






给出哈希之闭散列的定义:
#define HashMaxSize 1000
typedef enum Stat
{
Empty,
Valid,
Invalid //当前元素被删除了
}Stat;
typedef int KeyType;
typedef int ValType;
typedef size_t(*HashFunc)(KeyType key);
typedef struct HashElem
{
KeyType key;
ValType value;
Stat stat; // 引入一个 stat 标记来作为是否有效的标记
}HashElem;
typedef struct HashTable
{
HashElem data[HashMaxSize];
size_t size;
HashFunc hash_func;
}HashTable;将函数的声明放在head.h的头文件里面:
// 现在使用闭散列的方式实现hash表(通用的hash表)
//
// 下面的问题是我们要解决的问题之一
// 统计一个数组中每一个元素出现的个数
// 这个时候就可以用 value 来表示次数了
// 给定一个数组 {1,1,1,2,2,3}
// 遍历数组
// 1)先将hash表中查找(得到了当前元素的次数)
// 2)如果元素在hash表中存在,将这个次数(value)+ 1
// 3) 如果元素在hash表中不存在,插入一个新的元素,初始value为1
#pragma once
#include <stddef.h>
#include <windows.h>
#include <stdio.h>
#define HashMaxSize 1000
typedef enum Stat
{
Empty,
Valid,
Invalid //当前元素被删除了
}Stat;
typedef int KeyType;
typedef int ValType;
typedef size_t(*HashFunc)(KeyType key);
typedef struct HashElem
{
KeyType key;
ValType value;
Stat stat; // 引入一个 stat 标记来作为是否有效的标记
}HashElem;
typedef struct HashTable
{
HashElem data[HashMaxSize];
size_t size;
HashFunc hash_func;
}HashTable;
/
// 哈希函数
size_t HashFuncDefault(KeyType key);
// 初始化
void HashInit(HashTable* ht, HashFunc hash_func);
// 插入
int HashInsert(HashTable* ht, KeyType key, ValType value);
// 输入key,查找对应key的value
int HashFind(HashTable* ht, KeyType key, ValType* value);
// 删除
void HashRemove(HashTable* ht, KeyType key);
// 判空
int HashEmpty(HashTable* ht);
// 大小
size_t HashSize(HashTable* ht);
// 销毁
void HashDestroy(HashTable* ht);
// 打印
void HashPrintInt(HashTable* ht, const char* msg);
函数的定义(具体实现):
#include "Hash.h"
// 默认的取哈希值的方式
// 比较简单,但是冲突的可能性也比较大
size_t HashFuncDefault(KeyType key)
{
return key % HashMaxSize;
}
void HashInit(HashTable* ht, HashFunc hash_func)
{
if (ht == NULL)
{
// 非法输入
return;
}
ht->hash_func = hash_func;
ht->size = 0;
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
ht->data[i].stat = Empty;
}
return;
}
void HashPrintInt(HashTable* ht, const char* msg)
{
printf("[%s]\n", msg);
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
if (ht->data[i].stat != Empty)
{
printf("[%lu] key = %d, value = %d stat = %d\n", i, ht->data[i].key, ht->data[i].value, ht->data[i].stat);
}
}
}
int HashInsert(HashTable* ht, KeyType key, ValType value)
{
if (ht == NULL)
{
// 非法输入
return 0;
}
if (ht->size >= HashMaxSize * 0.8) // 设定负载因子为 0.8
{
// 这里认为hash表已经满了,不能继续插入
return 0;
}
// 先找到 key 对应的下标
size_t offset = ht->hash_func(key);
while (1)
{
if (ht->data[offset].stat == Valid)
{
if (ht->data[offset].key == key)
{
// 发现在hash表中已经存在了相同的元素
// 策略1:认为插入失败
// 策略2:更新对应的value
// ht->data[offset].value = value;
return 0;
}
// 出现了hash冲突,使用线性探测的方式查找下一个元素
++offset;
if (offset >= HashMaxSize) // 判断越界和处理
{
offset -= HashMaxSize;
}
}
else
{
// 由于我们的负载因子是 80%,一定能找到一个空位
ht->data[offset].key = key;
ht->data[offset].value = value;
ht->data[offset].stat = Valid;
++ht->size;
return 1;
}
}
return 0;
}
int HashFind(HashTable* ht, KeyType key, ValType* value)
{
if (ht == NULL || value == NULL)
{
// 非法输入
return 0;
}
// 1. 通过hash函数计算数组下标
size_t offset = ht->hash_func(key);
// 2. 从这个数组下标开始,线性的向后查找
while (1)
{
// a) 如果找到了某个元素的 key 是想要的值,并且状态为 Valid,就认为找到了,就将 value 赋值给输出参数
if (ht->data[offset].key == key && ht->data[offset].stat == Valid)
{
// 找到了想要找的元素
*value = ht->data[offset].value;
return 1;
}
// b) 如果发现当前位置的状态是 Empty,就认为没有找到
else if (ht->data[offset].stat == Empty)
{
return 0;
}
// c)继续尝试查找下一个位置
else
{
offset++;
if (offset >= HashMaxSize) // 判断越界和处理
{
offset -= HashMaxSize;
}
}
}
return 0;
}
void HashRemove(HashTable* ht, KeyType key)
{
if (ht == NULL)
{
return;
}
// 1. 根据 key 找到对应的数组下标
size_t offset = ht->hash_func(key);
// 2. 从找到的下标开始依次遍历
while (1)
{
// 6种情况:
// 1. key 相同:
// a) 状态为 Valid
// b) 状态为 Empty
// c) 状态为 Invalid
// 2. key 不相同:
// a) 状态为 Valid
// b) 状态为 Empty
// c) 状态为 Invalid
// a) 如果当前元素的 key 为要删除的 key,并且状态为 Valid,就将状态置为 Invalid,并且要 -- size
if (ht->data[offset].key == key && ht->data[offset].stat == Valid)
{
// 找到了想要找的元素
ht->data[offset].stat = Invalid;
--ht->size;
return;
}
// b) 如果当前元素的状态为 Empty,要删除的 key 没有找到,不需要进行任何删除了
else if (ht->data[offset].stat == Empty)
{
return;
}
// c) 剩下的情况,就依次的取下一个元素就行了
else
{
offset++;
if (offset >= HashMaxSize) // 判断越界和处理
{
offset -= HashMaxSize;
}
}
}
return;
}
int HashEmpty(HashTable* ht)
{
if (ht == NULL)
{
return 1;
}
return ht->size == 0 ? 1 : 0;
}
size_t HashSize(HashTable* ht)
{
if (ht == NULL)
{
return 0;
}
return ht->size;
}
void HashDestroy(HashTable* ht) // 清理掉所有状态
{
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
ht->data[i].stat = Empty;
}
ht->size = 0;
ht->hash_func = NULL;
return;
}
测试代码:
#include "Hash.h"
void TestInit()
{
HashTable ht;
HashInit(&ht, HashFuncDefault);
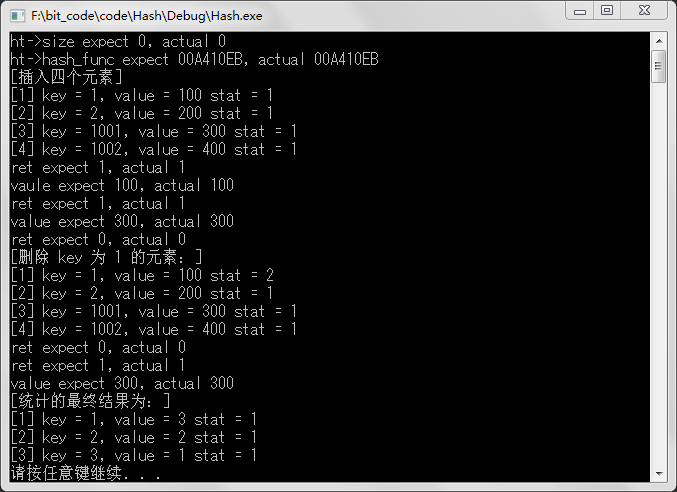
printf("ht->size expect 0, actual %lu\n", ht.size);
printf("ht->hash_func expect %p, actual %p\n", HashFuncDefault, ht.hash_func);
size_t i = 0;
for (; i < HashMaxSize; ++i)
{
if (ht.data[i].stat != Empty)
{
printf("pos [%lu] elem error!\n", i);
}
}
}
void TestInsert()
{
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashPrintInt(&ht, "插入四个元素");
}
void TestFind()
{
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
int value = 0;
int ret = HashFind(&ht, 1, &value);
printf("ret expect 1, actual %d\n", ret);
printf("vaule expect 100, actual %d\n", value);
ret = HashFind(&ht, 1001, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect 300, actual %d\n", value);
ret = HashFind(&ht, 1005, &value);
printf("ret expect 0, actual %d\n", ret);
}
void TestRemove()
{
HashTable ht;
HashInit(&ht, HashFuncDefault);
HashInsert(&ht, 1, 100);
HashInsert(&ht, 2, 200);
HashInsert(&ht, 1001, 300);
HashInsert(&ht, 1002, 400);
HashRemove(&ht, 1);
HashPrintInt(&ht, "删除 key 为 1 的元素:");
int value = 0;
int ret = HashFind(&ht, 1, &value);
printf("ret expect 0, actual %d\n", ret);
ret = HashFind(&ht, 1001, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect 300, actual %d\n", value);
}
// 哈希桶(统计元素个数)
void CountNum()
{
int array[] = { 1, 1, 1, 2, 2, 3 };
HashTable ht;
HashInit(&ht, HashFuncDefault);
size_t i = 0;
for (; i < sizeof(array) / sizeof(array[0]); ++i)
{
int value = 0;
int ret = HashFind(&ht, array[i], &value);
if (ret == 0)
{
// 没有找到
HashInsert(&ht, array[i], 1);
}
else
{
// 该元素已经存在
HashRemove(&ht, array[i]);
HashInsert(&ht, array[i], value + 1);
}
}
HashPrintInt(&ht, "统计的最终结果为:");
}
c++ 中的hash,做了这样的事情
重载了 [] 运算符
如果1已经存在,就取出对应的value
如果1已经不存在,插入一个默认的值
int value = ht[1];
ht[1] = value;
//#include <unordered_map>
//void CountNum_CPP()
//{
// int array[] = { 1, 1, 1, 2, 2, 3 };
// std::unordered_map<int, int>ht;
// size_t i = 0;
// for (; i < sizeof(array) / sizeof(array[0]); ++i)
// {
// ++ht[i];
// }
// // 遍历哈希表,打印结果就可以了
// for (auto item : ht)
// {
// printf("%d,%d\n", item.fist, item.second);
// }
//}
int main()
{
TestInit();
TestInsert();
TestFind();
TestRemove();
CountNum();
//CountNum_CPP();
system("pause");
return 0;
}结果如下:















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









