







读了《大型网站技术架构》一书,基本是科普的水平,没有太多的深入分析。但是读过后还是觉得对于平常在公司做的一些事情,有了一些高屋建瓴的理解。把我的一些笔记留在这里。
网站的演化过程:
LAMP或类似架构
瓶颈: traffic增长,无法接受每次对DB的访问
使用缓存
具体操作:local cache (如程序实现的cache), remote cache server(一些专用的缓存服务器,读速度快,容量有限,例如memcached,voldemort)
瓶颈:高并发,服务器无法应对
多服务器 + 负载均衡调度服务器
具体操作: load-balancer将请求分发到多服务器中
瓶颈:DB无法接受同时大量读写
DB主从结构,读写分离
具体操作:典型的主从服务器架构:主服务器进行写操作并对从服务器备份,从服务器负责cache无法解决的读操作
瓶颈:网站访问延迟过大
CDN及反向代理
具体操作:静态图形文件以及Javascript文件可以放在CDN中,CDN根据客户位置部署,可大大减少load时间;反向代理指服务器只告诉资源在哪里,类似DNS
瓶颈: 更大的traffic,已有架构仍不能满足要求
多种解决方案:
1. 分布式:包含分布式操作系统(如GFS,TFS)和分布式数据库(如Golden Gate)。分布式数据库将数据冗余的分布在多个数据中心,需要考虑同步问题 2. NoSQL: nosql通常对分布式有一些特殊的支持 3. 业务拆分:搜索,checkout,fulfillment使用不同的子系统,etc 4. 多使用离线数据,如Hadoop,Spark等
业务拆分后的瓶颈:多种业务互相调用过于复杂
面向服务: Rest化所有的服务,服务间只能使用接口互相访问,不能直接访问对方数据库。
基于消息的数据服务: 使用消息队列进行异步调用。例如对一个服务发了请求后直接返回进行其他操作,使这个request变成non-blocking request。response生成后再处理。
相关术语:
- round robin: 轮询,即轮流
- CAP中的最终一致性: 较弱的数据一致性标准,不能保证数据的实时一致。只能保证数据在一段时间后能够一致。也就是说,系统有一定方法使分布式系统的各部分同步,但是需要一段过程
- 分配负载的consistent hash方法:使用0-2^32的环,将节点按hash值分布在环上。对一个请求,计算hash,按照顺时针找到第一个发现的节点。 好处:相比于直接hash取余使用consistent hash可以使增加节点数据迁移量最少。
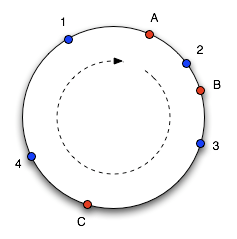
- consistent hash的虚拟节点方法:直接consistent hash还是不能保证所有节点的traffic平衡,是用虚拟节点可以解决这个问题。再hash换上较均匀分布若干虚拟节点,然后用一个表把几个虚拟节点映射到一个实体节点上。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









