







分享嘉宾 | 郭春超
责编 | 梦依丹
出品丨AI 科技大本营(ID:rgznai100)
现在这个时代,我们玩的游戏、看的电影、甚至未来的虚拟世界,都离不开精细逼真的三维(3D)模型。然而,制作这些 3D 内容,过去常常意味着耗时数周甚至数月的人工建模,成本高昂且效率低下。就像平面设计曾被 Photoshop 改变一样,人工智能正在瞄准 3D 领域,试图彻底革新数字内容的生产方式。
在这场由 AI 驱动的 3D 生成浪潮中,腾讯混元团队推出的开源项目 Hunyuan 3D 成为了全球开发者社区的焦点。它不仅在 GitHub 上迅速积累了超过 9.6k 的 Star,跻身 3D 生成开源项目的第一梯队,更凭借其出色的模型生成效果,赢得了“几乎没有变形的 Image to 3D,恐怖如斯”这样的用户评价。

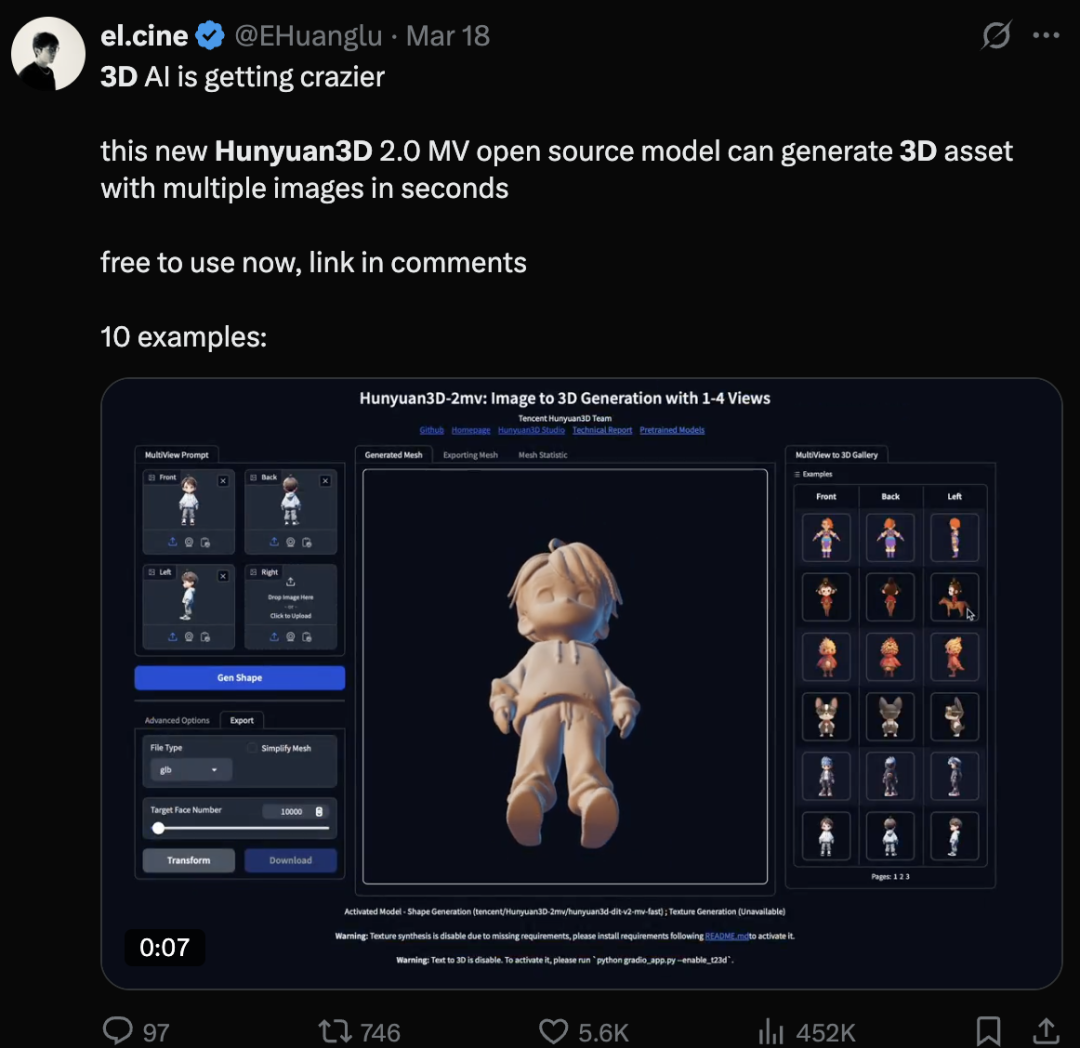
AI 生成 3D 的能力发展到什么阶段了?它离真正改变游戏、影视、数字人等行业还有多远?在 4 月 18-19 日举行的 2025 全球机器学习技术大会(ML-Summit)上,腾讯混元 3D 负责人郭春超对此进行了详尽解读,并在会后接受了 CSDN 专访。
令人意外的是,尽管当前 3D AIGC 技术已取得显著进展,郭春超却抛出了一个引人深思的观点:“真正的 3D AIGC 革命,还没开始!”

为什么他会这么说?在这次干货满满的对话中,郭春超分享了多个核心洞察:
3D 生成仍处前半程: 相比成熟的文本和图像生成,3D 生成的工业应用才刚刚起步,可用度仍有较大提升空间。
从“可见”到“可用”的挑战: 当前技术在生成静态 3D 模型上已能满足部分需求,但要融入专业的工业级 CG 管线(如自动拓扑、骨骼绑定等),还有很长的路要走。
数据稀缺与利用率: 3D 数据获取难度远高于图片,未来的突破在于如何提高现有数据的利用效率和表达能力。
技术路线的演进: 自回归(AR)模型正与扩散(Diffusion)模型结合,有望提升 3D 生成的可控性和记忆能力,甚至向构建具备物理规律的“世界模型”迈进。
开源与护城河: 持续快速的模型迭代是当前最大的护城河,开源是加速技术发展和生态繁荣的关键催化剂。
对专业人士的影响: AI 不是替代 3D 设计师,而是成为强大的生产力工具,帮助他们更快地将创意变为现实。
这篇专访将带你深入了解 3D AIGC 领域的现状、挑战与未来图景,无论你是否是技术专家,都能从中窥见这场即将到来的数字内容革命的冰山一角。

腾讯混元大模型家族:从语言模型走向全模态演进
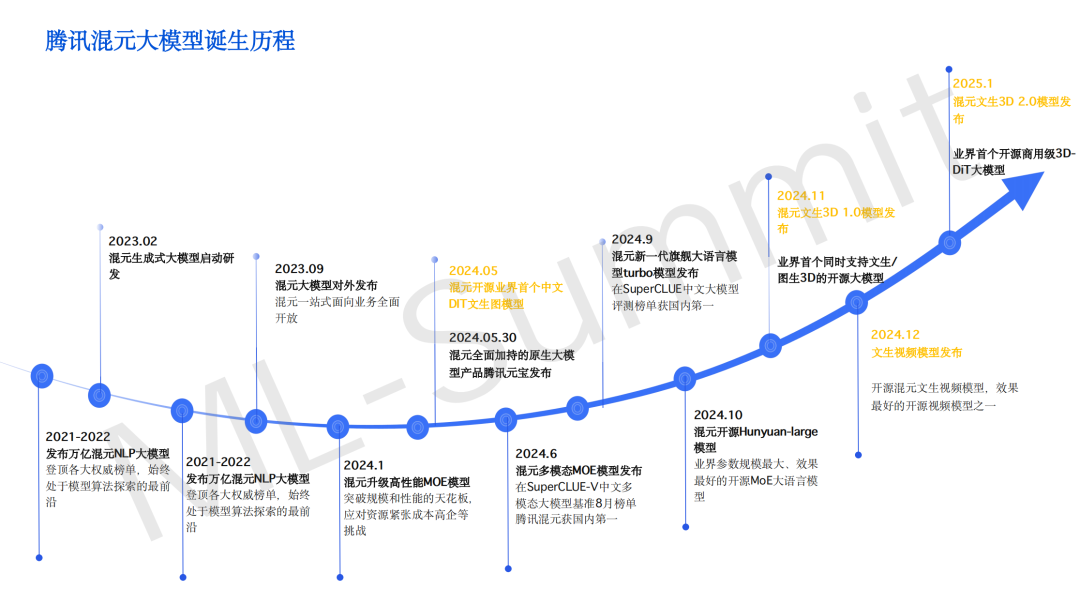
腾讯混元大模型自 2023 年 2 月启动研发以来,经历了从大语言模型向多模态模型的全面演进。早期阶段,混元聚焦于大语言模型方向,并于 2023 年 9 月正式发布,基于此前推出的万亿参数级 NLP 稀疏大模型构建生成式能力。
随着多模态生成需求的快速增长,混元持续拓展模型边界。2024 年 5 月,混元开源了业界首个中文 DIT 架构的图像生成模型,实现了中文图像生成领域的开源突破。同年 11 月,混元推出 3D 生成 1.0 模型,成为业内首个同时支持文生 3D 和图生 3D 的开源大模型。紧接着在 12 月,混元文生视频模型也加入开源行列,凭借优异的生成效果在开发者社区广受好评。
正如腾讯混元负责人郭春超所言,混元始终坚持“多模态协同”与“持续开源”的策略布局,未来还将持续推进图像、3D、视频等方向的模型开源。经过两年多的发展,腾讯混元大模型已从单一的大语言模型,成长为覆盖文本、语音、图像、3D、视频等多模态能力的全面生成式 AI 基座。

从多模态到三维:打造全链路的 3D AIGC 引擎
腾讯混元负责人郭春超指出,3D 模型作为数字世界的重要资产,已广泛应用于游戏、数字人、玩具、工业设计等多个领域。它具有可交互、可全景展示、高可控性等特征,但在生产端却长期面临成本高、周期长、数据稀缺等现实难题。
相较于图像可由手机轻松采集,3D 数据往往依赖专业艺术家建模或昂贵的 3D 扫描设备,这使得其创作门槛高、难以大规模生产。上述建模困难正亟需 3D AIGC 技术来打破瓶颈,从根本上提升 3D 资产制作效率、降低内容生产门槛。
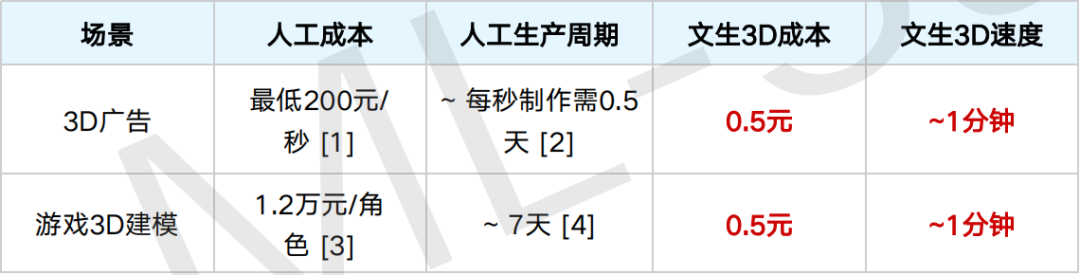
正如郭春超在大会上展示的对比数据为例,当前在广告、游戏等典型 3D 应用场景中,传统人工建模的成本与效率极不匹配:
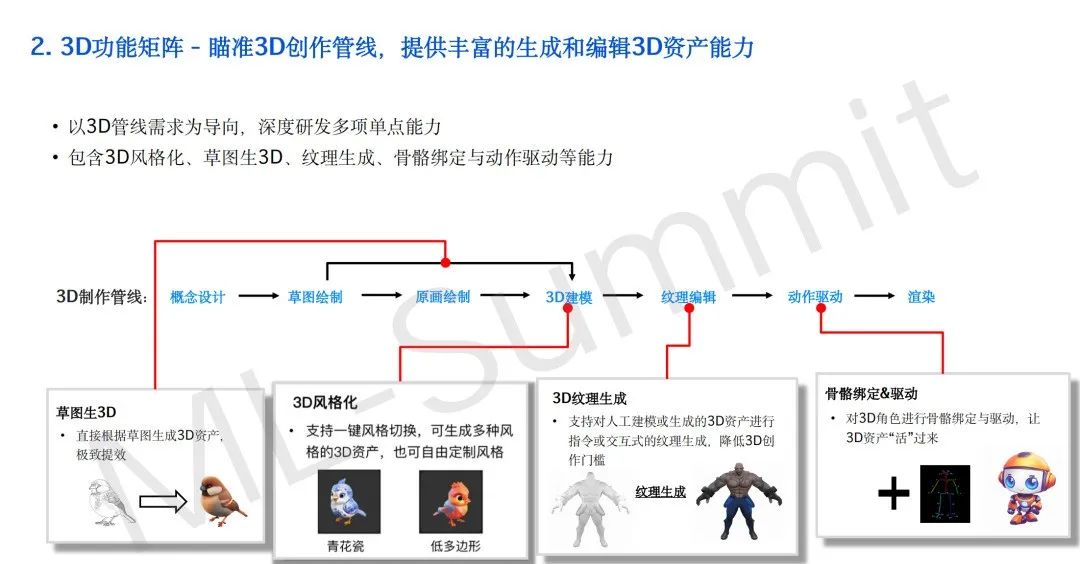
针对这些难点,腾讯混元构建了“3D 创动引擎”架构,围绕草图生 3D、纹理生3D、动作融合建模和低多边形优化,打造从稀疏输入到高质量可用资产的完整模型矩阵:
草图生 3D(Sketch-to-3D):可通过手绘草图快速生成三维模型,并支持通过 2D 图像作为桥接增强泛化能力,适用于初学者、设计师等低门槛创作场景;
纹理换肤生成:基于已有 3D 白膜实现任意纹理映射,使一个几何模型可支持多种形象外观,大幅提升资产复用率,适用于数字人、虚拟角色等个性化需求场景;
动作融合建模:支持角色的动作生成与驱动,服务于动画、虚拟数字人等动态内容需求;
低多边形建模与布线控制:通过自研 PolyGen 技术,生成布线规整、适配工业动画与实时渲染需求的轻量化模型,推动 3D 资产在终端设备上的落地能力。相关技术论文已于 CVPR 2025 收录。
郭春超强调,混元的目标并非一次性“接管”整个 CG 管线,而是希望通过生成式 AI 技术逐步渗透、替代关键环节,哪怕最初只解决 30%-40% 的任务,也能带来可观的提效。这种“局部重塑+逐步演进”的路径,正在让 3D 大模型真正从实验室走向产业端。
在模型能力之外,腾讯混元同步推出了 3D 创作管线工作流,为设计师提供可视化的调整界面。目前,腾讯混元的 3D 模型已获得 ComfyUI 官方支持,用户可在 ComfyUI 最新版本中直接调用混元能力,实现从草图到完整 3D 模型的一键式生成体验。

从 World Model 到三维世界重构:混元 3D 的应用与未来展望
从“重建一个物体”到“生成一个场景”,再到“理解一个世界”,混元 3D 的发展目标,是构建服务于智能体的三维世界模型(World Model)。例如未来某天,用户无需亲临卢浮宫,也能进入一个沉浸式、可编辑、可漫游的线上展馆。
构建 World Model 的过程,意味着不仅要解决三维重建和多模态理解的问题,还需应对物理一致性建模、生成内容的空间语义连贯性等系统级挑战。正如郭春超所言,单一模态难以生成复杂的 3D 场景,团队将通过跨模态融合,先从局部实现空间合理性,再逐步扩展至更大规模、结构更完整的三维世界。
目前腾讯混元的 3D 生成技术已在多个实际场景中落地,包括人物 UGC、地图车标、虚拟道具等创作。在腾讯地图上,用户可生成个性化导航车标;在游戏领域,混元也正与开发商合作,将生成能力嵌入角色、道具与场景生产流程,提升内容效率。
在开源生态方面,腾讯混元已开源多个版本的 3D 模型,最小参数仅 0.6B,支持在本地运行。目前 GitHub Star 数超 1.2 万,Hugging Face 下载量超 100 万。团队还计划在年内开放更多模型与数据集,降低行业门槛,推动能力普及。
郭春超表示,到 2025 年底,他们希望实现物体级生成接近人工建模水平,场景类生成具备初步雏形。他指出,3D 属于视觉生成分支,未来也将吸收大语言模型的演进经验,逐步走向原生多模态的统一架构。他认为,包括 AR 与 diffusion 结合的方向,将在视觉生成领域迎来更多突破。
演讲结束后,为了更深入地了解腾讯混元在 3D 生成领域的实践与思考,CSDN对腾讯混元 3D 大模型负责人郭春超先生进行了现场专访,围绕 3D 生成的技术现状、应用前景以及行业发展趋势等话题展开了深入探讨。
CSDN:感谢郭老师接受我们的采访,除了作为分享嘉宾,今天在会场有听到哪些你特别感兴趣的演讲和分享吗?
郭春超:我在来之前听了阶跃段楠老师的分享。今天我对视觉类的生成,还有多模态类的生成非常感兴趣。刚才也在听,感觉收获非常大。感觉视觉生成还处于一个继续向上爬坡的阶段。应该在 25 年会有一个更大的进展。
CSDN: 今天整个 B 会场都是关于多模态视觉生成的内容。我们进入第一个话题:3D 生成现在进行到什么状态?
郭春超:在这一波生成式 AI 大模型的浪潮中,语言模态无疑是起步最早、发展最成熟的。大众真正开始接触这类技术,大多是从 ChatGPT 开始的,也正是以大语言模型为代表的技术最先实现了较高的可用性。
相比之下,3D 生成算是一个相对年轻的方向。学术界大约在 2022 年 9 月左右,才开始出现像 DreamFusion 这样的早期工作。2023 这一年,学术界的研究热度迅速上升,而真正进入工业界的落地探索,基本是在 2024 年才开始。如果从工业界大规模投入的时间来看,到现在也只有一年出头。
所以整体来看,3D 生成目前仍处在发展的早期阶段。如果我们把当前大语言模型的任务处理可用度视作 90%,那么 3D 生成这个模态可能还处于 50% 甚至更低的水平。但它的发展速度非常快,整个领域正在迅速爬坡中。
CSDN: 现在 3D 生成跟早期 AI 生成一样,有一种开盲盒的感觉。像今天的GPT-4o,还有后面 Gemini 3 出来之后,它生成的内容,虽然图像生成已经进化到多模态阶段了,还是要试很多次,反复试错才能得到满意的图片。在 3D 生成方面,用户想要精准控制,但有时也想要 AI 带来意外惊喜,偶尔生成一个高质量的 3D 模型。你们是怎么平衡生成结果的可控性和随机性的?
郭春超:对于可控性而言,有很多种途径,例如把 2D 的结果和 3D 相结合。我们在做文本生成 3D 的时候,可控性相对会弱一些,因为普通用户很难描述得详细、专业。此外它也考验模型的理解能力,也就是指令跟随的能力。对于图像生成 3D,它的跟随度和可控性会更高一些。
对于专业人士,他用图片生成 3D 的情况会更多。普通的小白或者只是过来体验一下,大家可能用的文本生成多一些。文本生成的多样性和惊喜会更多一些。图像生成更多的是要求跟原图的指令遵循度,也就是图像作为 Prompt 输入时,要有更高的还原度。
专业人士可能图像生成 3D 更适合。除了单图生成,我们在可控性方面也做了多图生成。例如很多设计师会自己先有三视图,基于三视图再去生成三维资产,可控性会得到进一步提升。
CSDN: 对于比较专业的用户,包括我看网友评论,他们在体验 3D 生成模型过程中,模型生成出来只是第一步,他们更关心 AI 如何融入现有的工作流程,比如现有管线。未来有没有可能实现更深度的融合,比如现在已有 3D 编辑功能,想要进一步深入到流程自动化,例如 AI 可以辅助拓扑或展 UV,实现这个的瓶颈在哪?
郭春超:这个问题比较专业了。三维资产可以理解为两大类用途:
静态资产,比如 3D 打印、摆放类场景。生成后可以直接用,不会考虑很强的布线、拓扑以及下游的骨骼绑定、蒙皮、驱动等动画需求。对这类静态资产,目前 3D 生成的可用度比较高。
动态/专业资产,对 CG 管线要求更高。围绕整个 CG 管线,我们也做了很多 AI 模型。比如主持人刚问的拓扑生成,我们就发布了一个基于自回归架构的拓扑大模型(CVPR 2025 论文)。后续的骨骼绑定、驱动等动画环节,也都有对应的 AI 技术在研发。
所以,从“可见”到“可用”,虽然还不像大语言模型那么成熟,但我们已经解决了一部分 CG 管线问题,后续的 AI 化浓度会越来越高。
CSDN: 所以现在想要落地到工业级生产,还是有很长一段路。比如一说到 3D 生成,我们可能就想到游戏或电影,今年比较典型的就是《黑神话:悟空》,这种非常精细的建模,可能距离完全靠 AI 难以实现。但对于完全没有 3D 基础的用户,比如只想给自己社交媒体做个 3D 头像,或者做个简单 AR 滤镜,现在的体验是否足够傻瓜化?它最大的障碍是什么呢?
郭春超:在海外,3D 用户群体是很大的,国内正处于一个普及阶段。对于普通用户而言,现在的 3D AI 能力很大程度上能满足需求。大家有时会做一个虚拟个人形象、虚拟手办或虚拟宠物等等。对于这类静态资产的生成,它的成熟度在很多场合能满足。
更大的挑战在于对于专业人士,如设计师、建模师、动画师,或者用在影视级、 3A 大作里面,挑战比较大。你可以认为目前的发展阶段,对于普通用户而言,很多场合已经能满足,我们正在努力解决的是专业场景下需要解决的问题,因为那一部分背后有非常大的工业价值、商业价值。
CSDN: 3D 生成可以应用的场景很多,除了游戏娱乐,还有自动驾驶、元宇宙、具身智能都可以用到。混元有没有设想过未来美术的成本结构会有什么样的改变?通过 AI 融入进来,比如像游戏,不同类型的游戏(休闲游戏或3A写实大作),AI 生成的 3D 资产可用性会有什么差异?
郭春超:差异非常大。一个 3D 资产的市场价差从几百到几万不等,取决于精细程度和 CG 管线复杂度。
轻量小游戏:AI 最先满足道具、基础角色等需求,已“踮脚可及”。
腰部游戏:AI 可做道具辅助生成。
大制作:角色、场景地图等资产需要多轮原型迭代,AI 在原型阶段能极大提升效率、节省成本。
CSDN: 我觉得现在对独立游戏是很幸运的时代,美术素材更好做了。像混元是一个开放体验的引擎。想问一下混元在 3D AIGC 领域的商业模式打算怎么做?一直做开源吗?还是提供工具服务平台授权?或者未来会结合腾讯的生态?当年元宝的发布会,最深的感觉是它把腾讯的全生态接起来了,很厉害。混元 3D 会朝这种方向发展吗?
郭春超:我们会多条腿走路这样布局。首先作为腾讯的官方大模型团队,它要服务公司内的很多需求,因为腾讯是一个业务非常广泛的互联网公司,公司内的很多需求混元要去比较好地支持。此外,我们作为一个基础大模型的研发团队,也要积极回馈社区。
整个混元的各个模态,我们一直在持续开源。开源和商业价值之间并不是矛盾,而是互相促进。举个例子,我们开源了 3D 生成模型之后(目前已开源两代模型),开源完第二代之后,效果非常好。业界社区给我们反馈很多问题,甚至有人去部署发现了一些待解决的问题,以前我们自己都没发现。在社区里,这些问题反馈回来到我们这里,会成为我们的研发点。业界会搭建很多工作流、做很多配套插件,这些插件有时我们自己做研发时也会复用。开源对于商业价值是赋能的,它既促进了我们的提升,同时也帮着把生态建设得更加完善。我觉得开源和商业之间是相互促进的作用。
CSDN: 3D AIGC 是比较新的领域。您认为对比相对成熟的文本和 2D 图像生成领域,开源在早期对 3D AIGC 发展更重要,还是技术更成熟后开源更好?
郭春超:开源肯定是持续性的。像现在大家接触到最成熟的模态是文本,其次是图像。但是,这些都是站在前人肩膀上一步步发展起来的。如果没人先去做社区开源以及把社区繁荣起来,后面就比较难再发展壮大。每一个基建、每一个配套都要自己从零去搭,社区就基本不太可能繁荣起来。所以可以看到,越是成熟度高的领域,开源模型反而越多。
大家可以看到文本和图像的开源模型是非常多的。视频类目前也有这个趋势,前两年视频生成还不太成熟,但前两年陆陆续续学术界、工业界都有一些视频生成模型在开源。我觉得开源是这个领域能够繁荣的很重要的催化剂,不是要等到非常成熟才开源。相反,如果前面没有开源,有一家突然做出来非常成熟的,很可能会选择闭源,直接走商业化路线。
CSDN: 这会遇到一个跟前几个领域殊途同归的问题:数据怎么来?开源项目通常如何解决数据来源问题?尤其是 3D 比较特殊,像以前有 LAION 做图像数据集,还有 AlexNet,都是社区驱动的数据贡献。但在 3D 领域,懂的人相对少一点,这是否可行?
郭春超:3D 最开始是在爱好者和设计师群体,或是游戏、动漫等行业的从业者这里需要用到。3D 资产,它不能通过摄像头(像我们用的手机)直接拍出来,更多需要艺术家手工建模。可以理解为它是一个劳动的结晶,不像图片拍一张就唾手可得。3D 是一个复杂劳动的结晶,所以必然存在数据量相对比较稀缺、比较少的问题。目前工业界往往可用的在千万量级。3D 资产,对于图片这个领域往往可以达到百亿级别以上。大家可以看到有三个数量级的差异。
但虽然数据稀缺,可以从两方面去进一步做探索。一方面是如何提高数据利用率。现在绝大多数的 3D 模型,还有 3D 的表达方式(3D的encoding方式),并没有把 3D 数据发挥到极致。哪怕只有几百万模型,只要数据用得好,也能训练出很好的模型。但目前三维数据的表达、模型对数据的利用率都还没做到很好,这是可以探索的第一条路。
第二条可以探索的路是提升现在模型的复用率。举个例子,现在模型很多时候大家是把它整体拿过去,但对于3D模型而言,它就像我们演播间一样。三维的东西都是可拆卸的,例如这个桌子可以搬走。如果把这些元素都能充分用起来,例如充分拆解、组合,数据又会大好几个量级。这是可以探索的第二条路。
CSDN: 开源相关的话题会延伸到当前很多公司都在讨论的一个问题:它的护城河在哪?特别是对于 3D 生成,你刚才说它比较早,有没有思考过未来护城河会在哪?
郭春超:开源模型既是对社区的回馈,也是对每个技术研发团队的一种鞭策。业界有了一个开源模型,它会成为业界的一个标尺。大家站在这个标尺之上,一定会更进一步,而不是往回退。这种一代代的更新,必然会促使这个领域、也促使自己团队往前走得更快。大家可以看到硅谷的很多开源,或是他们自己模型的发布,例如谷歌发了一个,OpenAI 就会继续加快研发节奏,很快也会再发一个版本。再后面可能Meta也会再发新版本。整个AI大模型领域都是你追我赶的状态。有开源放出来,就是在加速技术的发展,让这种你追我赶的状态速度更快一些。
至于护城河,我觉得在现阶段对各模态而言,只有持续迭代模型,让模型进化速度更快,这才是真正的护城河。
CSDN: 现阶段可能是共识。您觉得开源模型会成为 3D AIGC 的主流吗?(因为开源方面,感觉腾讯更新比较勤,只了解腾讯)。还是会像文本模型一样,与高质量的闭源模型长期并存?
郭春超:很可能是并存的方式,这在各模态目前都是这样。今年肯定会是 3D AIGC 发展很快的一年,很可能接近可用性的临界点。目前我们内部已经在用了。只不过,大家可能看到对于专业人士而言,从专业人士的评价来看,它的可用度还不够。但它其实是一个农村包围城市的路线,逐步渗透。在很多需要用 3D 的领域,实际上已经用起了我们的 API 或开源模型。
我们也在像爬山一样,往更高的半山腰甚至山顶去爬。在这个过程中,一定是一个技术和业务双向匹配、双向驱动的阶段。开源模型或闭源模型,只要能让3D领域继续往山顶爬,我觉得对整个行业都是有利的。
CSDN: 刚刚在讲的过程中提到腾讯最新拓扑大模型用的是自回归架构。我觉得今年特别惊喜的一件事,特别是在多模态领域,大家发现自回归模型居然也能做图像,甚至可能做 3D。以前有个刻板印象:语言是离散的,token 是离散的,适合用自回归;图像是连续的,适合用扩散模型生成。在生成式 AI 发展早期,很多研究者觉得这是刻板印象。最近 GPT-4o 出来,它在图像生成上的进步,比如对文字渲染能力(英文基本达到完美,中文也在跟上)的提升很显著。未来您怎么看扩散 VS 自回归?这个技术路线在 3D 生成上的根本差异和未来潜力是什么?是否存在一个最优架构,还是会像现在这样并存?
郭春超:实际上各模态之间技术可以借鉴。自回归模型在语言模型上用得最早。语言模型也是所有模态里在生成式 AI 中起步最早的,它踩了最多的坑,也取得了现在最高的成熟可用度。
对于视觉类生成,后面自回归(Autoregressive, AR模型)在里面扮演的比重会越来越大。对于视觉,目前一个比较大的趋势会把 AR 和 Diffusion 做结合使用,会有更高的可控性、更好的记忆能力。因为大语言模型这种架构天然具备较好的记忆窗口。通往 AGI 的路上,像人类一样,记忆是做推理的基础,是能够具备智能的基础。所以,视觉模型如果想变得更智能,离不开非常强的记忆能力。否则如果只是硬去拟合数据分布,对数据的需求量是无穷的,且对数据的利用率比较低。因此我个人非常看好自回归(AR模型)和 Diffusion 相结合,甚至 AR 起到大脑的作用。
CSDN: 现在形容文本模型有个很典型的用户体验:如果 AI 生成结果不是我想要的,我就会像甲方一样一直提需求,一直问,直到得到想要的结果。这是推理模型出来后特有的用户体验。如果多模态模型(图像和3D模型)引入自回归模型后,就会有多模态推理。这方面怎么发展?未来是不是也可以像甲方一直提需求?就像今年《哪吒2》电影花絮里,一群特效师在那抠特别久的细节快疯掉了。未来是不是疯掉的变成 AI?我们一直提需求,让它一直改 3D 模型,实现精细化?
郭春超:这种产品和技术肯定会出现。因为您刚才提到的实际上就是大语言模型的多轮对话,这也是为什么大家这么强调其记忆能力的原因,只有在多轮磨合中才能一步步达到人真正想要的结果。在大语言模型里实际已经走通这条路,对于其他模态而言,走这样的路线也是必经之路。只有这样才能解决您最开始问的问题:怎么样提升抽卡成功率?怎么样让结果更符合我的需求?实际上就是要在一轮轮描述中,把我想要的保留,把不想要的部分修改掉。这类技术一定会成为各个厂商努力研发的点。
CSDN: 这也很让人好奇一点,它对现有技术栈的影响会怎么样?未来如果真的走向 AR 主导(自回归主导),对我们目前大部分公司基于 Diffusion 积累的技术、工具链还有经验意味着什么?是需要彻底革新,还是可以在现有技术上平滑过渡?
郭春超:实际上对于算法模型团队而言,我觉得相对还好。更多是借鉴 LM 踩过的坑,然后把这两类技术做结合。但是对于一些硬件厂商而言,可能影响会大一些,因为它配套的生态、配套的库,就需要做很大的改变,因为上层模型其实转身比较快。越往基层、越往 Infra 层级走,转身会越慢一些。我觉得这类技术一直在快速变革,对于最上层的模型团队而言,相对成本反而没那么高。可能对于 Infra 这一层,挑战会更大一些。
CSDN: 主要是对基础设施的挑战。具体来说,通常认为 Diffusion 采样比较慢,AR 训练比较难(长期练一代)。在 3D 生成这个复杂任务上,这两种路线在训练和推理的成本效率各自表现如何?未来哪种路线可能会在效率上取得突破?
郭春超:目前看,在推理速度上肯定是 Diffusion 更快,因为它相当于一次就生成了。而自回归路线是要一个一个 token 去生成。面片数多的话,时耗肯定会比较长。这类也是需要业界继续突破的点。至少如果对速度要求比较高,目前还会是 Diffusion 占据最主要的应用范式。
王启隆: 未来我们想做,比如 3D 生成有很多应用场景,甚至包括具身智能、世界模型。您看到 AR 在哪方面潜力,它与大语言模型、世界模型的结合更有前景?要实现这一转变需要哪些关键技术突破?
郭春超:实际上现在多模态模型,最开始是基于文本和语音,统一这样一维信号。目前已经能把图像结合得非常好,就像这次 GPT-4o 出来,把生图从原来的“可以看”提升到“高可控地使用”。这是一个非常大的里程碑,相当于把二维信号也统一进来了。再往后,视频可以理解为像 2.5 维。3D 可能是三维。我们真实世界,就像您提到的世界模型,到真实世界可能是 4D,因为它既有空间又有时间。
所以,多模态模型其实也像爬山一样,爬到半山腰的状态。接下来一定是各模态分别在各领域有贡献,最终形成多模态各模态的融合合力,才能达到我们预期的世界模型的智能。因为世界模型目前还没有非常严格的统一定义。但它最终很可能是需要各模态都达到非常高的可用度,才能做成完全符合世界规律并具备智能的世界模型。现在虽然各家都在提世界模型,但其实都处于比较早期阶段,可能能在局部做到符合规律,但要做到完全智能,可能还有比较长的路要走。
CSDN: 要生成符合物理规律、时空连续的 3D 场景交互,AI 就需要具备对物理世界的理解。目前 AI 在这方面的能力如何?这也是具身智能前沿领域的一个思考:AI 要怎么实现对物理世界的理解?是通过学习大量数据模拟出来,还是通过底层研究?比如杨立昆喜欢提,通过大模型那条路行不通,要通过 JPA。
郭春超:关于这个,其实业界还没有特别强的共识。现在业界也有挺多世界模型的 paper,或有一些创业公司在研究世界模型。目前在我看来,更多现阶段世界模型的概念是:先能在局部、部分场合做到符合世界物理规律,就已是一个比较大的进步。它就像生成式 AI 最开始发展时,大家会认为它比较傻瓜,有时甚至会答错简单的算术题,或者容易被误导。它非常不成熟。但是可以看到经过各方面努力、整个产业协同投入,它的成熟度获得了非常大的提升。
类比于大语言模型的发展,其实世界模型也是类似的。很可能自动驾驶会做一个,纯视频模型也会做一个,再后来可能语言模型推理也会有一个。慢慢地各模态都是百花齐放的状态,最后大家站在前人肩膀上,把各模态统一,也许在某一个垂类场合,它就突然可用了,这类场合可用再复制到其他。例如现在很多提的自动驾驶领域,他们做的世界模型,很多时候也是基于文本推理、视频生成,再结合 3D 物体的生成与摆放等。我觉得世界模型的发展,一定也是农村包围城市、逐步渗透的过程。它会先做局部可用,先做部分行业垂域可用的状态。
CSDN: 能不能做一个总结:您认为制约 3D 生成效果和成熟度的关键因素,除了数据量不足,还有哪些技术难点等待突破?
郭春超:数据量是一个点,但可能并非最主要理由。因为即使只有几百万数据,前面说到,只要提升信息密度也能训出比较好的模型。我觉得现在一个很大的问题是:对于 3D 模型、3D 资产,如何提升利用率、提升密度?这一点做得还不够好。也就是说,能不能有更 Compact 的 3D 表达?能不能让模型训练更有效率?能不能基于大语言模型或图像生成的范式,真正无损地迁移到 3D 生成上?我觉得这些点,相比较数据而言,都更有可能在短期被解决。
CSDN: 请您建议一下未来开发者关注的内容。另外我很好奇一点:做 3D 生成、3D AIGC 算法工程师,是不是本身要对 3D 建模有了解,或有过 3D 业界工作经验?
郭春超:实际上原来的 3D 属于传统图形学领域,的确对 3D 类有比较多的技术栈要求。但随着生成式 AI 大模型兴起,反而对传统图形学要求在降低,对生成式 AI 模型的要求在提升,可以认为是东升西降的状态。所以,倒不一定要求有非常多的 3D 建模经验,但要求对生成式 AI 非常熟悉。可以把它理解为计算机图形学和计算机视觉的交叉学科。
CSDN: 最后请您建议:对于开发者来说,您有哪些建议?以及现在需要具备哪些核心知识储备和核心能力?
郭春超:如果是一些像咱们 CSDN 很多用户,是前端、后台这种开发的程序猿,对于这类开发者而言,我觉得例如他是一个独立的游戏开发者,熟练使用这些 API 能用就可以了,更多还是专注于自身业务。但如果他是做这方面 research 的,例如在读的博士生等,他需要多去 follow 业界前沿的 paper。因为这个领域在学术界目前非常火。他们如果想进一步发表更优质的 paper,做出业界更有影响力的工作,一定需要持续 follow 业界的 SOTA 进展。因此对于研究者,还是对于产业从业者,需要关注的点是不一样的。
CSDN: 从文生图到文生视频再到 3D 生成,AIGC 在不断降低内容创作门槛。渐渐会有一种哲学上的思考,也是对我们CSDN“人人都是开发者”的一个叩问:未来普通人进行 3D 内容创作可能会像今天用美图秀秀 P 图一样简单。那这对专业 3D 设计师意味着什么?第二,真的需要每个人都是开发者,人人都是 3D 生成的开发者吗?
郭春超:实际上,刚才主持人问对 3D 从业者什么影响?大家可以类比 2D 生图。即使现在无论是 Midjourney、混元生图还是一些其他的(如刚才提到的GPT-4o)生图接口,业界可用的已经非常多了。但是,平面设计师也没有被替代掉,仍然很多。更多是大家把它作为一个生产力工具。对于 3D 而言也是这样,它能帮助大家更快把创意落地呈现。有了 AI 工具,别的设计师用了,你没有用,生产效率可能就会差十倍。
所以大家可能更多地把它理解为:3D 设计师或 2D 平面设计师,更多是转型为最擅长用 AI,并能结合自身业务、自身 idea 的复合型人才。我觉得这可能是对设计师的影响。就像开车一样,以前都是开火车,到后来有汽车,再到后来有自动挡,再到后来有智能电动汽车,其实大家也都是在不断学习。那对于设计师而言,我觉得用好 AI,绝对对他们有助力的。
CSDN: 非常感谢腾讯混元3D大模型负责人郭春超老师的精彩对话。

2025 全球机器学习技术大会上海站已圆满结束,本次大会围绕 AI 最前沿的发展趋势与落地实践,聚焦大语言模型技术演进、AI 智能体、具身智能、DeepSeek 技术解析与行业实践等 12 大专题,邀请了超 60 位来自全球顶尖科技企业与学术机构的重磅嘉宾齐聚一堂,全面呈现 AI 领域的技术风向与应用前沿。
扫码下方二维码免费领取「2025 全球机器学习技术大会上海站」大会 PPT。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









