







【导读】在 AI 技术飞速发展的今天,跨平台的边端 AI 推理部署已成为智能设备应用的关键。本文作者以“一次开发一键部署”为目标,与团队设计开发了一款支持多硬件、灵活易用的高性能边端 AI 推理部署框架。亮点在于其高度的模块化设计,实现了算法逻辑与底层硬件的解耦,极大地提升了开发效率和算法的可移植性。对于追求高性能、高复用率的 AI 开发者而言值得一读。
本文出自 2024 全球软件研发技术大会中的演讲,同时收录于《新程序员 008》。《新程序员 008》聚焦于大模型对软件开发的全面支撑,囊括 Daniel Jackson 和 Daniel Povey 等研发专家的真知灼见与“AGI 技术 50 人”栏目的深度访谈内容,欢迎大家点击订阅年卡。
作者 | 陈晓涛
责编 | 唐小引
出品丨《新程序员》编辑部


背景介绍
视觉算法在目前的应用场景和普及程度非常高,主要包括人脸识别、扫码支付、车牌识别、无人驾驶、智能门锁、智能笔等,都是在日常生活中或多或少能接触到的。而在美团的诸多业务场景中,比如停车摄像头,电单车用户在骑行完后要还车,系统需判断还车是否符合规定,有没有停在要求停放的区域内;自动车安全员监控,类似于司机监控系统;骑行交规,电单车用户在骑行过程中,需要规范其行为,比如判断是否闯红灯、逆行等。
以上这些应用场景,其实都是基于图像分类、目标检测、图像分割、关键点检测、文字识别等诸多基础算法任务组合实现的。相同的算法任务,其算法逻辑基本一样,比如目标检测模型 YOLO,既能做人脸检测,也可以做人体检测和车辆车牌检测。基于算法任务去开发,可以大大减少开发量,提高代码复用率。
算法模型一般都运行在 NPU 上,在边端硬件层,包含了芯片、NPU 算力、推理库和量化工具等关键部分,尽管不同硬件厂商提供的推理库和量化工具各异,但它们的 NPU 一般只支持 INT8,这就要求模型必须经过 INT8 量化才能在 NPU 上跑。INT8 量化是模型生产阶段的一部分,由于每家硬件的量化工具不同,如果在各硬件平台上运行的量化模型都需要使用它们对应的量化工具,工作量和学习成本会非常大。还有一点是生产了 INT8 模型后,需要拿该模型和原始的 FP32 模型在测试集上进行精度对齐,这部分工作量也很大。
为什么我们需要实现 NPU 量化部署?表 1 显示了不同模型分别跑在 NPU 和 CPU 上的性能数据,可以看到 NPU 相对于 CPU 有数量级的性能提升。随着模型越大,性能提升越明显。在一些边端实时性要求较高的场景下,NPU 推理是必不可少的。
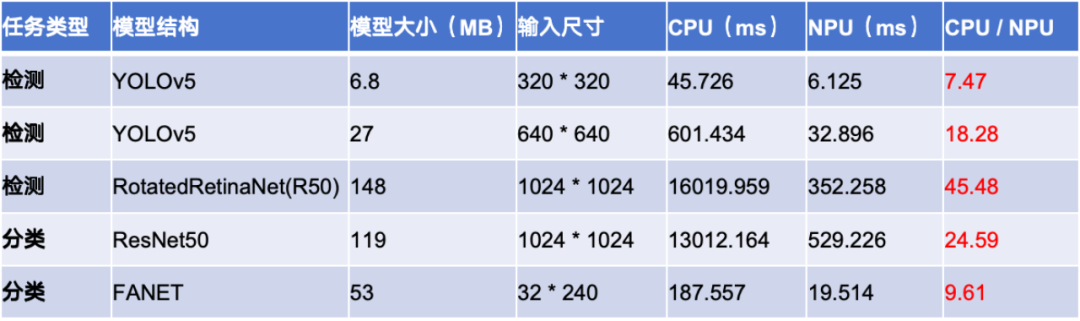
表 1 模型性能数据
而屏蔽硬件差异的必要性则有三点。首先算法逻辑本身与硬件无关,例如人脸验证算法流程(人脸检测→质量/活体判断→特征提取)中并没有硬件相关内容,所以在算法开发过程中也应屏蔽底层硬件与算法逻辑的差异。其次算法存在多端部署需求,如人脸验证在手机、嵌入式设备、地铁口和打卡机等多场景中都有应用。针对每种硬件单独开发算法工作量大,维护成本高,因此必须屏蔽硬件差异。最后,产品迭代或降本需求可能需要更低端硬件,如果不屏蔽硬件差异,更新硬件时相当于重新开发算法,成本大。
如图 1 所示的边端硬件算法部署流程,主要是量化模型生产、精度对齐和算法 SDK 开发三个部分。首先,我们拿到算法同学训练好的 FP32 模型,基于对应厂商的量化工具进行量化配置和校正数据集,得到量化模型。接着需要做精度对齐,基于对应推理库开发测试程序,在测试集上得到精度指标,判断和原始 FP32 模型的差异,确定是否达到上线要求。如果达标,基于量化模型开发 SDK 上线。如果精度不达标,需定位量化掉点问题,调整量化策略或数据集,直到精度达标。
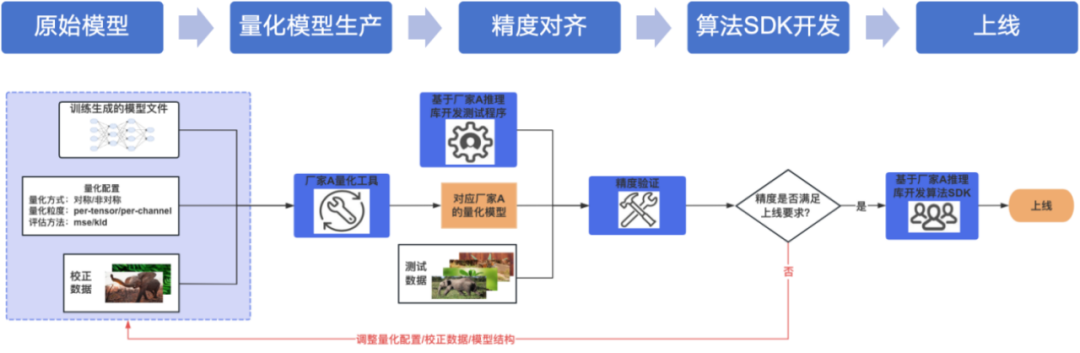
图 1 边端硬件算法部署流程
整个过程工作量包括:基于厂家的量化工具生产量化模型,基于推理库开发精度验证程序,基于推理库开发算法 SDK,以及搭建编译和运行环境。每种硬件推理库和量化工具不同,导致每种硬件都需走一套流程,费时费力,难度大。针对这个问题,我们对边端部署框架的期望就呼之欲出了:
-
首先是一次开发一键部署到任意硬件,具体部署框架需要屏蔽各类硬件推理库的差异。
-
一次量化,生产任意硬件平台量化模型:量化模型生产阶段需要一次量化生产任意平台模型,整合不同量化工具的差异。
-
简化精度对齐流程,开发简单低门槛的精度验证程序,减小对齐成本。
-
确保各类硬件性能充分释放,能够无损地配置各类硬件性能相关的超参。
综上,从不同业务需求和硬件成本等方面考量,需要在不同硬件上部署各类 AI 算法,实现一套算法一次开发后能够一键部署到任意硬件上的目标。那么,我们需要解决两方面的问题,分别是:在算法开发阶段,需要屏蔽底层硬件和算法逻辑的差异;在模型生产阶段,需要屏蔽不同量化工具的差异,同时简化精度对齐流程。
为了将算法与底层硬件隔离,使得算法可以一键部署到任意硬件,我们设计开发了一款支持多硬件、灵活易用的高性能边端 AI 推理部署框架。该框架可极大提高算法部署效率,具有高度可扩展性,可持续新增新硬件和推理后端。目前框架已支持分类、检测、分割、关键点、OCR 等主流视觉任务的 AI 模型,支持的硬件包括瑞芯微 RV1106/RV1126/RK3588、爱芯 AX620U/AX650N、全志 V851、Android Arm 等 7 大类常见硬件。

框架设计与实现
如图 2 所示的整体框架架构图,底层是各类硬件平台,上层是不同系统平台,再之上是各类硬件提供的推理库、封装的 MTBase 推理抽象层,到基于 MTBase 开发、实现与底层硬件无关的基础算法。业务 SDK 基于算法核心模块开发,关注业务逻辑实现。其他部分包括数据处理部分的预处理和后处理实现,工具组件的 MTNN-IoT 量化工具、Python 推理工具、交叉编译工具等。
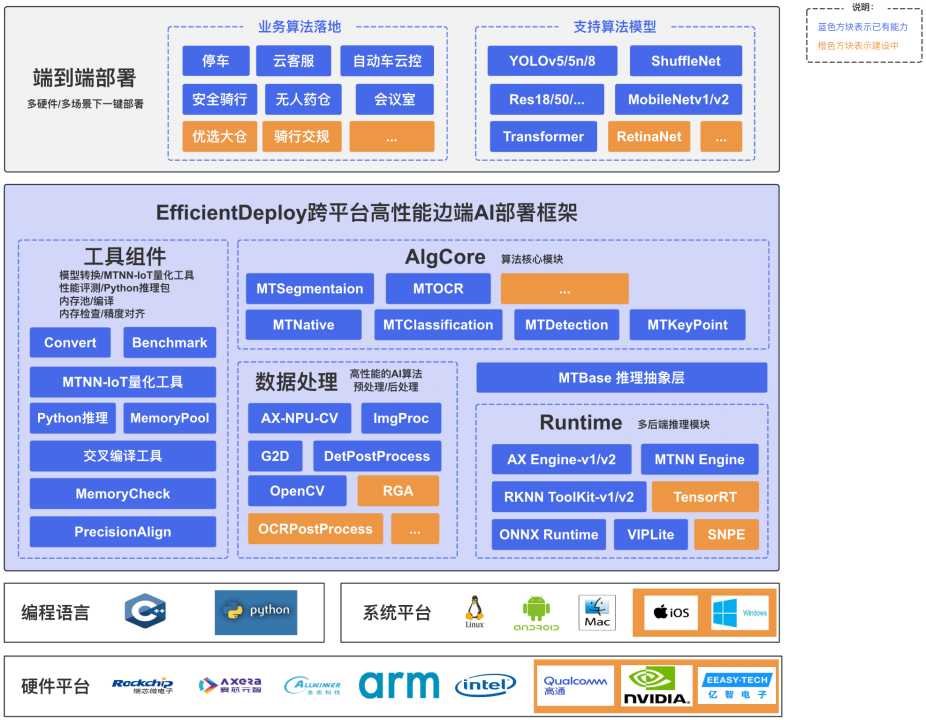
图 2 整体架构图
前面我们所说的对边端部署框架的四点期望是如何实现的呢?
-
屏蔽硬件推理库接口的差异,在 MTBase 推理抽样层,将底层硬件推理库和上层算法实现完全屏蔽开。
-
统一整合硬件量化工具,通过 MTNN-IoT 量化工具实现。
-
简化精度对齐流程,通过 Python 推理包实现。图 1 的边端硬件算法部署流程中提到,精度验证需要基于厂商的推理库去开发对应的 C++程序跑测试集的精度,而现在我们通过一个 Python 推理包就可以完成这项工作。
-
最后是无损配置各类硬件性能相关的超参。
接下来我们详细来看各模块的具体实现。首先是业务算法如何屏蔽底层硬件差异,我们采用如图 3 所示的三层结构。底层是各类硬件厂商的推理库,通过 MTBase 推理抽象层屏蔽硬件差异。在核心算法层包括分类、检测、分割、关键点等任务,基于 MTBase 开发,天然地与底层硬件无关。由于 MTBase 只包含基础推理的一些功能,结合数据处理就能够组合出分类、检测、分割算法。业务 SDK 层基于算法核心模块开发,关注业务逻辑。这三层是解耦开的,每一层的模块都能够独立扩展,MTBase 新增新硬件后端,AlgCore 新增算法任务,业务 SDK 新增业务。
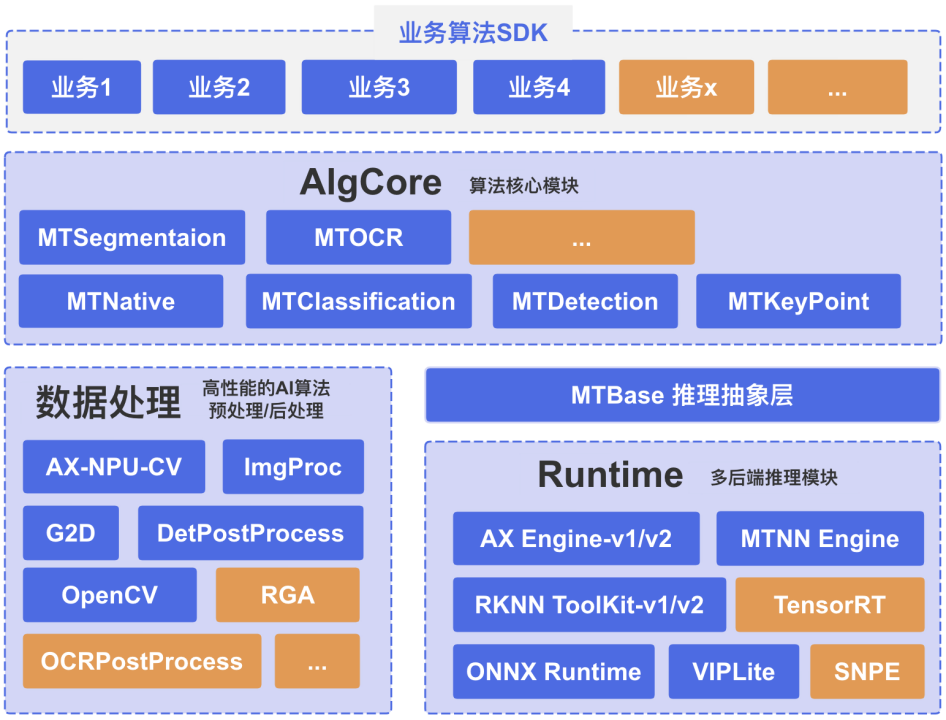
图 3 业务算法三层架构
接着我们来看一下具体设计,如图 4 所示,在 MTBase 接口层,通过实现 MTBase 接口屏蔽硬件差异,新增硬件后端简单高效。接着在基础算法模块 AlgCore 层,基于 MTBase 接口串联算法逻辑,接口类似,包括 load model、inference、destroy 等。不同算法任务后处理有细微差异,通过新增对应的子实例支持。上层业务接口一致,方便业务算法层调用。到业务层,基于这些基础的算法模块,只需要关注自身的业务逻辑,无需关注算法任务底层的实现逻辑。
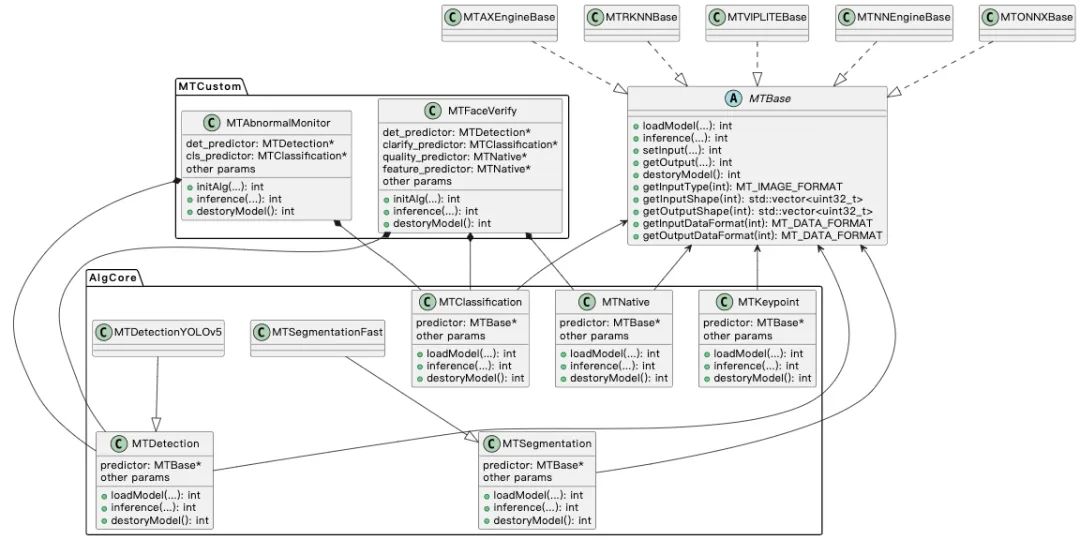
图 4 具体设计
为什么我们需要 MTBase 接口?我们有大量的接口主要是为了方便基础算法层获取模型信息,适配不同硬件模型差异,比如瑞芯微、爱芯、全志等的硬件类型、数据排布、输入图像格式、输出数据类型等都有差异。对于基础算法层拿到底层硬件给的 Tensor 后,如何正确地进行解析?就需要通过这些接口拿到对应的信息,从而完成解析工作。
在 AlgCore 基础算法模块方面,具体实例包括:
-
MTNative:适用于无后处理模型,如特征提取。
-
MTDetection:适用于各类 YOLO 模型,包括 YOLOv5、YOLOv8、YOLOX 系列模型。
-
MTClassification:适用于任意单输出分类模型。
-
MTSegmentation:适用于单输出的分割模型,这里有两个子实例:SegNormal,基于浮点输出 upsample 到图像的模型输入的尺寸,再逐像素地做 ArcMax;SegFast,基于 INT8 输出直接分割,不做 upsample,分割的精度指标可能会掉一点。
各类子实例对外接口相同,上层业务只需要基于不同模型的性能考虑,选择最优任务子实例实现业务逻辑的串联即可。
在数据处理层面,主要包括如图 3 所示的 7 个部分。ImgProc 是我们维护的一套 C++源码库,包含图像格式转换、缩放等基本操作,给各类硬件提供基础的图像处理功能;AX-NPU-CV(爱芯)、G2D(全志)、RGA(瑞芯微)是对应的硬件厂商提供的图像处理单元;裁剪后的开源 OpenCV 库支持多平台;DetPostProcess 是我们整合的各类检测算法相关的后处理,包括 NMS、generate-proposals、数据格式转换等;OCRPostProcess 是文字识别算法相关的后处理实现。
需要特别说明的是,ImgProc 支持全平台,当我们新增硬件实现在 MTBase 里,结合 ImgProc 就可以把上层所有算法一键部署到新硬件上来,非常高效。但当你追求极致性能同时希望降低 CPU 利用率时,ImgProc 就不太适用,这时可以替换成对应硬件厂家特有的图像处理单元,代替 ImgProc 进行图像处理。在某些存储和内存受限的极低端的设备上,可能会受设备存储、内存限制,无法引入第三方库,比如即使是经过裁剪后的 OpenCV 库可能也有大几十兆,在一些比较低端的芯片上,由于成本考虑是不允许被引入的,这就要求我们对相关的实现都自行去实现对应的一些前处理后处理的逻辑,所以在整个库里许多传统的图像处理算法都是自己用 C++实现的。
硬件性能如何充分发挥?一个原则是基于 EfficientDeploy 开发的算法性能,要与基于原生推理库开发的算法性能基本一致。这就要求我们需要能够无损配置各类硬件性能相关的超参。比如瑞芯微 RK3588、爱芯 AX650N 的 NPU 是多核结构,那么影响它们性能相关的因素就是 NPU 核数,可以配置模型跑几个 NPU 核或者跑在哪个 NPU 核上。由美团内部维护的推理引擎 MTNN-Engine 支持 CPU、OpenCL、DSP,同样也需要能进行对应配置。ONNXRuntime 的可配置参数是 CPU 线程数,我们通过 Engine Config 就能配置相关超参。
在编译工具链方面,不同硬件有不同的硬件架构、系统平台、编译工具链。由于需要整合这些差异,我们自行开发了一套交叉编译工具。如图 5 的第一个示例,编译云客服算法到 RV1126 上,只需要指定系统平台、推理后端及算法,就可以一键编译。

图 5 编译示例

模型生产和对齐
在模型生产和对齐方面,首先是 MTNN-IoT 模型量化工具,如图 6 所示,前面我们提到不同硬件厂商的量化工具、使用方式都不一样,这必然导致学习成本和生产模型成本成倍增加。其次,虽然工具不同,但量化原理和输入信息类似,比如都需要输入量化配置,告诉工具是需要做对称还是非对称,INT8 还是 INT16,还有量化数据集。通过整合不同硬件的量化工具,统一输入格式,从而在模型生产阶段,达到了一次配置就能生产任意硬件模型的效果。
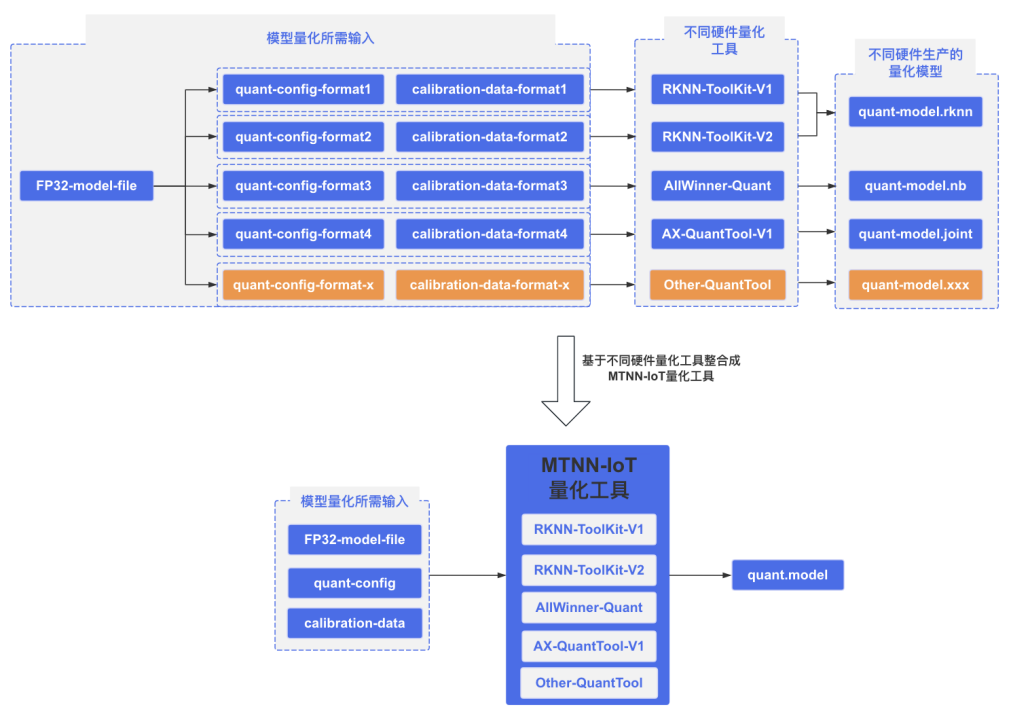
图 6 MTNN-IoT 模型量化工具逻辑
量化模型需进行精度验证,难点在于算法同学没有 IoT/C++开发经验,开发测试程序难度大,而推理部署同学对算法了解不够,无法自行评测各类算法精度指标。为此,我们开发了一个 Python 推理包 PyKit,方便算法同学在 Python 层将量化模型跑在对应硬件上。
参见图 7 的 PyKit 示意图,右边是我们部署在各类硬件上的服务器,能响应各类算法任务,算法同学在客户端通过一些简单的 API 就能将量化模型以及图片数据网络传输到对应服务器,服务器完成推理将结果返回。这样做的好处包括:开发工作量小,在 AlgCore 基础上只需要增加网络响应代码就能搭建出服务器;一次开发,支持任意硬件部署;算法同学可复用 Python 评测代码。
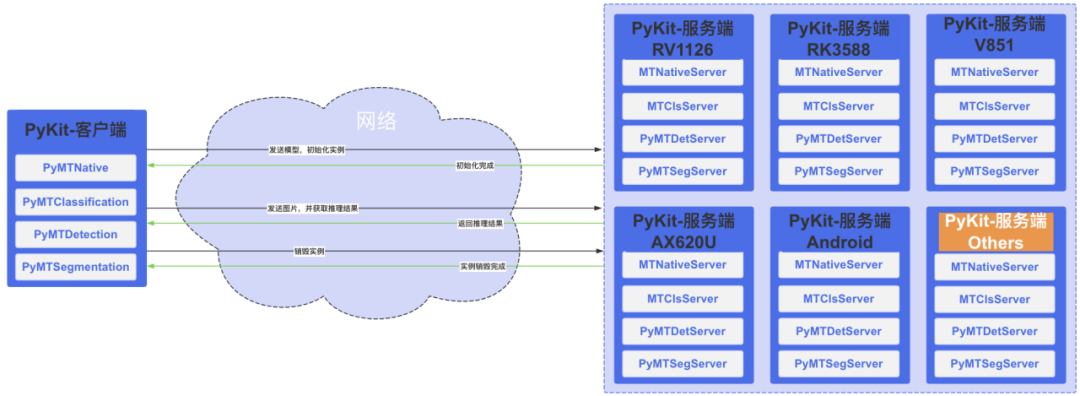
图 7 PyKit 示意图
PyKit 里有 5 个主要实例,分别是:评测任意模型推理性能的 benchModel,支持 AlgCore 中 Native 实例推理的 Native,支持 AlgCore 中 Classification 实例推理的 Classification,支持 AlgCore 中所有 Detection 子实例推理的 Detection,支持 AlgCore 中所有 Segmentation 子实例推理的 Segmentation。
在此以一个具体的检测算法实例来看,包括加载模型、初始化连接、推理和销毁,图 8 的代码是一个具体的 Demo,通过检测算法的类型得到一个检测算法的实例,连接远程的硬件后加载模型,就可以读取图片、推理得到对应结果,继而做对应的精度指标的计算或可视化,最后对实例进行销毁。
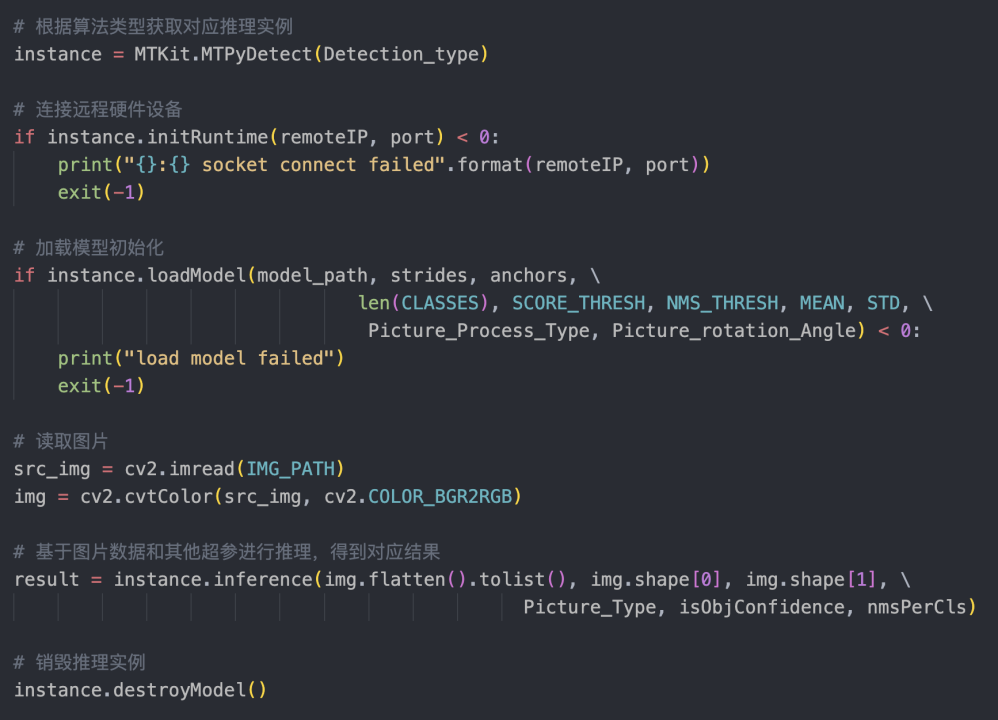
图 8 PyKit 实例
在量化模型生产过程中,我们也遇到了一些非常棘手的问题。最主要的就是算法同学提供的原始模型,很多是无法直接量化的,一是算子不支持,因为硬件厂商的工具链完备性没办法和 TensorRT 相比,必然存在一些小众的算子不支持。二是存在精度掉点的问题,可能是工具链存在 Bug 或算子本身不适合量化导致的。对此,我们的解决方案是对模型进行裁剪,有一些关键逻辑我们在 C++中自行实现即可。

性能优化
性能优化首先是对硬件预处理的优化,表 2 列举了我们在全志 V851 和 AX620U 上的一些性能优化数据,可以看到在不同的预处理方式下,用 CPU 预处理和用硬件预处理的性能耗时基本都是减半的状态,并且 CPU 利用率显著降低。因此在对性能有极致要求的情况下,我们就可以用对应厂商提供的硬件预处理来提升整体的推理性能,但其劣势在于不同厂商的硬件预处理不同,导致我们需要针对不同的硬件厂商各自优化,开发成本相较而言会更高。
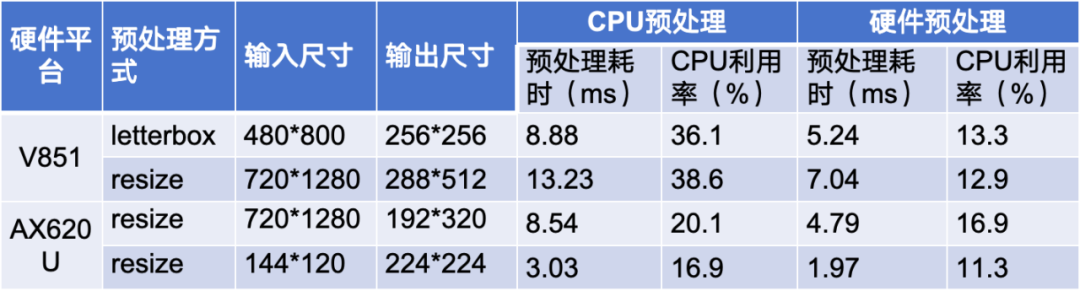
表 2 硬件预处理性能优化数据
第二点是 RK3588 多核推理,RK3588 是多核结构,有三个核,每个核有两 T 的算力,总共算力有 6T。表 3 展示了我们的实验数据,我们的一个算法模型跑在一个 NPU 核上,它的推理耗时是 32.581ms,NPU 利用率为 44%。当我们把一个算法模型跑在 3 个 NPU 核上时,性能反而降低很多。这就说明 RK3588 单模型跑在多核上性能是明显下降的,而单模型跑单核的性能是最优的,那么如何充分地利用它的多核能力?很自然的想法是起三个实例分别跑在对应的 NPU 核上,每个实例的耗时与单实例跑一个核类似,吞吐量就能提升三倍。由此验证,通过多实例跑多核,可在不影响时延情况下,显著提升推理吞吐量。后来经过我们再实验发现,NPU 利用率其实还是没有打满,主要是因为模型较小,这种情况下,一个核上跑多个实例性能也能成倍提升,同时也不影响推理耗时。即 NPU 利用率如果没有达到 90%以上的话,完全可以把多个实例跑在一个 NPU 核上。
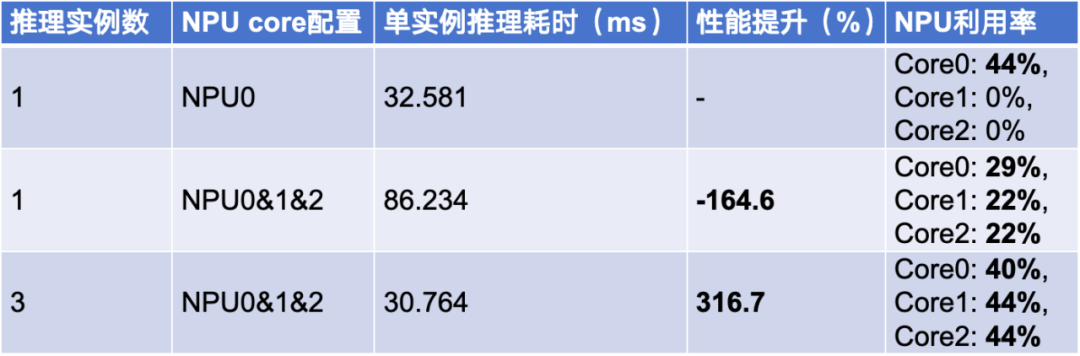
表 3 RK3588 多核推理数据
第三是多模型共享内存的优化,其原理是多模型复用推理过程中的临时 buff,如计算 buff、输入输出 buff 等。表 4 是我们在 V851 上的一些实验数据,比如我们需要跑 5 个模型,单独跑的话总内存占用为 39.3MB,而通过共享模式跑的话内存占用就变成了 33.4MB,整体降低 15%左右。为什么我们要通过共享内存的方式?核心在于 V851 设备较为低端,总内存仅为 64MB,要跑 5 个模型必须要做这样的优化。
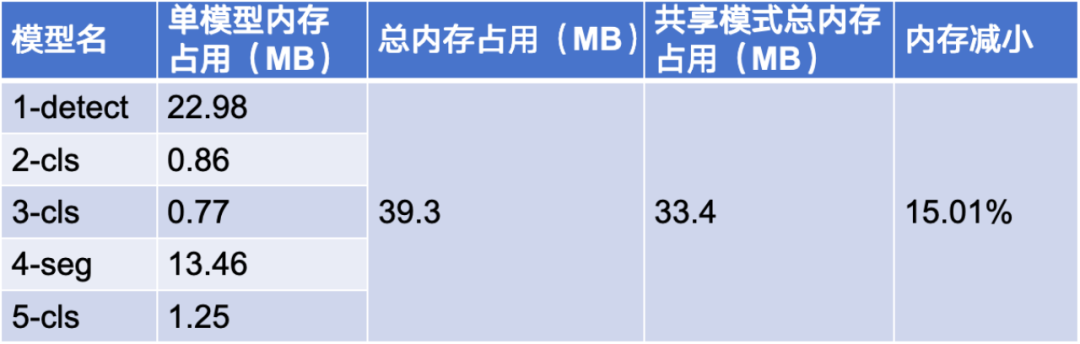
表 4 模型内存占用数据

总结与展望
EfficientDeploy 是一款跨平台高性能边端 AI 推理部署框架,最大的亮点就在于一次开发一键部署任意硬件平台,将底层硬件、算法任务、业务逻辑解耦,使得各模块可以独立扩展。在模型生产阶段,统一了不同硬件的量化工具,简化了模型精度验证的工作。在工具链方面,提供统一的跨平台交叉编译工具,并对不同硬件进行针对性的优化。
目前 EfficientDeploy 主要聚焦于视觉 CNN 算法,下一步我们将进一步语音等 NLP 算法,以及 LLM 和 VLM 模型的推理部署。

大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。

注:封面图为 AI 生成


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









