







2. 表结构设计和数据类型优化
2.1. 数据库表设计
良好的表结构设计是高性能的基石,应该根据系统将要执行的业务查询来设 计,这往往需要权衡各种因素。糟糕的表结构设计,会浪费大量的开发时间,严重延误项目开发周期,让人痛苦万分,而且直接影响到数据库的性能,并需要花 费大量不必要的优化时间,效果往往还不怎么样。
在数据库表设计上有个很重要的设计准则,称为范式设计。
2.1.1. 范式设计
2.1.1.1. 什么是范式?
范式来自英文 Normal Form,简称 NF。要想设计—个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求得严格。满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入 (insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据 库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三 范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又 称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上 进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来 说,数据库只需满足第三范式(3NF)就行了。
2.1.1.2. 数据库设计的第一范式
定义: 属于第一范式关系的所有属性都不可再分,即数据项不可分。 理解: 第一范式强调数据表的原子性,是其他范式的基础。例如下表
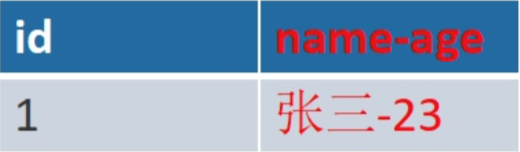
name-age 列具有两个属性,一个 name,一个 age 不符合第一范式,把它拆 分成两列

上表就符合第一范式关系。但日常生活中仅用第一范式来规范表格是远远不 够的,依然会存在数据冗余过大、删除异常、插入异常、修改异常的问题,此时 就需要引入规范化概念,将其转化为更标准化的表格,减少数据依赖。
实际上,1NF 是所有关系型数据库的最基本要求,你在关系型数据库管理系 统(RDBMS),例如 SQL Server,Oracle,MySQL 中创建数据表的时候,如果数 据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说, 只要在 RDBMS 中已经存在的数据表,一定是符合 1NF 的。
2.1.1.3. 数据库设计的第二范式
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二 范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。 通常在实现来说,需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
也就是说要求表中只具有一个业务主键,而且第二范式(2NF)要求实体的 属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。什么意思呢?
有两张表:订单表,产品表


一个订单有多个产品,所以订单的主键为【订单 ID】和【产品 ID】组成的 联合主键,这样 2 个组件不符合第二范式,而且产品 ID 和订单 ID 没有强关联, 故,把订单表进行拆分为订单表与订单与商品的中间表

2.1.1.4. 数据库设计的第三范式
指每一个非非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。例如,存在一个部门信息表, 其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。

其中
产品 ID 与订单编号存在关联关系
产品名称与订单编号存在关联关系
产品 ID 与产品名称存在关联关系
如果产品 ID 发生改变,产品姓名也会改变;产品名称发生变化,这样不符 合第三范式,应该把产品名称这一列从订单表中删除
2.1.1.5. 范式说明
真正的数据库范式定义上,相当难懂,比如第二范式(2NF)的定义“若某关系R属于第一范式,且每一个非主属性完全函数依赖于任何一个候选码,则关系R属于第二范式。”,这里面有着大堆专业术语的堆叠,比如“函数依赖”、 “码”、“非主属性”、与“完全函数依赖”等等,而且有完备的公式定义,需要仔细研究的同学,请参考这本书:

2.1.2. 反范式设计
2.1.2.1. 什么叫反范式化设计
完全符合范式化的设计真的完美无缺吗?很明显在实际的业务查询中会大量存在着表的关联查询,而大量的表关联很多的时候非常影响查询的性能。
所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反。允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间。
2.1.2.2. 反范式设计-商品信息
下面是范式设计的商品信息表

商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放。

2.1.2.3. 范式化和反范式总结
范式化设计优缺点
1、范式化的更新操作通常比反范式化要快。
2、当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修 改更少的数据。
3、范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快。
4、很少有多余的数据意味着检索列表数据时更少需要 DISTINCT 或者 GROUP BY 语句。在非范式化的结构中必须使用 DISTINCT 或者 GROUPBY 才能获得一份唯一的列表,但是如果是一张单独的表,很可能则只需要简单的查询这张表就行了。
范式化设计的缺点是通常需要关联。稍微复杂一些的查询语句在符合范式的 表上都可能需要至少一次关联,也许更多。这不但代价昂贵,也可能使一些索引策略无效。例如,范式化可能将列存放在不同的表中,而这些列如果在一个表中本可以属于同一个索引。
反范式化设计优缺点
1、反范式设计可以减少表的关联
2、可以更好的进行索引优化。
反范式设计缺点也很明显
1、存在数据冗余及数据维护异常,
2、对数据的修改需要更多的成本。
2.1.3. 实际工作中的反范式实现
2.1.3.1. 性能提升-缓存和汇总
范式化和反范式化的各有优劣,怎么选择最佳的设计?
请记住:小孩子才做选择,我们全都要;小孩才分对错,大人只看利弊。
而现实也是,完全的范式化和完全的反范式化设计都是实验室里才有的东西, 在真实世界中很少会这么极端地使用。在实际应用中经常需要混用。
最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
比如从父表冗余一些数据到子表的。前面我们看到的分类信息放到商品表里面进行冗余存放就是典型的例子。
缓存衍生值也是有用的。如果需要显示每个用户发了多少消息,可以每次执行一个对用户发送消息进行 count 的子查询来计算并显示它,也可以在 user 表用 户中建一个消息发送数目的专门列,每当用户发新消息时更新这个值。
有需要时创建一张完全独立的汇总表或缓存表也是升性能的好办法。“缓存表”来表示存储那些可以比较简单地从其他表获取(但是每次获取的速度比较 慢)数据的表(例如,逻辑上冗余的数据)。而“汇总表”时,则保存的是使用 GROUP BY 语句聚合数据的表。
在使用缓存表和汇总表时,有个关键点是如何维护缓存表和汇总表中的数据, 常用的有两种方式,实时维护数据和定期重建,这个取决于应用程序,不过一般 来说,缓存表用实时维护数据更多点,往往在一个事务中同时更新数据本表和缓存表,汇总表则用定期重建更多,使用定时任务对汇总表进行更新。
2.1.3.2. 性能提升-计数器表
计数器表在 Web 应用中很常见。比如网站点击数、用户的朋友数、文件下 载次数等。对于高并发下的处理,首先可以创建一张独立的表存储计数器,这样 可使计数器表小且快,并且可以使用一些更高级的技巧。
比如假设有一个计数器表,只有一行数据,记录网站的点击次数,网站的每 次点击都会导致对计数器进行更新,问题在于,对于任何想要更新这一行的事务 来说,这条记录上都有一个全局的互斥锁(mutex)。这会使得这些事务只能串行 执行,会严重限制系统的并发能力。
怎么改进呢?可以将计数器保存在多行中,每次随机选择一行进行更新。在 具体实现上,可以增加一个槽(slot)字段,然后预先在这张表增加 100 行或者更 多数据,当对计数器更新时,选择一个随机的槽(slot)进行更新即可。
这种解决思路其实就是写热点的分散,在 JDK 的 JDK1.8 中新的原子类 LongAdder 也是这种处理方式,而我们在实际的缓冲中间件 Redis 等的使用、架 构设计中,可以采用这种写热点的分散的方式,当然架构设计中对于写热点还有削峰填谷的处理方式,这种在 MySQL 的实现中也有体现。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









