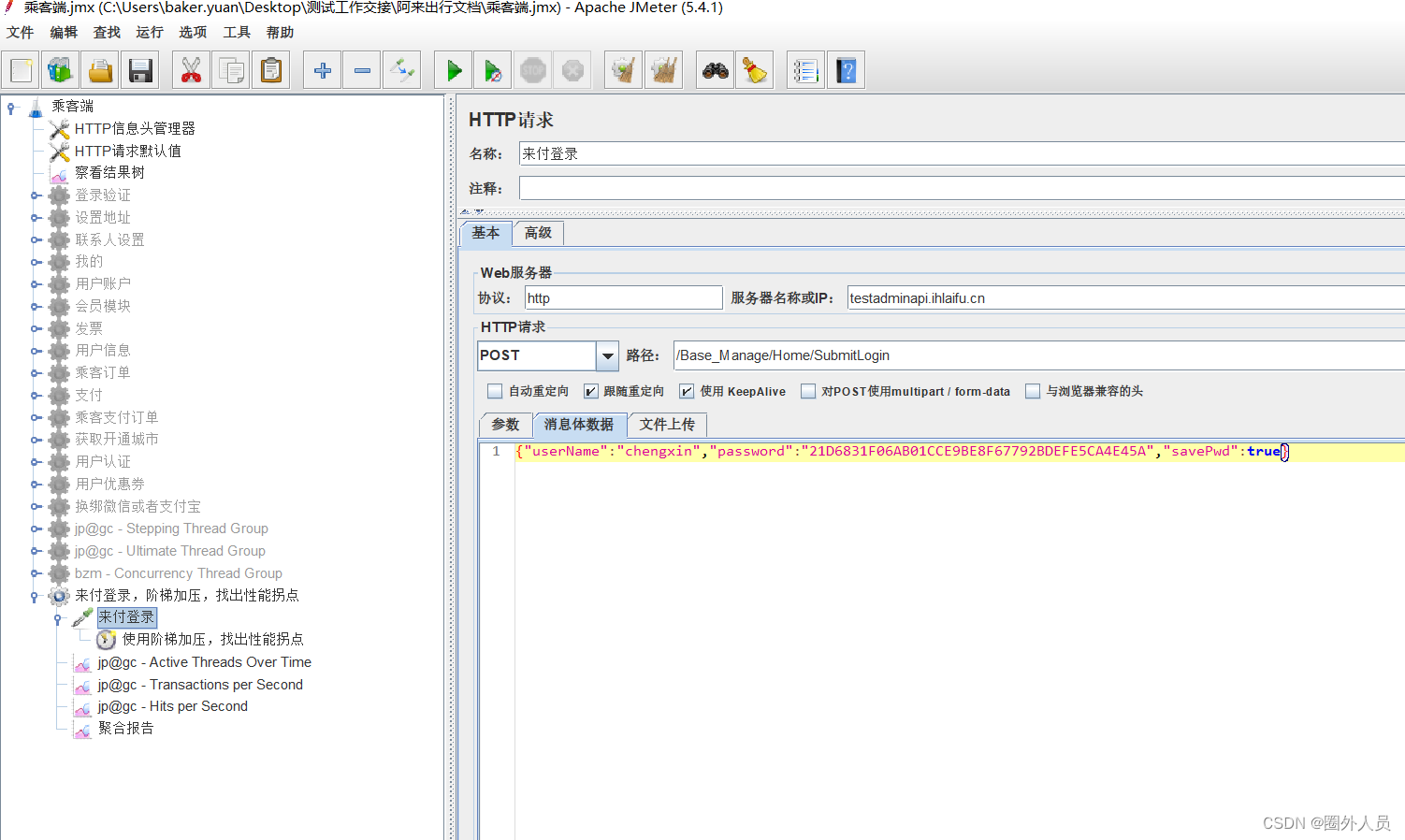
设置一个请求登录接口:
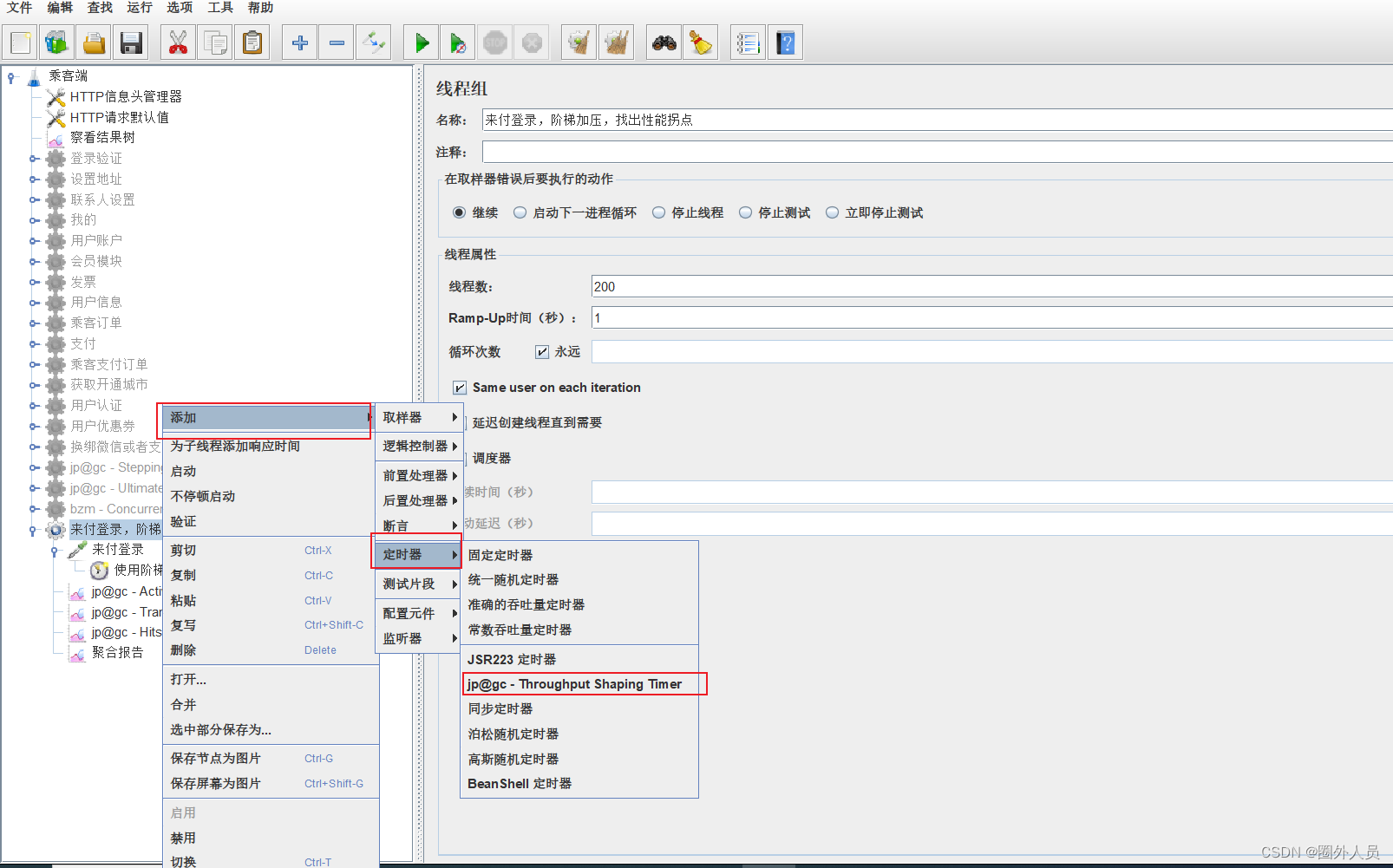
添加吞吐量控制器:
 在9秒处,之前的时间都是一个逐步上升的情况,可以说1秒钟最大请求数为158
在9秒处,之前的时间都是一个逐步上升的情况,可以说1秒钟最大请求数为158

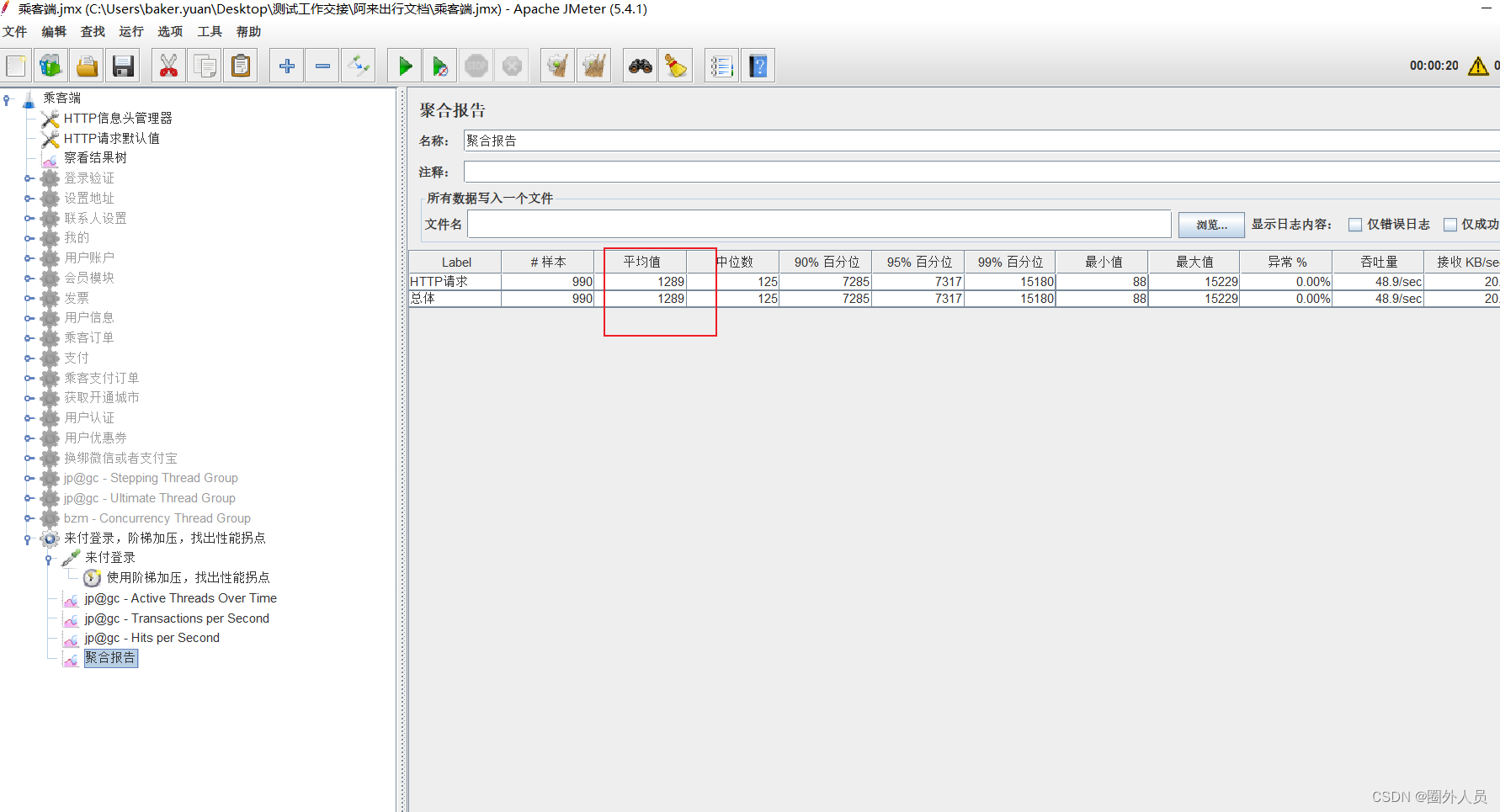
由之前的公式:并发数=RPS*RT,我们可以算出并发数:158*1.289=203,也就是说1秒钟可以同时有203个用户登录页面
第一次找性能拐点,为了保证我算出来的数据是正确的,我还反向推理了一下,我将原本的200个并发数改成了300 ,然后果不其然就报错,然后改成了250,还是一样接口后面就出错,最后我把并发数改成204再跑了一次脚本,最后的接口也是出错了,改成203后就所有接口都正确请求
有个疑问:
为啥每次请求的数据每秒最大请求数和响应时间是不同的,那就没办法精确实际最大请求
多用户同时登录,获取到多用户token去实现多用户请求其他(登录进去后)的接口
djmeter进行csv参数化,获取不同用户的登录token(实现多用户调用同一个接口)_jmeter怎么提取token并保存-CSDN博客
参考上方博主内容,实操如下:
一、准备多用户测试数据
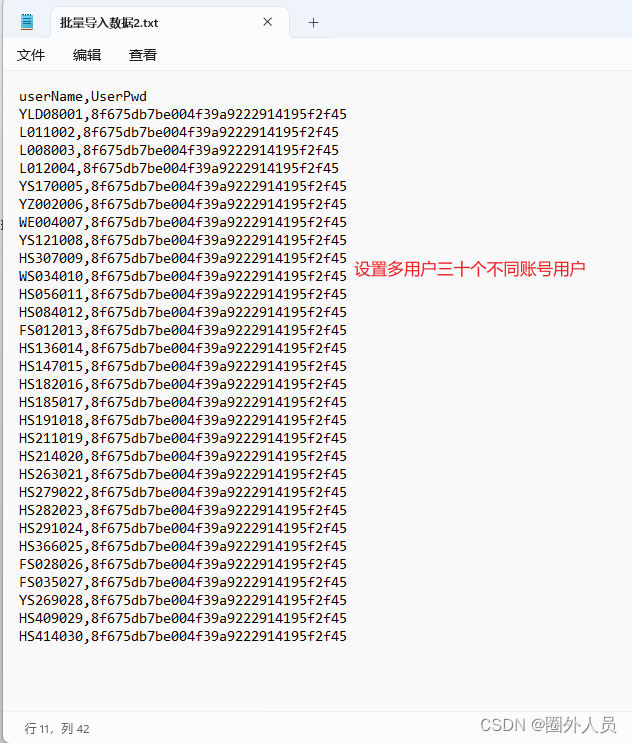
2、设置csv批量文件导入,具体参考教程使用
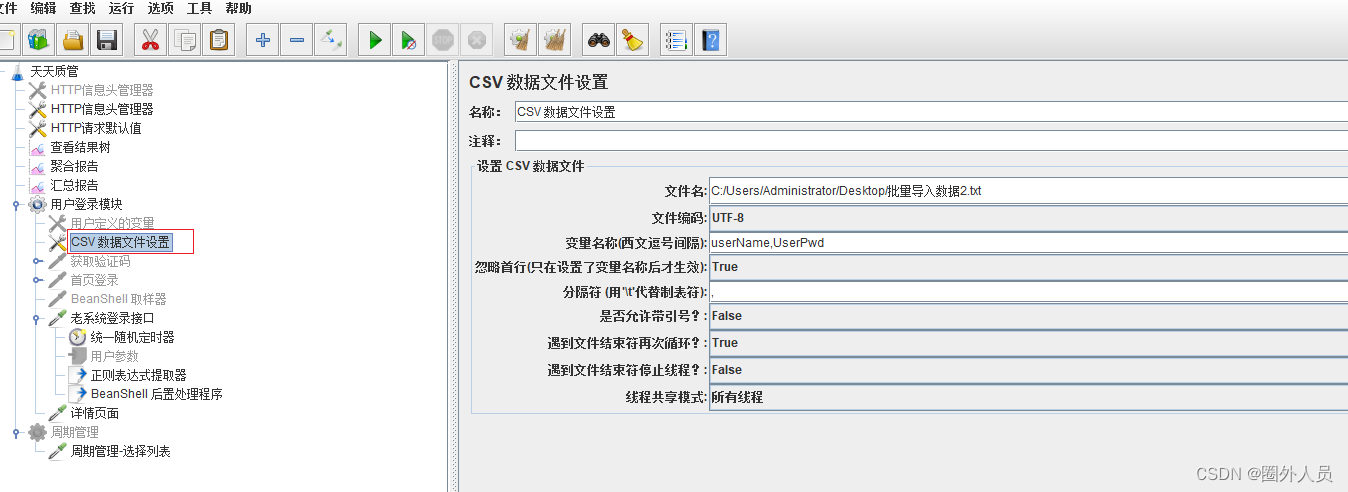
3、填写登录接口的相关请求参数
4、使用正则表达式,将登录请求的三十个用户返回的token提取出来
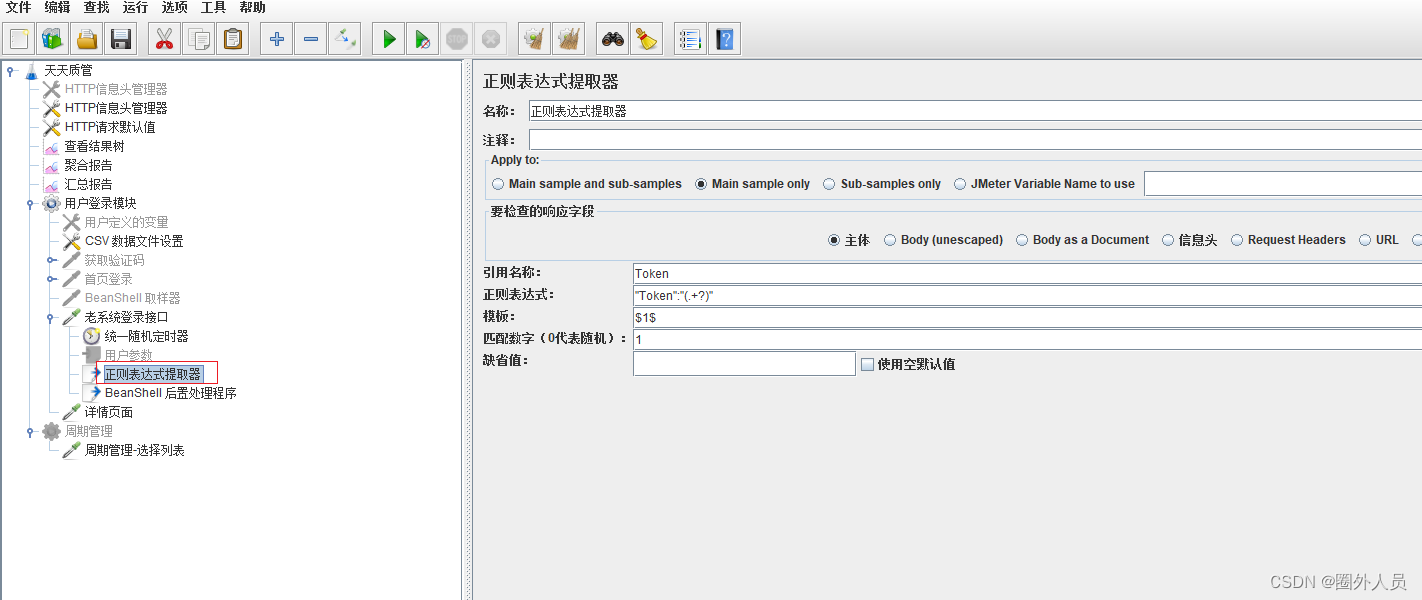
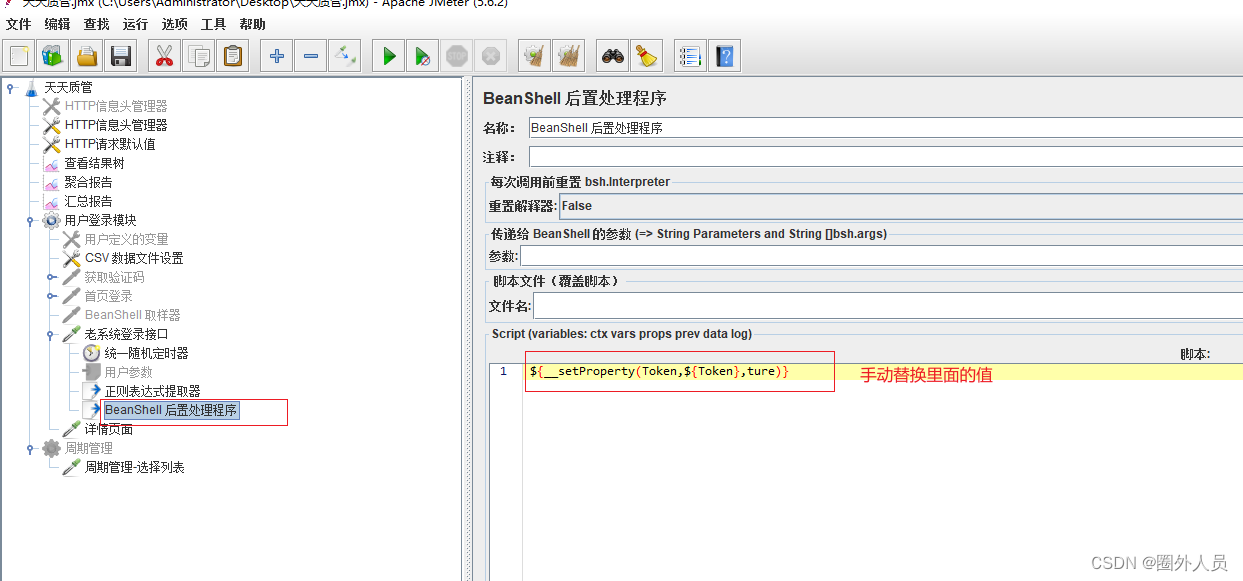
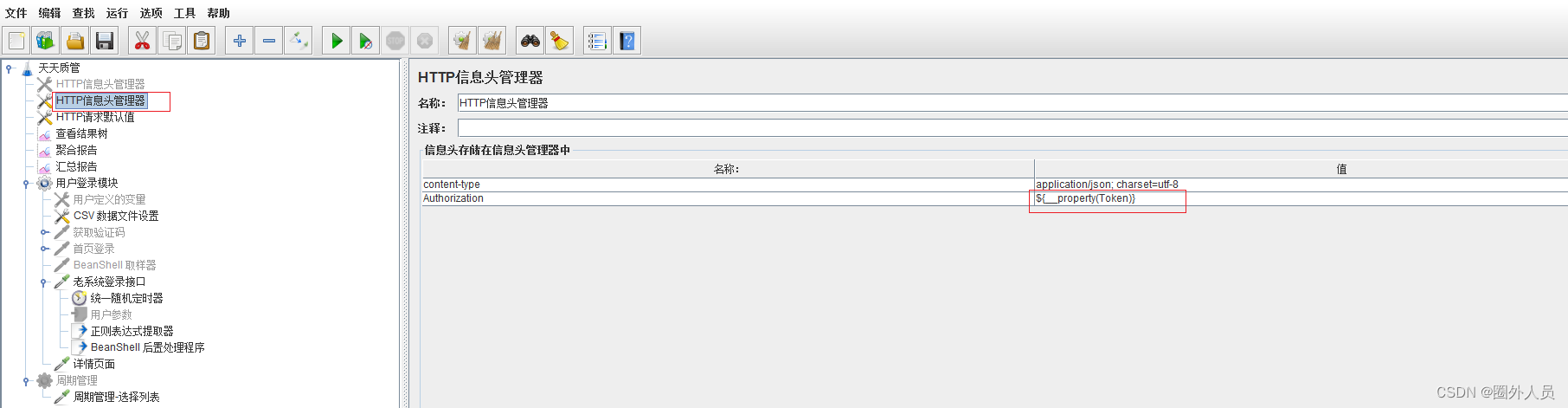
5、创建一个BeanShell后置处理程序,将${__setProperty(access_token,${access_token},ture)}值替换,然后粘贴在BeanShell后置处理程序里面,且在http信息头管理器里面添加加 ${__property(access_token)}进行获取登录返回的token
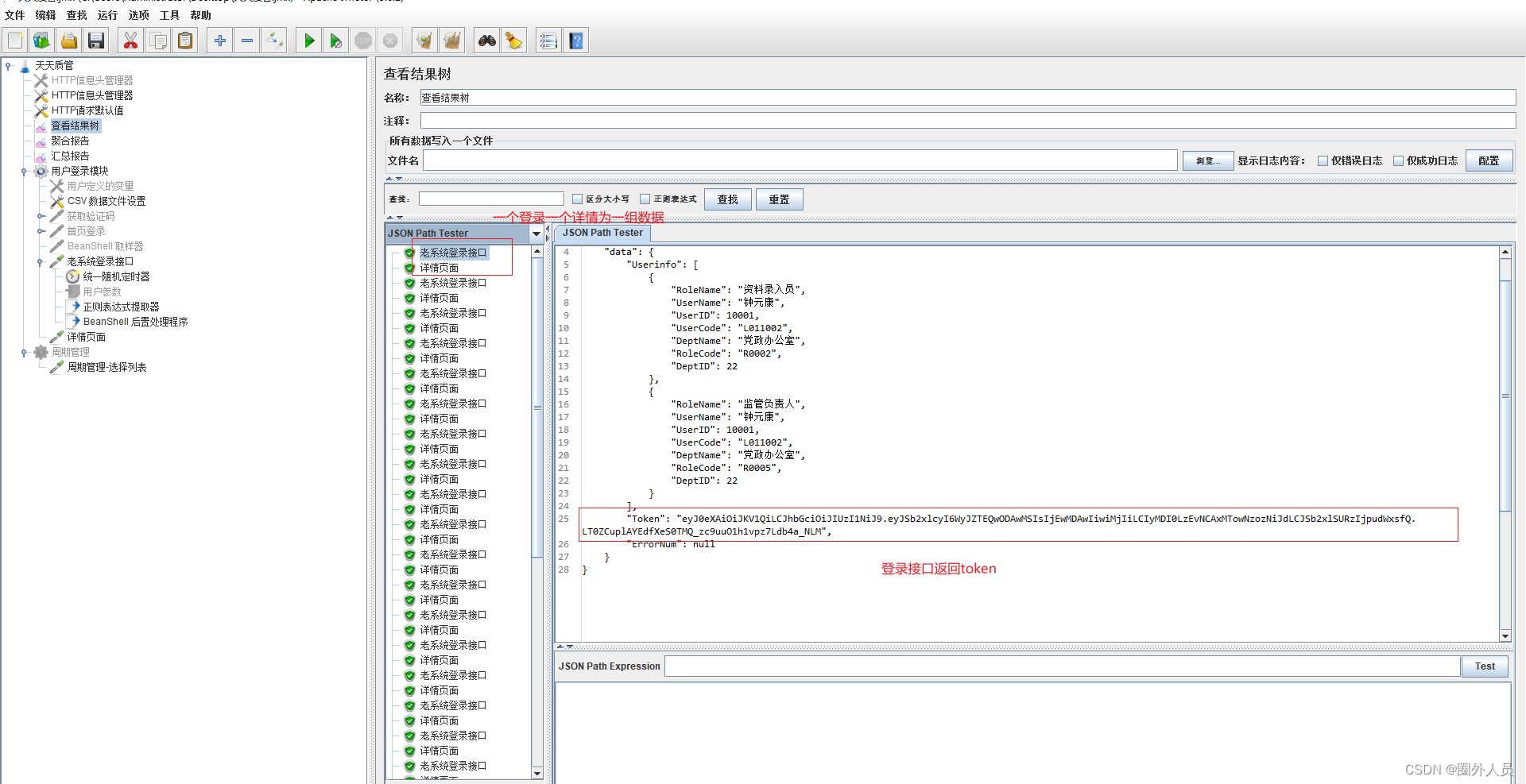
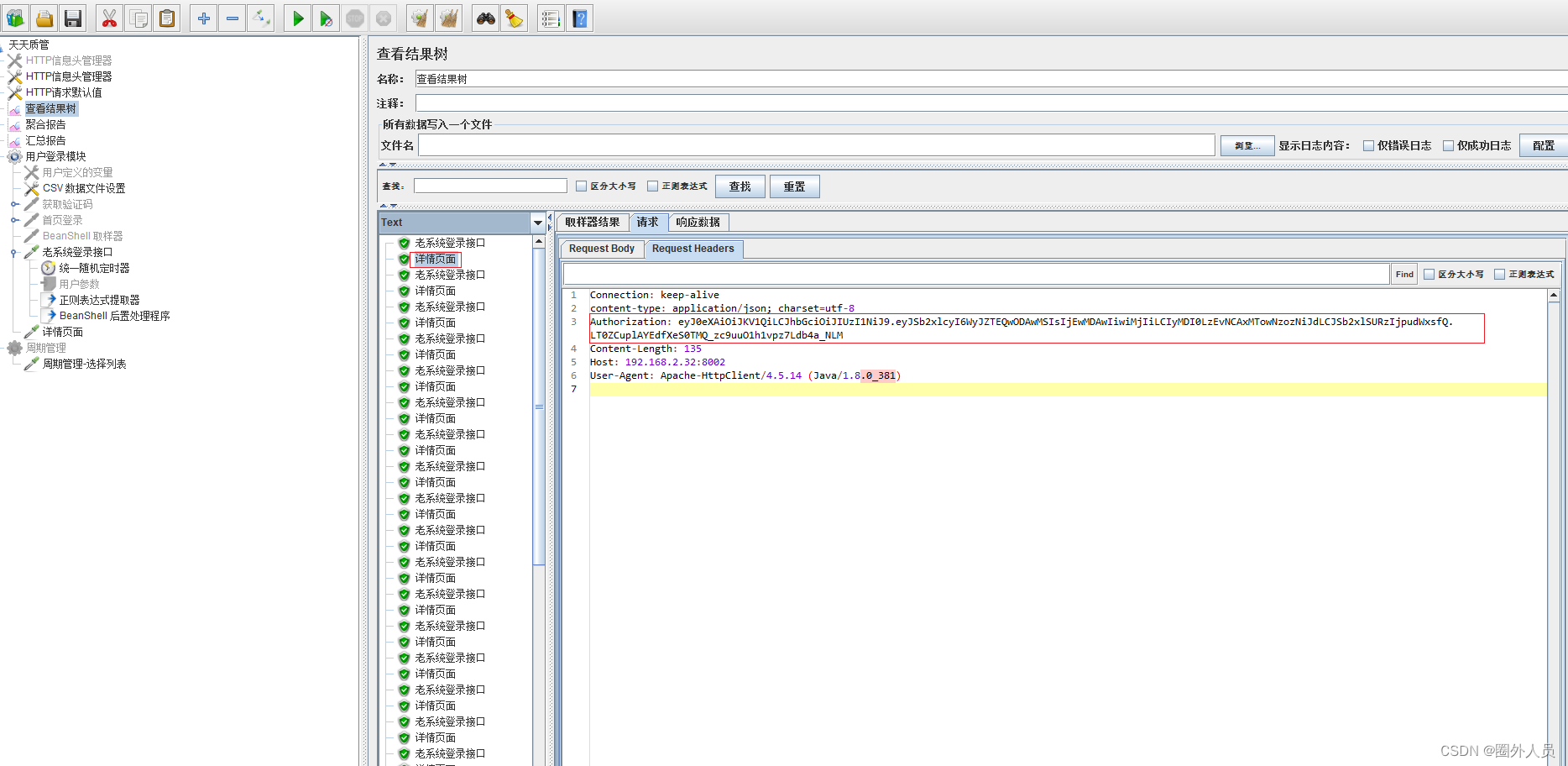
6、添加详情接口,然后执行登录和详情,对比发现登录返回的token,就是查询详情请求头里面的Authorization
处理多个接口测试并发的顺序要执行一致
参考:高级性能测试系列《21.临界部分控制器:如何让锁变成动态锁,生成多把锁? 》...-CSDN博客
一、在线程组逻辑控制器里面添加临界部分控制器
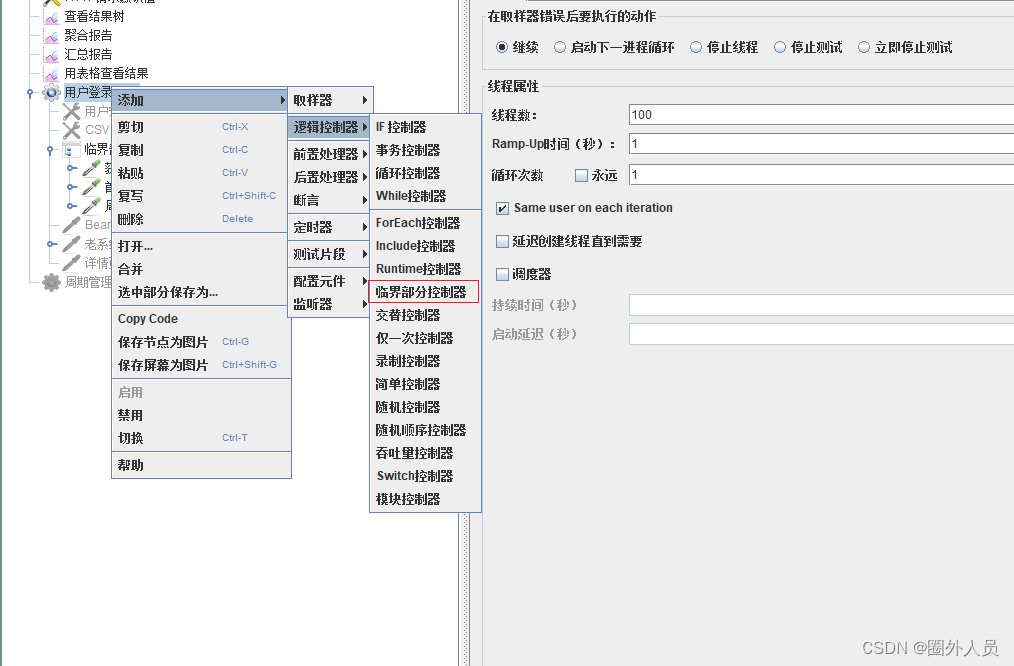
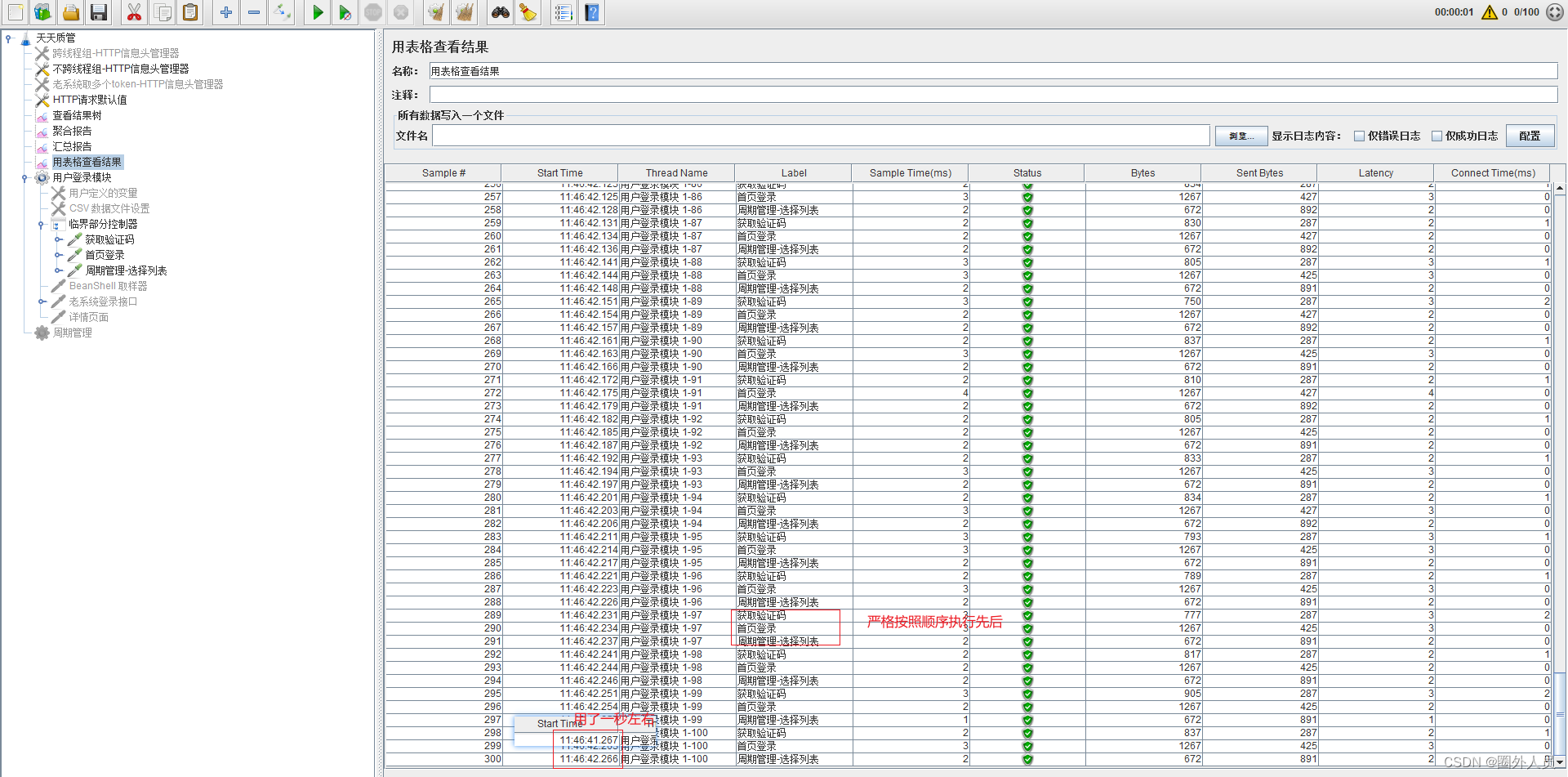
二、把接口放在添加好的临界部分控制器下面 (未设置函数)

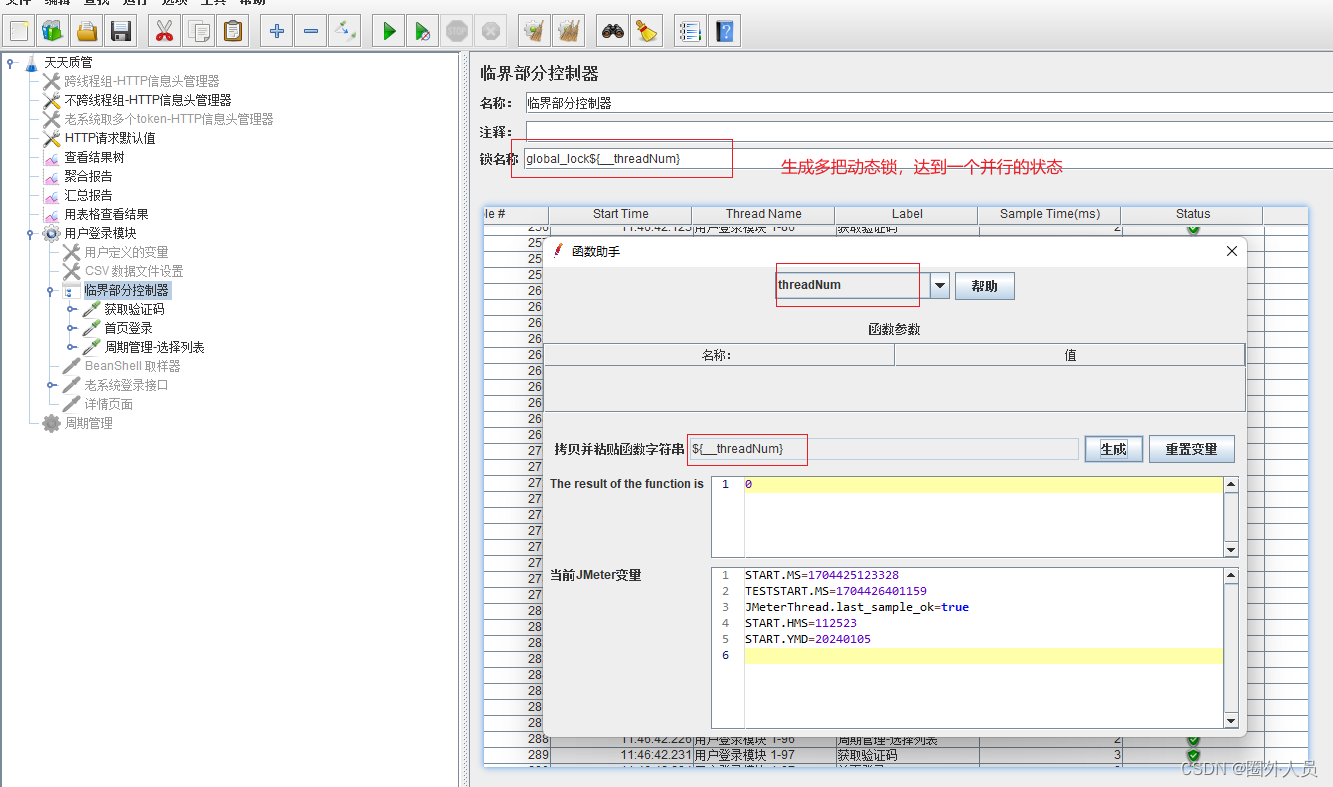
三、用函数将临界部分控制器的缺陷弥补
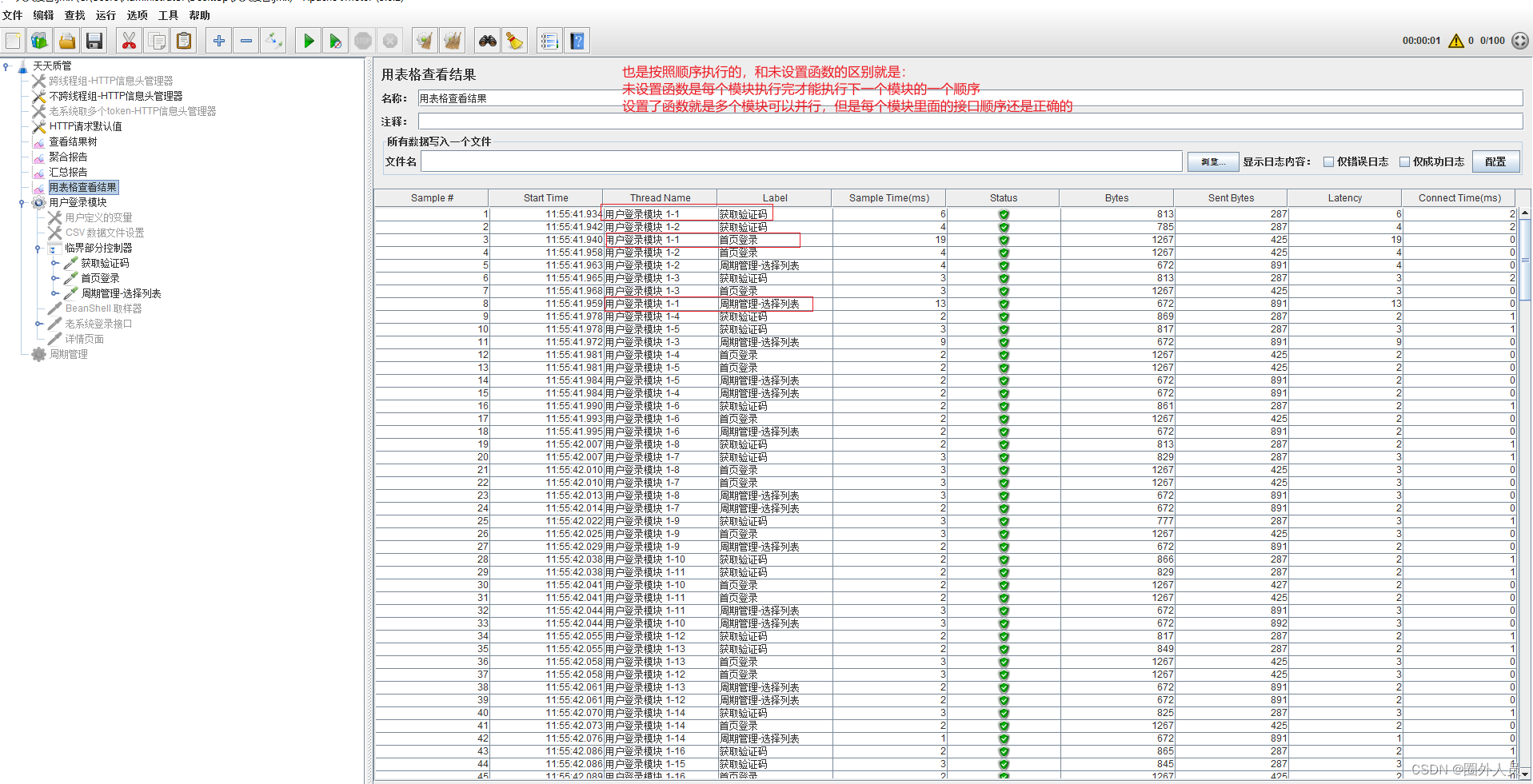
工作中遇到的问题:
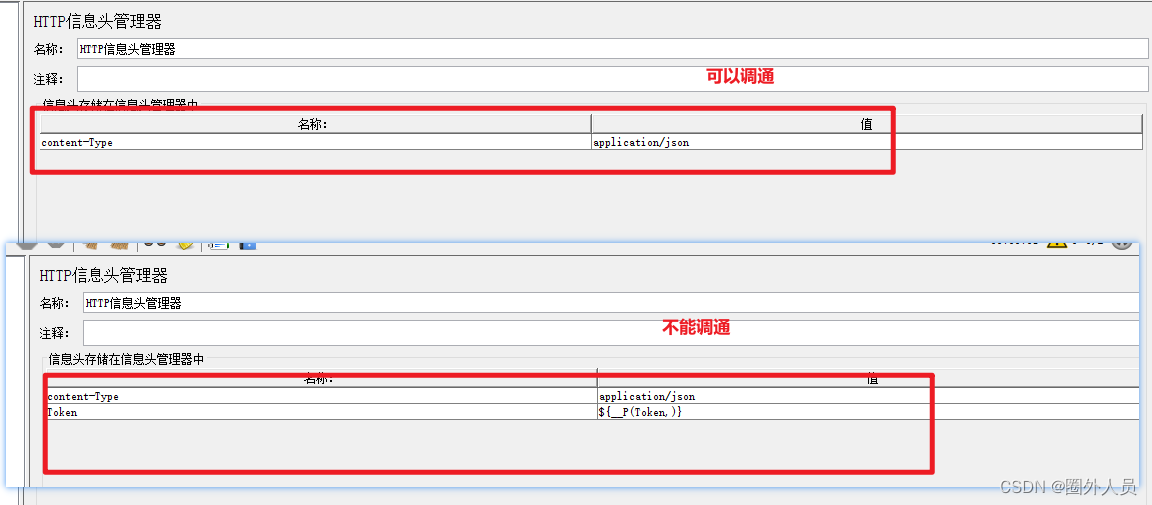
关于HTTP信息头管理器:有时候一个接口找不到问题和保错,就看下HTTP信息头管理器,之前遇到一个接口,一直都是通过token直接全局变量,后续突然一个不需要token的接口再使用这个信息头就调不通,找了很久的问题,还是求助同事排查出来的
报错解决:请求编码加上UTF-8

报错2:

报错3:
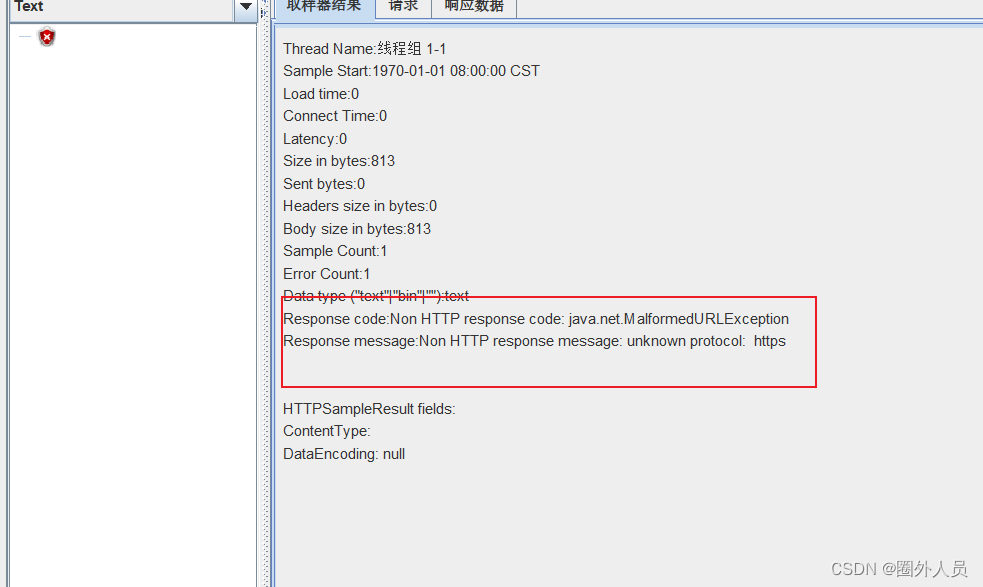
解决:检查发现在单独的请求协议框中带上'https'后能正常请求,删除后再次报错,再次检查配置元件‘HTTP请求默认值’中的协议框,发现‘https’的前面多了一个空格键,删除空格后恢复正常。















 3675
3675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









