



 本文详细介绍了车牌识别系统的实现过程,包括车牌定位、字符分割与识别等关键步骤,并分享了在实际开发过程中遇到的问题及解决方案。
本文详细介绍了车牌识别系统的实现过程,包括车牌定位、字符分割与识别等关键步骤,并分享了在实际开发过程中遇到的问题及解决方案。
| 主题 | 概要 |
|---|---|
| 车牌识别 | 车牌识别流程及算法 |
| 编辑 | 时间 |
| 新建 | 20161216 |
| 序号 | 参考资料 |
| 1 | https://github.com/openalpr/openalpr |
| 2 | https://github.com/liuruoze/EasyPR |
| 3 | 学习openCV,Cary Bradski,清华大学出版社 |
| 4 | http://www.cnblogs.com/subconscious/ |
| 5 | 基于子区域投影分析的车牌倾斜校正,马洪霞,计算机应用与软件 |
业余时间研究车牌识别近半年,接手之前没想到这么难,最后批量识别效果大概只有60%,只能做一个测试版。希望现场环境搭建起来后,采集更多样本,能够不断迭代优化。总之,就是不要放弃。欣慰的是几经努力,在PC机上,单张图片的识别速度保证了在1s以内,0.5s左右。下面把整个识别过程、算法思路回顾总结一遍。
在此之前,特别感谢easyPR和openalpr的作者,可以说我只是一个代码的搬运工,让我从完全没有OpenCV的知识背景,能够快速起步。
应用场景及目录结构
小区、停车场车牌自动识别。
C#写的窗体程序做为管理系统,接收摄像机传来的图片。车牌识别部分用c++完成,编译为一个dll,每当C#收到一张图片,就调用这个dll,传入图片并返回识别结果。
程序的目录结构:
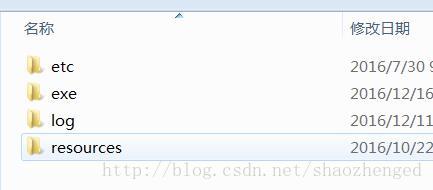
exe中是C#的exe程序和车牌识别dll及依赖的其他动态库;log目录保存识别过程日志;etc目录配置log选项及easyPR中带有的一些配置;resources目录保存调试模式时产生的中间图片,及ocr、cascade训练后的模型。另外,easypr中的ann和svm模型也放在此目录里面,但暂时已经没有使用。
下面通过一组调试过程的中间图片,详解各个识别过程。
车牌定位
车牌定位过程实际上综合了openalpr和easypr的过程,分为粗略定位和精确定位两部分。
粗略定位应用人脸识别技术(cascade)+形态学操作得到粗略的车牌,此时的车牌区域会比真正的车牌大些,包含了没法区分的背景。而且只是经过很粗放的旋转操作,存在水平倾斜及垂直错切的情况。需要更进一步的精确定位。
粗略定位
这是传递过来的原始图片,注意箭头所指的文字会对cascade定位产生干扰,所以进行了瘦身处理,去掉字符。
去掉字符,对上下边界简单的去掉10个像素:
应用cascade定位后,得到两个结果:

可以看到这两个车牌范围都太大,而且倾斜严重。对得到cascade的结果应用easyPR里面的sobel定位进行二次定位,在sobel定位无法得到结果时,再用颜色定位进行二次定位。应用sobel定位效果如下:




可以看到,成功把范围缩小,但水平倾斜严重。这里会先进行一次粗略的旋转,并同时进行一次车牌校验。思路是对车牌二值化后进行取轮廓操作,剔除掉不合理的轮廓后,如果合理的轮廓个数满足大于2个,则认可是一张车牌。另外,计算穿过轮廓中心的直线斜率,可以粗略确定需要旋转的角度。



如下图所示,找到了6个合理的字符,并且根据第一个字符矩形和最后一个字符矩形中心的位置来计算旋转角度。

经过粗略旋转后:

可以看到,水平方向虽然旋转了,但产生了透视,而且垂直方向是倾斜的。会影响后面的字符分割和OCR识别,因此还要进一步的精确处理。
精确定位
精确定位需要做两件事情,一是对车牌进行更可靠的水平旋转。因为上面计算旋转角度的方法不可靠,如果根据取轮廓没找到合适的字符矩形,就没法计算旋转角度,而且就算计算出来了,精度也不高。这里水平校正采用仿射变换的方式,因为我发现openalpr里面用于寻找字符上下边界的算法十分可靠,可以看下找到了字符的上下边界的mask,根据四个转角点,就能仿射到一个固定此寸的大小。

仿射变换后的车牌:
初步看来,与上面经过粗略水平旋转的车牌没什么两样。其实只是这张车牌粗略水平旋转时,效果很好的特例。总体来看,这一步还是有必要的。
在水平旋转变换后,车牌字符仍然是垂直倾斜的,为了进行垂直校正,想了很多方法来求垂直倾斜角度,但鲁棒性都不高。
最后参考了一篇论文:《基于子区域投影分析的车牌倾斜校正》,就是前面参考资料5提到的。实现了其中的垂直校正部分,校果很好。基本思路是,把车牌水平划分成几个子区域。然后求每个子区域的投影。投影只需求一次,然后用一个微小的增量来迭代寻优垂直倾斜角度,具体可参考本篇论文。

知道了垂直倾斜角度,下面就能求车牌的四个转角点,然后再进行一次仿射变换。为了解决上面出现的透视的情况,打算用霍夫变换求取上下水平边界,用垂直投影法来确定左右边界。
理想的经过霍夫变换后,上下边界应该是像这张车牌一样:

但霍夫变换,不能都成功的找到上下边界,像这张车牌求取上下边界的效果:
取到的下边界太短,而且不能严格贴着车牌边缘,也就很难解决透视问题了。
垂直边缘求取垂直方向的直方图来确定,延长水平边缘与垂直边缘,它们的交点就确定了车牌的四个转角,如下图:
求垂直边缘时候,根据垂直投影可以确定最左与最右的边界,再加上前面计算出来的垂直倾斜角度,就能推算出边缘。
仿射变换后,得到最终定位出来的车牌:

由于背景的干扰,垂直边界通常都不精确,后续分割字符的时候,需要对边缘部分进行过滤。实际上这部分是对openalpr改动最大的部分,openalpr没有进行水平校正,也没进行垂直校正,直接应用霍夫变换求水平边缘和垂直边缘来求四个转角点。但实践发现,效果比较差,因为很多时候都没法找出垂直边缘。


字符分割与识别
字符分割部分,根据openalpr的方法没有太多变动。但是因为中文字符的存在,还是做了很多调整。
主要有三点:
1.对于边缘的过滤
可以看到,云字左边的字符,应该被过滤掉。采取的思路是,如果第一个字符的宽度比第二个字符小70%或者比平均宽度大了1.3倍,都可认为是边缘。如果通过宽度不能过滤,就根据位置过滤,因为先验知识,第二个字符与第三个字符的距离会比较大。通过这样,一般都能过滤。而右边的字符,不需过滤,只要取前面7个字符就行了。
2.对于字符的合并
汉字具有左右结构,甚至左中右结构(如川),因此需要进行两次合并,如果相邻的字符宽度加起来小于平均字符宽度的1点几倍,则可接受为一个字符。但要注意,像上面最右边的3和像1的边缘可能合并成一个字符,因此合并的宽度要合理选取。
3.轮廓过滤时汉字要特殊处理
对于二值化后的车牌,可通过校验轮廓的方法去除燥点或污染点,进行清除操作。清除前:
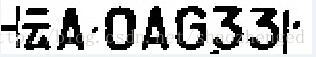
清除后:

可以看到云字的上面短横被去掉了,类似的,如果其它左右结构(如浙),小点也会被去掉。如果只是单纯降低清除的范围,虽然可以保留这些小点,但清除的效果就大打折扣了,因此需特殊处理。
解决方法是,把清除操作前和清除操作后的图片都保留起来。最后汉字从清除前的图片复制到另一张图片,数字和字母则从清除后的图片复制。这样就重新集成起来,并得到一张比较干净的车牌。
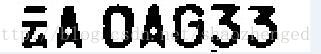
这张车牌就可进行OCR识别。分割后的效果:

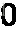


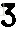
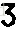
字符识别部分,是用的tesseract库,很多人说用OCR来识别车牌字符这种字体,效果会不好。我没试过其他方法,但想来openalpr采用了这种方法,只要分割出来的字符足够清晰,
训练得足够好,应该还是可以接受的。实际上B和8,D和0这种字符确实也很易识别错误,后面还需想办法提高。
Tesseract的训练方法可以参考我的上篇博客《Tesseract-OCR字符训练工具及方法》。

总结
目前来看,影响车牌识别的还有三个问题要解决:
一是用cascade进行车牌探测,速度很快,但是存在漏检的情况。不知是我训练时样本不够多的原因,还是其他。白天、夜间的也训练了2万多张,但还是可能漏检。
二是二值化效果,应用OSTU和Niblack进行二值化,但是存在字符和背景不能分离的情况。
三是OCR的识别准确率,需要再想办法提高。或者用其它的识别方法代替。
转载http://blog.csdn.net/shaozhenged/article/details/53726794

















 2692
2692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









