









Solving flow shop scheduling problem with genetic algorithm
前言
这里要来说明如何运用GA求解flow shop 问题,以下将先对flow shop 问题做个简介,说明一下编码原则,接着对每个程序块进行说明。
什么是 flow shop 问题?
简单来说,flow shop 问题就是有 n 个工件以及 m 台机器,每个工件在机器上的加工顺序都一样,如下图所示,工件1先进入机器1加工,再到机器2加工,而工件2跟随着工件1的脚步,按照同样的机器顺序加工,其他工件以此类推。
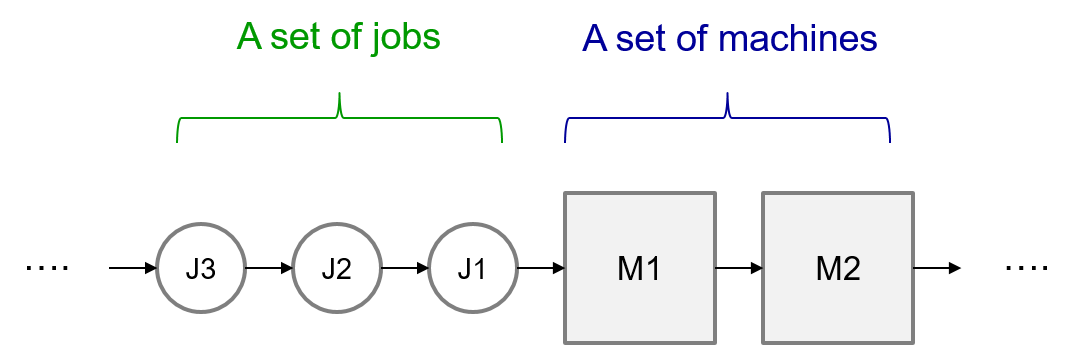
因此假设现在有3个工件2台机器,每个工件在每台机器上的加工时间,如左下图所示,工件的加工顺序为先到机器A加工再到机器B上加工,假设得到的排程结果为: Job 1->Job 2->Job 3,因此可得到如右下图的甘特图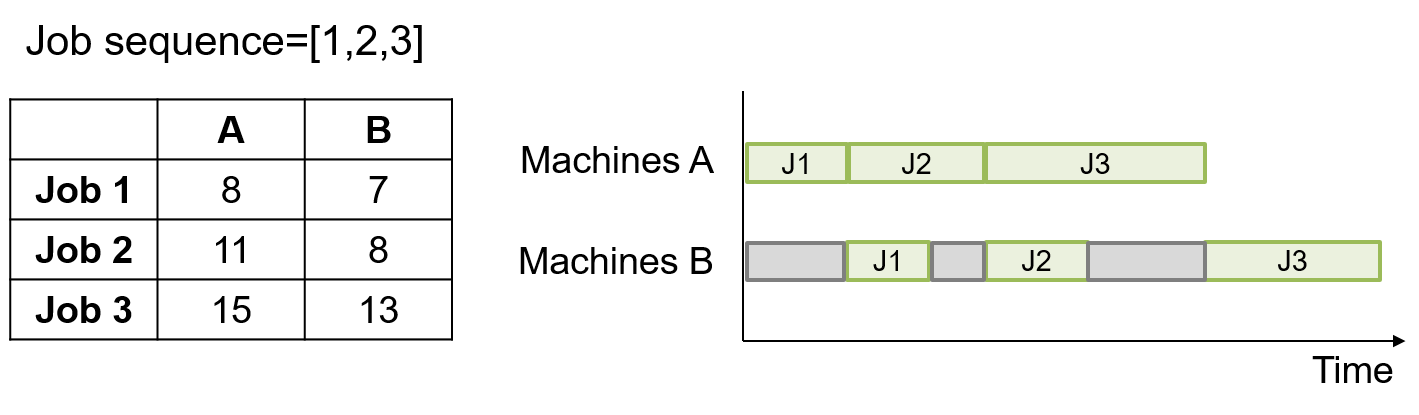
问题描述
本范例是一个具有20个工件的flow shop 问题,排程目标最小化的加权延迟 (Total weighted tardiness) ,工件信息如下图所示

排程目标
由本文范例的目标为最小化的加权延迟 (Total weighted tardiness),因此除了必须知道每个工件在每台机器上的加工时间外,还必须知道每个工件的到期日及权重。
工件 i 的完工时间 (Completion time)、:工件 i 的到期日 (Due date)、:工件 i 的延迟时间(Tardiness time)、工件 i 的权重(Weight)
首先计算每个工件的延迟时间,如果提早做完,则延迟时间为0
计算所有工件的加权延迟时间总和,从公式我们可以知道,当工件的权重越大,我们要尽可能的准时完成那些权重较大的工件,不然会导致总加权延迟时间太大,对于这样的排程问题来说,这就不是一个好的排程
另外,这里提供了另一个版本的 flow shop 程序,跟本文主要的差別在于求解目标的不同,另一版本的目标为最小化总闲置时间 (Idle time),也就是上面范例甘特图中,灰色区域的部分,期望排出来的排程,可以尽可能减少总机器的闲置时间。
编码原则
这里的编码方式很简单,每個染色体就表示一组排程结果,因此,如果 flow shop 的问题中,共有五个工件要排,则每个染色体就由五个基因所組成,每个基因即代表某个工件,会通过list 來储存每个染色体,
如下面所示:
chromosome 1 => [0,1,2,3,4]
chromosome 2 => [1,2,0,3,4]
chromosome 3 => [4,2,0,1,3]
........
程序说明
这里主要针对程序中重要的步骤来说明,有些细节未放入,如有需要请参考完整程序码或范例代码
导入包
# importing required modules
import numpy as np
import time
import copy初始设定
此处主要包含数据或是资料给定,以及一些参数上的设定
''' ================= initialization setting ======================'''
num_job=20 # 工件数量
p=[10,10,13,4,9,4,8,15,7,1,9,3,15,9,11,6,5,14,18,3]#每个工件的完工时间
d=[50,38,49,12,20,105,73,45,6,64,15,6,92,43,78,21,15,50,150,99]#每个工件的到期时间
w=[10,5,1,5,10,1,5,10,5,1,5,10,10,5,1,10,5,5,1,5]#每个工作的到期日
# raw_input is used in python 2
population_size=int(input('Please input the size of population: ') or 30)#种群规模,默认为30
crossover_rate=float(input('Please input the size of Crossover Rate: ') or 0.8) #交叉概率,默认为0.8
mutation_rate=float(input('Please input the size of Mutation Rate: ') or 0.1)
#变异概率,默认为0.1
mutation_selection_rate=float(input('Please input the mutation selection rate: ') or 0.5)#变异选择概率,默认为0.5
num_mutation_jobs=round(num_job*mutation_selection_rate)#变异数量
num_iteration=int(input('Please input number of iteration: ') or 2000)
# 最大迭代次数,默认为2000
start_time = time.time() 种群初始化
根据上述所设定的族群大小,通过随机的方式,产生初始族群
'''----- generate initial population -----'''
Tbest = 999999999999999 # 最小的总加权延迟时间
best_list, best_obj = [], []
population_list = []
makespan_record = []
for i in range(population_size):
nxm_random_num = list(np.random.permutation(num_job)) # 对0到num_job-1之间的序列进行随机排序
population_list.append(nxm_random_num) # 添加到population_list中
# population_list: 30次0到num_job-1的随机排序
for n in range(num_iteration):
Tbest_now = 99999999999 # 到目前为止最小的总加权延迟时间 交插
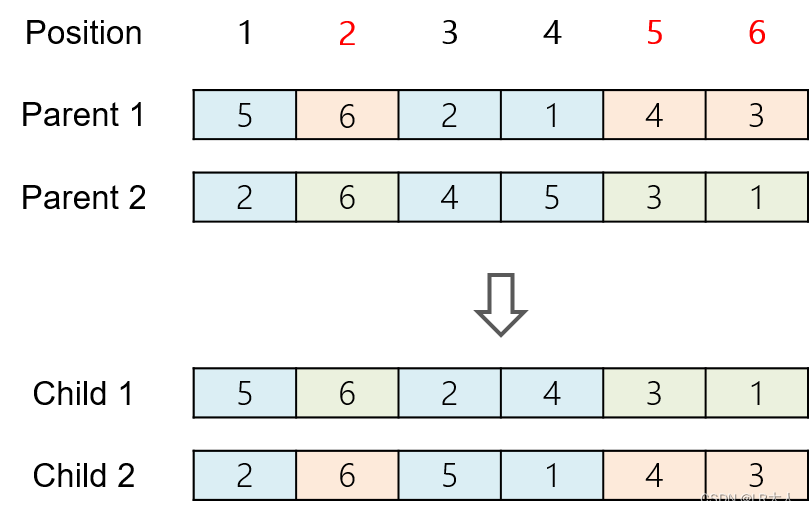
这里的交插方式是通过指定位置的方式进行行交插,执行的步骤如下:
-
通过随机选择的方式,将基因数一半的位置设为固定不变,以下图例,共有六个工件进行排序,生成两个子代,在此选定2、5、6为工件顺序不变的位置。
-
将 Parent 1 工件不变的位置,复制到对应的 Child 2 ,接着将Child 2 与Parent 2 进行比较。
-
将 parent 2 与child2不重复的工件,依序填入 Child 2 剩余的位置,形成新的子代2。
-
Child 1 的形成方式如 Child 2 所示。
'''-------- crossover --------'''
parent_list = population_list[:] # 亲本列表
offspring_list = population_list[:] # 子代列表
S = list(np.random.permutation(population_size)) # 生成一个随机序列,选择亲本染色体进行交叉操作
# 对0到population_size之间的序列进行随机排序
for m in range(int(population_size / 2)):
crossover_prob = np.random.rand()
if crossover_rate >= crossover_prob:
parent_1 = population_list[S[2 * m]][:] # 亲本1为population_list的第S[2*m]个
parent_2 = population_list[S[2 * m + 1]][:] # 亲本2为population_list的第S[2*m+1]个
child_1 = ['na' for i in range(num_job)] # 初始化子代1
child_2 = ['na' for i in range(num_job)] # 初始化子代2
fix_num = round(num_job/2) # 工件个数的一半
g_fix = list(np.random.choice(num_job, fix_num, replace=False)) # 从20个基因中随机选10个
for g in range(fix_num):
child_1[g_fix[g]] = parent_2[g_fix[g]] # 亲本2中g_fix位的基因赋给子代1
child_2[g_fix[g]] = parent_1[g_fix[g]] # 亲本1中g_fix位的基因赋给子代2
c1 = [parent_1[i] for i in range(num_job) if parent_1[i] not in child_1] # 子代1中的空位需要的基因
c2 = [parent_2[i] for i in range(num_job) if parent_2[i] not in child_2] # 子代2中的空位需要的基因
for i in range(num_job - fix_num):
child_1[child_1.index('na')] = c1[i] # 填补子代2中的空位需要的基因
child_2[child_2.index('na')] = c2[i] # 填补子代2中的空位需要的基因
offspring_list[S[2 * m]] = child_1[:]
offspring_list[S[2 * m + 1]] = child_2[:]
变异
此方法是通过基因位移的方式进行突变,突变方式如下:
-
依据 mutation selection rate 決定染色体中有多少百分比的基因要进行突变,假设每条染色体有六个基因, mutation selection rate 为0.5,则有3个基因要进行突变。
-
随机选定要位移的基因位,假设选定5、2、6 (在此表示该位置下的基因要进行突变)
-
进行基因移位,移位方式如图所示。

'''--------mutatuon--------'''
for m in range(len(offspring_list)):
mutation_prob = np.random.rand()
if mutation_rate >= mutation_prob:
m_chg = list(np.random.choice(num_job, num_mutation_jobs, replace=False)) # 从20个基因中随机选10个变异位置
t_value_last = offspring_list[m][m_chg[0]] # 保存子代第一个变异位置上的值
for i in range(num_mutation_jobs - 1):
offspring_list[m][m_chg[i]] = offspring_list[m][m_chg[i + 1]] # 移位
offspring_list[m][m_chg[num_mutation_jobs - 1]] = t_value_last # 将第一个变异位置的值移至最后一个变异位置
适应度计算
计算每个染色体也就是每个排程结果的总加权延迟,并将其记录,以利于进行选择时能进行比较.
'''--------fitness value(calculate tardiness)-------------'''
total_chromosome = parent_list[:] + offspring_list[:] # 结合亲本和子代的染色体,形成总种群total_chromosome
chrom_fitness, chrom_fit = [], []
total_fitness = 0
for i in range(population_size * 2): # 对于每个亲本和子代染色体
ptime = 0
tardiness = 0
for j in range(num_job): # 对于每个工件
ptime = ptime + p[total_chromosome[i][j]] # 完工时间
tardiness = tardiness + w[total_chromosome[i][j]] * max(ptime - d[total_chromosome[i][j]], 0) # 总加权拖期时间
chrom_fitness.append(1 / tardiness)
chrom_fit.append(tardiness)
total_fitness = total_fitness + chrom_fitness[i]选择
这里选择轮盘赌 (Roulette wheel) 的选择机制
'''----------selection----------'''
pk, qk = [], []
for i in range(population_size * 2): # 对于每个亲本和子代染色体
pk.append(chrom_fitness[i] / total_fitness)
for i in range(population_size * 2):
cumulative = 0
for j in range(0, i + 1):
cumulative = cumulative + pk[j]
qk.append(cumulative)
selection_rand = [np.random.rand() for i in range(population_size)]
for i in range(population_size):
if selection_rand[i] <= qk[0]:
population_list[i][:] = total_chromosome[0][:]
break
else:
for j in range(0, population_size * 2 - 1):
if selection_rand[i] > qk[j] and selection_rand[i] <= qk[j + 1]:
population_list[i][:] = total_chromosome[j + 1][:]比较
先比较每个染色体的总加权延迟 (chrom_fit) ,找到的最好解 (Tbest_now) ,接着在跟目前为止找到的最好解 (Tbest) 进行比较,一旦有一个的解比目前为止找到的解还要好,就替代 Tbest 并记录此解所得到的排程结果。
'''----------comparison----------'''
for i in range(population_size * 2):
if chrom_fit[i] < Tbest_now:
Tbest_now = chrom_fit[i]
sequence_now = total_chromosome[i][:]
if Tbest_now <= Tbest:
Tbest = Tbest_now
sequence_best = sequence_now[:]
makespan_record.append(Tbest)
job_sequence_ptime = 0
num_tardy = 0
for k in range(num_job): # 对于每个工件
job_sequence_ptime = job_sequence_ptime + p[sequence_best[k]]
if job_sequence_ptime > d[sequence_best[k]]:
num_tardy = num_tardy + 1结果
等所有迭代次数结束后,在输出的所有迭代中找到的最好排程结果 (sequence_best)、它的总加权延迟时间、每个工件平均加权延迟时间、有多少工件延迟以及程序的执行时间
'''----------result----------'''
print("optimeal sequence", sequence_best)
print("optimeal value:%f" % Tbest)
print("average tardiness:%f" % (Tbest / num_job))
print("number of tardy:%d" % num_tardy)
print('the elapsed time:%s' % (time.time() - start_time))
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot([i for i in range(len(makespan_record))],makespan_record,'b')
plt.ylabel('makespan',fontsize=15)
plt.xlabel('generation',fontsize=15)
plt.show()Please input the size of population: 30
Please input the size of Crossover Rate: 0.8
Please input the size of Mutation Rate: 0.1
Please input the mutation selection rate: 0.5
Please input number of iteration: 2000
optimeal sequence [11, 4, 15, 16, 3, 0, 7, 19, 9, 10, 6, 12, 13, 1, 8, 17, 2, 18, 5, 14]
optimeal value:2235.000000
average tardiness:111.750000
number of tardy:12
the elapsed time:35.346625566482544
甘特图
'''--------plot gantt chart-------'''
import pandas as pd
import plotly.plotly as py
import plotly.figure_factory as ff
import plotly.offline as offline
import datetime
j_keys=[j for j in range(num_job)]
j_count={key:0 for key in j_keys}
m_count=0
j_record={}
for i in sequence_best:
gen_t=int(p[i])
j_count[i]=j_count[i]+gen_t
m_count=m_count+gen_t
if m_count<j_count[i]:
m_count=j_count[i]
elif m_count>j_count[i]:
j_count[i]=m_count
start_time=str(datetime.timedelta(seconds=j_count[i]-p[i])) # convert seconds to hours, minutes and seconds
end_time=str(datetime.timedelta(seconds=j_count[i]))
j_record[i]=[start_time,end_time]
df=[]
for j in j_keys:
df.append(dict(Task='Machine', Start='2018-07-14 %s'%(str(j_record[j][0])), Finish='2018-07-14 %s'%(str(j_record[j][1])),Resource='Job %s'%(j+1)))
# colors={}
# for i in j_keys:
# colors['Job %s'%(i+1)]='rgb(%s,%s,%s)'%(255/(i+1)+0*i,5+12*i,50+10*i)
fig = ff.create_gantt(df, colors=['#008B00','#FF8C00','#E3CF57','#0000CD','#7AC5CD','#ED9121','#76EE00','#6495ED','#008B8B','#A9A9A9','#A2CD5A','#9A32CD','#8FBC8F','#EEC900','#EEE685','#CDC1C5','#9AC0CD','#EEA2AD','#00FA9A','#CDB38B'], index_col='Resource', show_colorbar=True, group_tasks=True, showgrid_x=True)
py.iplot(fig, filename='GA_flow_shop_scheduling_tardyjob', world_readable=True)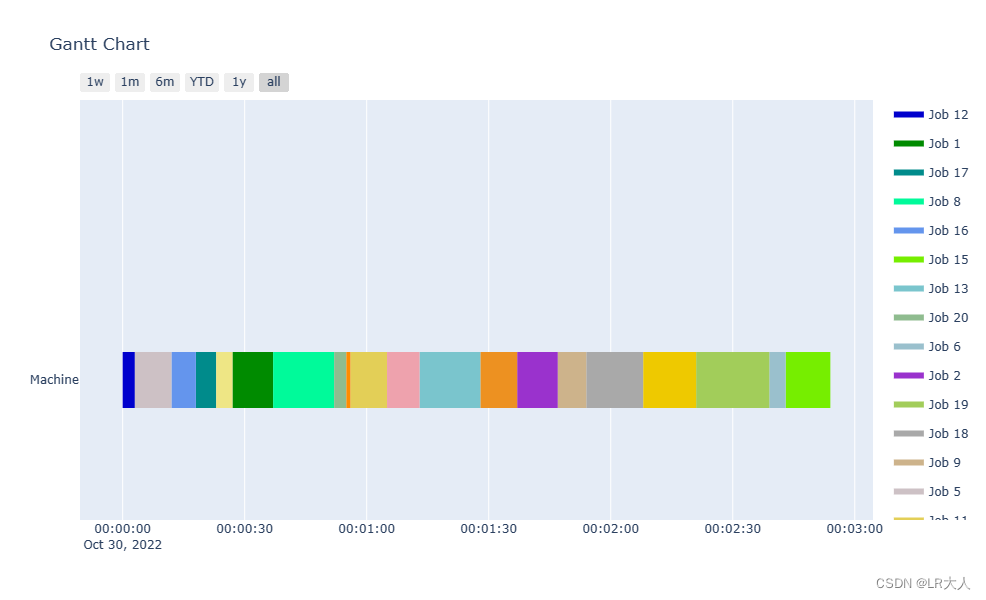
Reference
-
António Ferrolho and Manuel Crisóstomo. “Single Machine Total Weighted Tardiness Problem with Genetic Algorithms”
-
N. Liu, Mohamed A. Abdelrahman, and Snni Ramaswamy. “A Genetic Algorithm for the Single Machine Total Weighted Tardiness Problem”















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









