







1.故障背景
20230512早上9点半左右,服务突然中断造成产品不可用。
2.设想重启原因:
1.时间端内有占用大内存操作,定时任务,造成内存溢出或者探针失败重启
2.时间段内业务高峰,内存溢出或探针失败重启
3.kafka大量失败造成应用重启。那么kafka失败原因排查
3.排查过程
3.1排查应用不可用探针失败造成重启
首先查看 pod状态:

所有pod都有一次重启记录。
检查pod状态:因为pod已经重启了。查看现在pod详情还是可以看到探针超时。
检查探针设置:

Pod Events中超时的是 readiness探针。解释下探针:
readiness probes:就绪性探针,用于检测应用实例当前是否可以接收请求,如果不能,k8s不会转发流量。
探针说明,探测类型
livenessProbe:kubelet 使用存活探测器来确定什么时候要重启容器。 例如,存活探测器可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。
readinessProbe:kubelet 使用就绪探测器可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。
startupProbe:kubelet 使用启动探测器来了解应用容器何时启动。 如果配置了这类探测器,你就可以控制容器在启动成功后再进行存活性和就绪态检查, 确保这些存活、就绪探测器不会影响应用的启动。 启动探测器可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉
也就是说只要readiness 失败只会标记未就绪,从service的负载均衡中移除,并不会重启pod。
那么readiness探针失败造成重启就排除了。
3.2 排查kafka报错造成服务重启:
容器重启当前容器的日志不是故障发生的日志,需要查看历史容器的日志。
我知道的有两种方式可以查看历史容器日志:
- kubectl logs podName --previous
- 找到目录
/var/log/pod/容器id/容器名查看历史容器日志:
怀疑kafka的最直接原因原容器的日志中:
2023-05-12 09:29:16.211 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.fetch.size.avg [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.211 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.records.consumed.rate [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.213 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.bytes.consumed.rate [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.214 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.records.per.request.avg [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.218 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.fetch.size.max [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.220 INFO 1 --- [ool-67-thread-1] i.m.c.i.binder.kafka.KafkaMetrics : Failed to bind meter: kafka.consumer.fetch.manager.records.consumed.total [tag(client-id=consumer-hcp-fdbusiness-svc-12), tag(topic=med-pay-trade), tag(kafka-version=2.5.1), tag(spring.id=med-pay-trade.consumer.consumer-hcp-fdbusiness-svc-12)]. However, this could happen and might be restored in the next refresh.
2023-05-12 09:29:16.370 ERROR 1 --- [io-8080-exec-22] c.z.h.f.e.DefaultExceptionHandler : System exception found:
reactor.core.Exceptions$ReactiveException: java.lang.InterruptedException
java.lang.NullPointerException: null
at org.springframework.web.util.UrlPathHelper.removeJsessionid(UrlPathHelper.java:542)
2023-05-12 09:29:17.216 INFO 1 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService
2023-05-12 09:29:17.244 INFO 1 --- [extShutdownHook] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'
2023-05-12 09:29:17.247 INFO 1 --- [extShutdownHook] o.s.s.c.ThreadPoolTaskScheduler : Shutting down ExecutorService 'taskScheduler'
2023-05-12 09:29:17.248 INFO 1 --- [extShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown initiated...
2023-05-12 09:29:17.256 INFO 1 --- [extShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
2023-05-12 09:29:17.260 INFO 1 --- [extShutdownHook] com.netflix.discovery.DiscoveryClient : Shutting down DiscoveryClient ...
2023-05-12 09:29:20.261 WARN 1 --- [scoveryClient-1] c.netflix.discovery.TimedSupervisorTask : task supervisor shutting down, can't accept the task
2023-05-12 09:29:20.261 INFO 1 --- [extShutdownHook] com.netflix.discovery.DiscoveryClient : Unregistering ...
2023-05-12 09:29:20.267 INFO 1 --- [extShutdownHook] com.netflix.discovery.DiscoveryClient : DiscoveryClient_HCP-FDBUSINESS-SVC/hcp-fdbusiness-svc-5457d99c89-94ff4:hcp-fdbusiness-svc - deregister status: 200
2023-05-12 09:29:20.275 INFO 1 --- [extShutdownHook] com.netflix.discovery.DiscoveryClient : Completed shut down of DiscoveryClient
Kafka执行rebalence 后就马上报错,然后就是各种shutdown了。日志再往前翻,也有rebalence,并不会直接造成服务被干掉。 而且rebalence并不是很频繁。Rebalence是kafka非常常见的动作,只会短暂无法消费消息,很快就会恢复正常。
到这里就排除了kafka的原因
3.3故障时间段内业务高峰。
从主要业务数据检查是否异常:
核心的签约业务,并没有异常数据量情况。同时检查定时任务也没有发现异常数据量操作。
所以排除故障时间段内业务高峰
4.系统原因排查
切换到pod所在物理主机查看linux操作系统日志:/var/log/messages
May 12 09:28:39 kn-56 kubelet: W0512 09:28:39.680915 21612 eviction_manager.go:330] eviction manager: attempting to reclaim memory
May 12 09:28:39 kn-56 kubelet: I0512 09:28:39.682970 21612 eviction_manager.go:341] eviction manager: must evict pod(s) to reclaim memory
May 12 09:28:39 kn-56 kubelet: I0512 09:28:39.684012 21612 eviction_manager.go:359] eviction manager: pods ranked for eviction: redis-3_med-rhin(d756304c-c34f-4aec-856e-589f94bcccb8), nuclein-svc-40_med-rhin(b23e48a9-1533-4105-9b2b-a7301943ce8d), hcp-fdbusiness-svc-5457d99c89-94ff4_med-rhin(6505583b-894e-4d31-a31a-67d6b9c57e81), nuclein-trip-svc-41_med-rhin(5b9d8572-d645-44ff-b794-8b6e4c07a003), nuclein-trip-svc-57_med-rhin(5332fd71-c56a-4198-886e-f029410c77d8), nuclein-weixin-6cb545fd44-xpbtf_med-rhin(f545f1cf-94fc-445a-81a0-313193a95246), rhin-eureka-1_med-rhin(bdec2717-0868-4ab6-a49b-db18a8d0a8f1), nginx-ingress-controller-dfkw5_ingress-nginx(b6eade3b-cc4e-44d8-91b1-01fefad4d8d7), hcp-wechat-portal-6d4879db4b-t2mp7_med-rhin(c603056d-91b3-4070-a868-24aefb1b1963), nuclein-manage-tender-5c6fc5d796-26nrv_med-rhin(f7876802-efb0-4370-a466-859906c1c4f3), calico-node-djgrl_kube-system(4a0c6908-f716-4cc7-92e6-2c3f41d9a253), kube-proxy-m8xq5_kube-system(96a786d7-aaa2-40ca-907e-bb392c457ea9), node-exporter-767hm_monitoring(c315e60c-2323-4775-a28b-e7ba11dc091f), filebeat-filebeat-vd8ld_med-rhin(a5cefe0a-38fb-48ff-8555-e00cb6cb0e38)
May 12 09:28:39 kn-56 dockerd: time=“2023-05-12T09:28:39.829704332+08:00” level=info msg=“Container ad6332e6c7e6fe491fc2f79d576dea8d1dd48985553c595414e1686abd3faa8d failed to exit within 0 seconds of signal 15 - using the force”
驱逐pod以回收内存。
在阿里云微博中找到了k8s驱逐pod原因:
Kubernetes用于处理低RAM和磁盘空间情况的驱逐策略:https://www.alibabacloud.com/blog/kubernetes-eviction-policies-for-handling-low-ram-and-disk-space-situations—part-1_595202
定义了低RAM和低磁盘空间的阈值,当达到这些阈值时,Kubernetes驱逐策略就会起作用。Kubernetes将Pods从节点中逐出,以解决低RAM和低磁盘空间的问题。
文章介绍有两种情况会导致pod驱逐:
-
RAM和磁盘空间超过一定阈值就会开始驱逐pod
检查节点的磁盘使用量:
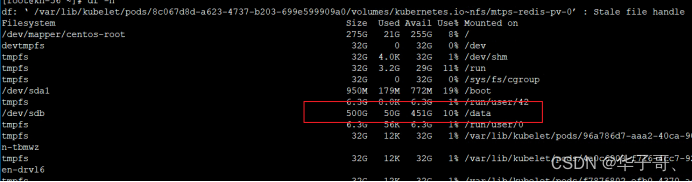
Data目录下的空间还有很多。 pod运行时的日志文件都是写入这个目录下的。磁盘的使用量一般只会不断累积,越来越大。
所以排除磁盘使用量不足问题所以磁盘超过阈值的情况 -
检查内存使用量情况:

目前看,可用量还是比较多的。节点内存一共64G 可用量有13G
然后问题就是内存使用量了。然而一个节点上部署的应用是不固定的,每个应用占用的内存大小也不是固定的。所以大概率还是节点上的内存使用量超过阈值触发了Kubernetes驱逐策略生效。
5.结论
最终本次故障的原因最终定位到:内存使用量问题上。节点上的内存使用量超过阈值触发了Kubernetes驱逐策略生效。
优化建议:
- k8s配置调优:
给每个应用加上资源限制。K8s的调度策略是根据request和limit来判断是否应该调度到目标节点。给关键节点配置亲和与反亲和。 - Liunx系统参数调优:
调高系统进程id数量:/etc/sysctl.conf kernel.pid_max
调高文件句柄数:/etc/security/limits.conf
限制一个进程可以拥有的VMA(虚拟内存区域)的数量:/etc/sysctl.conf max_map_count
调整内存分配策略:/etc/sysctl.conf vm.overcommit_memory:0 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









