






比较多这一部分,包含了编译和链接,书还没看完就先记录一下其中编译的一部分
编译
gcc编译分为预处理、编译、汇编、链接四个步骤
预处理
也称预编译,主要处理的是源代码文件中以“#”开始的预编译指令,这里简单讲一下规则:
1.删除“#define”并展开所有宏定义
补充:
宏定义是 C/C++ 中通过#define指令定义的符号替换规则,分为无参宏和有参宏两种
无参宏:简单文本替换
#define PI 3.1415926
有参宏:类似函数替换
#define MAX(a, b) ((a) > (b) ? (a) : (b))
删除定义本身后,代码中用到宏的地方会被替换为定义的内容,宏会递归展开,直到没有可替换 的宏为止,总结来说就是宏定义就是通过#define定义的符号替换规则,预编译时会删除定义并展开所有宏调用,生成纯粹的 C 代码
这里尝试一下
#define SQUARE(x) (x * x)
int x = SQUARE(2 + 3);gcc -E 1.c -o 1.i
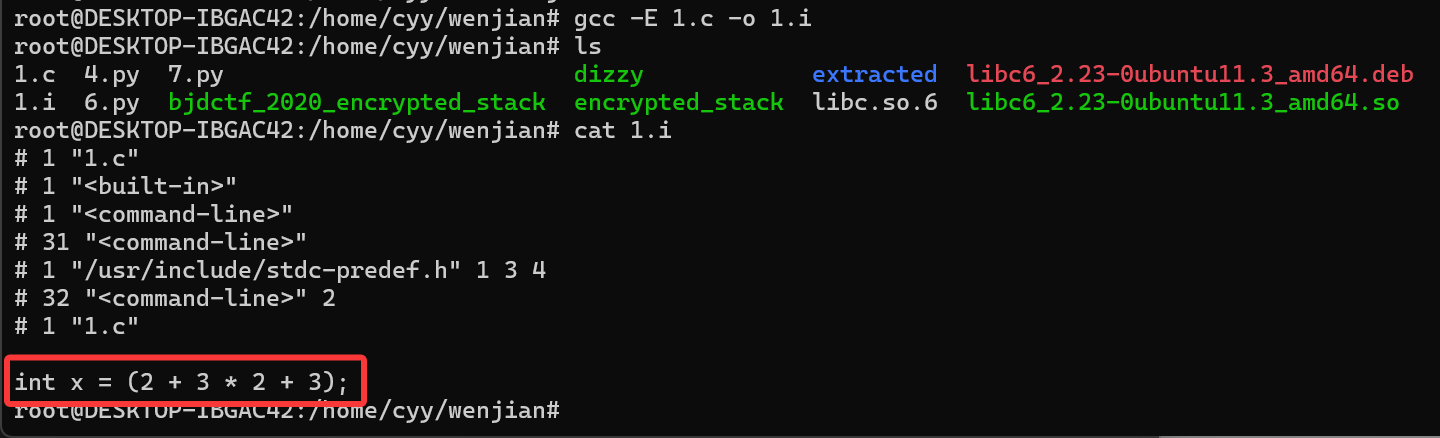
可以看到所有的#define都没了,宏调用被替换为实际值
2.处理所有条件预编译指令,例如“#if”、“#ifdef”、“elif”、“else”、“#endif”
预处理器会计算条件表达式或检查宏是否定义,仅保留符合条件的代码块,其余部分也就是条件 指令本身(如#if、#ifdef)直接删除
3.处理“#include”,将被包含的文件插入到该预编译指令位置,这个过程是递归的,所以被包含的 文件可能还包含了其他文件
当预处理器遇到#include时,首先找到被包含的文件,然后将文件内容完整插入到#include位 置,如果被包含的文件中还有#include,就会重复上述过程,造成被包含的文件还包含了其他文 件的结果,直到没有更多嵌套包含
简单举个例子
// main.c
#include "A.h"
// A.h
#include "B.h"
int foo();
// B.h
#include "C.h"
void bar();
// C.h
#define PI 3.14在预处理过程中会经历以下过程
展开
A.h→ 发现A.h包含B.h展开
B.h→ 发现B.h包含C.h展开
C.h→ 插入#define PI 3.14回退到
B.h→ 插入void bar();回退到
A.h→ 插入int foo();
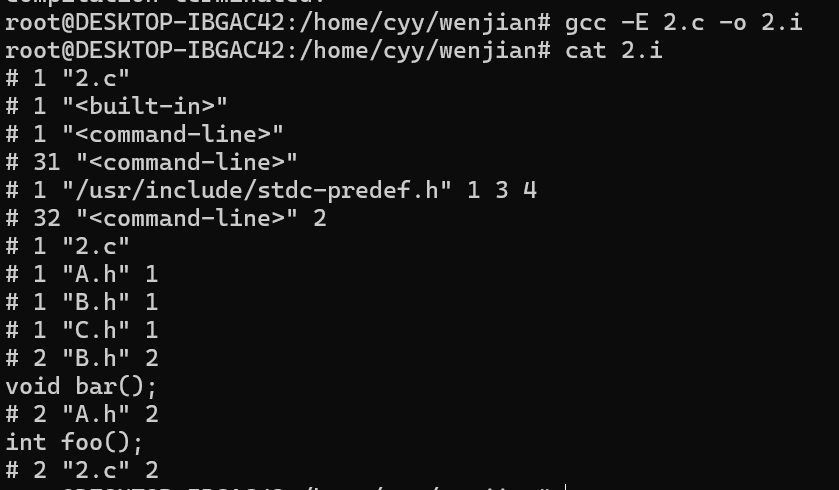
最终内容是这样的
4.删除所有注释“//”和“/**/”,以简化后续步骤
5.添加行号和文件名标识,比如#2 “1.c” 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告可以显示行号
6.保留所有的#pragma编译器指令
补充:
#pragma是 C/C++ 标准中定义的编译器特定指令
语法如下
#pragma directive_name [options]
以#pragma开头,后面跟具体的指令名称和可选参数
它不是语言标准的核心部分,而是由编译器自行定义和实现的,因此不同编译器(如 GCC、 Clang、MSVC)支持的#pragma指令可能不同
之所以不展开是因为它不是预处理器指令,而是为编译器后续阶段服务的,许多#pragma指令会 直接影响编译器的行为(如优化、对齐、警告控制等),因此需要保留到编译阶段由编译器解析
下面是我找到的一些常见的#pragma指令
//控制编译器警告
#pragma GCC diagnostic warning "-Wunused-variable" // 强制将特定警告设为错误
#pragma GCC diagnostic ignored "-Wdeprecated" // 忽略特定警告
//代码优化
#pragma GCC optimize("O3") // 强制对当前代码使用 O3 优化级别
//数据对齐
#pragma pack(1) // 强制结构体按 1 字节对齐(取消填充)
//特定平台支持
#pragma once // 防止头文件重复包含(非标准但广泛支持)
#pragma weak symbol_name // 定义弱符号(用于链接时覆盖)
//OpenMP并行化
#pragma omp parallel for // 启用 OpenMP 并行循环这里说一下OpenMP 并行化
OpenMP是一种用于共享内存并行编程的 API(应用程序接口),支持 C、C++ 和 Fortran。 通过编译器指令(如#pragma)、库函数和环境变量,能够轻松地将串行代码并行化,利用多核 CPU 的并行计算能力
OpenMP 的并行化是通过在代码中插入特定的#pragma omp指令,将任务分配给多个线程执 行,举个例子
#pragma omp parallel for
for (int i = 0; i < 100; i++) {
printf("Thread %d handles iteration %d\n", omp_get_thread_num(), i);
}
这会将循环的 100 次迭代分配到多个线程上并行执行
编译
就是把预处理完的文件进行一系列分析、优化后生成相应的汇编代码文件,也就是下面这个命令(这里的.s后缀是汇编语言源代码文件常见的后缀)
gcc -S 1.i -o 1.s
现在的预处理和编译一般都合成一步进行了,使用下面这个命令就可以了
gcc -S 1.c -o 1.s
不同的语言对应的程序不同,假如这个是c语言,那么这个程序就是cc1(GCC 的实际C 编译器前端,负责将预处理后的 C 代码转换为汇编代码也就是.s文件),c++对应的则是cc1plus,java是jc1,所以实际上,gcc就是这些后台程序的包装,会根据不同的参数要求去调用预处理编译程序cc1、汇编器as(将汇编代码(.s 文件)转换为机器码目标文件(.o 文件))、链接器ld(将多个目标文件(.o)和库文件(.a/.so)合并为单一可执行文件或共享库,解决跨文件的符号引用(如函数调用、全局变量访问))
简单来说编译器就是将高级语言翻译为机器语言的工具,因为机器语言比较低级,写起来会很麻烦,效率极低而且编写出的程序还需要依赖特定机器,在不同的cpu下就无法运行了,而高级语言可以尽量少考虑机器本身限制,像字长、内存大小、存储方式等
回到编译器本身,编译过程可分为6步:扫描、词法分析、语义分析、源代码优化、代码生成、目标代码优化,下面用到的这个例子是书上提供的
array[index] = (index + 4) * (2 + 6)
CompilerExpression.c
下面简单描述一下源代码到最终目标代码的过程
词法分析
源代码被输入到扫描器后会进行简单的词法分析,运用一种类似于有限状态机(fsm)的算法将源代码字符序列分割成一系列记号(一般分为:关键字、字面量(数字、字符串等)、特殊符号(+、=)、标识符)
补充:
有限状态机(FSM)是什么?
定义
一种抽象计算模型,由有限的状态、输入符号、状态转移规则和初始/终止状态组成
根据当前状态和输入字符,决定下一个状态(可能伴随动作,如生成记号)
在词法分析中的作用
分割字符流:将连续的源代码字符(如 if (x > 0))分解为离散的记号(如 IF, LPAREN, ID(x), GT, NUM(0), RPAREN)。
消除冗余:跳过空格、注释等无关字符。
有限状态机的算法实现
这里是核心逻辑
初始化:从起始状态开始
状态转移:逐个读取字符,根据当前状态和输入字符跳转到下一状态
终止条件:遇到无法转移的字符时,回退并生成记号
记号(Token)是什么?
定义
词法分析的最小语义单元,通常表示为 <类型, 属性值> 对
类型:关键字、标识符、运算符等
属性值:具体内容(如变量名、常数值)
作用
为后续的语法分析(如解析成抽象语法树)提供结构化输入
上面那个例子包含28个非空字符,扫描后会产生16个记号,在这同时也会将表示符号放到符号表,将数字、字符串放到文字表等
这里提到了一个叫做lex的程序,可以实现词法扫描,会按照用户之前描述的词法规则将输入的字符串股分割为一个个记号,不用再为每个编译器开发一个独立的词法扫描器,只要改变词法规则就可以了
对于有预处理的语言比如c,它的宏替换和文件包含是交给一个独立的预处理器而不是编译器
语法分析
语法分析器将对由扫描器产生的记号进行语法分析,从而产生语法树,这个过程采用了上下文无关语法的分析手段,简单来说,由语法分析器生成的语法树就是以表达式为节点的树, C 语言的一个语句是一个表达式,而复杂的语句是很多表达式的组合,上面例子中的语句就是一个由赋值表达式、加法表达式、乘法表达式、数组表达式、括号表达式组成的复杂语句,经过语法分析器后会生成下面这个语法树
补充:
上下文无关文法(CFG)
定义
一种形式化语法,用于描述编程语言的语法结构,由一组产生式规则组成
每个规则的形式为:
非终结符 → 终结符/非终结符的组合
非终结符:可进一步展开的符号(如 表达式、语句)
终结符:词法分析生成的记号(如 ID, NUM, +)
关键特性
“上下文无关”的含义:
非终结符的展开不依赖其周围的上下文。例如:
S → aSb | ε
无论 S 出现在何处,都可以按此规则展开(生成字符串如 ab, aabb, aaabbb)
与正则文法的区别:
正则文法只能描述线性结构(如 a*),而 CFG 能描述嵌套结构(如括号匹配、if-else 嵌套)
在编译器中的应用
定义编程语言的语法规则(如 if 语句、函数声明)
生成语法分析器(如递归下降解析器、LR 解析器)
下推自动机(PDA)
定义
一种扩展的有限状态机(FSM),增加了栈结构,用于处理上下文无关文法
核心组件:
状态集:类似 FSM 的有限状态
输入符号:记号的序列
栈:存储符号(如非终结符),支持 push 和 pop 操作
转移规则:基于当前状态、输入符号和栈顶符号决定下一步动作
关键特性
栈的作用:
解决嵌套结构的匹配问题(如括号 (()()))
记录未完成的语法规则(如等待 else 的 if 语句)。
与 FSM 的区别:
FSM 无栈,只能处理正则语言;PDA 因栈的存在,能处理 CFG。
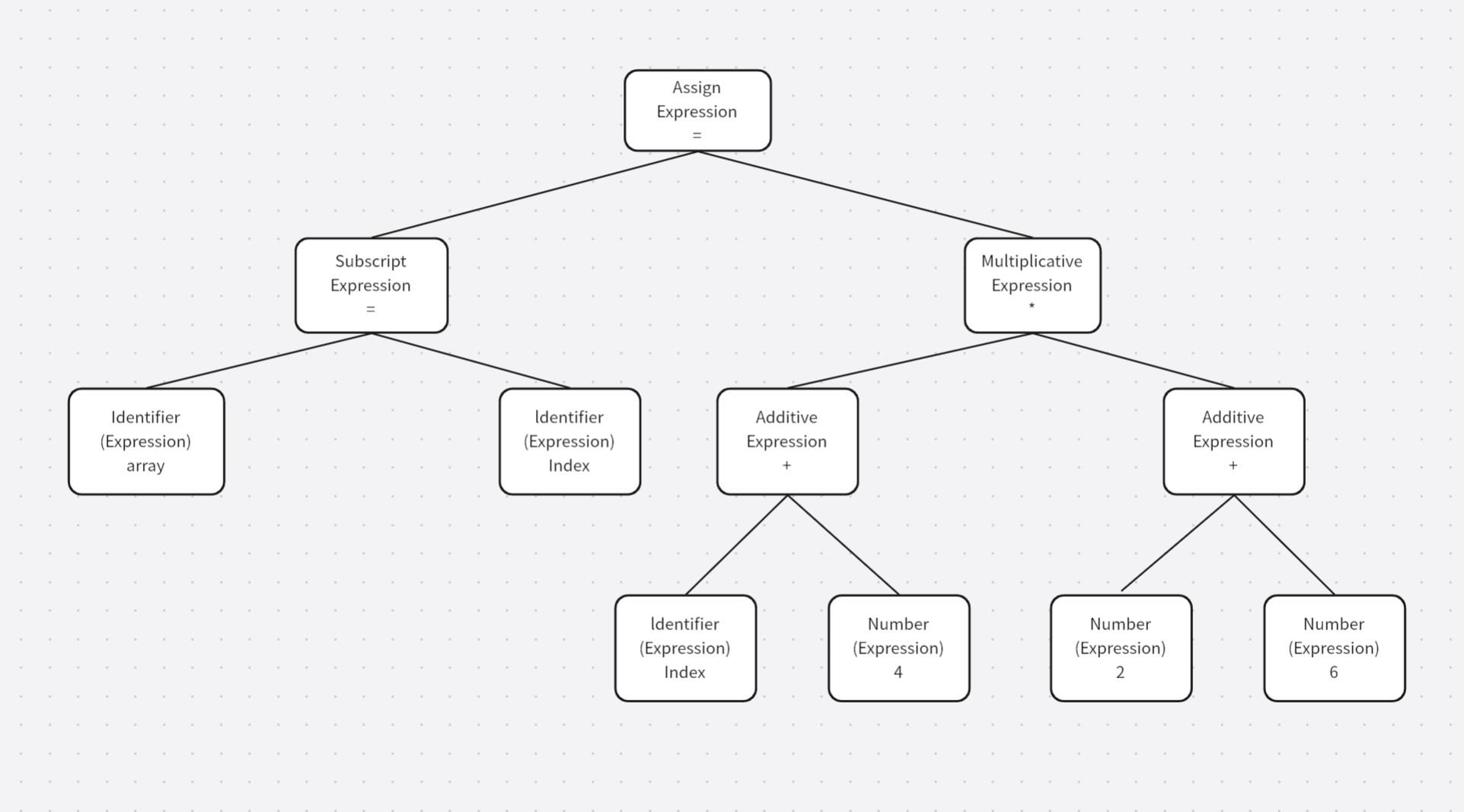
从图中可以看到,整个语句被看作是一个赋值表达式,而赋值表达式的左边是一个数组表达式,右边是一个乘法表达式,数组表达式又由两个符号表达式组成等,符号和数字是最小的表达式,不由其他的表达式组成,所以通常作为整个语法树的叶节点,在语法分析的同时,很多运算符号的优先级和含义也被确定,比如乘法表达式的优先级就会比加法高,而圆括号表达式的优先级又会比乘法高等,另外有些符号具有多重含义,比如星号*在C语言中可以表示是乘法表达式,也可以表示对指针取内容的表达式,所以语法分析阶段必须对其进行区分,如果出现了表达式不合法,就像括号不匹配、表达式中缺少操作符等,编译器就会报错
前面的词法分析有lex,语法分析也有一个工具叫做 yacc,和lex一样,可以根据用户给定的语法规则对输入的记号序列进行解析,从而构建语法树,不同的编程语言,编译器的开发者只须改变语法规则,而无须为每个编译器编写一个语法分析器,所以又被称为"编译器编译器“
汇编
汇编器是将汇编代码转变为机器可执行的指令,每一个汇编语句几乎都对应一条机器指令,不需要做指令优化,只是根据汇编指令和机器指令对照表一一翻译即可,可通过调用汇编器as完成
as 1.s -o 1.o
或
gcc -c 1.s -o 1.o
下面这个gcc需要经过上述预处理和编译过程从c源码变为现在所需机器码目标文件
gcc -c 1.c -o 1.o


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









