







深度学习
前言
之前看吴恩达老师的深度学习视频知道了不少专业名词,但是并不明白是什么,怎么用。
这次又看了李沐老师的动手学深度学习课程,理论+代码的方式让我受益匪浅。
课程地址:https://www.bilibili.com/video/BV1if4y147hS/?spm_id_from=333.337.search-card.all.click
下面所写仅为记录自己学习的过程遇到的觉得比较重要的知识点,如有错误请指正。
环境安装(Windows)
安装anaconda
使用conda或miniconda创建环境
# 如果之前创建过则先移除之前的环境
conda env remove d2l-zh
# 创建虚拟环境并下载解释器
conda create -n d2l-zh python=3.8
# 激活刚刚创建的环境
conda activate d2l-zh
下载所需的包
pip install -y jupyter d2l torch torchvision
下载代码并执行(课件代码)
注意:这里的wget、unzip命令都是linux中的命令,可以直接去下面的网站里下,也可以用Wget for Windows 下载
# 下载
wget https://zh-v2.d2l.ai/d2l-zh.zip
# 解压
unzip d2l-zh.zip
# 使用jupyter
jupyter notebook
关于线性代数
内积(数量积、点乘)
外积
关于数据操作
X.sum(0, keepdim=True) 和 X.sum(1, keepdim=True)
- X.sum(0) 为按第0维求和,即
按列求和 - X.sum(1) 为按第1维求和,即
按行求和 - keepdim参数为是否保持X原本的维度
例如:
X = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]])
即
X
=
[
1.0
2.0
3.0
4.0
5.0
6.0
]
X = \begin{bmatrix} 1.0&2.0&3.0\\ 4.0&5.0&6.0\\ \end{bmatrix}
X=[1.04.02.05.03.06.0]
按行分出两个向量并按列求和
X
r
o
w
=
1
=
[
1.0
2.0
3.0
]
X
r
o
w
=
2
=
[
4.0
5.0
6.0
]
X
.
s
u
m
(
0
,
k
e
e
p
d
i
m
=
T
r
u
e
)
=
X
r
o
w
=
1
+
X
r
o
w
=
2
=
[
5.0
7.0
9.0
]
X_{row=1} = \begin{bmatrix} 1.0&2.0&3.0\\ \end{bmatrix} \\ X_{row=2} = \begin{bmatrix} 4.0&5.0&6.0\\ \end{bmatrix} \\ X.sum(0, keepdim=True) = X_{row=1}+X_{row=2}= \begin{bmatrix} 5.0&7.0&9.0\\ \end{bmatrix}
Xrow=1=[1.02.03.0]Xrow=2=[4.05.06.0]X.sum(0,keepdim=True)=Xrow=1+Xrow=2=[5.07.09.0]
由于参数keepdim=True则X.sum的结果的维度与X本身的维度相同即 [ [ 5.0 7.0 9.0 ] ]
例如:
X = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]])
即
X
=
[
1.0
2.0
3.0
4.0
5.0
6.0
]
X = \begin{bmatrix} 1.0&2.0&3.0\\ 4.0&5.0&6.0\\ \end{bmatrix}
X=[1.04.02.05.03.06.0]
按行分出三个向量并按行求和
X
c
o
l
=
1
=
[
1.0
4.0
]
T
X
c
o
l
=
3
=
[
3.0
6.0
]
T
X
c
o
l
=
2
=
[
2.0
5.0
]
T
X
.
s
u
m
(
1
,
k
e
e
p
d
i
m
=
T
r
u
e
)
=
X
c
o
l
=
1
+
X
c
o
l
=
2
+
X
c
o
l
=
3
=
[
6.0
15.0
]
X_{col=1} = \begin{bmatrix} 1.0&4.0\\ \end{bmatrix}^T \\ X_{col=3} = \begin{bmatrix} 3.0&6.0\\ \end{bmatrix} ^T \\ \\ X_{col=2} = \begin{bmatrix} 2.0&5.0\\ \end{bmatrix} ^T \\ X.sum(1, keepdim=True) = X_{col=1}+X_{col=2}+X_{col=3}= \begin{bmatrix} 6.0&15.0\\ \end{bmatrix}
Xcol=1=[1.04.0]TXcol=3=[3.06.0]TXcol=2=[2.05.0]TX.sum(1,keepdim=True)=Xcol=1+Xcol=2+Xcol=3=[6.015.0]
由于参数keepdim=True则X.sum的结果的维度与X本身的维度相同即 [ [ 6.0 15.0 ] ]
广播机制(broadcast)
- 什么是广播机制?
如过两个数组做运算,数组的形状不同,则会自动转换成相同的数组的形状进行运算,小一点的数组适应大的数组
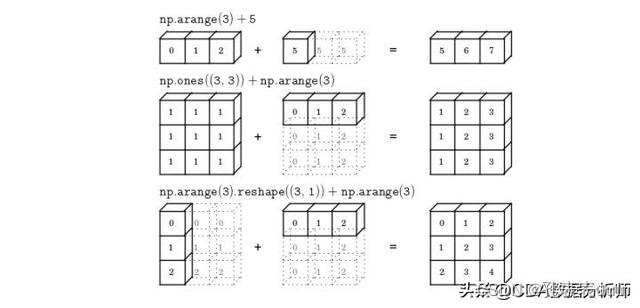
图片出处
- 广播机制条件
1.
2. - 广播机制运算
例如:
[
0
0
0
1
1
1
2
2
2
]
+
[
1
2
3
]
⟺
[
0
0
0
1
1
1
2
2
2
]
+
[
1
2
3
1
2
3
1
2
3
]
=
[
1
2
3
2
3
4
3
4
5
]
\begin{bmatrix} 0&0&0\\ 1&1&1\\ 2&2&2\\ \end{bmatrix} + \begin{bmatrix} 1&2&3\\ \end{bmatrix} \iff \begin{bmatrix} 0&0&0\\ 1&1&1\\ 2&2&2\\ \end{bmatrix} + \begin{bmatrix} 1&2&3\\ 1&2&3\\ 1&2&3\\ \end{bmatrix} = \begin{bmatrix} 1&2&3\\ 2&3&4\\ 3&4&5\\ \end{bmatrix}
012012012
+[123]⟺
012012012
+
111222333
=
123234345
先把维度较小的tensor的维度扩充到和较大维度的tensor的维度一致,即先把[1 2 3]向量扩充成[[1 2 3], [1 2 3], [1 2 3]]然后再进行运算
Softmax函数和交叉熵损失函数
Softmax函数
公式:
s
o
f
t
m
a
x
(
X
i
j
)
=
exp
(
X
i
j
)
∑
k
exp
(
X
i
k
)
softmax(X_{ij}) = \frac{\exp(X_{ij})}{\sum_{k}\exp(X_{ik})}
softmax(Xij)=∑kexp(Xik)exp(Xij)
交叉熵损失函数
多分类公式:
L
=
−
∑
i
=
1
n
y
i
log
[
s
o
f
t
m
a
x
(
X
)
]
=
−
log
y
y
^
L = -\sum_{i=1}^{n}{y_i\log[softmax(X)]} = -\log \hat{y_y}
L=−i=1∑nyilog[softmax(X)]=−logyy^
其中,n为输出维度(分类个数),y为真是label的概率(one-hot),L反应的是真实值和预测值的差距
感知机
公式:
ο
=
σ
(
<
W
,
X
>
+
b
)
σ
(
x
)
=
{
1
,
i
f
x
>
0
0
,
o
t
h
e
r
w
i
s
e
\omicron = \sigma(<\textbf{W}, \textbf{X}> + b) \qquad \sigma(x) =\begin{cases} 1, & if \ x > 0 \\ 0, & otherwise \end{cases}
ο=σ(<W,X>+b)σ(x)={1,0,if x>0otherwise
















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











