






问题描述
此次作业的主要目的是使用残差网络实现深层卷积神经网络完成分类问题。
多分类问题还是之前的识别手势代表的数字。

参考:残差网络ResNet
import h5py
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
1 - ResNets介绍
1.1 - 深度神经网络的问题
我们知道深度神经网络可以表达出更加复杂的非线性函数,这就可以实现从输入中提取更多不同的特征。但是随着网络层数的加多,梯度消失(vanishing gradient)的效应将被放大,这将导致算法在反向传播时从最后一层传播到第一层的过程中,算法乘了每一层的权重矩阵,因此梯度会很快地下降到接近0(或者很快地增加到一个很大的值)。
具体来说,在训练是你会看到前面层的梯度会非常迅速地降为零:

1.2 - 残差网络
残差网络可以很好解决深度神经网络的上诉问题,主要就是使用跳跃连接(skip connection)让梯度可以直接反向传递给前面的层(earlier layers):

残差块主要有两种,根据输入输出的维度是否相同划分为对等块(identity block)和卷积块(convolutional block)。
1.2.1 - 对等块
ResNets中的对等块表示输入激活值的维度 a [ l ] a^{[l]} a[l]和输出激活值的维度 a [ l + 1 ] a^{[l+1]} a[l+1]相同的情况。

图中上部的路径表示跳跃连接,下部的路径表示主路径。为了加速训练过程,并在每一层添加了BatchNorm的步骤。
在本次试验中你将实现一个更加有效的ResNets的对等块,即进行跨越3个隐藏层的跳跃连接而非2个:

1.2.2 - 卷积块
ResNets中的卷积块表示输入激活值的维度
a
[
l
]
a^{[l]}
a[l]和输出激活值的维度
a
[
l
+
1
]
a^{[l+1]}
a[l+1]不相同的情况。对于不相同的情况我们对跳跃连接的部分再次应用一个卷积层(CONV2D)以此达到输入输出维度相同的目的。

这个应用到跳跃连接的卷积层和视频中所说的矩阵 W s W_s Ws拥有相同的作用,不过注意这个卷积层不会应用任何的非线性函数,因为这个路径的作用仅仅是更改输入层 a [ l ] a^{[l]} a[l]的维度以便和输出层 a [ l + 3 ] a^{[l+3]} a[l+3]的维度相匹配。
1.2.3 - 模型架构
模型架构如下图所示,本次试验采用参考作者所实现的34层的ResNet而非作业中的50层,不过只要34层实现了,50层也是同样的道理:

具体的残差块的设计如下所示:

残差块用的卷积核为kernel_size=3.模型的conv3_1,conv4_1,conv5_1之前做了宽高减半的downsample.conv2_x是通过maxpool(stride=2)完成的下采样.其余的是通过conv2d(stride=2)完成的.
你可以利用公式: ⌊ n + 2 p − f s + 1 ⌋ \left\lfloor\frac{n+2p-f}{s}+1\right\rfloor ⌊sn+2p−f+1⌋证明当 p = 1 , f = 3 p=1,f=3 p=1,f=3固定时, s = 1 s=1 s=1为SAME卷积, s = 2 s=2 s=2为高和宽减半的卷积。
1.2.4 - 构建残差块
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, stride=1) -> None:
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, stride=stride, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
# 在conv3_x,conv4_x,conv5_x的第一层会使用残差层进行图像高和宽的缩减以及维度的增加,
# 此时就要用到1.2.2的卷积块,利用1x1的卷积块对x的维度进行更新。
# or if stride != 1:
if in_channels != out_channels:
self.conv1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv1x1 = None
def forward(self, x):
o1 = self.relu(self.bn1(self.conv1(x)))
o2 = self.bn2(self.conv2(o1))
if self.conv1x1:
x = self.conv1x1(x)
return self.relu(o2 + x)
注意:
原作者进行了如下操作,我没有在吴老师的课堂上听到相关的操作,且老师作业的源码貌似也没有这个,所以我删除了参考作者的这个操作。
- ReLU(inplace=True):指原地进行操作,操作完成后覆盖原来的变量
- 优点:节省内存
- 缺点:进行梯度回归的时候传回失败,原来的变量被覆盖,找不到原来的变量
2 - 数据预处理
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', 'r')
test_dataset = h5py.File('datasets/test_signs.h5', 'r')
# 直接从把h5数组转化为tensor太慢,先转成numpy再转到tensor更快
train_set_x = torch.from_numpy(np.array(train_dataset['train_set_x']))
train_set_y = torch.from_numpy(np.array(train_dataset['train_set_y']))
test_set_x = torch.from_numpy(np.array(test_dataset['test_set_x']))
test_set_y = torch.from_numpy(np.array(test_dataset['test_set_y']))
classes = torch.tensor(test_dataset['list_classes'])
train_set_x = train_set_x.permute(0, 3, 1, 2) / 255
test_set_x = test_set_x.permute(0, 3, 1, 2) / 255
return train_set_x, train_set_y, test_set_x, test_set_y, classes
def data_loader(x, y, batch_size = 32):
db = TensorDataset(x, y)
return DataLoader(db, batch_size, shuffle=True)
train_x, train_y, test_x, test_y, classes = load_dataset()
print(f'The number of train set: {train_x.shape[0]}')
print(f'The number of test set: {test_x.shape[0]}')
print(f'The shape of train set(x): {train_x.shape}')
print(f'The shape of train set(y): {train_y.shape}')
print(f'The number of class: {classes.shape[0]}')

3 - 构建ResNets模型
利用上面的残差块和34层的网络模型,你可以按如下方式实现该ResNet。
具体的:
- conv1: input-3x64x64, output-64x32x32
- conv2: input-64x32x32, output-64x16x16
- conv3: input-64x16x16, output-128x8x8
- conv4: input-128x8x8, output-256x4x4
- conv5: input-256x4x4, output-512x2x2
- avg_pool: input-512x2x2, output-512x1x1
class ResNet(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
'''
构建一个34层的ResNet网络模型。
'''
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=64, stride=2, kernel_size=7, padding=3),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
Residual(64, 64),
Residual(64, 64),
Residual(64, 64)
)
self.conv3 = nn.Sequential(
Residual(64, 128, stride=2),
Residual(128, 128),
Residual(128, 128),
Residual(128, 128)
)
self.conv4 = nn.Sequential(
Residual(128, 256, stride=2),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256)
)
self.conv5 = nn.Sequential(
Residual(256, 512, stride=2),
Residual(512, 512),
Residual(512, 512)
)
# self.avg_pool = nn.AvgPool2d(kernel_size=2)
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1) # 自适应平均池化,指定输出(H,W)
self.fc = nn.Linear(512, num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avg_pool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
def predict(self, x):
out = self.forward(x)
out = self.softmax(out)
return torch.max(out, dim=1)[1]
4 - 训练模型
def model(train_x, train_y, num_classes, device, batch_size = 32, epochs = 50, lr = 0.001, pc = True):
# 获取输入通道数
in_channels = train_x.shape[1]
# 释放GPU显存空间
torch.cuda.empty_cache()
# 初始化ResNet
net = ResNet(in_channels, num_classes).to(device)
train_x = train_x.to(device)
train_y = train_y.to(device)
# 加载数据
train_loader = data_loader(train_x, train_y, batch_size)
# 选择交叉熵损失函数
loss_fc = nn.CrossEntropyLoss()
# 选择Adam优化器
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 迭代学习
for e in range(epochs):
epoch_loss = 0
for step, (batch_x, batch_y) in enumerate(train_loader):
# 前向传播
output = net.forward(batch_x)
# 计算损失
loss = loss_fc(output, batch_y)
epoch_loss += loss.cpu().detach().numpy()
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度下降
optimizer.step()
epoch_loss /= step + 1
if e % 5 == 0:
writer.add_scalar(tag=f'Layers={34}, lr={lr}, epochs={epochs}', scalar_value=epoch_loss, global_step=e)
if pc:
print(f'epoch: {e}, loss: {epoch_loss}')
# 保存学习参数
torch.save(net.state_dict(), 'ResNet34_params.pkl')
print('参数已保存到本地pkl文件')
return net.cpu()
(我最开始用我的垃圾cpu训练,5个epoch跑了2分钟都没结束,虽然我的gpu也很渣,但时间能接受,所以尽量配好环境用gpu训练。)
net = model(train_x, train_y, classes.shape[0], device)

loss图如下:
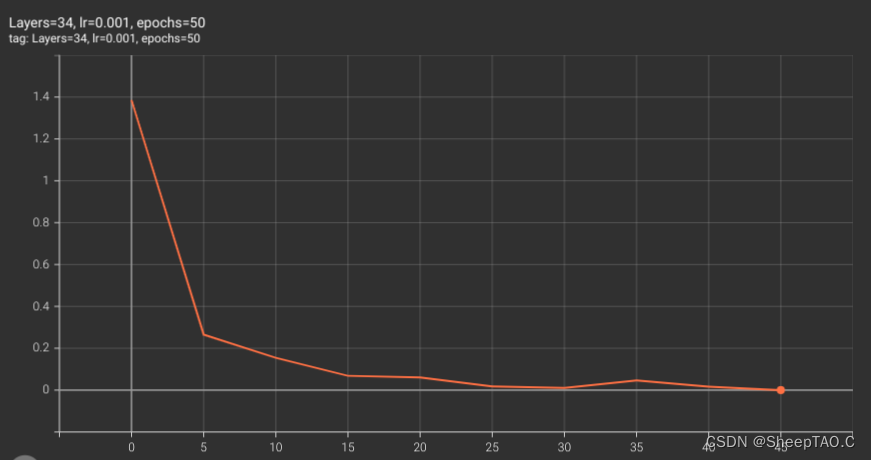
# 评估模型准确度
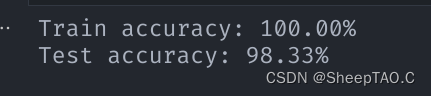
train_pred = net.predict(train_x)
print(f'Train accuracy: {torch.sum(train_pred == train_y) / train_y.shape[0] * 100:.2f}%')
test_pred = net.predict(test_x)
print(f'Test accuracy: {torch.sum(test_pred == test_y) / test_y.shape[0] * 100:.2f}%')















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









