






 OpenAI的AI创作工具Sora已让好莱坞专业人士惊叹,通过一系列创新短片展示了其在故事叙述和超现实场景方面的潜力。Sora利用Transformer架构和潜在扩散模型,实现了高质量的视频生成,预示着AI在创意产业的影响力日益增强。
OpenAI的AI创作工具Sora已让好莱坞专业人士惊叹,通过一系列创新短片展示了其在故事叙述和超现实场景方面的潜力。Sora利用Transformer架构和潜在扩散模型,实现了高质量的视频生成,预示着AI在创意产业的影响力日益增强。

作者 | 王启隆
出品 | CSDN(ID:CSDNnews)
今年 2 月中旬,OpenAI 首次向公众展示 Sora,从此吊了全世界一个月的胃口,每当问起“Sora 什么时候发布?”,下到员工,上到 Sam Altman 都会这么回答:“现在还不行。”
虽然表面上 OpenAI 搞得神神秘秘,但在上周就有知情人士透露,OpenAI 计划与美国洛杉矶与好莱坞的影视公司和媒体高管会面。而 OpenAI 首席执行官 Sam Altman 在奥斯卡电影节周末出席洛杉矶的多场派对印证了这一说法,难道 Sora 真的成功到能让好莱坞青睐了?
就在今天早上,OpenAI 给出了答案:一批精选的艺术家、设计师和电影制作人已经使用 Sora 两个月啦!OpenAI 还难得更新了官方博客,取名为:初印象。
下面就来看看,好莱坞的大神们能用 AI 创作出多么大开脑洞的电影。

能讲故事的 AI 电影
总部位于多伦多的多媒体制作公司 Shy Kids 用 Sora 制作了短片《气球人》(Air Head),这也是当前最受关注的一则短片,导演只有三人:Walter Woodman, Sidney Leeder 和 Patrick Cederberg。
导演 Walter Woodman 如此评价 Sora:“尽管 Sora 擅长创造拟真的事物,但令我们兴奋的是它能够创造出完全超现实的事物。”
影片开头,是气球人的自言自语:“每个人都有与众不同的地方,但对我来说,这种特殊性显而易见……”
然后镜头一转到他的头部,一颗气球说道:“我其实充满了热空气。”
Woodman 评价的“超现实”这个词恰如其分地描述了这部影片,毕竟主角脑袋是一个黄色的气球。
紧接着,气球人继续描述了他这种与异常状态共存的喜悦与困扰。刮风的日子会让他的头从肩膀上飞走,当他走过一家植物店的仙人掌区时,情况则更加棘手。但他也深深地意识到“我们所有人都只差一根针扎就能泄气”,而对此他表示感激。简而言之,就是教导大家克服生活中的不如意。
OpenAI 在其博客文章中表示,来自 Shy Kids 和其他早期测试者的视频将有助于他们尽早发布 Sora。OpenAI 并未透露他们到底请了多少艺术界大佬来测试 Sora,也没有透露影片制作所依据的具体参数。
再来看看作家兼导演 Paul Trillo 的影片,他的作品曾赢得了《滚石》和《纽约客》等媒体的赞誉。他说:“与 Sora 合作是我第一次感受到作为一名电影制片人不受束缚,不受时间、金钱、他人许可的限制,我可以以大胆而令人兴奋的方式进行构思和实验。”
乍一看前几秒,还以为是第一人称赛车,但往后看会发现这是一个极具想象力的影片,展现了一个金属人的冒险。
下面这一则影片非常有”镜头感“,它来自 Nativeforeign 的创意总监 Nik Kleverov,他所属的公司是一家来自加利福尼亚州洛杉矶的艾美奖提名创意机构,专门从事品牌故事讲述、动作和标题设计以及生成人工智能工作流程。可以说,这家公司就是针对 AI 时代建立的。

超现实的梦幻场景
伦敦 Oraar Studio 的创意总监 Josephine Miller 也参与了测试,她的工作室擅长 3D 视觉、增强现实和数字时尚,她的短片最为梦幻,展现了一个梦幻般的水下世界,人类身着覆盖着虹彩鱼鳞般光泽的服装,在其中悠然旋转,整个世界介于现实与无拘无束的想象之间。
Miller 对 Sora 的评价是:“这种高质量快速概念化的能力不仅挑战了我的创作过程,还帮助我在讲故事方面不断进化。”
OpenAI 还请到了梦工厂的 Don Allen Stevenson III 创作了一个“动物片”,据他本人所称,“很长一段时间以来,我一直在制作增强现实混合生物,我认为它们在我的脑海中会是有趣的组合。现在,在完全构建 3D 角色并将其放入空间计算机之前,我可以更轻松地对想法进行原型设计。”
在未来,AIGC 开始涉及游戏创作的时候,这一技术肯定能创造出各种奇异的归怪物。
导演用 Sora 都十分得心应手,那如果换其他行业的人来呢?测试者中也包括 August Kamp 这样的研究员兼音乐人,她的思路就是创作一个科幻片。
七部短片中还包括 L.A.-based 创意机构 Native Foreign 的联合创始人兼创意总监 Nik Kleverov 的作品。他的作品呈现了一部跨越数十年、情绪和视觉风格的引人入胜的合辑。
在这部影片中,一名仿佛出自黑白电影中的男子走在雨后鹅卵石铺成的城市街道上,另一名男子则在渲染成怀旧棕褐色调的老式钟表修理店里俯身研究钟表。
Kleverov 的评价是,他已经看到了 Sora 将如何改变他在代理机构工作和个人项目上的方式。“它让我能够迭代和探索那些因预算和资源限制而被搁置或暂停的原创概念。”
OpenAI 称:“虽然我们在 Sora 上还有很多改进要做,但我们已经开始看到该模型如何帮助创作者将想法变为现实。”

隐藏在影片后的技术实现
如今,Sora 面临着无数的「复现者」和「解读者」,大家都想搞出自己的视频生成工具。虽然 OpenAI 对此一言不发,但仍有人试图从蛛丝马迹之中揭秘 Sora 的真相。近期,前 OpenAI 研究科学家 Matthias Plappert 就在 Factorial Funds 发表了自己的猜测。
Plappert 先是阅读了 Sora 的那篇完全不透露细节的技术报告,然后推测 Sora 深受 Scalable Diffusion Models with Transformers 这篇论文的影响,其中作者提出了一种基于 Transformer 的架构,称为 DiT(Diffusion Transformers 的缩写),用于图像生成。
他是怎么推测出来的?因为 DiT 的作者是 William Peebles,这个人正是 Sora 的核心作者之一。
接下来就可以根据这点推出 Sora 模型的工作原理,其中有三个重要部分:
1. Sora 不在像素空间中运行,而是在潜在空间中执行扩散(即潜在扩散,后文会解释)
2. Sora 还是没绕开 Transformer 架构
3. Sora 使用着非常大的数据集
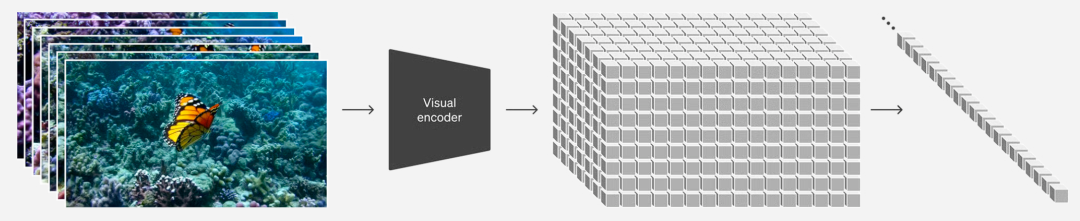
这张图从左到右表示了“像素”——“潜在”的映射。所谓“潜在扩散”,是一种高效生成高质量图像的技术手段。在生成图像时,传统的扩散模型可能会直接对每个像素进行操作,但这样做会在面对高分辨率图像(如 512x512 像素)时计算效率极低。
为解决这一问题,“High-Resolution Image Synthesis with Latent Diffusion Models”研究论文提出了一个关键突破:首先将像素映射到压缩后的潜在空间表示中,在这个更为紧凑的潜在空间执行扩散过程,最后再从潜在空间解码回像素空间。例如,原本需要处理 262,144 个像素,现在只需生成 4,096 个潜在变量(如 64x64 大小),极大地提升了计算效率。
DiT 和 Sora这样的模型,它们都采用了这一方法。而 Sora 针对视频数据还考虑了时间维度,因此其编码步骤不仅在空间上压缩每一帧的宽度和高度,还在时间维度上进行压缩,以适应视频序列的特点。
其次,DiT 和 Sora 摒弃了常用的 U-Net 架构,转而采用 Transformer 架构。研究表明,使用 Transformer 能带来可预测的规模扩展性:随着训练计算量的增加(通过延长训练时间、增大模型规模或两者兼施),模型性能会得到相应提升。Sora 报告中的数据显示,视频生成任务同样存在这种规律,并给出了生动的说明。
为了训练诸如 Sora 这样的模型,还需要大量的标注数据作为关键要素。OpenAI 并未详细透露所使用的数据集信息,但暗示其规模非常庞大,借鉴了大规模语言模型通过互联网级别数据训练获得通用能力的经验。
紧接着,Plappert 聊了聊 Sora 能带来的影响,表示 Sora 毋庸置疑能改变这些行业:
鉴于 Sora 模型的具体信息有限,Plappert 还是基于 DiT 模型进行估算。
DiT-XL 模型拥有 6.75 亿参数,训练用了约 10^21 FLOPS。考虑到 Sora 为视频模型,可生成 1 分钟视频,若按照 24fps 计算,有 1440 帧,假设像素至潜在空间的压缩率与 DiT 相同为 8 倍,则潜在空间处理 180 帧。结合 Sora 可能有 20B 参数,比 DiT 模型大 30 倍,所以对训练计算量进行放大。
实际上,OpenAI 可能用了更多的参数……
对于数据集大小,假设 Sora 的数据集比 DiT 大 4 到 10 倍,据此进行低估和高估训练计算量,得到低估计为 1.1×10^25 FLOPS,高估计为 2.7×10^25 FLOPS,对应 Nvidia H100 数量分别为 4,211 至 10,528 台/月。
在推理阶段,Sora 每生成一分钟视频所需约为 2.8×10^15 FLOPS,按 250 个扩散步骤计算,单个 H100 每小时生成约 5 分钟视频。估算在生成一定数量视频后,推理计算将超过训练计算。对比 TikTok 和 YouTube 每日上传视频数量及假设的人工智能渗透率,估计在峰值需求下,支持这两个平台创作社区所需的 Nvidia H100 总量约 72 万个,但这未考虑 GPU 利用率、内存瓶颈、非均匀需求以及创作者可能产生的多个候选视频等因素。
总的来说,尽管推理计算通常小于训练计算,但随着生成式 AI 模型(如 Sora)的广泛应用,推理阶段的计算需求将占据主导地位,并随模型规模扩大而显著增长。同时,优化推理技术和跨堆栈优化能够减轻计算压力。

4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。欢迎所有开发者朋友访问官网 http://ml-summit.org、点击「阅读原文」或扫码进一步了解详情。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









