






参照
https://clickhouse.com/docs/en/optimize/skipping-indexes
概述
许多因素会影响ClickHouse查询性能。大部分场景下最关键的因素是,当解析评估查询WHERE子句条件时,ClickHouse能否使用primary key。因此,一个有效的表设计,就是要根据大部分查询模式,选择一个primary key。
然而,无论如何仔细优化设计primary key,仍然不可避免还是有查询用例无法有效使用primary key的情况。用户通常依赖ClickHouse按时间序列类型处理数据(例如本日销售额,本月销售额,销售额同比、环比),但是他们常常还希望从其他业务纬度来分析这些数据,例如customer id,website URL,或者 产品编码。在这种(多维度,不仅仅是时间纬度)分析的情况下,查询性能会变差,这是由于WHERE子句条件中所要求的column的全表扫描。不过即使这样,ClickHouse仍然是相对较快(相对传统行式rdbms),只是解析百万或者十亿级非索引查询将会慢于那些基于primary key的查询。
传统的关系型数据库,针对这种情况的处理方法是,将一个或者多个“secondary”索引绑定到表上。这(指rdbms索引)是一个二叉树(b-tree)结构,让数据库能够在O(log(n))时间内找到硬盘上所有匹配的行,替代一个表扫描的O(n)时间,其中n是行数。但是,这种类型的secondary index不适合ClickHouse(或者更准确的说column-oriented databases都不能使用这类索引),因为在硬盘上,它没有单独的行(行不唯一)用于增加索引。
相反,ClickHouse提供了一种不同类型的索引,在某些情况下,它能够显著提高查询速度。这些结构被标签化为“Skip”indexes,因为它们能够让ClickHouse忽略读取很多数据,这些数据被确认没有匹配(查询)的值。称为忽略索引,使用这种索引时,整个数据扫描过程看着像跳跃,也可以称为跳跃索引。
基本操作
用户只能在*MergeTree家族(系列引擎)的表上使用Data Skipping Indexes。每个数据忽略索引(创建时)都有四个参数
- Index name 索引名是用来在每个partition创建索引文件。当dropping或者materializing索引时,索引名也是必须的参数。
- Index expression 索引表达式是被用来计算一系列值,这些值被存储在index。它可以是columns的拼接,simple operators,and/or a subset of functions determined by the index type.
- TYPE 索引的类型控制(表达式的)计算,(计算结果)决定了要忽略读取的index block。
- GRANULARITY 每个索引块的颗粒度。例如,如果primary table index的颗粒度是8192rows,这个参数被设置为4时,索引块存储4*unit,unit取决于索引类型,minmax则是最大值最小值两个值,那么每个索引块能管理的行将会是32768rows。
primary table index的颗粒度是建表语句中的settings指定,供primary key或者order by所使用,而此处跳跃索引是secondary index。
当用户创建了一个data skipping index时,那么对应这张表,将会在每个data part directory生成两个额外的文件。
- skp_idx_{index_name}.idx 包含ordered expression values(索引表达式)
- skp_idx_{index_name}.mrk2 包含进入关联的data column files的corresponding offsets
当执行一个查询和要读取相关column files时,如果WHERE子句过滤条件的某些部分匹配到了skip index,那么ClickHouse将使用index file data 判断相关的数据块是要被处理还是跳过(假设这些要处理的数据块还没有被primary key排除)。简单示例如下
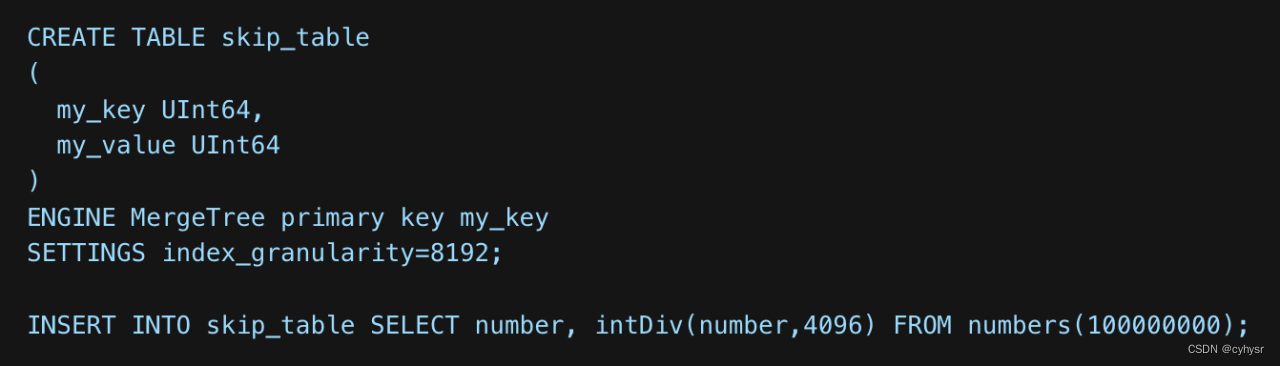
当执行一个简单查询,该查询没有使用primary key,10亿行(100 million)都会被扫描处理。
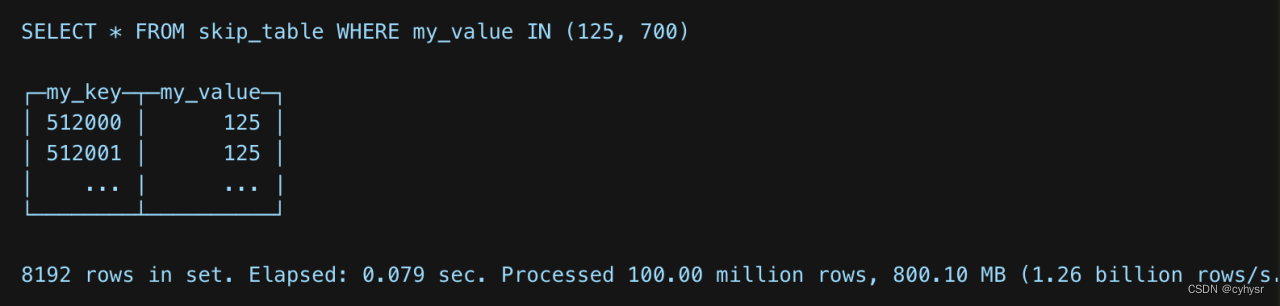
现在增加一个基本的skip index

通常skip index只对newly inserted data(增加skip index之后增加的数据)生效,所以如果只是增加上述索引,那么上述查询不会受到任何影响。
要索引现有数据,使用如下语句

再次执行查询
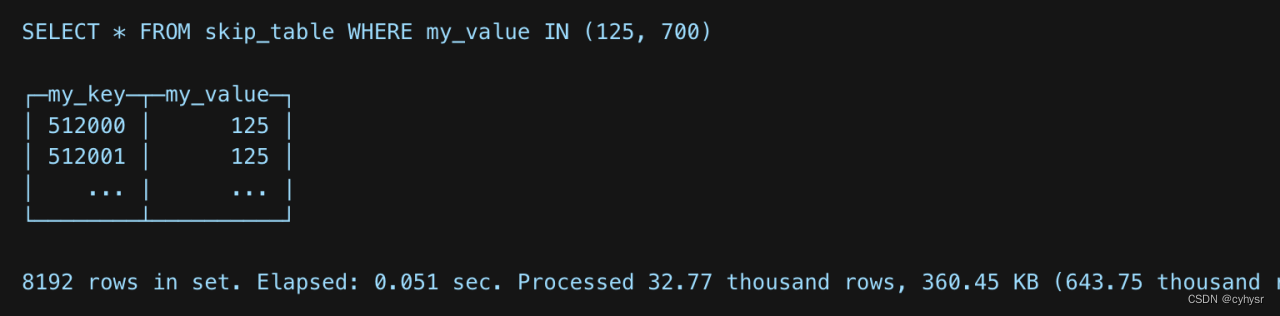
不再是处理800.10MB的100millionrows的数据,ClickHouse只是读取了360.45kilobytes的32768rows数据。four granules of 8192 rows each.
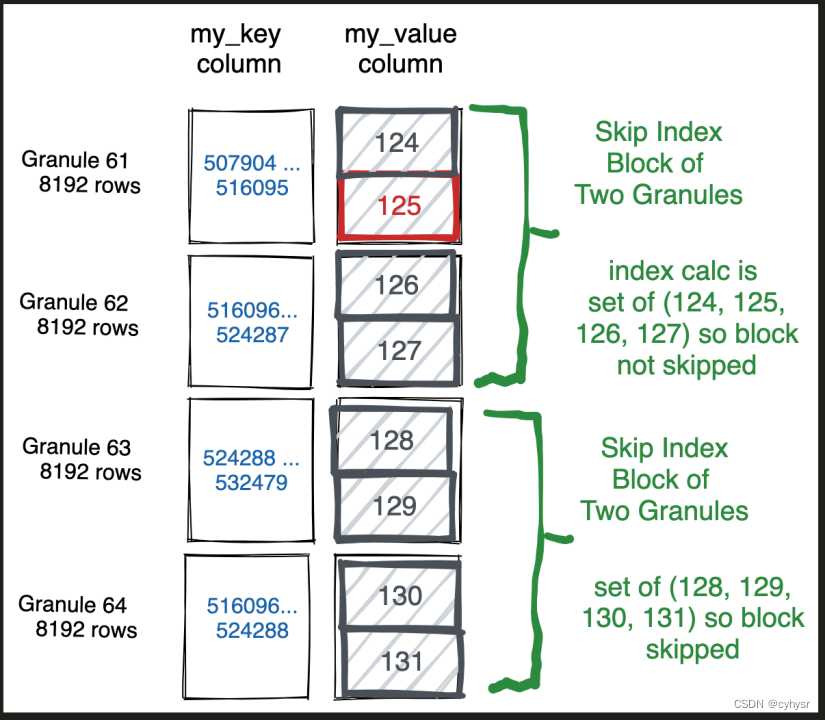
下图演示了,带有my_value字段值125的4096行数据如何被读取和选择的,以及剩下的行如何被忽略不再读取。
通过enabling trace,可以在执行查询时,用户能够访问到更细节的skip index使用信息。从clickhouse-client进行设置,具体如下

索引类型
skip index type 共有三类:minmax、set、Bloom Filter Types。
minmax
这个轻量级索引类型要求无参。它会存储索引表达式对应每个数据块的最小值和最大值。这种类型(的索引)非常适合按值松散排序的列。
set
这个轻量级索引类型要求一个参数,该参数是一个set允许存储的每个数据块中值的个数(0表示允许无限数量的离散值)。set会包含数据块中的所有值,如果个数超过了set设置的值,后来超出的值则为empty。如果指定颗粒度是2,那么索引块大小应该是2*set。该类型适合于每个颗粒度的set内基数低,但整体基数更高的列。
实践操作
句法如下
alter table tablename add index indexname indexexpression type indextype granularity 2;
以CT_OD_IC_FLOW为例,实践操作索引。
进入system库,查询tables获取CT_OD_IC_FLOW状态
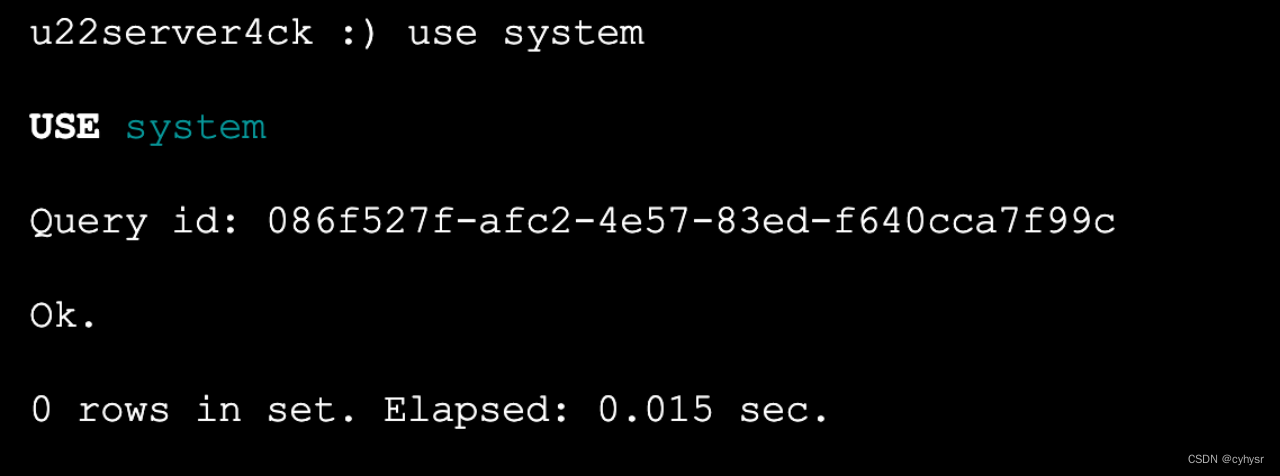
查询表概况
select data_paths,sorting_key,primary_key,total_rows,total_bytes from tables where name='CT_OD_IC_FLOW'
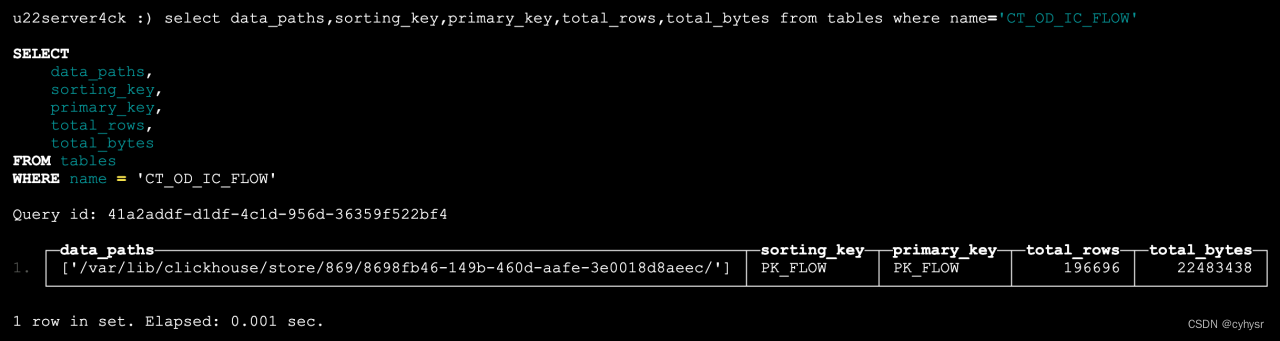
查询索引情况
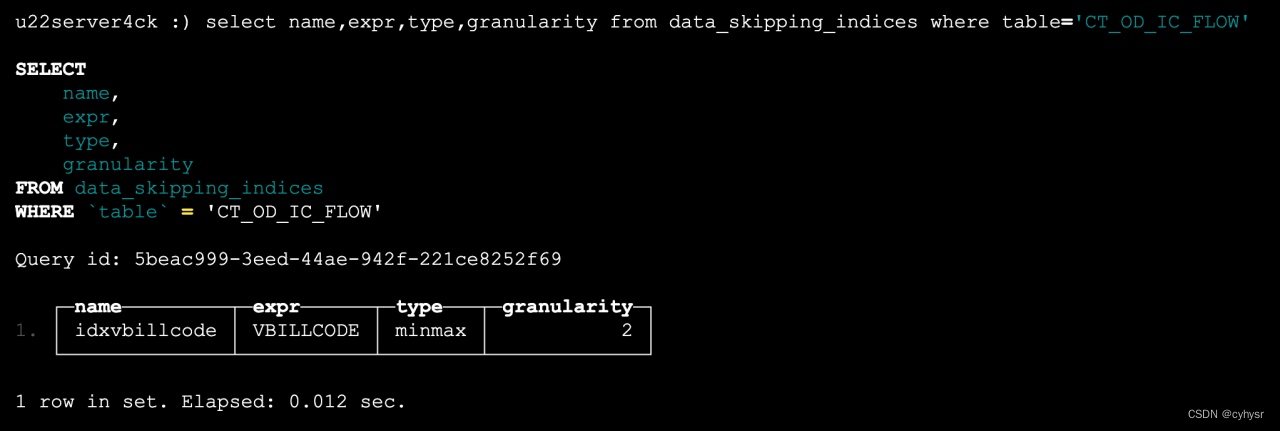
select name,expr,type,granularity from data_skipping_indices where table='CT_OD_IC_FLOW'
查询结果显示,目前CT_OD_IC_FLOW并没有secondary index。
创建minmax类型
alter table CT_OD_IC_FLOW add index idxvbillcode VBILLCODE type minmax granularity 2;
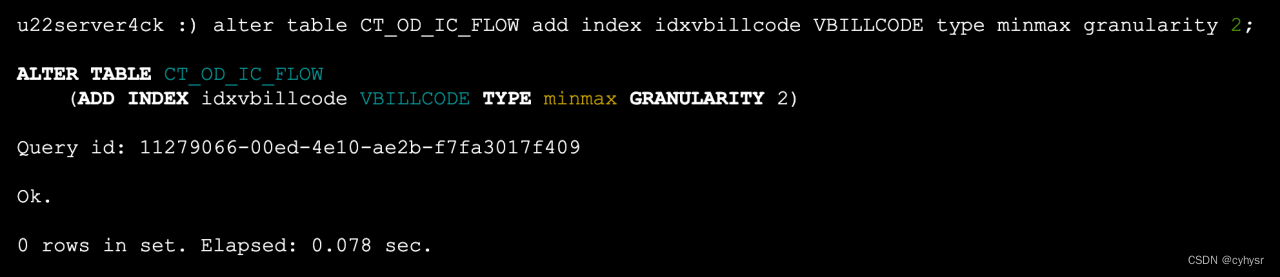
再次查询索引情况
alter table CT_OD_IC_FLOW materialize index idxvbillcode;
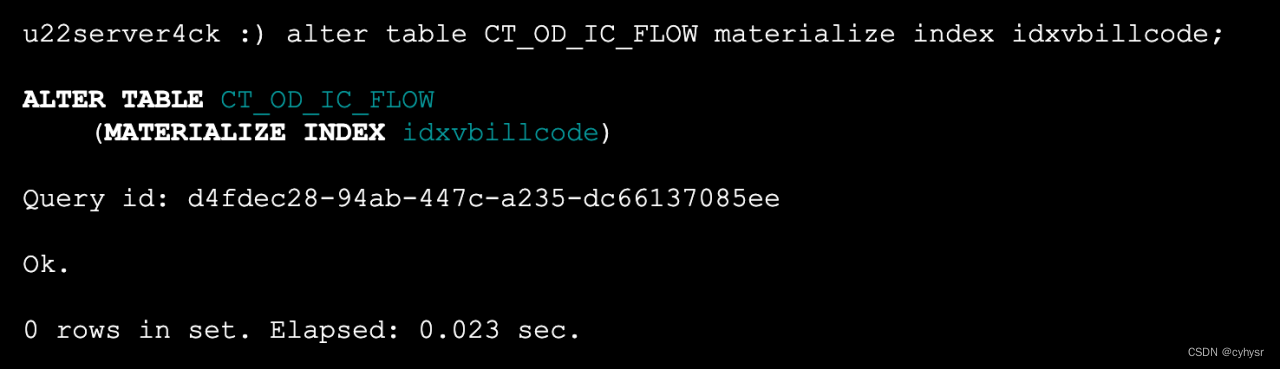
执行以上命令后,旧数据才会被索引,生成索引文件。
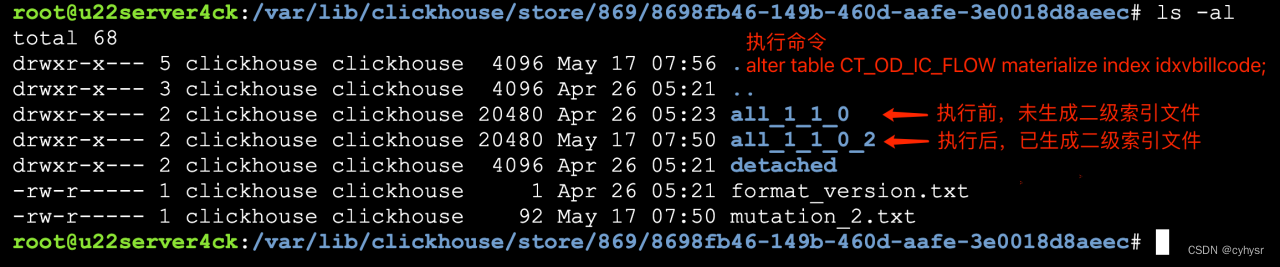
有延迟,一段时间后(1-2分钟),原有的all_1_1_0会消失。只有含新生成的二级索引相关文件的新文件夹all_1_1_0_2继续存在。
cd all_1_1_0_2
ls -al

















 1641
1641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









