







linux中的文件存储
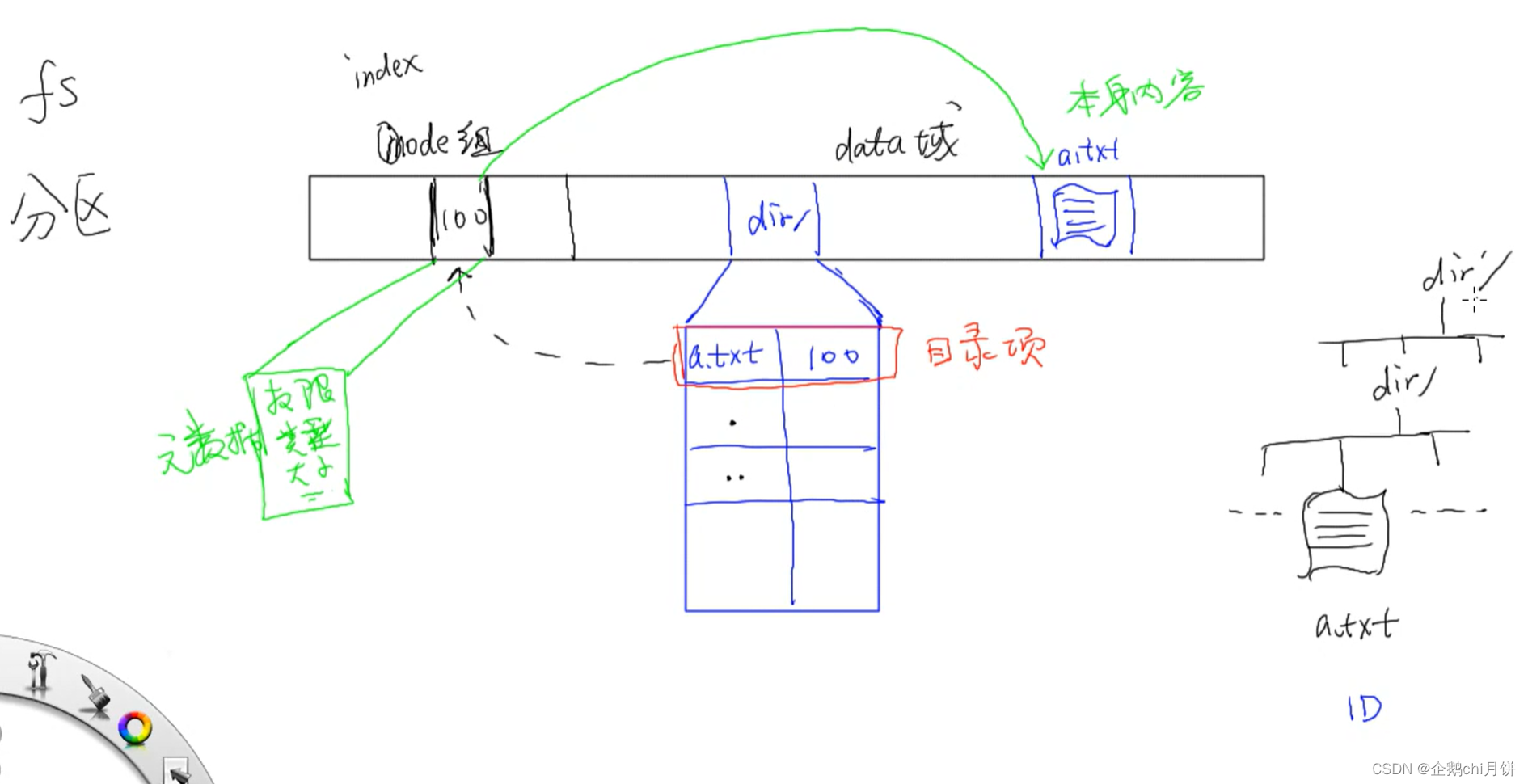
inode组和目录项中的inode号
dir是我们的一个目录,这个目录下面有许多目录项,每个目录项由两部分组成:文件名和对应的inode号。我们通过这个idnode号可以对应到我们的inode组。
看到inode Table(inode组), 其实可以很自然从Table的联想到它应该是一个数组.
但是inode究竟是什么呢?
在Linux系统中, 存在一个 inode结构体, 此结构体存储的是磁盘文件的各种属性,如文件大小、权限、所有者、所属组、创建时间、修改时间等。此外,还包含指向文件数据的指针,用于定位文件的实际数据存储位置。
我们的inode号是什么呢?
inode号是在inode组中项的下标或索引。在文件系统中,每个inode都有一个唯一的inode号,用于在inode组中定位该inode的具体位置。
现在我们已经知道了每个文件都会在其文件夹下有一个目录项,现在介绍两个特殊的目录项
在Linux和Unix系统中,每个目录下通常都包含两个特殊的目录项:
.和..。
. 代表当前目录。它是一个指向当前目录本身的符号链接。通过
.目录项:.可以引用当前目录中的文件和子目录。.. 代表父目录。它是一个指向当前目录的父目录的符号链接。通过
..目录项:..可以引用当前目录的父目录中的文件和子目录。这两个特殊的目录项对于文件系统的导航和路径解析非常重要。它们使得在文件系统中进行相对路径操作变得更加简单和直观。
因此,几乎所有的Linux和Unix系统都会在每个目录下包含
.和..这两个特殊的目录项。
数据域
数据域(Data Blocks):
- 数据域是存储文件实际数据的地方。它由一系列数据块(Data Blocks)组成,用于存储文件内容。
- 当文件较小时,所有数据都存储在inode中的直接指针中。但对于较大的文件,inode中的指针将指向数据块的位置,而数据块中存储着文件的实际内容。
- 文件系统会根据文件大小动态分配所需的数据块,并将文件内容存储在这些数据块中。
- 补充直接指针定义(Direct Pointers):
- 直接指针是inode结构中的一种指针,它直接指向文件的数据块。每个直接指针可以指向一个数据块,这个数据块中存储着文件的实际内容。
- 通常,文件系统会分配一定数量的直接指针来存储文件的初始数据块。这些直接指针能够快速地定位到文件的数据块,因此对于小型文件来说非常高效。
在典型的文件系统中,一个inode结构可能包含多个直接指针字段,每个直接指针字段可以指向一个数据块。如果文件大小超过了直接指针所能指向的数据块数量,那么就需要利用间接指针或双重间接指针来指向更多的数据块,以容纳文件的全部内容。
补充ls命令中的-i选项
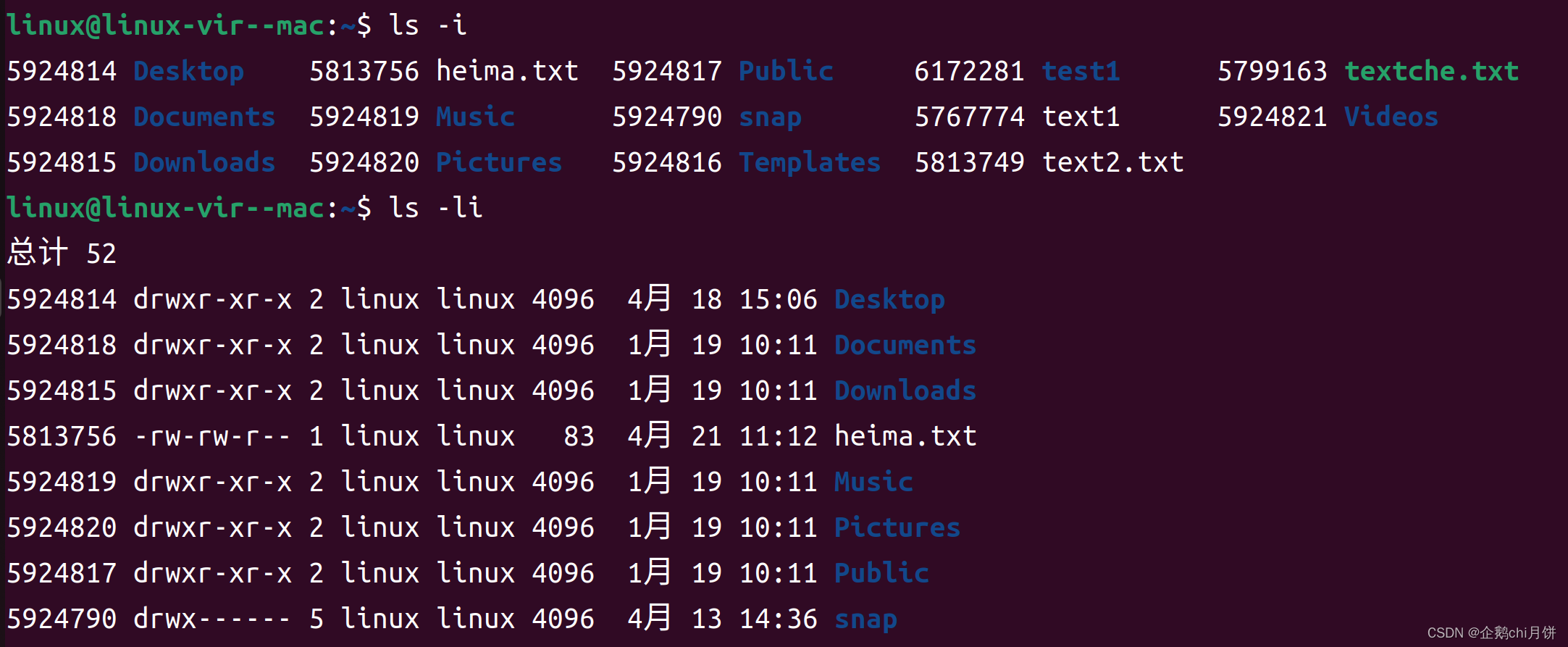
-i选项可以呈现文件的inode号,我们也叫它id号,当然也可以-li连用
rm命令之后会发生什么事情?
在我们使用rm a.txt之后并不会像下面这张图中描述的这样将这个文件从硬盘中抹除

在Linux中,当你删除一个文件时,实际上删除的是文件的目录项(directory entry),而不是文件的内容或inode。这意味着文件的数据块仍然存在于磁盘上,只是文件的目录项被删除了。
当你删除一个文件时,操作系统会首先查找该文件的目录项,然后将这个目录项从文件系统的目录结构中移除。这样,文件名就不再与对应的inode关联了,但文件的inode本身仍然存在,以及它所占用的数据块也没有被删除。
- Linux 中的
rm命令删除的文件通常无法直接恢复,除非提前进行了备份或者使用一些专门的工具,可能一会之后这个文件内容被覆盖了 - Windows 中删除的文件通常会被移动到回收站,可以在回收站中找回,或者通过一些恢复软件来尝试恢复。
rm命令-i选项的补充
先来看效果
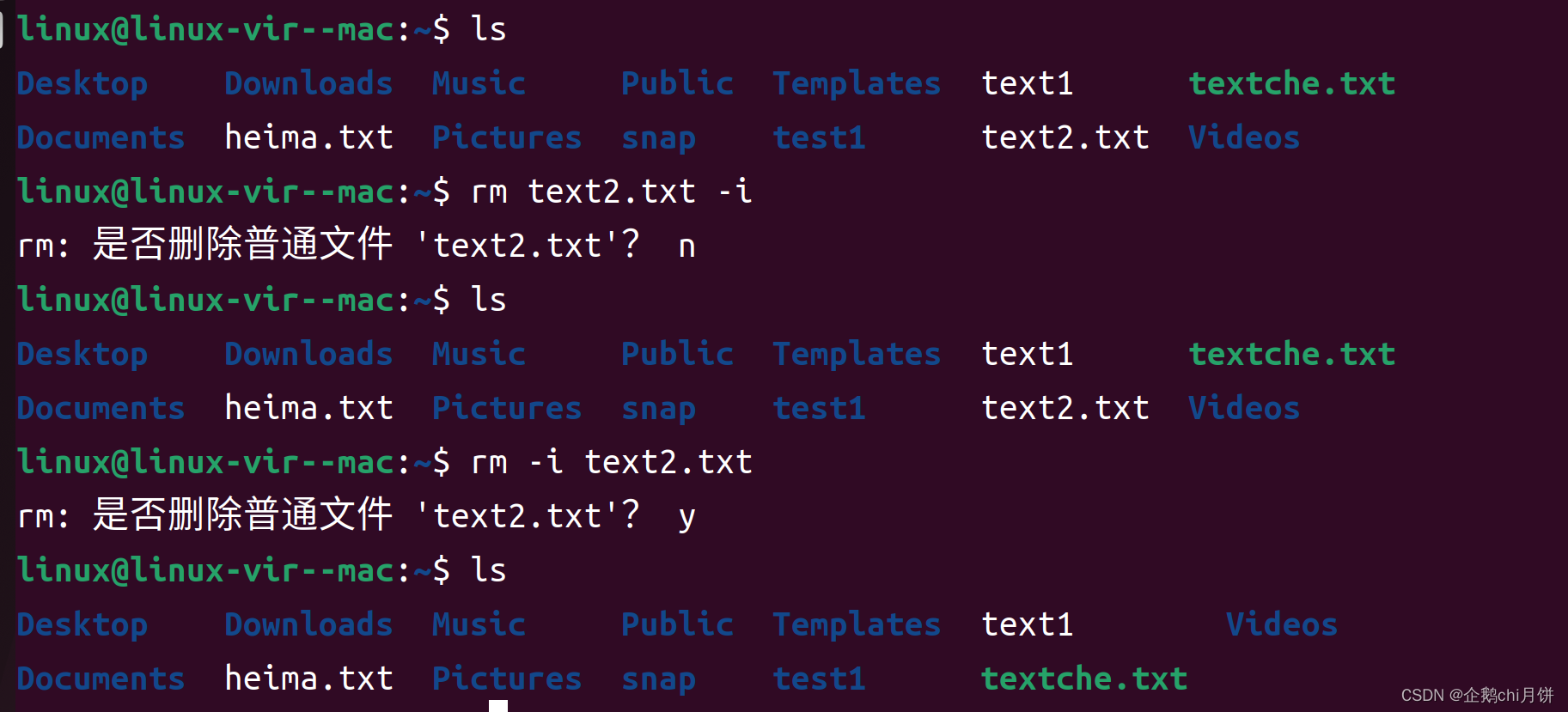
发现此时我们删除这个文件的时候系统将会来询问我们,这个操作确实看起来没什么用处,但是比较适合我们在写脚本语言中,如果在脚本语言中rm将会自动执行,可能会删错,所以在写脚本命令的时候加上-i选项更加保险。
这里我们还可以看见我把-i选项放在了text.txt后面也可以执行,之前ls命令我都是把选项放在了前面,其实linux中命令中选项的位置是比较灵活的。
在同一个分区下面为什么移动很大的文件也会很快?
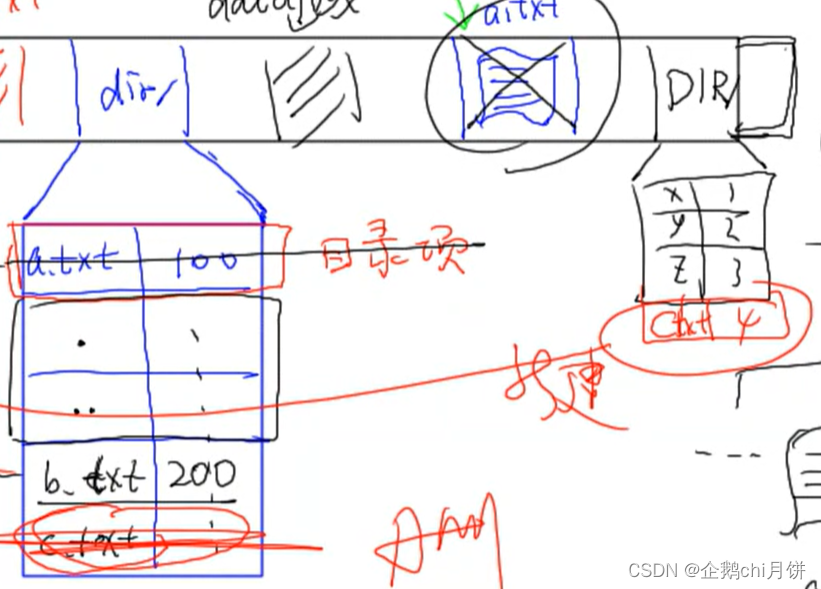
比如上面将dir目录下的c.txt移动到DIR目录下面,这两个目录是在同一个分区下面,这样的话当移动的时候只用移动一个目录项就可以了,这样很快,不涉及数据移动,但是对于两个目录在不同的分区就不是这样了。
- linux中目录实际上是一个包含文件名和对应inode号的列表。inode(Index Node)是文件系统中的数据结构,存储了文件的元数据(如权限、拥有者、时间戳等)以及指向数据块的指针。
- 当你删除或移动文件时,只需要更新相关目录项中的inode号和链接计数(如果有硬链接),而不需要实际移动文件数据,这样操作起来会更快。
综上所述:我们发现在linux中删除东西或者移动东西,要比window中快的多,因为linux中是目录,相当于一个指引的作用,真正的数据可能保存在别的地方,当我们变更数据的时候只需要改变一下目录项就可以实现,有点像改变了指针的指向。但是window就不一样了,window的文件夹起到一个容器的作用,当把一个文件夹中的东西复制到另一个文件夹中时,那么便需要真的涉及到数据的移动,就需要花费比较多的时间。由此看来确实linux中的关于数据移动这点要比window更加的合理高效。
linux中关于文件操作的命令深入了解

cat命令
- 释义:显示文本文件的内容
- 常见用法:
gec@ubuntu:~$ cat file.txt ==> 显示文本文件内容
gec@ubuntu:~$ cat -n a.c ==> 显示文本文件内容(并显示行号)
gec@ubuntu:~$ cat -A a.c ==> 显示文本文件内容(含不可见字符)
- 注意:
在某些情况下,我们可能需要检测文件中那些不可见的字符。比如在Windows系统中编辑了程序源文件,放到Ubuntu系统中编译可能会出现字符错误,这是因为Windows系统中的某些回车符、制表符跟Ubuntu系统的不一致,导致无法编译,而这些字符是不可见的,因此可以使用上述 cat -A 来识别。
head/tail命令
- 释义:查看指定文件的头部/尾部内容
- 常见用法:
- 加上-n表示显示几行内容
gec@ubuntu:~$ head file.txt
gec@ubuntu:~$ head -n file.txt
gec@ubuntu:~$ tail file.txt
gec@ubuntu:~$ tail -n file.txt比如查看日志文件中的最后几行
tail -n 10 text.txt
grep命令
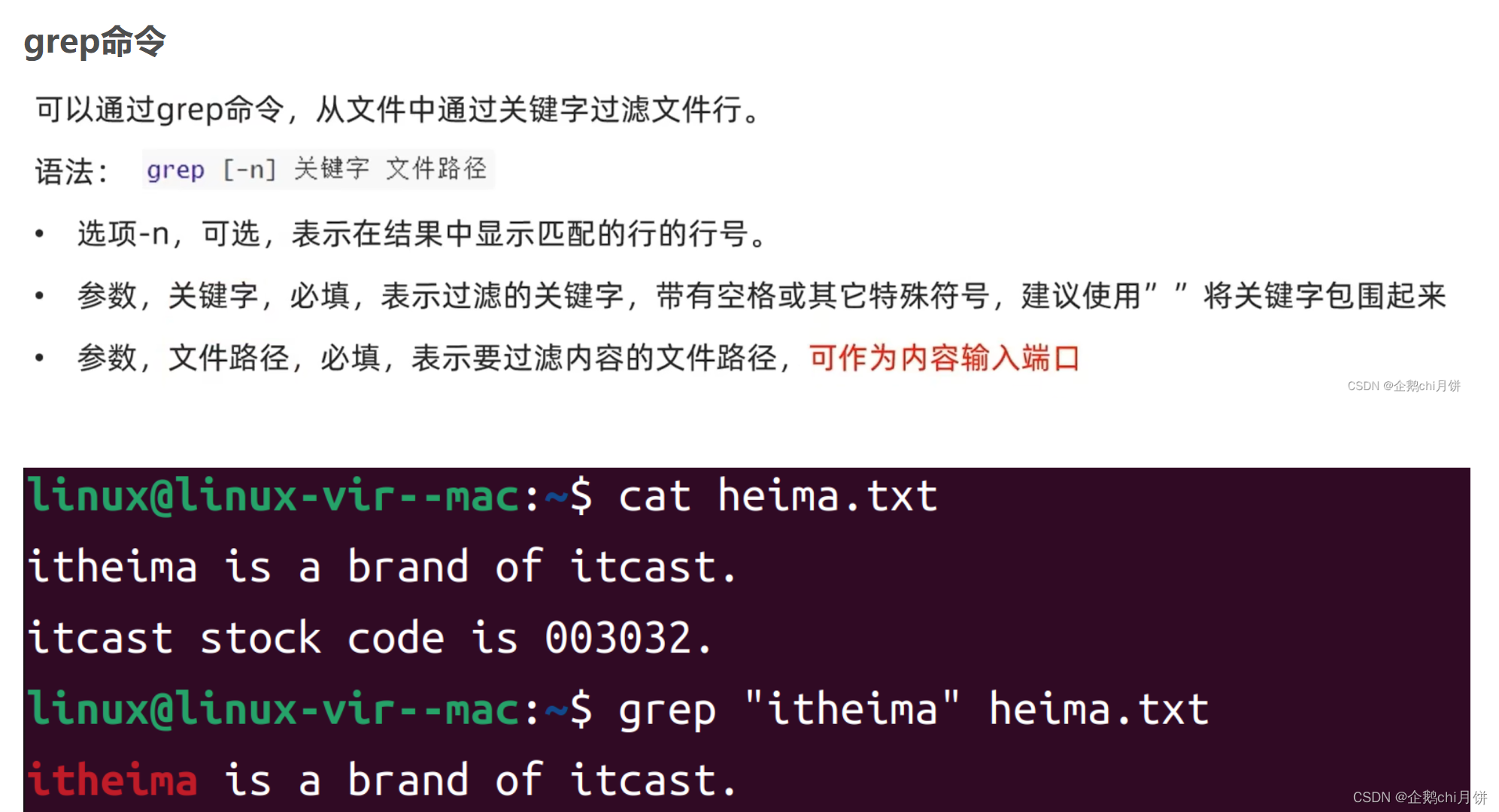
上面显示的是我在linux命令刚刚学习中提到的,当时仅仅介绍了grep后面跟随文件 ,还有可以与管道符配合使用,只要管道符左边是可以产生输出的就可以。往往我们其实是要在文件夹里面查找的,怎么办呢?
其实可以在这个命令中加入-r选项就可以了,是不是很熟悉,在rm命令和cp命令中要对文件夹操作也是加了-r命令

-H选项的作用是用于强制输出匹配行所属的文件名
-n选项是输出关键字所在行
压缩与解压命令
Linux下最常用的压缩包格式是:
- gz
- bz2
- zip
- xz
其中,gz和bz2格式一般都是通过tar命令来控制的,xz和zip格式各自由它们的同名命令控制。
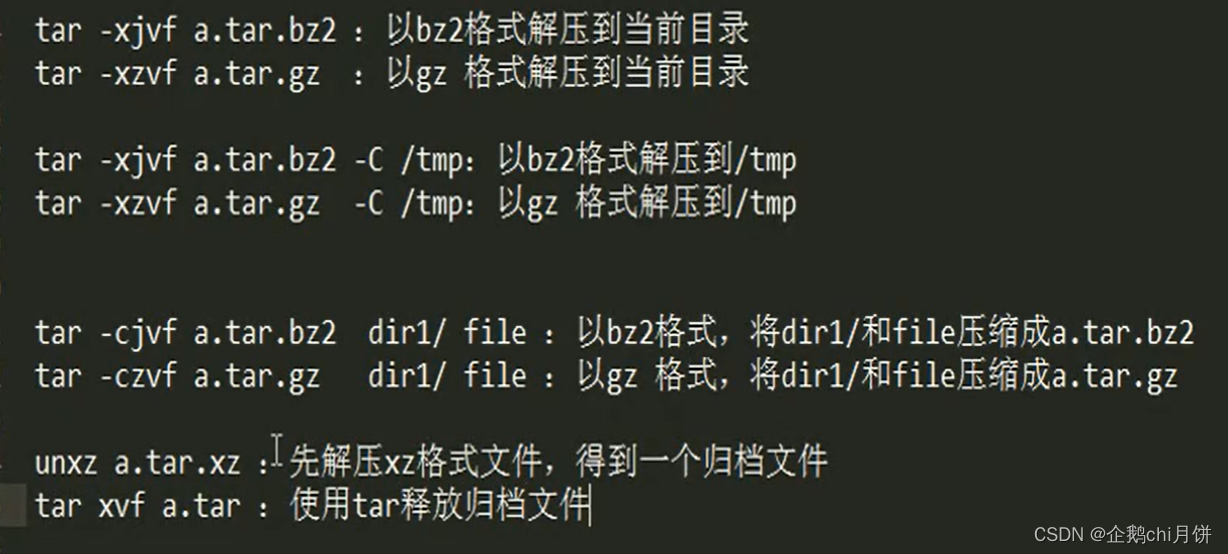
个人认为还是将-z选项 -j选项放到最前面比较直观,清楚。
rmdir命令
作用:删除空的文件夹
Linux中rmdir作用是删除空目录,但是我们rm不是加上-r选项可以递归删除目录吗,为什么还要rmdir命令?
这个命令其实方便我们写脚本语言时删除空的文件夹,使用rm命令删除空的文件夹我们还需要判断是否为空,使用rmdir命令就更简单。
cd命令补充
cd - 是一个命令,用于切换到前一个工作目录。在Linux和Unix系统中,-(连字符)通常表示上一个工作目录。当你执行 cd - 命令时,系统会将当前工作目录切换为上一个工作目录。
这个命令在需要频繁在两个目录之间切换时非常有用,因为它可以快速返回到之前所在的目录。
alias命令
在Linux或Unix系统中,alias 命令用于创建别名,也就是用一个简短的名称来替代长命令或一系列命令。通过为命令或命令序列定义别名,可以提高工作效率,并简化常用命令的输入。
创建别名:alias ll='ls -l'
//这将把 ll 定义为 ls -l 的别名,以后可以直接使用 ll 来执行ls -l的功能。
删除别名:unalias ll
显示所有别名:alias
永久保存别名:
你可以将别名定义添加到你的shell配置文件中,如 ~/.bashrc文件中,这个文件默认被隐藏,使用ls -a能看到,别名的使用可以使命令行操作更加高效和便捷,但需要注意,别名只在当前shell会话中生效,如果想要在所有的shell会话中生效,需要将别名定义添加到相应的配置文件中。
man命令
可以用来查看命令如何使用的同时也能查看函数的用法。
比如man ls
man strcpt
当然这样仅仅man后面跟着查询的东西,可能会出现找不到想用的东西,比如,这里使用-f选项查看man中的read发现有多个,这样比如说我们想查找的是read库函数,就加上3posix,这里不做过多详细阐述

![]()
补充Linux中的过滤命令

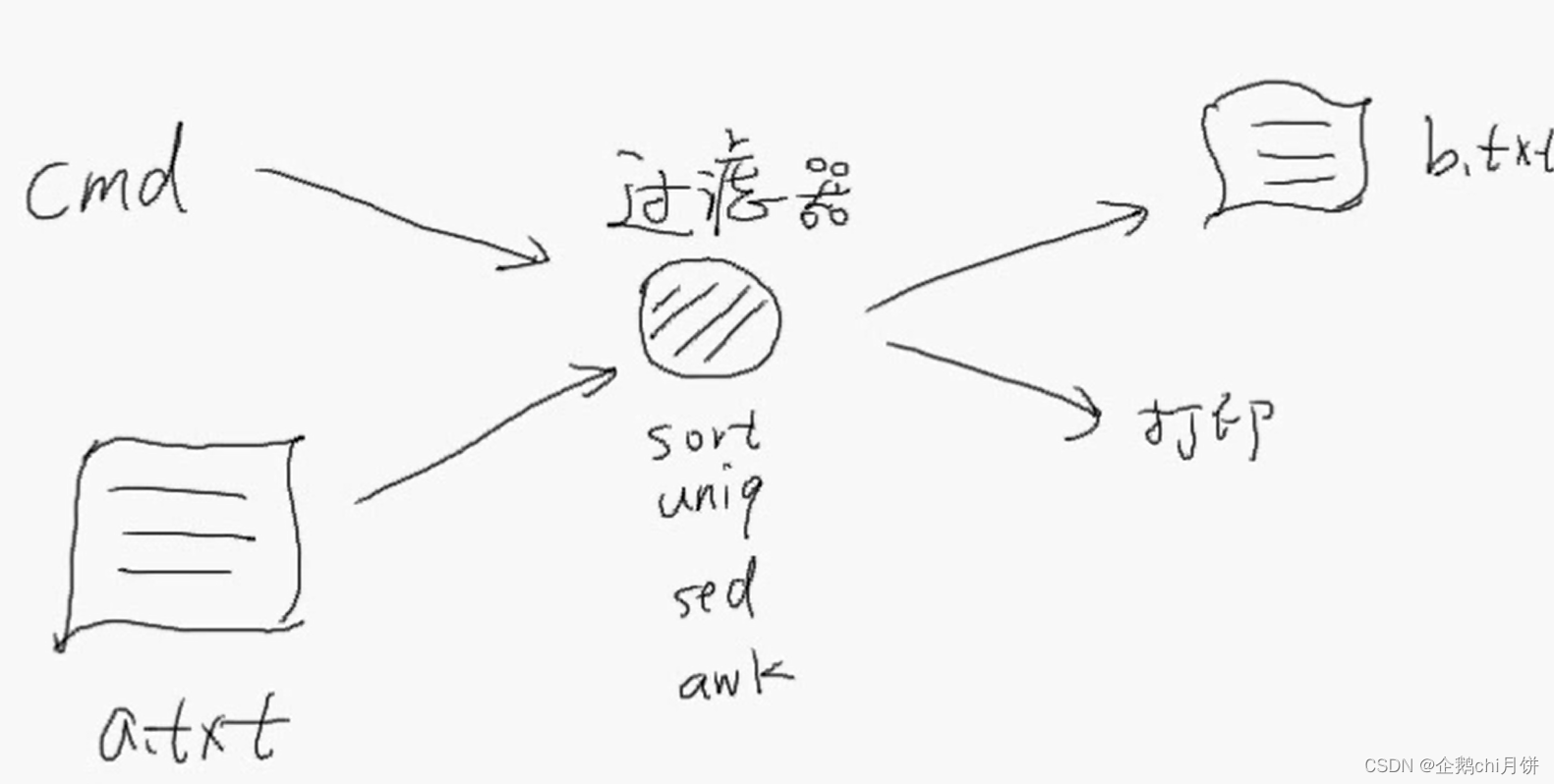
这些命令中上面两个比较简单,下面两个命令支持正则表达式。
这些命令输入可以是文件,也可以是命令产生的结果(比如我们ls命令也能产生输出结果),输出的话可以将过滤的结果直接打印出来,也可以将过滤的结果来写到别的文件中。
这些过滤命令是先将文件的内容读出来,然后进行过滤,我们可以将过滤的结果打印出来,不会对源文件产生影响和改变。
sort命令与uniq命令
排序

默认排序是按照首字母的顺序来排序的,加上-r选项可以让反过来排序
去除相邻重复行
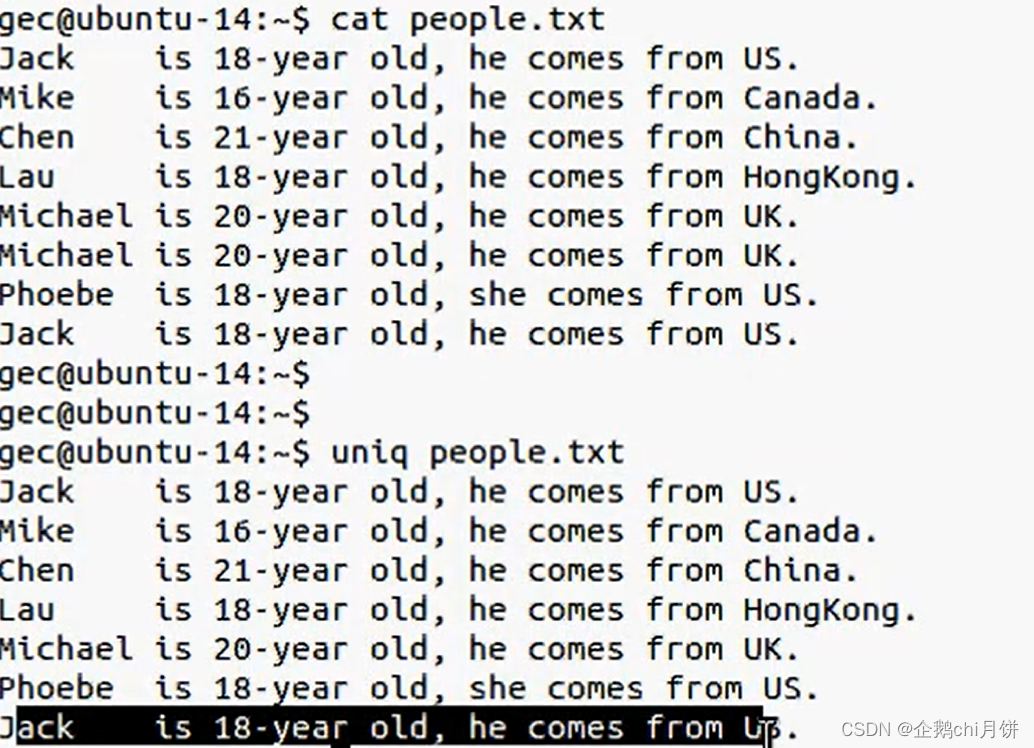
可以发现Mich这一行被去重了,但是最后的jack还在,因为uniq仅可以去重相邻行
组合技巧
现在我就要来想要实现将这个最后一行的jack也删掉,那怎么办呢?
我们要注意:Linux中提供给我们的命令就是一个个精巧的积木,我们可以将这些积木组合起来实现更加强大的功能。
sort people.txt | uniq //先排序将重复行放到一起,这样就能实现去重不相邻行
那我们如何来想要将过滤完的文件写回people.txt中呢?
sort people.txt | uniq > people.txt
这个命令是达不到过滤完写回的功能的
在这个命令中,
sort people.txt | uniq > people.txt会首先清空或创建一个空的people.txt文件,然后再将排序和去重后的结果写入其中。这样就导致了原始文件的内容被覆盖丢失的情况。这里重定向操作会优先执行,并不是按照我们的想法从左到右以此执行
我们可以这样来做
可以将输出重定向到一个新创建的空文件中,这样就算重定向优先清空也无所谓,然后再将其内容再移动回来
sort people.txt | uniq > sorted_people.txt
mv sorted_people.txt people.txt这里注意我们可以不需要提前创建好
sorted_people.txt这个文件,因为重定向符后面的文件如果不存在的话,系统将会先自动帮我们创建好,再执行相应的操作,这样的话将会便利我们这里的操作。
awk命令
awk命令特别擅长处理这种按列书写的数据
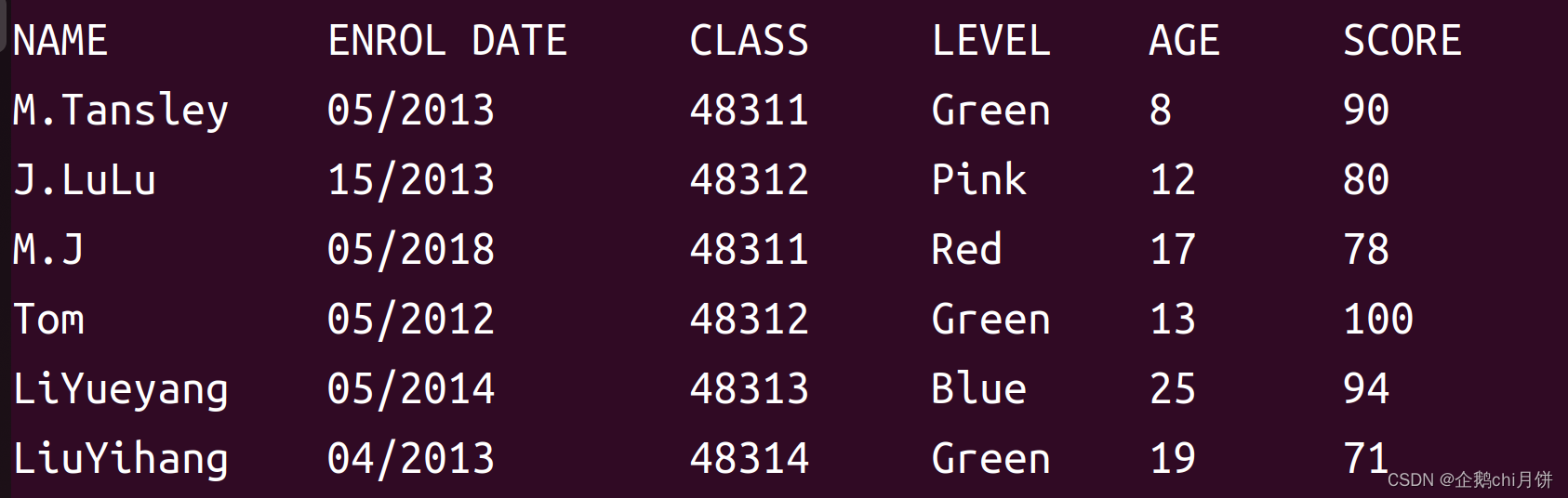
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
awk命令格式:
awk [选项参数] 'pattern1{action1} pattern2{action2}...' filename
pattern:表示AWK在数据中查找的内容,就是匹配模式,也可以认为是匹配条件。action:在找到匹配内容时所执行的一系列命令,可以认为是我们执行的动作。
这里有点相当于:if (pattern){
action
}
示例
示例1:
linux@linux-vir--mac:~$ awk 'NR>1 {print $3}' grade.txt
这里的NR>1是条件 , print $3是我们的操作 , grade.txt是我们要处理的文件
NR是行的编号,linux这里行编号从1开始,这里意思是处理的是从第二行到最后,先筛出了第一行即跳过文件中的第一行,然后处理第二行,依次逐行处理下去
print $3表示打印第三列,同样这里Linux的列编号也是从1开始,这里表示打印出第三列
示例2:
这里筛选的是两个条件,并且以&&连接,输出的是$0意思是将整行的是数据都输出出来

示例3:
awk命令选项的使用介绍
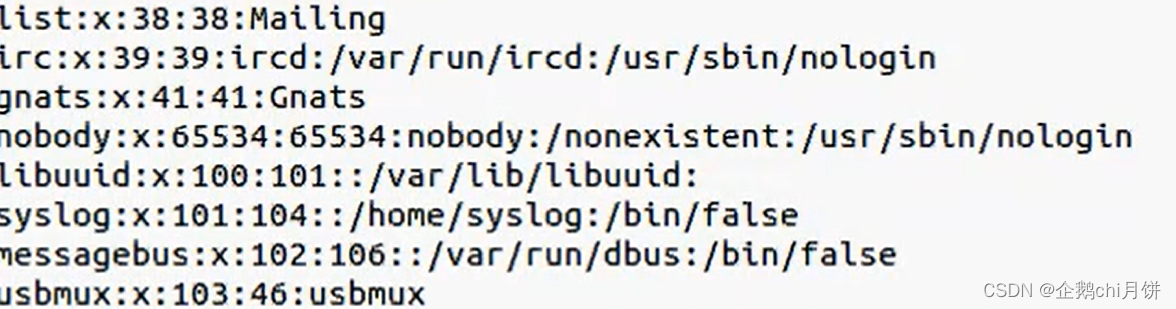
-F
看下面图片中 ,“:”就代表着这个表格项与项之间的分割符号
当我们使用 awk ‘{print $1}’ /etc/password 来输出第一列的时候的,发现并不成功,顺便说一下,这里我并没有写筛选条件,只写了执行的动作,这也是可以的。
上面情况的原因是,系统默认只承认空格和制表符才为分割符,不认为:是分隔符,所以有这里问题
解决方法 : awk -F: ‘{print $1}’ /etc/password
表示指定了:为我们的分隔符。
指定多个分隔符:-F'[:#/]' 定义三个分隔符//指定了:,#,/作为分隔符
示例4:
字符串的匹配既可以用==来匹配,也可以像这里一样使用正则表达式来匹配,~表示匹配,!~表示取反匹配,正则表达式的相关使用我之后会更新一篇文章来介绍。
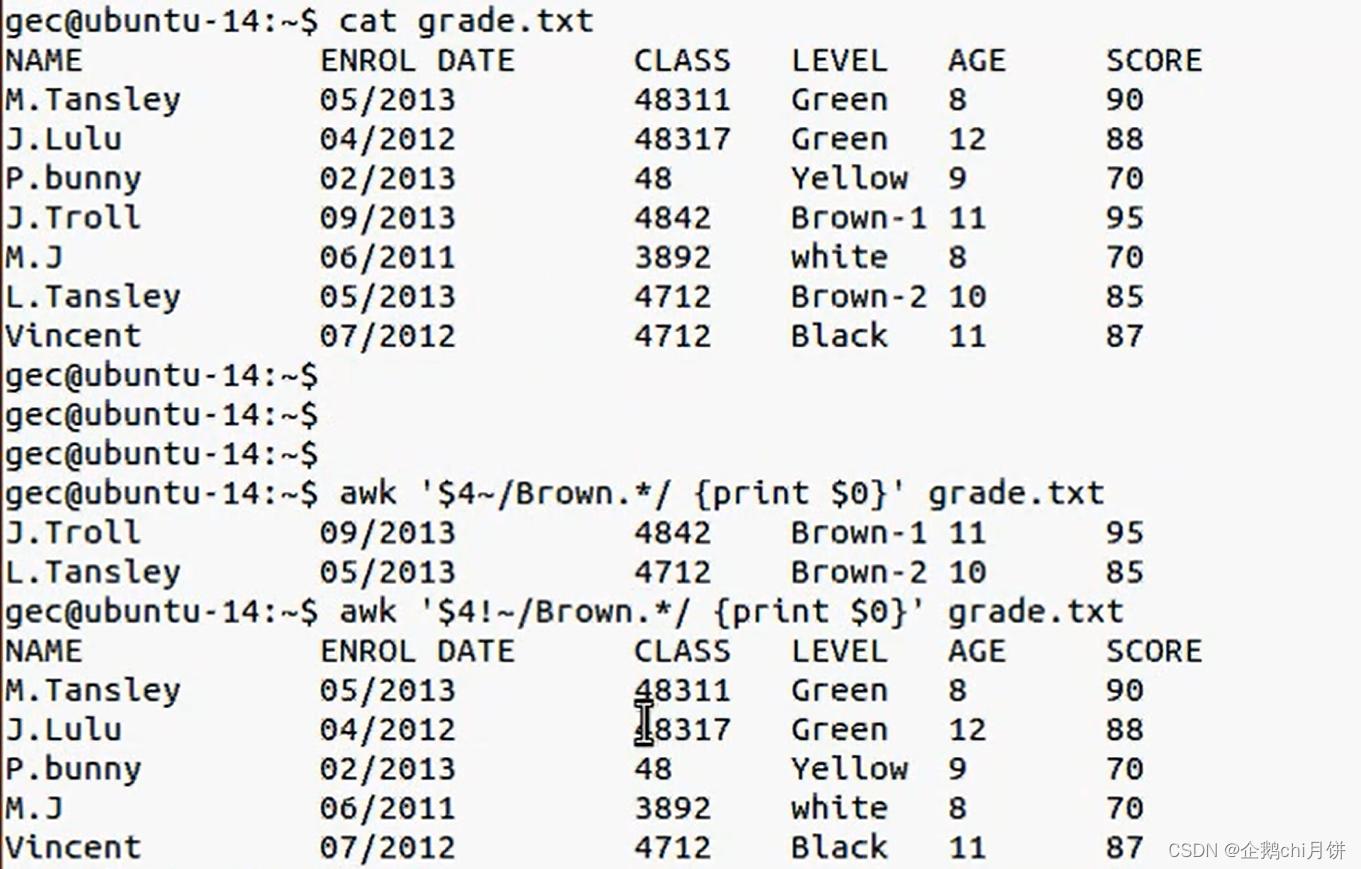
示例5:
我们会发现这个命令的结果有点不一样,让我们来进行下面的操作来看一下。
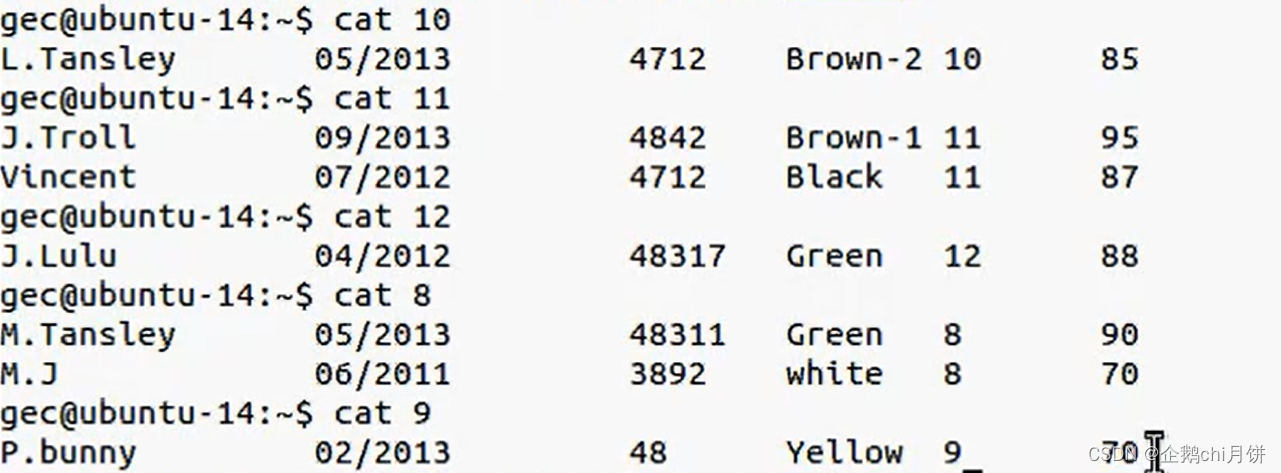
ok,我们发现多了名字为10,11,12,8,9这几个文件
并且里面对应存放的是上面文件中不同年龄对应的数据
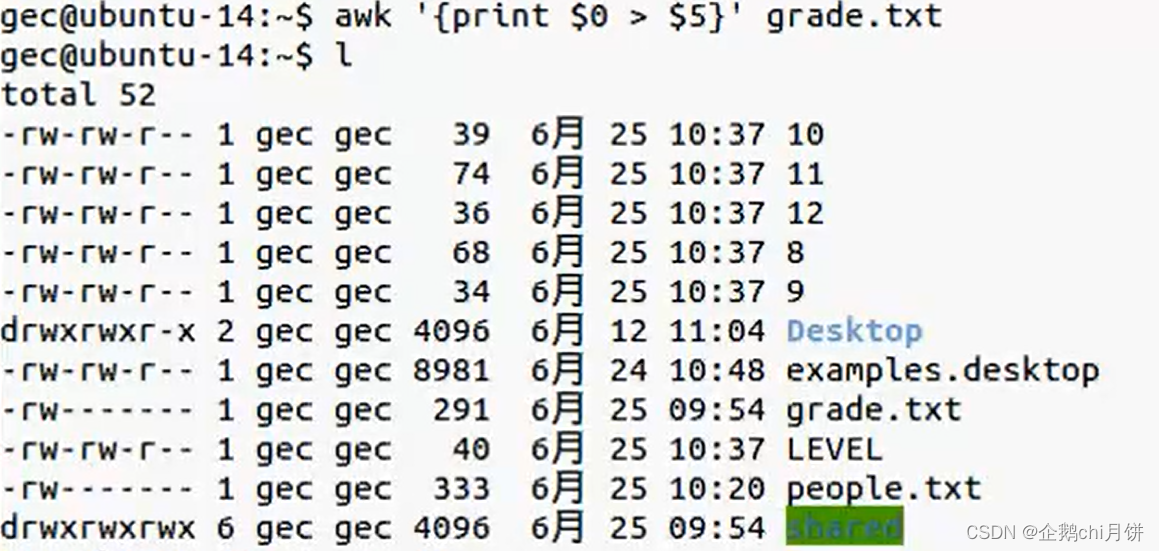
awk '{print$0 > $5}' grade.txt
这个命令是将文件中的每一行内容写入文件名为第五列所表示的文件中。换句话说,它会将每一行都写入一个以第五列内容命名的文件中。但是注意:这个命令可能会导致意外的结果,因为
$5可能包含特殊字符或不合法的文件名字符,导致文件写入失败或文件名不符合预期。在使用
awk的输出重定向时,如果指定的文件不存在,awk会自动创建该文件。因此,如果在awk命令中指定的文件不存在,awk会尝试创建这个文件并将内容写入其中。这里的话就会自动创建名字为10,11,12,8,9这几个文件
awk命令中关键字
比如我们刚刚使用的$0,NR,$1这些东西,这些东西是要pattern和action中会用到
下面我们将介绍更多
$0 表示整个当前行
$1 每行第一个字段(即第一列)
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
详细更多用法可以参考:linux awk命令详解-CSDN博客
sed命令
sed 是一个用于文本处理的流编辑器,也是逐行处理,sed 命令在缓冲区中一次处理一行内容,处理完成后,把缓冲区的内容送往屏幕,接着处理下一行,直到文件末尾。它在 Linux 中非常常见且功能强大。它可以对文本文件进行流式编辑,支持搜索、替换、删除、插入等操作。
sed命令和awk命令一样不会对源文件进行操作,处理文件时,把当前处理的行存储在临时缓冲区(称为“模式空间”(Pattern Space))中,即它是基于模式匹配过滤及修改文本。这一点和vim编辑器不一样,vim是一个交互的编辑器,会直接对文件本身进行修改操作。
那么sed命令和awk命令有什么区别呢?
sed以流的方式处理输入数据,适合按行处理大型文本文件或管道中的数据流,而awk则更加注重按列处理数据,并且支持更复杂的数据操作和处理。应用场景: 对于简单的文本替换、删除、插入等操作,可以使用
sed,而对于需要进行数据提取、格式化输出、统计分析等复杂任务,则更适合使用awk。
语法格式
sed [选项] [操作] 输入文件 //这里的操作由' '来括起来(这里用" "括起来也可以),操作是由
sed匹配范围+sed内置命令字符(动作)组成的
(对于sed匹配范围,命令应用到整个文件时就不需要写)
选项
常常使用的是前三个

-n:我们过滤之后会将不是默认地输出每一行的处理结果,拿替换来说,不加-n不管这一行内容有没有经过替换操作,都会将这一行结果输出出来,所以最终输出结果和原来内容的行数肯定是一样的,加上-n后,只有发生了替换的行才会输出,最终输出结果和原来内容的行数不一定相同。
-i:刚刚我们说过了sed命令并不会对源文件进行修改,加上-i,便可达到让修改后的内容写回到修改前文件,间接相当于是我们对源文件进行了修改。
-e:可以由多个-e指定多个动作,比如
-r:启用扩展的正则表达式,若与其他选项一起使用,应作为首个选项

sed内置命令字符
这些命令字符可用于执行各种文本处理任务,例如过滤行、搜索、替换、文本插入、删除等。


写sed命令的步骤:
1. 确定匹配范围
2. 确定匹配范围+内置命令字符(即确定要实现插入/删除/打印/替换)匹配范围在前动作在后
3. 确定是否需要命令中添加选项。
示例

示例1:打印指定行或行范围:
sed -n '5 p' input.txt // 打印文件中的第5行
sed -n '2,5 p' input.txt //打印文件中的第2到第5行
示例2:删除指定行:
//删除文件中匹配模式的行(如包含 "pattern" 的行)
sed '/pattern/ d' input.txt可以看到在" "中,也是匹配加动作
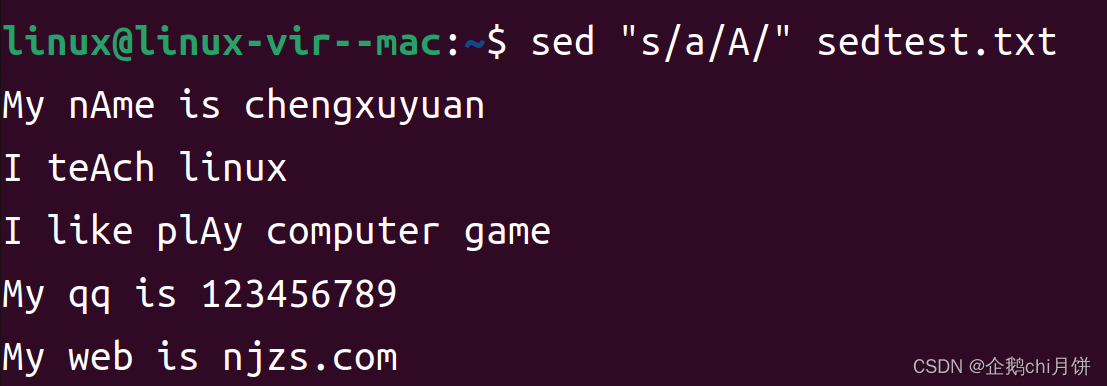
示例3:替换文本中的字符串:
# 替换文件中所有的 "old" 为 "new",并将结果输出到标准输出
sed 's/old/new/g' input.txt1. 带匹配范围的替换
2. g的作用是作用于全局
可以看到这里如果不加g的话对于匹配成功的每一行,只会将这行的第一个a改为A,第二个改不了,如果像将匹配成功的每行中的所有a都替换成A,那么就加上g

示例4:插入和追加文本:
// 在匹配行后面插入新文本
sed '/pattern/a This is a new line inserted after the matched pattern.' input.txt
// 在匹配行前面插入新文本
sed '/pattern/i This is a new line inserted before the matched pattern.' input.txt“”中是匹配+动作,后面还跟着要插入的内容
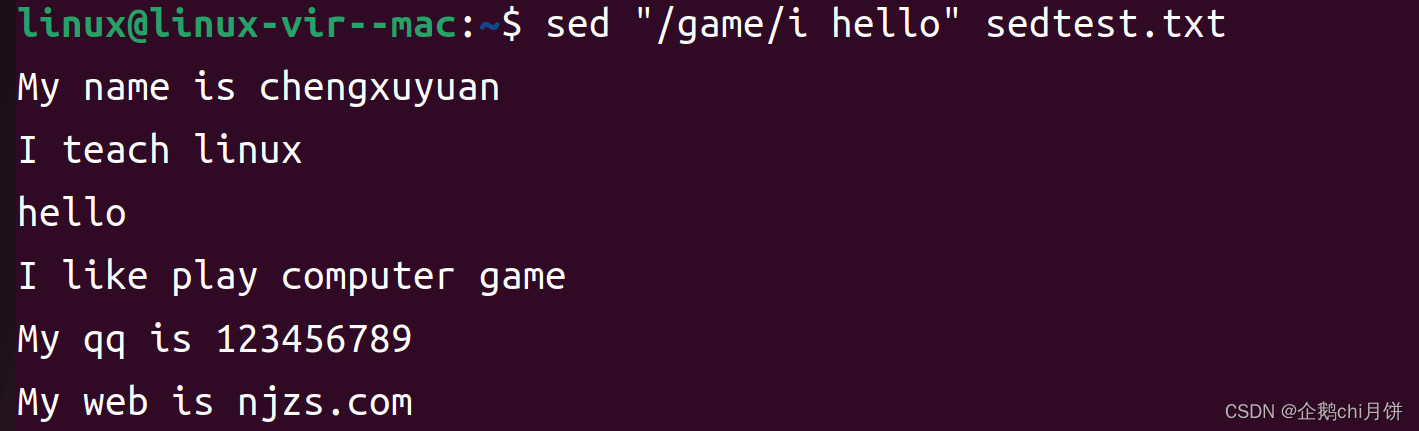
示例5 :使用多个编辑命令:
// 同时执行多个编辑命令
sed -e 's/old/new/g' -e '/pattern/d' input.txt
示例6 :使用多个编辑命令的另外一种方法
这里使用了;来分隔两个操作
第一个操作是全局替换l
第二个操作是替换1-4行的i
假如这里第一个操作不变,第二个操作变为将所有语句末尾的.去掉,我们此时会发现一个神奇的现象
我们的内容竟然都消失了,why?其实是因为
在这里的正则表达式中,一个.表示一个任意的字符,所以说这里和所有的字符都匹配上了,再加上我们加上了g表示全局,所以所有内容消失,全换为空。那我们应给怎么办呢?
在正则表达式中,
.(点号)表示匹配除换行符\n之外的任意单个字符。然而,有时候我们需要匹配字面上的点号字符.而不是它的特殊意义。这时候就需要使用\.来转义点号,表示它字面上的意思,即匹配实际的点号字符。例如,在正则表达式中:
.将匹配任意单个字符(除了换行符)。\.将匹配真实的点号字符.。所以,如果你想查找包含实际点号
.的文本,你可以使用\.来确保只匹配点号本身,而不是任意字符的通配符。所以这里的这条命令我们应该写成
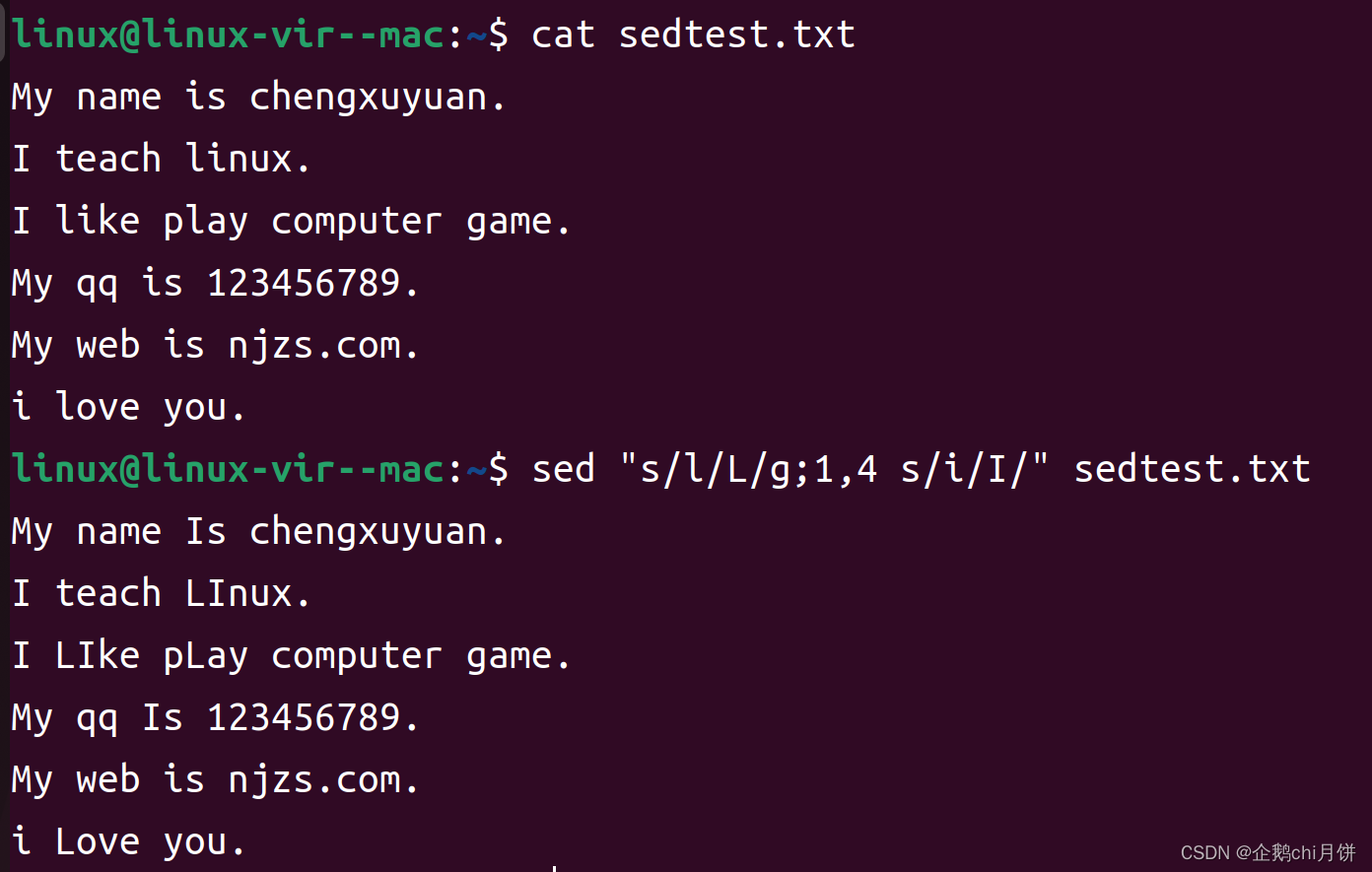
sed "s/l/L/g;1,4 s/\.//g" sedtest.txt
///
这里共4行,所以我这里写的是1,4,假如我不知道共有四行,我现在想要将第2行及之后的行数执行/\.//g那怎么办呢?
在
sed命令中,$表示最后一行。所以我们可以
sed "s/l/L/g;2,$ s/\.//g" sedtest.txt


注意一点空格小细节
我觉得该空格的时候最好空格
sed -n '5 p' input.txt // 打印文件中的第5行
比如说这里,虽然5p之间可以不空格,但是空格之后一方面体现出来我们上面说的匹配范围+动作,这是两个东西,再一方面可以避免一些隐藏的错误就比如下面:
对于这行命令:sed "s/l/L/g;2,$ s/\.//g" sedtest.txt
这里如果$和后面部分不空格,就会发生错误,所以为了增加命令的可读性和清晰度,同时可以避免潜在的错误,建议合理使用空格
一个复杂的sed例子
p、i、a、d 是对行进行处理的基本命令,用于打印、插入、追加和删除行;而 s/old/new/g 则是对行内文本进行查找和替换的高级命令。
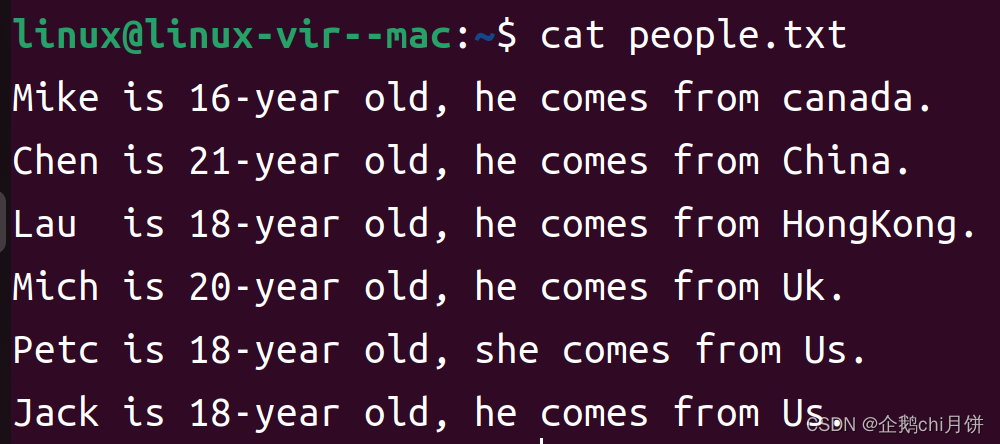
图片中内容来自于people.txt文件,我们如何用sed命令来将这里的人名和国家对应取出来输出?

首先我们要了解一些正则表达式中的知识
在正则表达式中,
.*是一个常见的模式,它由两部分组成:
.表示匹配任意单个字符,除了换行符\n之外。*表示匹配前面的元素零次或多次。因此,
.*连在一起就表示匹配任意长度的任意字符序列(包括空字符串)。换句话说,它可以匹配文本中的任何部分,直到下一个模式或者行结束符为止(默认情况下,.*是贪婪匹配,会尽可能多地匹配字符)。例如:
.*可以匹配空字符串、单个字符、一整行的文本,或者文本中的任何部分。a.*b可以匹配以a开头、以b结尾的任何长度的字符串,中间部分可以是任意字符。在我们的问题中便可以使用正则表达式:.*is.*from.*来匹配我们的语句
在正则表达式中,使用
()是用来创建一个捕获组(capturing group),它有以下作用:
分组操作:
()可以将多个表达式组合为一个单元,这些表达式可以是单个字符、字符类、量词、或者更复杂的子表达式。捕获:捕获组允许你从匹配的文本中提取部分内容,后续可以通过
\1、\2等来引用这些捕获组中的内容。\1表示正则表达式中第一个捕获的内容,即第一个用()括起来的。在大多数正则表达式引擎中,如果你想使用
()来表示一个捕获组,通常需要使用反斜杠\进行转义,如\(和\)。这是因为括号()在正则表达式中本身有特殊的含义,所以为了表示普通的括号字符,必须使用反斜杠进行转义。例如,如果你要匹配一个由括号包围的单词,可以使用
\(和\)来确保正确的匹配和捕获。总结来说,如果你想在正则表达式中使用
()来创建捕获组,确保要加上反斜杠\进行转义,以便正则表达式引擎能够正确理解你的意图。
\(表示圆括号的开始,标志着一个捕获组的开始。\)表示圆括号的结束,标志着一个捕获组的结束。这里我们想要保留的是人名和城市,所以这样写:"s/\(.*\)is.*from\(.*\)/\1\2/g"
最终我们这里的命令应该写成:sed "s/\(.*\)is.*from\(.*\)/\1\2/g" people.txt
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









