






参照官网:ceph搭建过程
参照:https://blog.csdn.net/get_set/article/details/108092248
软件版本:
| 软件 | 版本 |
|---|---|
| ceph | octopus(15.2.16) |
| centos | 7.9 |
ceph官网版本:
https://docs.ceph.com/en/latest/releases/#ceph-releases-index
机器列表:
| 机器名称 | ip | 块设备 |
|---|---|---|
| master0 | 172.70.10.161 | /dev/vdb 和 /dev/vdc |
| master1 | 172.70.10.162 | /dev/vdb 和 /dev/vdc |
| master2 | 172.70.10.163 | /dev/vdb 和 /dev/vdc |
准备工作
开始使用ansible做些准备工作,实际开始搭建后,不用ansible,因为cephadm本身就是一个集群管理工具。
如下ansible剧本均在集群外的任意一台机器上面执行,需要安装下ansible,不明白的可以参照ansible使用方法。
ansible的hosts配置如下(因为之前这些机器用来搭建k8s,所以名称没有改变):
master0 ansible_host=172.70.10.161 ansible_port=22 ansible_user=root ansible_password=*** host_name=master0
master1 ansible_host=172.70.10.162 ansible_port=22 ansible_user=root ansible_password=*** host_name=master1
master2 ansible_host=172.70.10.163 ansible_port=22 ansible_user=root ansible_password=*** host_name=master2
[all]
master0
master1
master2
升级系统内核
升级系统内核到5.17
ansible脚本如下(1.kenel.yaml):
- name: update kernel
hosts: all
gather_facts: True
vars:
tasks:
- name: create workspace
file:
path: /tmp/workspace/
state: directory
tags: workspace
- name: yum install elrepo
copy:
src: templates/rpm.sh.j2
dest: /tmp/workspace/rpm.sh
mode: 755
tags:
- copy-rmp
- name: sh rpm.sh
shell: sh /tmp/workspace/rpm.sh
tags:
- sh-rmp
- name: 列出可用的内核相关包
yum:
list: available
disablerepo: "*"
enablerepo: "elrepo-kernel"
- name: 安装内核
yum:
name:
- kernel-ml
#- kernel-lt.x86_64
#- kernel-lt-devel.x86_64
enablerepo: elrepo-kernel
- name: 查看内核版本默认启动顺序
shell: awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
- name: 修改grub中默认版本启动顺序
lineinfile:
path: /etc/default/grub
regexp: "^GRUB_DEFAULT"
line: "GRUB_0=saved"
backrefs: yes
state: present
tags:
- grub
- name: 重新创建内核配置
shell: grub2-mkconfig -o /boot/grub2/grub.cfg
- name: Reboot the machine
reboot:
reboot_timeout: 300
- name: uname -r
shell: uname -r
register: version
- name: debug
debug:
msg: "{{ version }}"
升级rpm脚本在ansible剧本同目录下的templates/rpm.sh.j2
内容是:
#!/bin/bash
rpm -import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
rpm -Uvh https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
echo 0
执行ansible-playbook -v 1.kenel.yaml完成集群中系统内核升级
安装必要工具和关闭相关配置
脚本2.config.yaml如下:
- name: set config
hosts: all
gather_facts: True
vars:
handlers:
- name: update_yum
shell: |
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
yum clean all
yum makecache -y
- name: noswap_service #禁用swap
systemd:
name: noswap
state: started #指定服务状态,其值可以为stopped停止、started启动、reloaded、restarted、running
enabled: yes #指定服务是否为开机启动,yes为启动,no为不启动
daemon_reload: yes #yes 重启systemd服务,让unit文件生效
tasks:
- name: back up repo
shell: |
mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup
mv /etc/yum.repos.d/epel-testing.repo /etc/yum.repos.d/epel-testing.repo.backup
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
- name: delete /etc/systemd/system/noswap.service #禁用swap
file:
path: /etc/systemd/system/noswap.service
state: absent
- name: download repo #下载yum源
get_url:
url: "{{ item.url }}"
dest: "{{item.dest}}"
force: yes
with_items:
- {url: "https://mirrors.aliyun.com/repo/Centos-7.repo", dest: "/etc/yum.repos.d/CentOS-Base.repo"}
- {url: "http://mirrors.aliyun.com/repo/epel-7.repo", dest: "/etc/yum.repos.d/epel.repo"}
- {url: "http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo", dest: "/etc/yum.repos.d/docker-ce.repo"}
notify: update_yum #更新yum(见上面的handlers)
- name: install net-tools #安装必要的工具
yum:
name:
- net-tools
- vim
- rsync
- chrony
state: present
update_cache: true
tags: tools
- name: chrony_service
systemd:
name: chronyd
state: started #指定服务状态,其值可以为stopped停止、started启动、reloaded、restarted、running
enabled: yes #指定服务是否为开机启动,yes为启动,no为不启动
daemon_reload: yes #yes 重启systemd服务,让unit文件生效
tags: chronyd
- name: config /etc/hosts #关键 生成hosts文件
template:
src: hosts.j2
dest: /etc/hosts
mode: 0644
backup: false
tags:
- hosts
- name: set hostname #设置主机名
hostname:
name={{host_name}}
- name: set timezone to Asia-Shanghai #设置时区
shell: |
/usr/bin/timedatectl set-timezone Asia/Shanghai
chronyc -a makestep
tags:
- set_timezone
- name: stop firewalld service #关闭防火墙
service :
name: firewalld.service
state: stopped
enabled: no
register: firewalld_service_result
failed_when: "firewalld_service_result is failed and 'Could not find the requested service' not in firewalld_service_result.msg"
tags: stop-firewall
- name: Write noswap systemd service config file
template:
src: noswap.service.j2
dest: /etc/systemd/system/noswap.service
owner: root
group: root
mode: 0644
notify: noswap_service
- name: Disabling SELinux state #关闭suse
selinux:
state: disabled
- name: Reboot the machine #重启机器
reboot:
reboot_timeout: 300
templates/hosts.j2内容:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
{% for h in play_hosts %}
{{hostvars[h]['ansible_default_ipv4']['address']}} {{hostvars[h]['inventory_hostname']}}
{% endfor -%}
执行ansible-playbook -v 2.config.yaml完成相关配置工作
安装docker
按照官网说法,可以使用docker或者podman,本文选用docker。
剧本3.docker.yaml内容如下:
- name: install docker
hosts: all
gather_facts: True
vars:
DOCKERHUB_URL: registry.aliyuncs.com/google_containers
handlers:
tasks:
- name: mkdir -p /etc/docker/
file:
path: /etc/docker/
state: directory
- name: install docker
yum: name=docker-ce
- name: change config of docker
shell: |
cat > /etc/docker/daemon.json <<EOF
{"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://registry.aliyuncs.com","https://registry.cn-beijing.aliyuncs.com"]
}
EOF
tags:
- config
- name: add systemctl
systemd:
name: docker.service
state: started #指定服务状态,其值可以为stopped、started、reloaded、restarted、running
enabled: yes #指定服务是否为开机启动,yes为启动,no为不启动
daemon_reload: yes #yes 重启systemd服务,让unit文件生效
tags:
- docker-daemon
- name: docker login #在阿里云镜像仓库开了个账号,用于同步墙外面的镜像(https://cr.console.aliyun.com/cn-beijing/instance/credentials)
shell: docker login --username cyxinda@163.com --password *** registry.cn-beijing.aliyuncs.com
tags: login
执行ansible-playbook -v 3.docker.yaml完成安装docker的工作
开始创建ceph集群
安装cephadm
继续使用ansible为集群中每台机器安装ceph
剧本cephadm.yaml内容如下:
- name: download ceph
hosts: 127.0.0.1
connection: local
gather_facts: yes
tasks:
- name: download cephadm
get_url:
url: https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
dest: /tmp/ceph/cephadm
force: yes
mode: 755
timeout: 600
- name: download cephadm and install
hosts: all
gather_facts: True
tasks:
- name: mkdir workdir
file:
path: /tmp/ceph
state: directory
- name: 分发cephadm安装文件
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
owner: root
group: root
mode: "{{item.mode}}"
with_items:
- {src: "/tmp/ceph/cephadm", dest: "/tmp/ceph/cephadm",mode: "755" }
tags: cp-cephadm
- name: install python3
yum:
name:
- python3
- chrony
state: present
- name: add systemd
systemd:
name: chronyd
state: started #指定服务状态,其值可以为stopped、started、reloaded、restarted、running
enabled: yes #指定服务是否为开机启动,yes为启动,no为不启动
daemon_reload: yes #yes 重启systemd服务,让unit文件生效
- name: add ceph release
shell: /tmp/ceph/cephadm add-repo --release octopus
- name: install cephadm
shell: /tmp/ceph/cephadm install
- name: which cephadm
shell: which cephadm
register: which_cephadm
tags: which-ceph
- name: show
debug: var=which_cephadm verbosity=0 #check.stdout 显示出的信息会看的更清晰点
tags: show-result
执行ansible-playbook -v cephadm.yaml完成ceph的安装
引导集群
将master0作为引导主机,在其上面执行如下引导命令:
[root@master0 ~]# mkdir -p /etc/ceph
[root@master0 ~]# cephadm bootstrap --mon-ip 172.70.10.161
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: e3386564-bb02-11ec-af56-525400299ff7
Verifying IP 172.70.10.161 port 3300 ...
Verifying IP 172.70.10.161 port 6789 ...
Mon IP 172.70.10.161 is in CIDR network 172.70.10.0/24
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host master0...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://master0:8443/
User: admin
Password: vym1bdeajd
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid e3386564-bb02-11ec-af56-525400299ff7 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
在命令执行过程中,有如下提示:
Ceph Dashboard is now available at :
URL: https://master0:8443/
User: admin
Password: vym1bdeajd
按照提示,在浏览器上面可以访问:

进入到管理页面后,如下:

参照安装文档,该命令将:
在本地主机上为新集群创建一个监视器和管理器守护程序。
为 Ceph 集群生成一个新的 SSH 密钥并将其添加到 root 用户的/root/.ssh/authorized_keys文件中。
将与新集群通信所需的最小配置文件写入/etc/ceph/ceph.conf.
client.admin将管理(特权!)密钥的副本写入/etc/ceph/ceph.client.admin.keyring.
将公钥的副本写入 /etc/ceph/ceph.pub.
启用 CEPH CLI(必须)
继续在引导机器上面执行如下命令,即可开启ceph shell client
注意:后面的ceph命令,均需在ceph shell环境下执行
[root@master0 ~]# cephadm shell
Inferring fsid e3386564-bb02-11ec-af56-525400299ff7
Inferring config /var/lib/ceph/e3386564-bb02-11ec-af56-525400299ff7/mon.master0/config
Using recent ceph image quay.io/ceph/ceph@sha256:1b0ceef23cbd6a1af6ba0cbde344ebe6bde4ae183f545c1ded9c7c684239947f
[ceph: root@master0 /]# ceph -v
ceph version 15.2.16 (d46a73d6d0a67a79558054a3a5a72cb561724974) octopus (stable)
[ceph: root@master0 /]# ceph status
cluster:
id: e3386564-bb02-11ec-af56-525400299ff7
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum master0 (age 48m)
mgr: master0.ojikws(active, since 47m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
将主机添加到集群
- 在新主机的 root 用户 authorized_keys文件中安装集群的公共 SSH 密钥
[root@master0 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@master1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
The authenticity of host 'master1 (172.70.10.162)' can't be established.
ECDSA key fingerprint is SHA256:J40vT3JXLYRku40nj9oOq1XQMbnkTXZ2Qc5IDFAy4xc.
ECDSA key fingerprint is MD5:8d:ef:46:df:ce:06:7d:86:05:e9:04:ad:68:12:40:8c.
Are you sure you want to continue connecting (yes/no)? yes
root@master1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@master1'"
and check to make sure that only the key(s) you wanted were added.
[root@master0 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@master2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
The authenticity of host 'master2 (172.70.10.163)' can't be established.
ECDSA key fingerprint is SHA256:J40vT3JXLYRku40nj9oOq1XQMbnkTXZ2Qc5IDFAy4xc.
ECDSA key fingerprint is MD5:8d:ef:46:df:ce:06:7d:86:05:e9:04:ad:68:12:40:8c.
Are you sure you want to continue connecting (yes/no)? yes
root@master2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@master2'"
and check to make sure that only the key(s) you wanted were added.
这部分本来也可以用ansible做的,但是懒得写脚本了,就两台机器,也就罢了
添加机器到集群:
[ceph: root@ceph1 /]# ceph orch host add ceph2 172.70.10.162
Added host 'ceph2'
[ceph: root@ceph1 /]# ceph orch host add ceph3 172.70.10.163
Added host 'ceph3'
[ceph: root@ceph1 /]# ceph orch host add ceph4 172.70.10.164
Added host 'ceph4'
[ceph: root@ceph1 /]# ceph orch host add ceph5 172.70.10.165
Added host 'ceph5'
[ceph: root@ceph1 /]# ceph orch host add ceph6 172.70.10.166
Added host 'ceph6'
添加多个监控器
配置监视器子网:
[ceph: root@master0 /]# ceph config set mon public_network 172.70.10.0/24
[ceph: root@master0 /]# ceph config set mon public_network 172.70.10.0/24
##要启动三台监视器,需要调整监视器数量:
[ceph: root@master0 /]# ceph orch apply mon 3
Scheduled mon update...
按照官网的说法:Cephadm 仅在已配置子网中配置了 IP 的主机上部署新的监控守护程序
在一组特定的主机上部署监视器,请务必在此列表中包含第一个(引导)主机。
[ceph: root@master0 /]# ceph orch apply mon master0,master1,master2
Scheduled mon update...
##加标签
[ceph: root@master0 /]# ceph orch host label add master0 mon
Added label mon to host master0
[ceph: root@master0 /]# ceph orch host label add master1 mon
Added label mon to host master1
[ceph: root@master0 /]# ceph orch host label add master2 mon
Added label mon to host master2
[ceph: root@master0 /]# ceph orch host ls
HOST ADDR LABELS STATUS
master0 master0 mon
master1 master1 mon
master2 master2 mon
[ceph: root@master0 /]# ceph -s
cluster:
id: e3386564-bb02-11ec-af56-525400299ff7
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum master0,master1,master2 (age 88s)
mgr: master0.ojikws(active, since 73m), standbys: master1.uxevld
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
加入ODS
可以看到集群三台机器上面,一共挂载了6块磁盘:
[ceph: root@master0 /]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
master0 /dev/vdb hdd 536G Unknown N/A N/A Yes
master0 /dev/vdc hdd 536G Unknown N/A N/A Yes
master1 /dev/vdb hdd 536G Unknown N/A N/A Yes
master1 /dev/vdc hdd 536G Unknown N/A N/A Yes
master2 /dev/vdb hdd 536G Unknown N/A N/A Yes
master2 /dev/vdc hdd 536G Unknown N/A N/A Yes
当然在每台机器上面可以列出块设备(/dev/vdb 和 /dev/vdc):
[ceph: root@master0 /]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 500G 0 disk
|-vda1 252:1 0 1G 0 part /rootfs/boot
`-vda2 252:2 0 499G 0 part
|-centos-root 253:0 0 50G 0 lvm /rootfs
|-centos-swap 253:1 0 7.9G 0 lvm
`-centos-home 253:2 0 441.1G 0 lvm /rootfs/home
vdb 252:16 0 500G 0 disk
vdc 252:32 0 500G 0 disk
按照官网说法:设备满足
如果满足以下所有条件,则认为存储设备可用:
- 设备不能有分区。
- 设备不得具有任何 LVM 状态。
- 不得安装该设备。
- 设备不得包含文件系统。
- 设备不得包含 Ceph BlueStore OSD。
- 设备必须大于 5 GB。
Ceph将 拒绝在不可用的设备上配置 OSD
可以使用如下命令,将所有可用的磁盘添加到ceph集群中:
[ceph: root@master0 /]# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update...
[ceph: root@master0 /]# ceph -s
cluster:
id: e3386564-bb02-11ec-af56-525400299ff7
health: HEALTH_OK
services:
mon: 3 daemons, quorum master0,master1,master2 (age 12m)
mgr: master0.ojikws(active, since 84m), standbys: master1.uxevld
osd: 6 osds: 6 up (since 22s), 6 in (since 22s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 2.9 TiB / 2.9 TiB avail
pgs: 1 active+clean
也可以单独加入:
[ceph: root@master0 /]# ceph orch daemon add osd master0:/dev/vdb
[ceph: root@master0 /]# ceph orch daemon add osd master0:/dev/vdc
[ceph: root@master0 /]# ceph orch daemon add osd master1:/dev/vdb
[ceph: root@master0 /]# ceph orch daemon add osd master1:/dev/vdc
[ceph: root@master0 /]# ceph orch daemon add osd master2:/dev/vdb
[ceph: root@master0 /]# ceph orch daemon add osd master2:/dev/vdc
在前端看到:


挂载块设备
[root@ceph101 tmp]# ceph osd pool create test_rbd 32
pool 'test_rbd' created
[root@ceph101 tmp]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 5.9 TiB 5.8 TiB 1.1 GiB 13 GiB 0.22
TOTAL 5.9 TiB 5.8 TiB 1.1 GiB 13 GiB 0.22
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 1.9 TiB
.rgw.root 24 32 22 KiB 36 6.6 MiB 0 1.9 TiB
zone_01.rgw.log 31 32 26 KiB 965 55 MiB 0 1.9 TiB
zone_01.rgw.control 32 32 0 B 8 0 B 0 1.9 TiB
zone_01.rgw.meta 33 8 5.5 KiB 16 2.6 MiB 0 1.9 TiB
zone_01.rgw.buckets.index 34 8 672 KiB 55 2.0 MiB 0 1.9 TiB
zone_01.rgw.buckets.data 35 32 2.2 MiB 12 7.9 MiB 0 1.9 TiB
zone_01.rgw.otp 36 32 0 B 0 0 B 0 1.9 TiB
cp_pool 42 32 1.4 MiB 2 4.4 MiB 0 1.9 TiB
test_rbd 43 32 0 B 0 0 B 0 1.9 TiB
##创建镜像
[root@ceph101 tmp]# rbd create test_rbd_image_1 --size 10240 -p test_rbd
[root@ceph101 tmp]# rbd -p test_rbd ls
test_rbd_image_1
##检看一个RBD镜像的详细信息
[root@ceph101 tmp]# rbd --image test_rbd_image_1 info -p test_rbd
rbd image 'test_rbd_image_1':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 2836b2f53ea86
block_name_prefix: rbd_data.2836b2f53ea86
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten, journaling
op_features:
flags:
create_timestamp: Tue May 10 10:38:16 2022
access_timestamp: Tue May 10 10:38:16 2022
modify_timestamp: Tue May 10 10:38:16 2022
journal: 2836b2f53ea86
mirroring state: disabled
[root@ceph101 tmp]# rbd pool stats -p test_rbd
Total Images: 1
Total Snapshots: 0
Provisioned Size: 10 GiB
[root@ceph101 tmp]# rbd showmapped
id pool namespace image snap device
0 cp_pool image2 - /dev/rbd0
[root@ceph101 test_rbd]# umount -f /dev/rbd0
#或者
[root@ceph101 test_rbd]# rbd unmap -f /dev/rbd0
##然后将pool关联应用
[root@ceph101 ~]# ceph osd pool application enable test_rbd rbd
enabled application 'rbd' on pool 'test_rbd'
[root@ceph101 ~]# rbd map test_rbd/test_rbd_image_1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable test_rbd/test_rbd_image_1 journaling".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
[root@ceph101 ~]# uname -r
5.17.6-1.el7.elrepo.x86_64
[root@ceph101 ~]# dmesg | tail
[ 9.843030] random: crng init done
[ 9.843034] random: 7 urandom warning(s) missed due to ratelimiting
[ 10.669178] Bridge firewalling registered
[ 22.239147] process '/bin/ip' started with executable stack
[ 8185.140070] Key type ceph registered
[ 8185.140395] libceph: loaded (mon/osd proto 15/24)
[ 8185.141923] rbd: loaded (major 251)
[ 8185.158536] libceph: mon3 (1)172.70.10.184:6789 session established
[ 8185.160696] libceph: client175843 fsid 7a367006-c449-11ec-9566-525400ce981f
[ 8185.288221] rbd: image test_rbd_image_1: image uses unsupported features: 0x40
##根据提示`[ 8185.288221] rbd: image test_rbd_image_1: image uses unsupported features: 0x40`,可以确定内核不支持的features是十六进制0x40,转成十进制是4*16+0*1=64,即2的6次方=64,journaling
#layering: 支持分层**(0次方)**
#striping: 支持条带化 v2 **(1次方)**
#exclusive-lock: 支持独占锁 **(2次方)**
#object-map: 支持对象映射(依赖 exclusive-lock )**(3次方)**
#fast-diff: 快速计算差异(依赖 object-map )**(4次方)**
#deep-flatten: 支持快照扁平化操作**(5次方)**
#journaling: 支持记录 IO 操作(依赖独占锁)**(6次方)**
[root@ceph101 ~]# rbd feature disable test_rbd/test_rbd_image_1 journaling
[root@ceph101 ~]# rbd map test_rbd/test_rbd_image_1
/dev/rbd0
#lsblk 查看磁盘
[root@ceph101 test_rbd]# rbd showmapped
id pool namespace image snap device
0 test_rbd test_rbd_image_1 - /dev/rbd0
[root@ceph101 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 251:0 0 10G 0 disk
vdb 252:16 0 500G 0 disk
└─ceph--cbd3517f--a42b--41b9--bdb5--350597fb4873-osd--block--da454e2d--c289--430f--a685--9b437b5a3e00 253:4 0 500G 0 lvm
sr0 11:0 1 1024M 0 rom
vdc 252:32 0 500G 0 disk
└─ceph--797b51d7--f835--43d7--a987--1316a2438933-osd--block--40e4dc65--08e9--4971--9187--2d05208bbb0d 253:3 0 500G 0 lvm
vda 252:0 0 500G 0 disk
├─vda2 252:2 0 499G 0 part
│ ├─centos-swap 253:1 0 7.9G 0 lvm
│ ├─centos-home 253:2 0 441.1G 0 lvm /home
│ └─centos-root 253:0 0 50G 0 lvm /
└─vda1 252:1 0 1G 0 part /boot
# 格式化磁盘
[root@ceph101 ~]# mkfs.ext4 /dev/rbd0
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: 完成
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=16 blocks, Stripe width=16 blocks
655360 inodes, 2621440 blocks
131072 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2151677952
80 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information:
完成
##创建挂载目录
[root@ceph101 ~]# mkdir test_rbd/
#挂载
[root@ceph101 ~]# mount /dev/rbd0 /root/test_rbd
[root@ceph101 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 251:0 0 10G 0 disk /root/test_rbd
vdb 252:16 0 500G 0 disk
└─ceph--cbd3517f--a42b--41b9--bdb5--350597fb4873-osd--block--da454e2d--c289--430f--a685--9b437b5a3e00 253:4 0 500G 0 lvm
sr0 11:0 1 1024M 0 rom
vdc 252:32 0 500G 0 disk
└─ceph--797b51d7--f835--43d7--a987--1316a2438933-osd--block--40e4dc65--08e9--4971--9187--2d05208bbb0d 253:3 0 500G 0 lvm
vda 252:0 0 500G 0 disk
├─vda2 252:2 0 499G 0 part
│ ├─centos-swap 253:1 0 7.9G 0 lvm
│ ├─centos-home 253:2 0 441.1G 0 lvm /home
│ └─centos-root 253:0 0 50G 0 lvm /
└─vda1 252:1 0 1G 0 part /boot
#写入小说文档到挂载的目录
[root@ceph101 ~]# mv bcsj.txt test_rbd/
[root@ceph101 ~]# md5sum test_rbd/bcsj.txt
0d615ccd0e1c55f62002134f5cac81cc test_rbd/bcsj.txt
[root@ceph101 ~]# df -lh
文件系统 容量 已用 可用 已用% 挂载点
/dev/rbd0 9.7G 15M 9.2G 1% /root/test_rbd
[root@ceph101 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 5.9 TiB 5.8 TiB 1.5 GiB 14 GiB 0.23
TOTAL 5.9 TiB 5.8 TiB 1.5 GiB 14 GiB 0.23
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 1.9 TiB
.rgw.root 24 32 22 KiB 36 6.6 MiB 0 1.9 TiB
zone_01.rgw.log 31 32 26 KiB 965 55 MiB 0 1.9 TiB
zone_01.rgw.control 32 32 0 B 8 0 B 0 1.9 TiB
zone_01.rgw.meta 33 8 5.5 KiB 16 2.6 MiB 0 1.9 TiB
zone_01.rgw.buckets.index 34 8 672 KiB 55 2.0 MiB 0 1.9 TiB
zone_01.rgw.buckets.data 35 32 2.2 MiB 12 7.9 MiB 0 1.9 TiB
zone_01.rgw.otp 36 32 0 B 0 0 B 0 1.9 TiB
cp_pool 42 32 2.2 MiB 2 7.0 MiB 0 1.9 TiB
test_rbd 43 32 148 MiB 57 446 MiB 0 1.9 TiB
对象网关
yum install ceph-radosgw -y
[ceph: root@ceph1 ceph]# radosgw-admin user create --uid='s3_admin' --display-name='s3_rgw_admin' --access-key='s3_rgw_admin_access_key' --secret-key='s3_rgw_admin_secret_key'
{
"user_id": "s3_admin",
"display_name": "s3_rgw_admin",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3_admin",
"access_key": "s3_rgw_admin_access_key",
"secret_key": "s3_rgw_admin_secret_key"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
[ceph: root@ceph1 ceph]#
[ceph: root@ceph1 ceph]# radosgw-admin user info --uid='s3_admin'
{
"user_id": "s3_admin",
"display_name": "s3_rgw_admin",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3_admin",
"access_key": "s3_rgw_admin_access_key",
"secret_key": "s3_rgw_admin_secret_key"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
ceph tell mon.* injectargs --mon_max_pg_per_osd=100
#----------------------------------------------------------------------------
radosgw-admin user create --uid=rgw_admin --display-name=rgw_admin --system
radosgw-admin user info --uid rgw_admin --system
radosgw-admin realm create --rgw-realm=realm_1 --default
radosgw-admin zonegroup create \
--rgw-realm=realm_1 \
--rgw-zonegroup=zone_group_1 \
--endpoints http://ceph101:80 \
--master --default
radosgw-admin zone modify \
--rgw-realm=realm_1 \
--rgw-zonegroup=zone_group_1 \
--rgw-zone=zone_01 \
--endpoints http://ceph101:80 \
--access-key=IAWL6PLNFMNM0SLQNWQ0 \
--secret=pZTNQ8HThJVXOHBnx5VCP1qJgPGfT9LTMpmwjhAo \
--master --default
radosgw-admin period update --commit
radosgw-admin period update --rgw-realm=realm_1
ceph orch apply rgw realm_1 zone_01 --placement="1 ceph101"
上述命令,一定要在集群健康的情况下运行,否则会出现rgw 的docker进程启动不了的情况,正常情况下,可以看到如下进程:
[root@ceph101 ~]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 4m ago 2d count:1 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f
crash 6/6 4m ago 2d * quay.io/ceph/ceph:v15 3edede73a7c4
grafana 1/1 4m ago 2d count:1 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646
mgr 2/2 4m ago 2d count:2 quay.io/ceph/ceph:v15 3edede73a7c4
mon 5/5 4m ago 2d ceph101;ceph102;ceph103;ceph104;ceph105 quay.io/ceph/ceph:v15 3edede73a7c4
node-exporter 6/6 4m ago 2d * quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf
osd.None 12/0 4m ago - <unmanaged> quay.io/ceph/ceph:v15 3edede73a7c4
prometheus 1/1 4m ago 2d count:1 quay.io/prometheus/prometheus:v2.18.1 de242295e225
rgw.realm_1.zone_01 1/1 4m ago 75m ceph101;count:1 quay.io/ceph/ceph:v15 3edede73a7c4
如果rgw进程无法启动的情况,可能是集群不健康,查看log:
ceph log last cephadm
/var/log/ceph/cephadm.log
[root@ceph101 system]# ceph log last cephadm
2022-04-27T07:57:57.347323+0000 mgr.ceph101.qhgzmi (mgr.14164) 95889 : cephadm [ERR] Failed to apply rgw.realm_1.zone_group_1acementSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlaceme': 'rgw', 'service_id': 'realm_1.zone_group_1', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone' 'rgw_frontend_ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when healt
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T07:57:57.353366+0000 mgr.ceph101.qhgzmi (mgr.14164) 95890 : cephadm [ERR] Failed to apply rgw.realm_1.zone_01 specntSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlacementSpegw', 'service_id': 'realm_1.zone_01', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone': 'zone_01ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when health ok
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:07:22.102133+0000 mgr.ceph101.qhgzmi (mgr.14164) 96175 : cephadm [INF] refreshing ceph104 facts
2022-04-27T08:07:22.103197+0000 mgr.ceph101.qhgzmi (mgr.14164) 96176 : cephadm [INF] refreshing ceph103 facts
2022-04-27T08:07:22.105047+0000 mgr.ceph101.qhgzmi (mgr.14164) 96177 : cephadm [INF] refreshing ceph106 facts
2022-04-27T08:07:22.105643+0000 mgr.ceph101.qhgzmi (mgr.14164) 96178 : cephadm [INF] refreshing ceph105 facts
2022-04-27T08:07:22.106985+0000 mgr.ceph101.qhgzmi (mgr.14164) 96179 : cephadm [INF] refreshing ceph102 facts
2022-04-27T08:07:22.910395+0000 mgr.ceph101.qhgzmi (mgr.14164) 96181 : cephadm [INF] refreshing ceph101 facts
2022-04-27T08:07:23.599992+0000 mgr.ceph101.qhgzmi (mgr.14164) 96182 : cephadm [ERR] Failed to apply rgw.realm_1.zone_group_1acementSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlaceme': 'rgw', 'service_id': 'realm_1.zone_group_1', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone' 'rgw_frontend_ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when healt
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:07:23.615964+0000 mgr.ceph101.qhgzmi (mgr.14164) 96183 : cephadm [ERR] Failed to apply rgw.realm_1.zone_01 specntSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlacementSpegw', 'service_id': 'realm_1.zone_01', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone': 'zone_01ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when health ok
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:07:23.784884+0000 mgr.ceph101.qhgzmi (mgr.14164) 96184 : cephadm [ERR] Failed to apply rgw.realm_1.zone_group_1acementSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlaceme': 'rgw', 'service_id': 'realm_1.zone_group_1', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone' 'rgw_frontend_ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when healt
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:07:23.788497+0000 mgr.ceph101.qhgzmi (mgr.14164) 96185 : cephadm [ERR] Failed to apply rgw.realm_1.zone_01 specntSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlacementSpegw', 'service_id': 'realm_1.zone_01', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone': 'zone_01ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when health ok
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:16:33.025623+0000 mgr.ceph101.qhgzmi (mgr.14164) 96463 : cephadm [INF] Saving service rgw.realm_1.zone_01 spec
2022-04-27T08:16:33.240231+0000 mgr.ceph101.qhgzmi (mgr.14164) 96464 : cephadm [INF] refreshing ceph101 facts
2022-04-27T08:16:33.248641+0000 mgr.ceph101.qhgzmi (mgr.14164) 96465 : cephadm [INF] refreshing ceph102 facts
2022-04-27T08:16:33.250945+0000 mgr.ceph101.qhgzmi (mgr.14164) 96466 : cephadm [INF] refreshing ceph103 facts
2022-04-27T08:16:33.252787+0000 mgr.ceph101.qhgzmi (mgr.14164) 96467 : cephadm [INF] refreshing ceph104 facts
2022-04-27T08:16:33.254250+0000 mgr.ceph101.qhgzmi (mgr.14164) 96468 : cephadm [INF] refreshing ceph105 facts
2022-04-27T08:16:33.256573+0000 mgr.ceph101.qhgzmi (mgr.14164) 96469 : cephadm [INF] refreshing ceph106 facts
2022-04-27T08:16:34.288319+0000 mgr.ceph101.qhgzmi (mgr.14164) 96470 : cephadm [ERR] Failed to apply rgw.realm_1.zone_group_1acementSpec(hostname='ceph101', network='', name=''), HostPlacementSpec(hostname='ceph102', network='', name=''), HostPlaceme': 'rgw', 'service_id': 'realm_1.zone_group_1', 'unmanaged': False, 'preview_only': False, 'rgw_realm': 'realm_1', 'rgw_zone' 'rgw_frontend_ssl_certificate': None, 'rgw_frontend_ssl_key': None, 'ssl': False}): Health not ok, will try again when healt
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
2022-04-27T08:16:34.292193+0000 mgr.ceph101.qhgzmi (mgr.14164) 96471 : cephadm [ERR] Failed to apply rgw.realm_1.zone_01 specntSpec(hostname='ceph101', network='', name='')]), 'service_type': 'rgw', 'service_id': 'realm_1.zone_01', 'unmanaged': Falsene_01', 'subcluster': None, 'rgw_frontend_port': None, 'rgw_frontend_ssl_certificate': None, 'rgw_frontend_ssl_key': None, 's
Traceback (most recent call last):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 412, in _apply_all_services
if self._apply_service(spec):
File "/usr/share/ceph/mgr/cephadm/serve.py", line 511, in _apply_service
rgw_config_func(cast(RGWSpec, spec), daemon_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 539, in config
self.create_realm_zonegroup_zone(spec, rgw_id)
File "/usr/share/ceph/mgr/cephadm/services/cephadmservice.py", line 617, in create_realm_zonegroup_zone
raise OrchestratorError('Health not ok, will try again when health ok')
orchestrator._interface.OrchestratorError: Health not ok, will try again when health ok
进入到docker中
docker exec -it 736e1816f245 /bin/sh
sh-4.4# cd /usr/share/ceph/mgr/cephadm/services/
sh-4.4# ls
__init__.py cephadmservice.py container.py iscsi.py monitoring.py nfs.py osd.py
sh-4.4# vim cephadmservice.py
sh: vim: command not found
sh-4.4# vi cephadmservice.py
##可以看到是因为python代码查看集群的状态为 Health not ok,所以不能向下进行了。
#进一步,将集群调整为健康状态,再次尝试,可以正常
访问s3对象服务,windows下安装S3 Browser
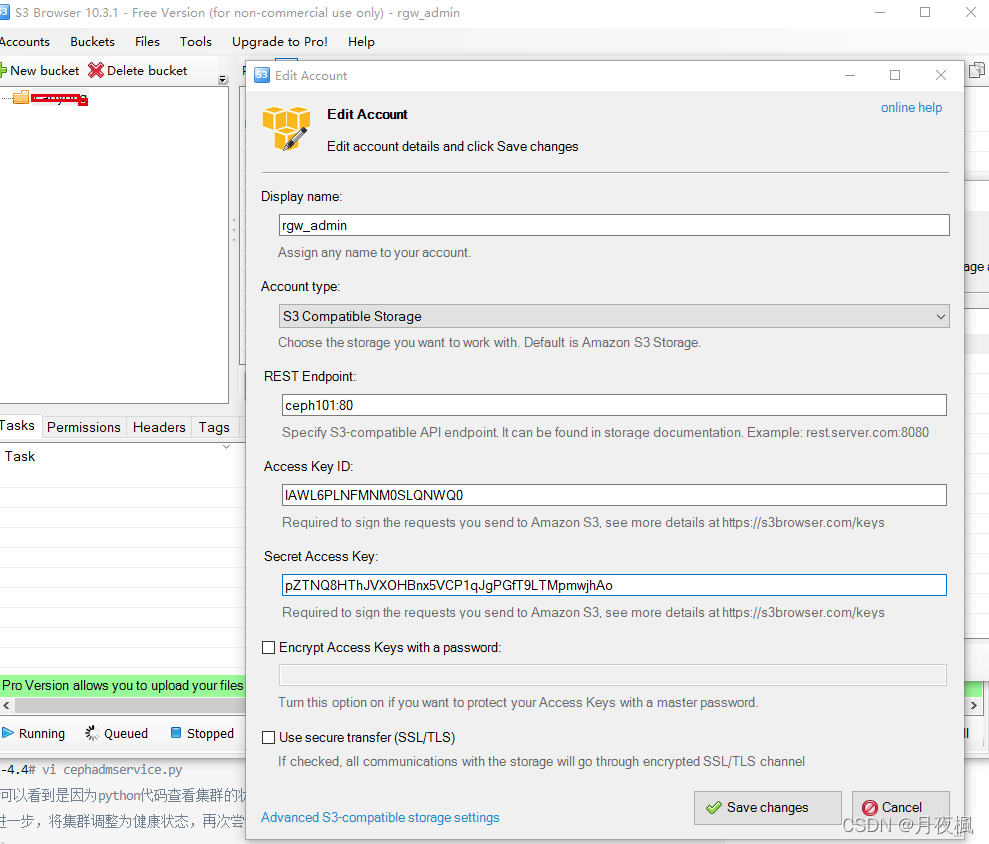
创建用户后,不知道为什么用户被自动删除掉了,重新建立了一下用户,再次绑定zone之后,就可以使用s3 Broswer正常访问了。
其他常用命令:
radosgw-admin realm delete --rgw-realm=realm_1
radosgw-admin zonegroup delete --rgw-zonegroup=zone_group_1
radosgw-admin zone delete --rgw-zone=zone_1
radosgw-admin realm list
radosgw-admin zonegroup list
radosgw-admin zone list
radosgw-admin zone list --rgw-zonegroup default
radosgw-admin user info --uid rgw_admin --system
s3cmd mb s3://sec --region=zone_group_1
配置dashboard:
1752 2022-05-09 11:21:28 radosgw-admin user list
1755 2022-05-09 11:22:06 radosgw-admin user info --uid rgw_admin
1757 2022-05-09 11:34:44 vim access.key
1758 2022-05-09 11:35:00 vim secret.key
1759 2022-05-09 11:35:21 ceph dashboard set-rgw-api-access-key -i access.key
1760 2022-05-09 11:35:34 ceph dashboard set-rgw-api-secret-key -i secret.key
1761 2022-05-09 11:36:49 history
在前端可以看到
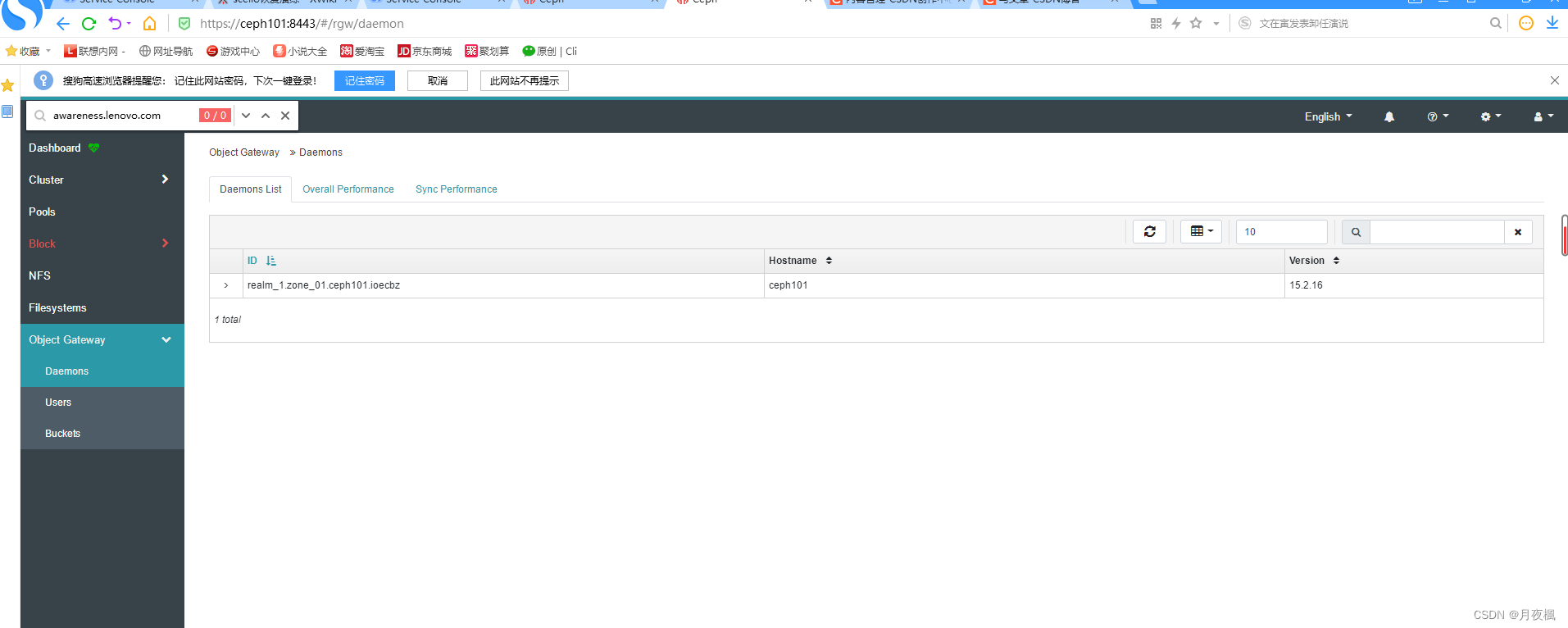
搭建主-主备份
radosgw-admin realm pull --url=http://172.70.10.181:80 --access-key=IAWL6PLNFMNM0SLQNWQ0 --secret=pZTNQ8HThJVXOHBnx5VCP1qJgPGfT9LTMpmwjhAo
radosgw-admin zone modify --rgw-zonegroup=zone_group_1 \
--rgw-zone=zone_02 --url=http://ceph101:80 \
--access-key=IAWL6PLNFMNM0SLQNWQ0 --secret=pZTNQ8HThJVXOHBnx5VCP1qJgPGfT9LTMpmwjhAo \
--endpoints=http://ceph1:80
radosgw-admin period update --commit
ceph orch apply rgw realm_1 zone_02 --placement="1 ceph1"
查看应用的配置
[root@ceph5 f88b0b1a-c467-11ec-a2b8-525400299ff7]# ceph config dump
[root@ceph5 f88b0b1a-c467-11ec-a2b8-525400299ff7]# pwd
/var/lib/ceph/f88b0b1a-c467-11ec-a2b8-525400299ff7
[root@ceph5 f88b0b1a-c467-11ec-a2b8-525400299ff7]# ll
总用量 0
drwx------ 4 ceph ceph 92 4月 27 18:52 crash
drwx------ 2 ceph ceph 133 4月 25 16:07 crash.ceph5
drwx------ 3 ceph ceph 190 4月 27 17:04 mon.ceph5
drwx------ 2 65534 65534 104 4月 25 16:07 node-exporter.ceph5
drwx------ 2 ceph ceph 241 4月 28 19:42 osd.4
drwx------ 4 root root 88 4月 28 10:59 removed
drwx------ 2 ceph ceph 133 4月 28 19:57 rgw.realm_1.zone_03.ceph5.tapydb
[root@ceph5 f88b0b1a-c467-11ec-a2b8-525400299ff7]# ceph config show rgw.realm_1.zone_03.ceph5.tapydb
NAME VALUE SOURCE OVERRIDES IGNORES
admin_socket $run_dir/$cluster-$name.$pid.$cctid.asok default
container_image quay.io/ceph/ceph:v15 mon
daemonize false override
debug_rgw 1/5 default
keyring $rgw_data/keyring default
log_stderr_prefix debug default
log_to_file false default
log_to_stderr true default
mon_host [v2:172.70.10.161:3300/0,v1:172.70.10.161:6789/0] [v2:172.70.10.162:3300/0,v1:172.70.10.162:6789/0] [v2:172.70.10.163:3300/0,v1:172.70.10.163:6789/0] [v2:172.70.10.164:3300/0,v1:172.70.10.164:6789/0] [v2:172.70.10.165:3300/0,v1:172.70.10.165:6789/0] file
no_config_file false override
objecter_inflight_ops 24576 default
rbd_default_features 61 default
rgw_frontends beast port=80 mon
rgw_realm realm_1 mon
rgw_zone zone_03 mon
setgroup ceph cmdline
setuser ceph cmdline
对于想修改rgw启动端口的,可以修改配置文件
##在一个域realm和一个zonegroup下面,可以创建多个zone,每个zone上面可以创建一个rgw,所以再次创建一个rgw网关
radosgw-admin realm pull --url=http://172.70.10.181:80 --access-key=IAWL6PLNFMNM0SLQNWQ0 --secret=pZTNQ8HThJVXOHBnx5VCP1qJgPGfT9LTMpmwjhAo
radosgw-admin zone modify --rgw-zonegroup=zone_group_1 \
--rgw-zone=zone_03 --url=http://ceph101:80 \
--access-key=IAWL6PLNFMNM0SLQNWQ0 --secret=pZTNQ8HThJVXOHBnx5VCP1qJgPGfT9LTMpmwjhAo \
--endpoints=http://ceph5:8088
radosgw-admin period update --commit
ceph orch apply rgw realm_1 zone_03 --placement="1 ceph1"
[root@ceph5 rgw.realm_1.zone_03.ceph5.crocaj]# pwd
/var/lib/ceph/f88b0b1a-c467-11ec-a2b8-525400299ff7/rgw.realm_1.zone_03.ceph5.crocaj
[root@ceph5 rgw.realm_1.zone_03.ceph5.crocaj]# vim
`# minimal ceph.conf for f88b0b1a-c467-11ec-a2b8-525400299ff7
[global]
fsid = f88b0b1a-c467-11ec-a2b8-525400299ff7
mon_host = [v2:172.70.10.161:3300/0,v1:172.70.10.161:6789/0] [v2:172.70.10.162:3300/0,v1:172.70.10.162:6789/0] [v2:172.70.10.163:3300/0,v1:172.70.10.163:6789/0] [v2:172.70.10.164:3300/0,v1:172.70.10.164:6789/0] [v2:172.70.10.165:3300/0,v1:172.70.10.165:6789/0]
[client]
rgw_frontends = "beast port=8088"
`
#然后重启rgw服务
#还可以通过执行ceph config set client.rgw.realm_1.zone_03 rgw_frontends "beast port=18888"
#去掉config中的配置项,重启服务,也可以生效
#至于精确的配置如:
`
[client.rgw.realm_1.zone_03]
rgw_frontends = "beast port=8888"
`
#试了很多次,都不好用,官网说的不明白
参见:
指定rgw的数据池
移除osd
如果是用命令行,操作如下:
将节点状态标记为out (节点已经不再提供服务)
[root@ceph1 ~]# ceph osd out osd.5
从crush中移除节点(不删除会影响到当前主机的host crush weight)
[root@ceph1 ~]# ceph osd crush remove osd.5
删除节点
[root@ceph1 ~]# ceph osd rm osd.5
删除节点认证(不删除编号会占住)
[root@ceph1 ~]# ceph auth ls
[root@ceph1 ~]# ceph auth del osd.5
[root@ceph1 ~]# ceph orch daemon stop osd.5
Scheduled to stop osd.5 on host 'ceph6'
[root@ceph1 ~]# ceph health detail
HEALTH_WARN 1 failed cephadm daemon(s)
[WRN] CEPHADM_FAILED_DAEMON: 1 failed cephadm daemon(s)
daemon osd.5 on ceph6 is in error state
[root@ceph1 ~]# ceph orch daemon rm osd.5 --force
Removed osd.5 from host 'ceph6'
恢复磁盘:
找到某个未加载的盘,有两种方式:
[root@ceph6 osd.5_2022-05-11T02:14:55.313464Z]# ceph osd metadata
和
[root@ceph6 osd.5_2022-05-11T02:14:55.313464Z]# pwd
/var/lib/ceph/f88b0b1a-c467-11ec-a2b8-525400299ff7/removed/osd.5_2022-05-11T02:14:55.313464Z
[root@ceph6 osd.5_2022-05-11T02:14:55.313464Z]# ll
总用量 52
lrwxrwxrwx 1 ceph ceph 93 5月 10 12:47 block -> /dev/ceph-2e1cc736-34d6-4dac-8d7c-f78db028a9eb/osd-block-c831faa6-7cc6-4c04-9709-c33fb29a45f3
-rw------- 1 ceph ceph 37 5月 10 12:47 ceph_fsid
-rw------- 1 ceph ceph 377 4月 28 19:43 config
-rw------- 1 ceph ceph 37 5月 10 12:47 fsid
-rw------- 1 ceph ceph 55 5月 10 12:47 keyring
-rw------- 1 ceph ceph 6 5月 10 12:47 ready
-rw------- 1 ceph ceph 3 4月 25 17:04 require_osd_release
-rw------- 1 ceph ceph 10 5月 10 12:47 type
-rw------- 1 ceph ceph 38 4月 28 19:43 unit.configured
-rw------- 1 ceph ceph 48 4月 25 17:04 unit.created
-rw------- 1 ceph ceph 22 4月 28 19:43 unit.image
-rw------- 1 ceph ceph 931 4月 28 19:43 unit.poststop
-rw------- 1 ceph ceph 2035 4月 28 19:43 unit.run
-rw------- 1 ceph ceph 2 5月 10 12:47 whoami
[root@ceph6 osd.5_2022-05-11T02:14:55.313464Z]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vdb 252:16 0 500G 0 disk
└─ceph--2e1cc736--34d6--4dac--8d7c--f78db028a9eb-osd--block--c831faa6--7cc6--4c04--9709--c33fb29a45f3 253:4 0 500G 0 lvm
sr0 11:0 1 1024M 0 rom
vdc 252:32 0 500G 0 disk
└─ceph--beabac1e--6d55--481b--99e4--db03786e8f78-osd--block--7f9316bd--d011--426f--be86--52b8bfad4c0b 253:3 0 500G 0 lvm
vda 252:0 0 500G 0 disk
├─vda2 252:2 0 499G 0 part
│ ├─centos-swap 253:1 0 7.9G 0 lvm
│ ├─centos-home 253:2 0 441.1G 0 lvm /home
│ └─centos-root 253:0 0 50G 0 lvm /
└─vda1 252:1 0 1G 0 part /boot
可用确定是ceph6上面的/dev/vdb块设备
#zap该磁盘,使其可重新被使用
[root@ceph1 ~]# ceph orch device zap ceph6 /dev/vdb --force
/bin/docker: stderr --> Zapping: /dev/vdb
/bin/docker: stderr Running command: /usr/bin/dd if=/dev/zero of=/dev/vdb bs=1M count=10 conv=fsync
/bin/docker: stderr stderr: 10+0 records in
/bin/docker: stderr 10+0 records out
/bin/docker: stderr stderr: 10485760 bytes (10 MB, 10 MiB) copied, 1.1166 s, 9.4 MB/s
/bin/docker: stderr --> Zapping successful for: <Raw Device: /dev/vdb>
[root@ceph1 ~]# ceph orch daemon add osd ceph106:/dev/vdc
ceph orch daemon rm osd.5 --force
ceph osd out osd.5
ceph osd rm osd.5
ceph osd crush rm osd.5
pg故障处理
[root@k8snode001 ~]# ceph health detail
HEALTH_ERR 1/973013 objects unfound (0.000%); 17 scrub errors; Possible data damage: 1 pg recovery_unfound, 8 pgs inconsistent, 1 pg repair; Degraded data redundancy: 1/2919039 objects degraded (0.000%), 1 pg degraded
OBJECT_UNFOUND 1/973013 objects unfound (0.000%)
pg 2.2b has 1 unfound objects
OSD_SCRUB_ERRORS 17 scrub errors
PG_DAMAGED Possible data damage: 1 pg recovery_unfound, 8 pgs inconsistent, 1 pg repair
pg 2.2b is active+recovery_unfound+degraded, acting [14,22,4], 1 unfound
pg 2.44 is active+clean+inconsistent, acting [14,8,21]
pg 2.73 is active+clean+inconsistent, acting [25,14,8]
pg 2.80 is active+clean+scrubbing+deep+inconsistent+repair, acting [4,8,14]
pg 2.83 is active+clean+inconsistent, acting [14,13,6]
pg 2.ae is active+clean+inconsistent, acting [14,3,2]
pg 2.c4 is active+clean+inconsistent, acting [8,21,14]
pg 2.da is active+clean+inconsistent, acting [23,14,15]
pg 2.fa is active+clean+inconsistent, acting [14,23,25]
PG_DEGRADED Degraded data redundancy: 1/2919039 objects degraded (0.000%), 1 pg degraded
pg 2.2b is active+recovery_unfound+degraded, acting [14,22,4], 1 unfound
2.查看pg map
[root@k8snode001 ~]# ceph pg map 2.2b
osdmap e10373 pg 2.2b (2.2b) -> up [14,22,4] acting [14,22,4]
从pg map可以看出,pg 2.2b分布到osd [14,22,4]上
3.查看存储池状态
[root@k8snode001 ~]# ceph osd pool stats k8s-1
pool k8s-1 id 2
1/1955664 objects degraded (0.000%)
1/651888 objects unfound (0.000%)
client io 271 KiB/s wr, 0 op/s rd, 52 op/s wr
[root@k8snode001 ~]# ceph osd pool ls detail|grep k8s-1
pool 2 'k8s-1' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 88 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
4.尝试恢复pg 2.2b丢失的块
[root@k8snode001 ~]# ceph pg repair 2.2b
如果一直修复不成功,可以查看卡住PG的具体信息,主要关注recovery_state,命令如下
[root@k8snode001 ~]# ceph pg 2.2b query
如果repair修复不了;
两种解决方案,回退旧版或者直接删除
回退旧版
[root@k8snode001 ~]# ceph pg 2.2b mark_unfound_lost revert
直接删除
[root@k8snode001 ~]# ceph pg 2.2b mark_unfound_lost delete
卸载
卸载过程:
重命名命令alias ceph='cephadm shell -- ceph'
#找到fsid
[root@master1 ~]# ceph -s
Inferring fsid 008a0d2e-b163-11ec-ba7a-5254004c51c6
Inferring config /var/lib/ceph/008a0d2e-b163-11ec-ba7a-5254004c51c6/mon.master1/config
Using recent ceph image quay.io/ceph/ceph@sha256:1b0ceef23cbd6a1af6ba0cbde344ebe6bde4ae183f545c1ded9c7c684239947f
2022-04-01T03:20:37.240+0000 7f27a2b6b700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2022-04-01T03:20:37.240+0000 7f27a2b6b700 -1 AuthRegistry(0x7f279c05ec00) no keyring found at /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
2022-04-01T03:20:37.242+0000 7f27a2b6b700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2022-04-01T03:20:37.242+0000 7f27a2b6b700 -1 AuthRegistry(0x7f27a2b69f90) no keyring found at /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
2022-04-01T03:20:37.243+0000 7f27a0907700 -1 monclient(hunting): handle_auth_bad_method server allowed_methods [2] but i only support [1]
2022-04-01T03:20:37.243+0000 7f27a2b6b700 -1 monclient: authenticate NOTE: no keyring found; disabled cephx authentication
[errno 13] RADOS permission denied (error connecting to the cluster)
#使用fsid删除集群
[root@master1 ~]# cephadm rm-cluster --fsid 008a0d2e-b163-11ec-ba7a-5254004c51c6 --force
分发ceph.pub
playbook -v 2.mon1.yaml -t "find_pub,show_pub,push_pub" --extra-vars "ceph_pub_path=/tmp/ceph/master1/etc/ceph/ceph.pub"
或
playbook -v 2.mon1.yaml -t "find_pub,show_pub,push_pub" -e "ceph_pub_path=/tmp/ceph/master1/etc/ceph/ceph.pub"
使用 ansible master0 -m setup 可以看所有的变量
参考:http://ansible.com.cn/docs/playbooks_variables.html
jinja2参考:
https://stackoverflow.com/questions/36328907/ansible-get-all-the-ip-addresses-of-a-group
playbook -v 2.mon1.yaml
playbook -v 3.push.pub.key.yaml -e "pub_key=/tmp/ceph/master1/etc/ceph/ceph.pub"
playbook -v 4.add.host.yaml -t "weave-script" -e "mon1=master1"
本篇介绍Ceph Monitor的子命令,通过子命令的配合实现对MON的管理和配置。
- 添加(add) 在某个地址上新增一个名字为的MON服务。
示例:
ceph mon add <IPaddr[:port]> - 导出(dump) 显示特定版本的MON map的格式化的信息,该命令可以指定MON map的版本信息,具体示例如下,参数为epoch:
ceph mon dump {<int[0-]>}
ceph mon dump 1 - 获取映射(getmap) 获取特定版本的MON map信息,该命令获取的是二进制的信息,可以保持在某个文件中,具体格式如下:
ceph mon getmap {<int[0-]>}
示例:
ceph mon getmap 2 –o filename - 移除(remove) 移除特定名称的MON服务节点。具体格式如下:
ceph mon remove
示例:
ceph mon remove osd3 - 获取状态( stat) 显示MON的摘要状态信息,具体格式如下:
ceph mon stat - 报告状态(mon_status) 报告MON的状态,相对详细,具体格式如下:
ceph mon_status
Ceph命令之ceph mon(Monitor管理)















 2368
2368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









