







Logistic回归模型
主题思想
是一个分类模型,通过对数据的分类边界线建立回归公式,从而实现分类。
激活函数
将连续的数值转化成0或1的输出。
Heaviside函数(阶梯跳跃函数):
- 0到1的跳跃过程不平滑
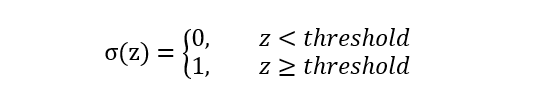

Sigmoid函数:
- 0到1的渐变过程平滑
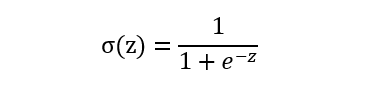

Logistic回归模型实现过程:
- 将样本特征值与回归系数相乘
- 再将所有特征值与回归系数的乘积相加
- 最后将加和代入sigmoid函数
- 输出一个范围在0-1之间的值
- 结果大于0.5的样本归入1类,小于0.5的归入0类
Logistic回归模型公式:
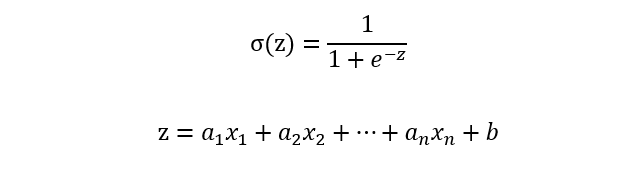
Logistic损失函数:对数似然损失函数
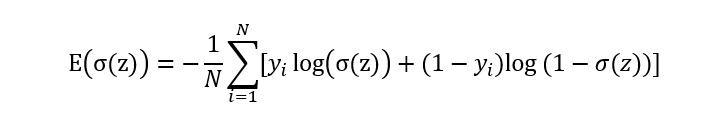
即:
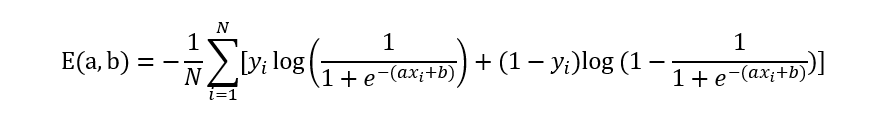
梯度下降法
- 无约束多元函数极值求解方法
- 一种常用的机器学习参数求解方法
- 通过迭代得到最小化的损失函数所对应的模型参数
基本思路:
- 在求解目标函数E(a) 的最小值时,a沿着梯度下降的方向不断变化求解最小值
什么是梯度:
假设优化目标是求解函数E(a)的最小值
- 参数a的梯度为函数E(a)的偏导数
- 因此a的迭代公式为:
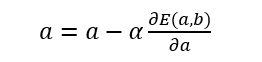
其中阿尔法为步长
什么是步长:
- 步长是梯度下降迭代的速度控制器
- 步长调小:收敛速度慢
- 步长太大:可能跳过函数最小值,导致发散
参数求解:梯度下降法
循环a和b:
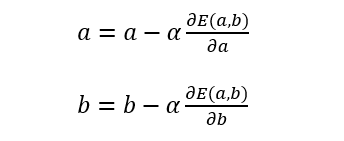
设置循环次数或者阈值,当达到循环次数或者两次的值小于阈值时,迭代终止。
惩罚模型
惩罚(正则化)定义: 通过在模型损失函数中增加一个正则项(惩罚项)来限制模型的复杂度
惩罚项: 一般来说都是一个随着模型复杂度增加而增加的单调递增函数
惩罚项(正则化)的形式:
假设一个模型的损失函数为:

则加了惩罚项的损失函数为:
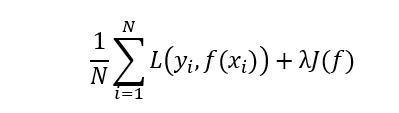
优化目标则变成:
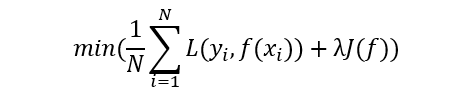
正则化的优化目标:求解参数使得模型的误差最小,同时模型的复杂度最低
惩罚项(正则化)的目的:通过降低模型的复杂度,从而防止过拟合,提高模型的泛化能力
解释一:
- 奥卡姆剃刀原理
- 解释:能够用简单的方法达到很好的项目,就没有必要使用复杂的方法
- 原理推广:如果简单的模型就能够达到很好的预测效果,就没有必要选择复杂的模型
解释二:
- 在模型中使用更多的自变量,一般情况下都会提升模型在训练数据集上的表现,但同时也会提高模型的复杂度,降低模型在验证集上的泛化能力,造成过拟合。
常用的惩罚项(正则化)
以线性回归模型的损失函数为例,假设线性回归模型需要求解的参数为列向量A,数据集中有N个样本
- L1正则系数:lasso回归
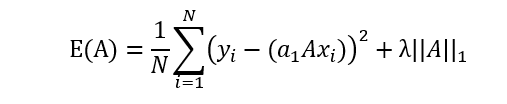
(所有参数绝对值之和) - L2正则系统:ridge回归
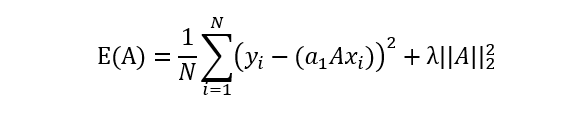
(所有参数平方的和再开方)
常用的惩罚项(正则项)特性:
L1正则系数:lasso回归
- L1是模型各个参数的绝对值之和
- L1可以将特征参数约束到0,因此L1会趋向于产生少量的特征,而其他的特征都是0
- L1也因此具有特征筛选的功能(被筛除的特征特征参数为0)
- L1通过融入少量的特征来防止过拟合
L2正则系统:ridge回归
- L2是模型各个参数的平方和的开方值
- L2只能减少特征参数值,让参数接近0,但不能将参数约束到0
- L2通过减少特征的参数值来防止过拟合
















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











