






简介
随着人工智能技术的发展,特别是深度学习和自然语言处理的进步,AI在内容创作领域的应用越来越广泛。字节跳动作为一家领先的科技公司,一直在探索如何利用AI技术来提升用户体验和创造力。OmniHuman-1模型正是在这种背景下诞生的,它致力于解决视频内容生成中的一些关键问题,比如人物动态生成、口型同步等,从而为用户提供更加丰富和生动的内容创作工具。
在这里插入图片描述
模型架构
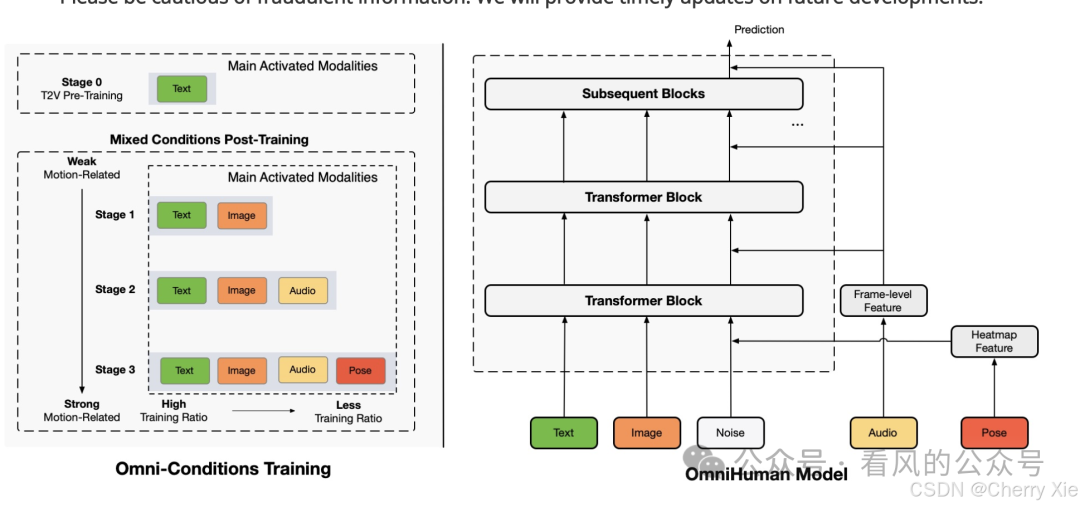
虽然具体的内部架构细节没有完全公开,但从已有的信息可以得知,OmniHuman-1模型是一个多模态的视频生成模型。这意味着它可以处理不同形式的数据输入,如图片和音频,并将它们整合起来以生成包含特定人物动作和声音的视频内容。该模型可能集成了高级的图像处理技术、语音识别以及合成技术,能够根据输入的一张图片和一段音频生成一个具有全身动作的动态视频,并保证口型同步的准确性。
相关特点
-
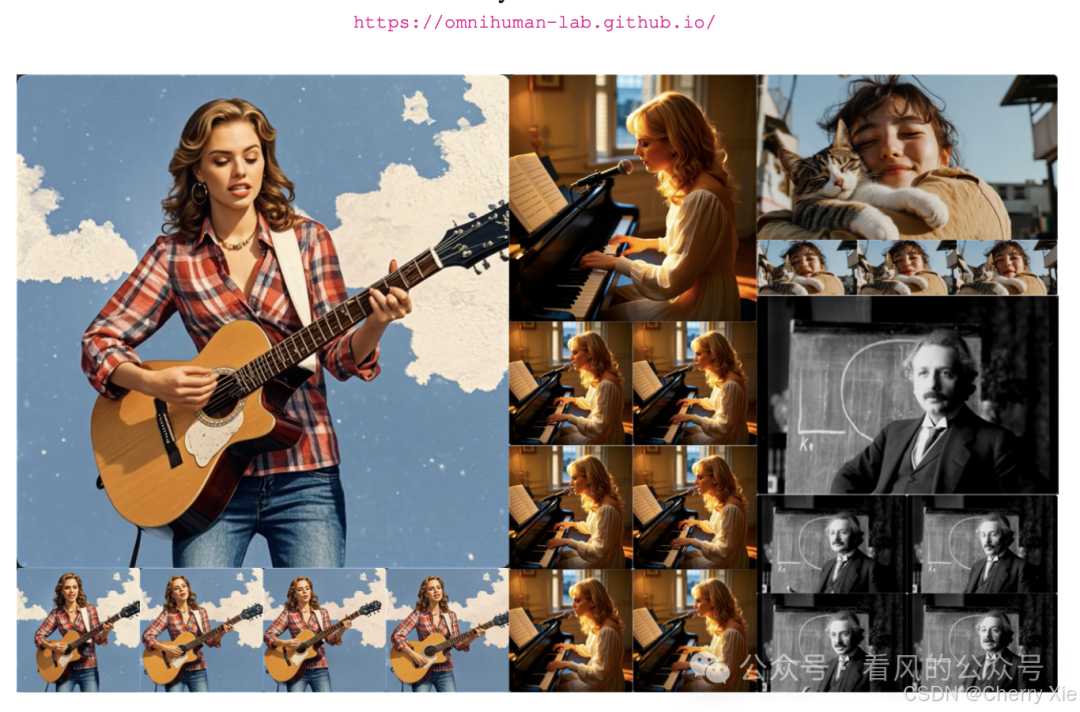
• 高效的视频生成:用户仅需上传一张图片和一段音频,即可快速生成带有指定人物动作和声音的视频。
-
• 精确的口型同步:OmniHuman-1特别强调了其在视频生成过程中对于口型同步的支持,这大大提升了生成视频的真实感和专业性。
- • 全面的动作捕捉:支持肖像、半身以及全身等不同尺寸的图片输入,并能据此生成相应的视频内容,增加了应用场景的多样性。
性能分析
性能方面,OmniHuman-1展示了强大的功能性和灵活性。例如,在内测阶段,该模型就表现出能够在一张照片加上一段音频的基础上生成背景动态、支持全身动作的视频,并且能够确保口型与音频的完美同步。此外,为了保障内容的安全性和合法性,即梦AI还设置了严格的安全审核机制,并对输出的视频添加水印标识。
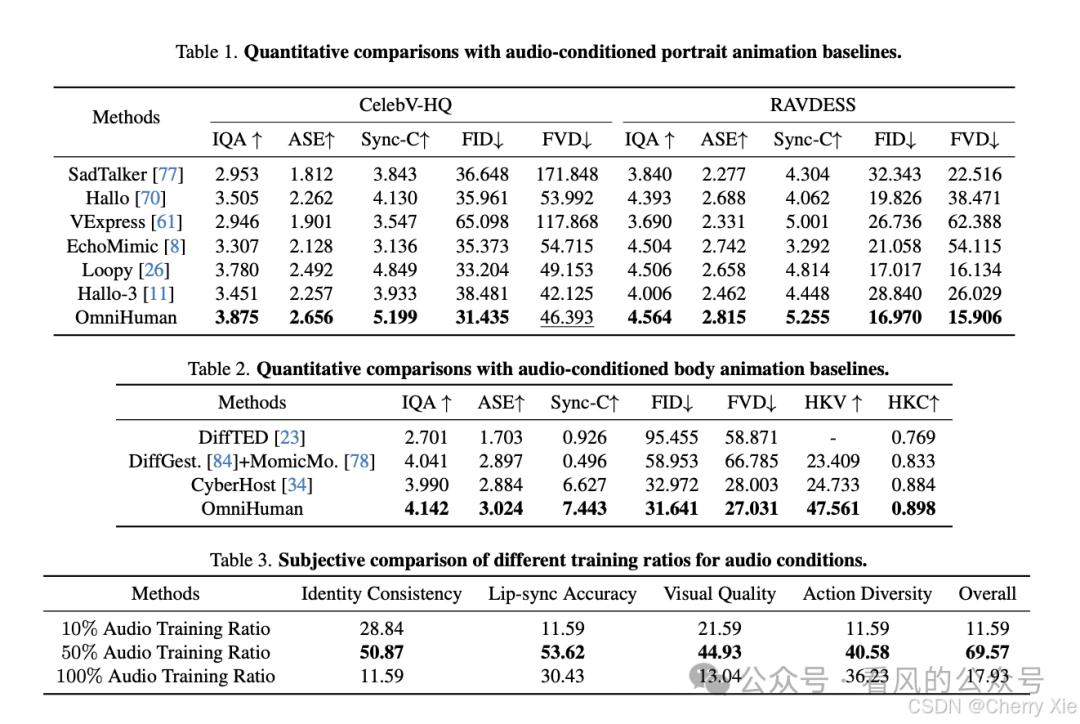
整体上口型,动作上,相对来说已经不是很僵硬了



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











