







作者 | 邵浩,上海瓦歌智能科技有限公司总经理,狗尾草科技人工智能研究院院长
责编 | 许爱艳
出品 | AI科技大本营(ID:rgznai100)
一、引言
最近,很多人邀请我回答下面的这些问题:
“人工智能能否取代人类?”
“十年内,人类是否能制造出贾维斯那样的AI?”
“人工智能什么时候才会拥有自我意识?”
为什么大家对这类问题如此感兴趣?这可能要追溯到2016年,AI真正进入到大众视野并引爆媒体的标志性事件,也就是AlphaGo战胜围棋的世界冠军-李世石。在之后,我们看到一个又一个AI技术的突破,以及不断被刷新的媒体头条,好像AI取代人类是完全可能而且理所应当的事情。
我们看到波士顿动力的机器人行云流水般的后空翻,看到索菲亚在各大场合欺骗人类感情,看到Dota2、星际争霸等游戏被AI攻破,也看到IBM的辩论机器人和人类旗鼓相当的交锋,在2019年7月份《Science》发表的研究成果中,一个名为Pluribus的算法仅仅通过自我博弈,就在多人无限注德州扑克中战胜了人类专业选手[1]。人工智能在这第三轮的热潮中,通过大数据和深度学习,创造了一项又一项历史,也吊足了普罗大众的胃口。
人工智能从1956年被提出至今,经历了三次大的热潮。20 世纪50 年代中期到80 年代初期的感知器,20世纪80 年代初期至21 世纪初期的专家系统,以及最近十年的深度学习技术,分别是三次热潮的代表性产物。
为了回答这些问题,我抛出了一张2018年Gartner技术曲线,解释目前人工智能的进展。如图1所示。
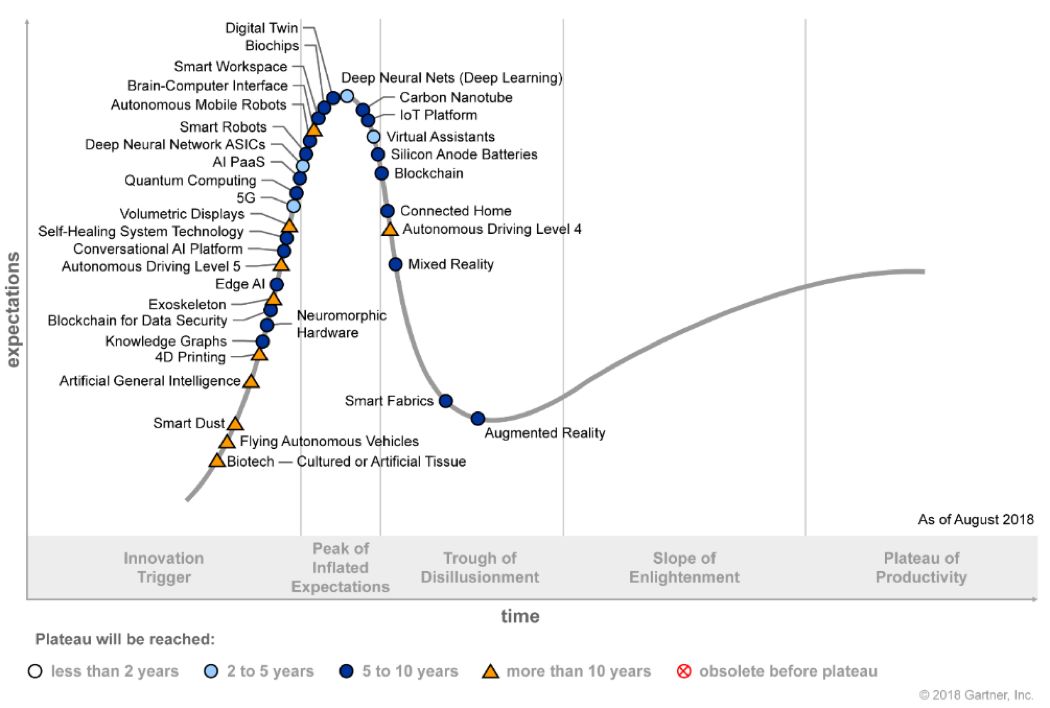
图1 Gartner2018技术成熟度曲线
Gartner每年发布的技术趋势曲线,聚焦未来5到10年间,可能产生巨大竞争力的新兴技术。在图中我们可以看到,深度学习(Deep Learning)已经走到高原期(Peak of Inflated Expectations),而知识图谱(Knowledge Graph)还是在起步阶段(Innovation Trigger),更不用说脑机接口(Brain-Computer Interface)、通用人工智能(Artificial General Intelligence)这些技术,在图中的标记还是黄色三角,也就是起码10年会后才能到达高原期。
人工智能技术远未达到媒体所宣传的神通广大,无所不能。从图1中的技术发展现状也可一窥端倪。AlphaGo可以战胜最好的人类棋手,但却不可能为你端一杯水。著名机器人学者Hans Moravec早前说过:机器人觉得容易的,对于人类来讲将是非常难的;反之亦然。
人可以轻松做到听说读写,但对于复杂计算很吃力;而机器人很难轻松做到用手抓取物体、以及走上坡路,但可以轻而易举地算出空间火箭的运行轨道。人类可以通过日积月累的学习,轻松完成各种动作,但对于机器人来讲完成这些简单的动作难如登天。专家们称此理论为“莫拉维克悖论”(Moravec's Paradox)。机器学习专家、著名的计算机科学和统计学家 Michael I. Jordan近日在《哈佛数据科学评论》上发表文章,也认为现在被称为AI的许多领域,实际上是机器学习,而真正的 AI 革命尚未到来。
在目前,即使是最先进的AI智能体,在适应环境变化的能力方面,也无法与动物相提并论。近期,英国帝国理工学院和剑桥大学研究人员共同组织了一场特别的AI竞赛,希望把动物能够完成的“觅食任务”交给AI智能体来完成,让AI和动物世界来一场虚拟比赛。我们也期待着这项比赛的结果。
因此,人工智能,任重而道远。
二、从感知智能到认知智能
业界一致认为,AI的三要素是算法,算力和数据。近十年来,人工智能的技术突破,很大程度上是得益于大数据以及大规模运算能力的提升,真正让深度学习这项“老”技术焕发了新生,突破了一项又一项感知能力。追溯到2006年,Geoffrey Hinton和他的学生在《Science》上提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督学习的训练算法;随后2012年深度神经网络技术在ImageNet评测中取得了突破性进展,人工智能进入到新的热潮,围绕语音、图像、机器人、自动驾驶的技术大量涌现,也出现了很多里程碑水平的技术。
2017年8月20日,微软语音和对话研究团队负责人黄学东宣布微软语音识别系统取得重大突破,错误率由之前的5.9%降低到5.1%,可与专业速记员比肩[2];Google在2015年提出的深度学习算法,已经在ImageNet2012分类数据集中将错误率降低到4.94%,首次超越了人眼识别的错误率(约5.1%)[3];DeepMind公司在2017年6月发布了当时世界上文本到语音环节最好的生成模型WaveNet语音合成系统;由斯坦福大学发起的SQuAD(Stanford Question Answering Dataset)阅读理解竞赛,截至2019年7月,使用BERT的集成系统暂列第一,其F1分值达到89.474,超越了人类水平。
从计算,到感知,再到认知,是大多数人都认同的人工智能技术发展路径。那么认知智能的发展现状如何?
首先,让我们看一下什么是认知智能。复旦大学肖仰华教授曾经提到,所谓让机器具备认知智能是指让机器能够像人一样思考,而这种思考能力具体体现在机器能够理解数据、理解语言进而理解现实世界的能力,体现在机器能够解释数据、解释过程进而解释现象的能力,体现在推理、规划等等一系列人类所独有的认知能力上。
也就是说,认知智能需要去解决推理、规划、联想、创作等复杂任务。我们可以大胆想象,如果机器人具备了认知智能,那么我们周围就会出现很多电影里才能看到的智能机器,比如说《银翼杀手2049》里的乔伊,《她》中的萨曼莎,以及《超能查派》里的机器人查派,这些智能机器会有意识,有情感,并且有自己的善恶观。
人类总是想当造物主,让机器拥有认知智能,其实在一定程度上是希望模仿生命本身,尤其是人类的各种能力。在维基百科给出的定义中,生命泛指一类具有稳定的物质和能量代谢现象并且能回应刺激、能进行自我复制(繁殖)的半开放物质系统。
简单来说,也就是有生命机制的物体,是存在一定的自我生长、繁衍、感觉、意识、意志、进化、互动等丰富可能的一类现象。科学家从来没有停止对生命的再造和探索,也就自然而然产生了“人工生命”(Artificial Life)的概念。人工生命可以分为两个方面,一是人造生命,特指利用基因工程技术创造的人工改造生物。另一方面则是本文所要探讨的虚拟生命(Virtual Life),特指利用人工智能创造的虚拟生命系统。(注:本文只讨论软件层面上的认知智能,因此不涉及对控制论、机器人硬件的讨论。)
三、创造具有认知智能的虚拟生命
一个具备认知智能的虚拟生命,不仅仅可以和人类进行多模态交互,还需要有具有生命感的表达能力。图2给出了虚拟生命的基本能力范畴。对于看、听、说、动作而言,感知智能已经可以达到非常好的效果。而对于推理、情感、联想等能力,还需要更强的认知能力的体现。

图2 虚拟生命基本能力范畴
那么问题来了,在现有技术条件下,是否能实现虚拟生命的认知能力?这也就是文章开头提到的问题的关注点。微软亚洲研究院宋睿华老师(微软小冰首席科学家)曾经说过一个故事,她在和母亲聊天的时候,问“如果机器人可以打败人类最顶尖的棋手,厉不厉害?”,母亲回答说“很厉害“。她再问母亲”如果我们做出一个机器人,可以和人聊天,厉不厉害?“,母亲回答说”不厉害“。宋老师就问为什么,母亲的回复是”因为不是每个人都会下棋,但每个人都会说话啊“。这个故事其实告诉我们,让机器人说话,虽然技术上非常复杂,但离人类的期望值还相差甚远。
即便是机器人可以聊天,那是不是就可以说其拥有了认知智能?答案仍然是否定的。会说话的机器很多,不仅仅是聊天机器人,智能客服,甚至是推销电话都可以做到以假乱真的程度。谷歌在2018年开发者大会上演示了一个预约理发店的聊天机器人,语气惟妙惟肖,表现相当令人惊艳。相信很多读者都接到过人工智能的推销电话,不去仔细分辨的话,根本不知道电话那头只是个AI程序。破解方法其实也很简单,问机器人一句“今天天气挺好的,你觉得呢”,相信很多推销电话就无法回答了。
这是因为在特定场景下,对话可以跳转的状态一般都是有限的,可能产生的话题分支,比起围棋的可能性要少很多,因此,即便是穷举所有的可能性,也不是不可做到的事情。如果提前设置好对话策略,加上语音合成技术,完全可以以假乱真,但一旦在开放域进行闲聊,对话的可能性几乎是无限的,场景对话技术也就无能为力了。
所以,要想真正实现具备认知智能的虚拟生命,还需要很多的技术突破,尤其是目前还不能够对人类的思维能力做到真正的理解,所以机器人就好比绿野仙踪中的铁皮人,还缺乏带有灵魂和感情的那颗心。因此,受限于目前的技术能力,虚拟生命不可能一蹴而就,而是要分步骤不断的突破技术难题。图3给出了虚拟生命不同发展阶段。

图3 虚拟生命发展阶段
虚拟生命1.0,可以看做是聊天机器人的升级版本。本阶段最重要的特点是单点技术的整合,并能作为整体和人类进行交互。从功能上来看,仍然是被动交互为主,但可以结合对用户的认知,进行用户画像和主动推荐。
我们目前正在处于虚拟生命的1.0阶段。在这个阶段,多轮对话、开放域对话、上下文理解、个性化问答、一致性和安全回复等仍然是亟待解决的技术难题。同时,虚拟生命也需要找到可落地的场景,做好特定领域的技术突破。
虚拟生命2.0,是目前正在努力前行的方向,在这个阶段,多模态技术整合已完全成熟,虚拟生命形态更为多样性,具备基于海量数据的联合推理及联想,对自我和用户都有了全面的认知,并可快速进行人格定制。实现这个阶段可能需要3-5年。
虚拟生命3.0, 初步达到强人工智能,具备超越人类的综合感知能力,并拥有全面的推理、联想和认知,具备自我意识,并能达到人类水平的自然交互。随着技术的进步,我们期待在未来十年至三十年实现虚拟生命的3.0。
本文后面的章节,就从虚拟生命1.0,也就是聊天机器人的角度,来阐述目前自然语言处理和知识图谱的技术落地,以及如何实现基本的机器人认知能力。
这两年,聊天机器人领域异常火热,原因在于我们目前所处的时代需要一个语音交互入口。从上世纪80年代至今,我们已经经历了四个技术时代,分别是PC时代,互联网时代,移动互联网时代和现在的AI时代。每一个时代均涌现了大量的科技成果,也出现了划时代的产品和伟大的公司。
其中,在PC时代,运算力改变了人类的生活,个人电脑和windows操作系统,成就了微软和IBM两个软件和硬件的巨头。在互联网时代,连接颠覆一切,人们可以通过网络随时随地进行信息交互,互联网和搜索引擎造就了谷歌;在移动互联网时代,技术带来了两大变革,一是数据利用效率的提升,导致服务发生了变化,人们可以随时随地享受即时服务,二是交互方式的改变,智能手机成为了主要的入口级设备,最具有代表性的公司就是苹果。
当人们跨越到AI时代,微软又提出对话即平台(Conversation As A Platform)的理念,认为语音交互是这个时代的入口,随着硬件和软件的成熟,人们可以采用最自然的交互方式-语音,和机器进行流畅对话,完成各种服务。也正是在这种背景之下,聊天机器人开始作为入口级产品而大量涌现。而打造聊天机器人产品,不仅需要计算机视觉、声学等技术,更进一步需要自然语言处理及知识图谱技术。
四、自然语言处理
语言是主要以发声为基础来传递信息的符号系统,是人类重要的交际工具和存在方式之一。作用于人与人的关系时,是表达相互反应的中介;作用于人和客观世界的关系时,是认识事物的工具;作用于文化时,是文化信息的载体(来源:维基百科)。语言与逻辑相关,而人类的思维逻辑最为完善。
1957年乔姆斯基的第一部专著《句法结构》出版,提出了基于普遍语法的理论核心,认为人脑有一种先天的特定结构或属性,即语言习得机制,它是人类学会使用语言的内因。而埃弗雷特通过研究皮拉罕的部落之后,认为是文化而不是遗传决定了语言,并否认了乔姆斯基普遍语法中的“递归性假设”。自然语言处理,研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,主要是计算机科学、语言学和数学的融合学科。
通过图4可以看出,自底向上,自然语言处理需要通过对字、词、短语、句子、段落、篇章的分析,使得计算机能够理解文本的意义。
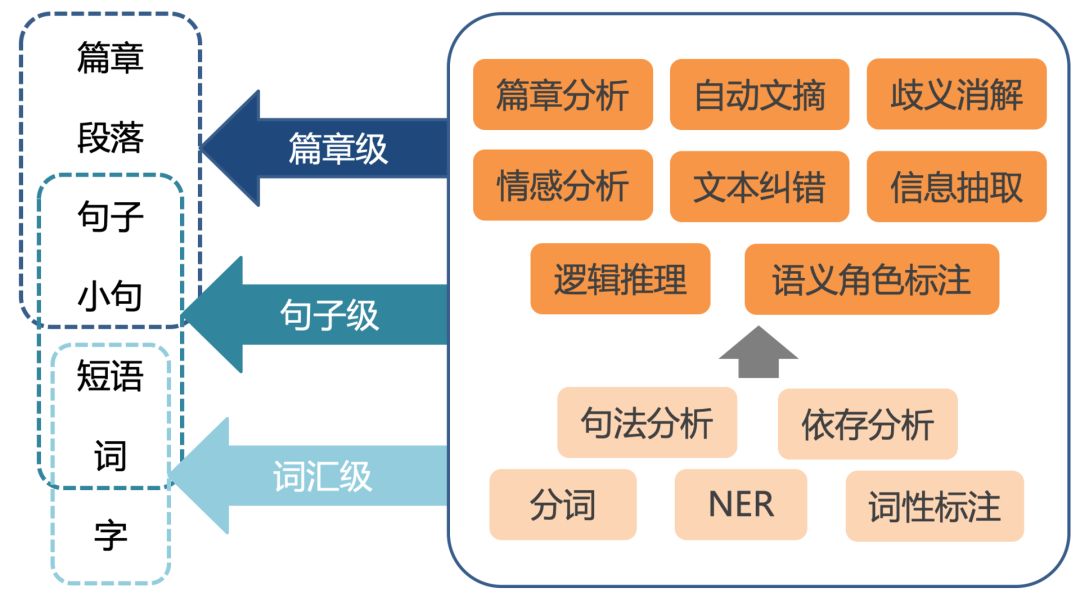
图4 自然语言技术体系
而在每一个层级上都包含大量的技术模块,比如说在词级别,需要做分词、词性标注、命名实体识别等。
由于本文主要探讨虚拟生命的相关技术,因此,在一个虚拟生命1.0框架(或者说聊天机器人)中,牵扯到的自然语言处理技术主要包括:自然语言理解,对话管理和自然语言生成。其中,自然语言理解是为了分析句子的各项含义,包括情感、意图、句型、主题等;而对话管理则是用于管理上下文、更新对话状态、进行逻辑推理等;最后的自然语言生成,用于合成自然流畅的句子,并以合适的形式进行反馈。无论是微软小冰、Siri、亚马逊的Echo,还是公子小白、度秘、小爱同学,都是自然语言处理技术的典型的产品落地体现。
比如和机器人对话的过程中,对于音乐话题的理解,就需要用到命名实体识别、实体链接等技术。举一个简单的例子,“我真的非常喜欢杰伦的双截棍”,就需要判断杰伦是一个人名,链接到知识库中“周杰伦”这样一个歌手实体,并且“双截棍”是一个歌名而不是一种器械。同时,还可以进行情感判断,是一个正面的“喜欢”的情感。
传统的自然语言处理技术,还是以统计学和机器学习为主,同时需要用到大量的规则。近十年来,深度学习技术的兴起,也带来了自然语言处理技术的突破。这一切还需要从语言的表示开始说起。
众所周知,计算机擅长处理符号,因此,自然语言需要被转化为一个机器友好的形式,使得计算机能够快速处理。一个很典型的表示方法是词汇的独热(one-hot)表示,也就是相当于每个词在词汇表里都有一个特定的位置。比如说有一个10000个词的词汇表,而“国王”是词汇表里的第500个词,那么“国王”就可以表示为一个一维向量,只有第500个位置是1,其他9999个位置都是0。但这种表示方法的问题很多,对语义相近但组成不同的词或句子如“国王”和“女王”,利用独热表示的向量内积,无法准确的判断两者之间的相似度。
2013年,Tomas Mikolov等人在谷歌开发了一个基于神经网络的词嵌入(word embedding)学习方法Word2Vec,不但大大缩短了词汇的表示向量的长度,而且能够更好的体现语义信息。通过这种嵌入方法可以很好的解决“国王”-“男人”=“女王”-“女人”这类问题。感兴趣的读者可以参考互联网上大量的关于词嵌入的资料。
计算机能够快速处理自然语言之后,传统的机器学习方法也进一步被深度学习所颠覆。相关算法在近年来的迭代速度非常快。以语言模型(Language Model)预训练方法为例,代表性方法有Transformer,ELMo,Open AI GPT,BERT,GPT2以及最新的XLNet。其中,Transformer于2017年6月被提出。ELMo的发表时间是2018年2月,刷新了当时所有的SOTA(State Of The Art)结果。
不到4个月,Open AI在6月,基于Transformer发布了GPT方法,刷新了9个SOTA结果。又过了4个月,横空出世的BERT又刷新了11个SOTA结果。2019年2月,Open AI发布的GPT2,包含15亿参数,刷新了11项任务的SOTA结果。而2019年6月,CMU 与谷歌大脑提出了全新 XLNet,在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。
除了算法和算力的进步,还有一个重要的原因在于,以前的自然语言处理研究,更多的是监督学习,需要大量的标注数据,成本高且质量难以控制,而以BERT为代表的深度学习方法,直接在无标注的文本上做出预训练模型。在人类历史上,无监督数据是海量的,也就代表着这些模型的提升空间还有很大。2019年7月11日,Google AI发表论文[5],就利用了惊人的250亿平行句对的训练样本。其应用效果我们也拭目以待。
从自然语言处理的理论发展来看,前景一片光明,但相比之下,聊天机器人产品的效果,却被无数用户所诟病。答非所问、响应延迟、误唤醒等问题大大降低了用户的满意度。随着2018年Facebook关闭其虚拟助手M,亚马逊Echo也被爆出侵犯用户隐私的问题,再加上聊天机器人实际使用效果远低于大众预期,整个行业也逐步走向低迷。
一个很关键的原因在于,媒体上对于聊天机器人的宣传,都在尝试模仿人类的对话交互。而在目前的技术条件下是无法达到的。微软亚洲研究院副院长周明博士曾经提到,语言智能可以看做是人工智能皇冠上的明珠。尝试用技术模拟人类的真实对话,在开放领域就是个伪命题。因为在人类的对话过程中,一句话中所表达出的信息,不只是文字本身,还包括世界观、情绪、环境、上下文、语音、表情、对话者之间的关系等。
比如说“今天天气不错”,在早晨拥挤的电梯中和同事说,在秋游的过程中和驴友说,走在大街上的男女朋友之间说,在倾盆大雨中对同伴说,很可能代表完全不同的意思。在人类对话中需要考虑到的因素包括:说话者和听者的静态世界观、动态情绪、两者的关系,以及上下文和所处环境等,如图5所示。
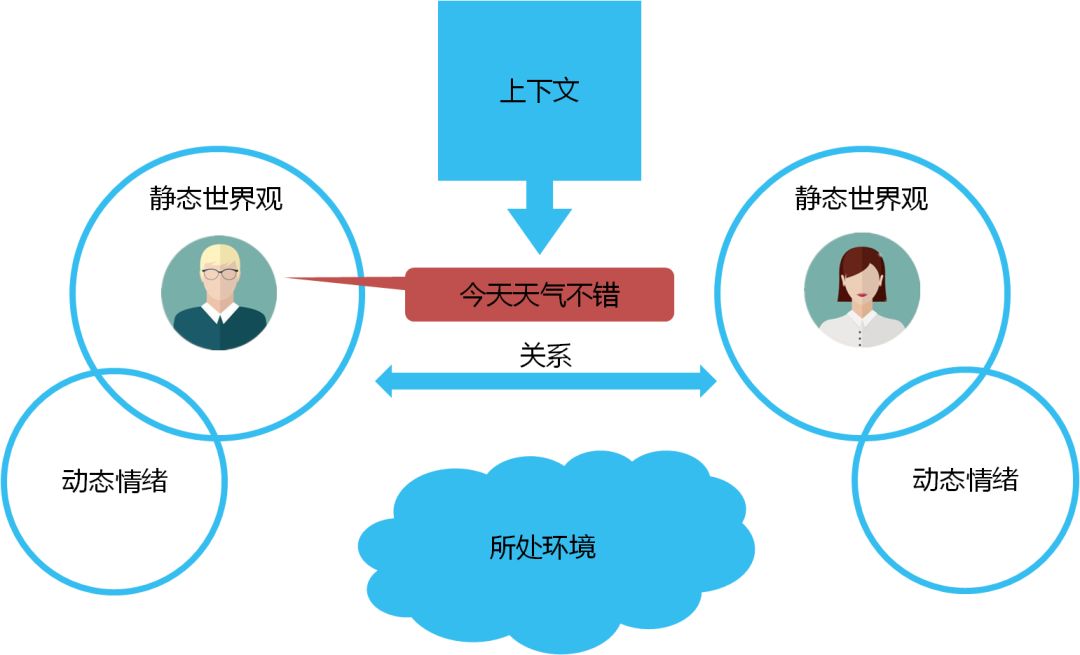
图5 人类聊天中的要素
而且,以上这些都不是独立因素,整合起来,才能真正反映一句话或者一个词所蕴含的意思。这就是人类语言的奇妙之处。同时,人类在交互过程中,并不是等对方说完一句话才进行信息处理,而是随着说出的每一个字,不断的进行脑补,在对方说完之前就很可能了解到其所有的信息。再进一步,人类有很强的纠错功能,在进行多轮交互的时候,能够根据对方的反馈,修正自己的理解,达到双方的信息同步。
再进一步,在体验模拟假说(Embodied Simulation Hypothesis)中[6],人类在进行语言理解的时候,会基于听觉、视觉以及运动等体验的模拟,来进行“脑补”。比如说当听到“绵羊有没有角”这个问题,我们会在脑海里浮现出绵羊的形象,甚至声音,再去判断它头上有没有角。
因此,在开放域的聊天机器人,寄希望于从一句话的文本理解其含义,这本身就是很不靠谱的一件事情。目前市场上大部分的聊天机器人,还仅是单通道的交互(语音或文本),离人类多模态交互的能力还相差甚远。哪怕仅仅是语音识别,在不同的噪音条件下也会产生不同的错误率,对于文本的理解就更加雪上加霜了。更别谈推理能力,仅仅通过自然语言处理技术也是无法进行解决的。
那么自然语言的生成模型是否可以解决问题呢?通过端到端的深度学习方法,我们可以做到句子的生成。但实际上,这种方法所生成的语句,还未能达到实用级别,因此本文不做深入讨论。
结合多模态识别和分析,是自然语言处理落地的新方向。举例来说,要识别一句话“你太坏了”是撒娇还是批评,如果将声音特征和表情特征结合进来,那么会很容易判断。哈工大李海峰教授也曾给出过一个有趣的例子,对于“我没有看见他拿了你的钱包“,重音位置不同,会导致不同的含义。当重音在”我“的时候,可能表示说话者没看到,但有其他人看到。当重音在”钱包“的时候,可能表示被拿走的不是钱包,而是别的东西。当重音在”看见“的时候,可能表示说话者并没看到,但有可能听说了这个事情。因此,结合多模态的自然语言处理,会大大提升多轮对话中机器人的表现。
五、知识图谱
在上一节中,我们也提到,自然语言处理技术很难解决推理问题。而推理是认知智能的重要组成部分。比如说对于问题“姚明的老婆的女儿的国籍是什么?”,一个可行的解决方案,就是通过大规模百科知识图谱来进行推理查询。
知识图谱被认为是从感知智能通往认知智能的重要基石。一个很简单的原因就是,没有知识的机器人不可能实现认知智能。图灵奖获得者,知识工程创始人Edward Feigenbaum曾经提到:“Knowledge is the power in AI system”。张钹院士也提到,“没有知识的AI不是真正的AI”。
拿上一节提到的GPT-2算法来看,即使其文章续写能力让人赞叹,也只是再次证明了足够大的神经网络配合足够多的训练数据,就能够产生强大的记忆能力。但逻辑和推理能力,仍然是无法从记忆能力中自然而然的出现的。学界和企业界都寄希望于知识图谱解决知识互连和推理的问题。那么什么是知识图谱?简单来说,就是把知识用图的形式组织起来。可能这样说还不够明白,我们举例子分别说下什么是知识,什么是图谱。
所谓知识,是信息的抽象,举一个简单的例子来说,226.1厘米,229厘米,都是客观存在的孤立的数据。此时,数据不具有任何的意义,仅表达一个事实存在。而“姚明臂展226.1厘米”, “姚明身高229厘米”,是事实型的陈述,属于信息的范畴。对于知识而言,是在更高层面上的一种抽象和归纳,把姚明的身高、臂展,及姚明的其他属性整合起来,就得到了对于姚明的一个认知,也可以进一步了解姚明的身高是比普通人更高的。
维基百科给出的关于知识的定义是:知识是人类在实践中认识客观世界(包括人类自身)的成果,它包括事实、信息的描述或在教育和实践中获得的技能。知识是人类从各个途径中获得得经过提升总结与凝练的系统的认识。
图谱的英文是graph,直译过来就是“图”的意思。在图论(数学的一个研究分支)中,图(graph)表示一些事物(objects)与另一些事物之间相互连接的结构。一张图通常由一些结点(vertices或nodes)和连接这些结点的边(edge)组成。Sylvester在1878年首次提出了“图”这一名词[7]。如果我们把姚明相关的“知识”用“图谱”构建起来,就是图6所体现的内容。
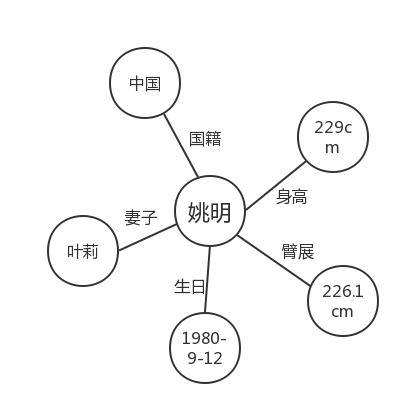
图6 姚明的基本信息知识图谱
知识图谱是实现通用人工智能(Artificial General Intelligence)的重要基石。从感知到认知的跨越过程中,构建大规模高质量知识图谱是一个重要环节,当人工智能可以通过更结构化的表示理解人类知识,并进行互联,才有可能让机器真正实现推理、联想等认知功能。而构建知识图谱是一个系统工程,其整体的技术栈如图7所示:
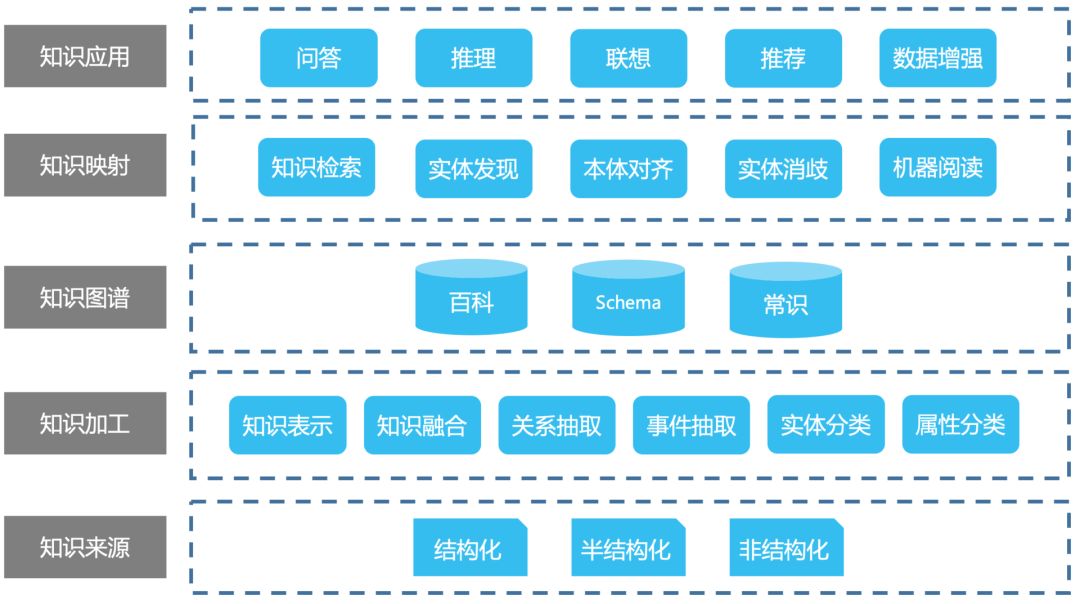
图7 知识图谱体系架构
针对不同场景,知识图谱的构建策略分为自顶向下和自底向上两种方法。
自顶向下的策略为专家驱动,根据应用场景和领域,利用经验知识人工为知识图谱定义数据模式,在定义本体的过程中,首先从最顶层的概念开始,然后逐步进行细化,形成结构良好的分类学层次结构;在定义好数据模式后,再将实体逐个对应到概念中。
自底向上的策略为数据驱动,从数据源开始,针对不同类型的数据,对其包含的实体和知识进行归纳组织,形成底层的概念,然后逐步往上抽象,形成上层的概念,并对应到具体的应用场景中。
知识图谱可以辅助各种智能场景下的应用。谷歌在2012年最早提出“Knowledge Graph”的概念,并将知识图谱用到搜索中,使得“搜索能直接通往答案”。知识图谱还能辅助智能问答、决策推理等应用场景。图8给出的是使用知识图谱结合自然语言处理进行问答的案例。
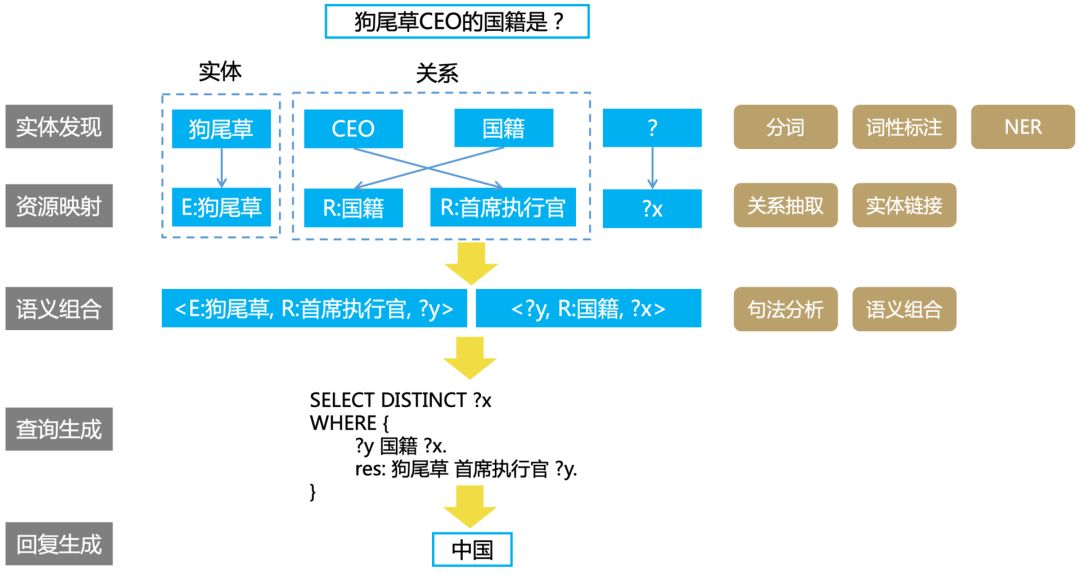
图8 知识图谱辅助智能问答
知识图谱让机器人拥有了知识,也让我们看到了实现认知智能的希望。但在目前的技术条件下,还有很多问题需要解决。
首先,知识的覆盖面不全。目前的知识图谱,仅仅涵盖了人类知识的极小的一部分。由于构建较为复杂,人类历史上海量自然语言文本中的知识,很大部分并没有被结构化到知识图谱中。即便是有了半自动的抽取方法,常识知识也很难从文本中得到。因此,常识推理也是目前知识图谱领域很难解决的一个问题。例如对于“鸡蛋放到篮子里,是鸡蛋大还是篮子大”,“人看见老虎要不要跑”这类问题,通过百科知识图谱就很难解决。
其次,知识图谱体系的标准化还不够完善。知识图谱体系称为“schema”。通俗来讲,schema是骨架,而知识图谱是血肉。有了schema,我们可以更好的做推理和联想。例如,树是一种植物,而柳树是树的一种实例化,可以推断出“柳树是植物”。一个简单的schema如图9所示。不同领域schema的建立通常会有所区别,不同知识图谱之间的schema也会有差异。
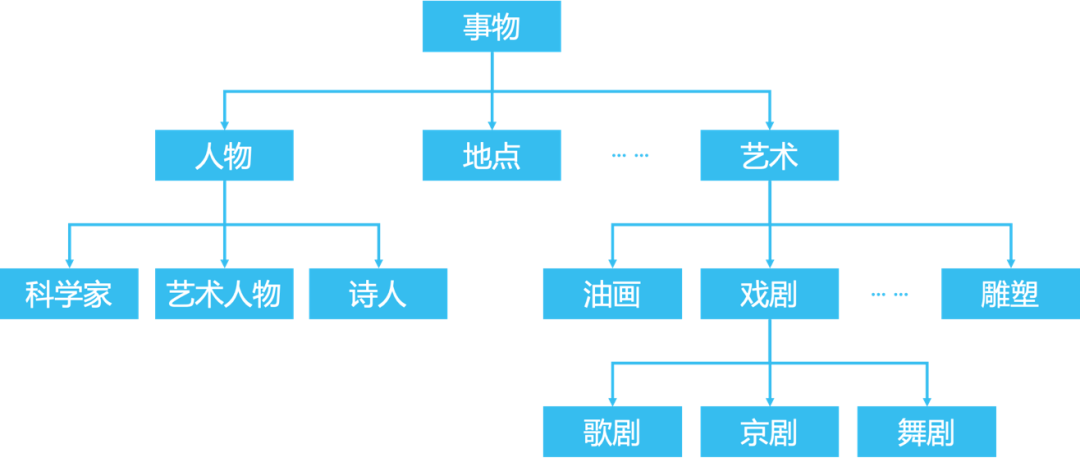
图9 知识图谱schema示例
2011年,Google、Microsoft和Yahoo!三大巨头推出了一个schema的规范体系:Schema.org,这个规范体系是一个消费驱动的尝试,其指导数据发布者和网站构建者在网页中嵌入并发布结构化数据,对应的回报是在用户在使用特定关键字搜索时,可以免费为这些网页提升排名,从而起到搜索引擎优化(SEO)的作用。
它的核心schema由专家自顶向下定义,截止目前,这个词汇本体已经包含600多个类和900多个关系,覆盖范围包括:个人、组织机构、地点、时间、医疗、商品等。通过SEO的明确价值导向,得到了广泛应用,目前全互联网有超过30%的网页增加了基于schema.org的数据体系的数据标注。在国内,相对应的是由OpenKG组织牵头的CnSchema(cnschema.org)。在相同的规范体系下,不同知识图谱之间可以做到更好的融合和知识迁移。
最后,构建知识图谱的成本仍然较高。Heiko Paulheim在其文章《How much is a Triple? Estimating the Cost of Knowledge Graph Creation》中,给出了几个典型的知识图谱的构建成本。其中,上世纪80年代开始的也是最早的知识图谱项目CYC,平均构建一条陈述句和断言的成本是5.71美元,而随着自然语言处理和机器学习技术的进步,DBpedia构建每一条的成本降低到了1.85美分。即便如此,在真正工程化落地的时候,牵扯到多源数据的清洗整合,一个知识图谱项目的成本还是居高不下。
六、重新审视认知科学
从感知智能通向认知智能的道路中,自然语言处理与知识图谱技术起到了重要作用。但不可忽视的是,认知智能乃至通用人工智能的实现,是需要多学科的共同进步才能完成的。
其中,脑科学是一个非常重要的研究领域。迄今为止,我们在创造智能机器的过程中,很大程度上还是在仿造现有的生命体。因此,对人脑的研究也提升了我们对认知智能的理解。人脑是由千亿级神经细胞,通过千万亿级的突触连接而形成的神经网络,不同的区域负责不同的功能。发达的大脑皮层也正是人类区别于动物的主要特点。
目前主流的深度学习技术,正是对人脑的一定程度的模仿。李航博士在其《智能与计算》一文中提到,虽然脑科学研究取得了一定的进展,但离探明人脑的工作机理还相差甚远。就能耗而言,前文中所提到的打败李世石的AlphaGo(拥有1202个CPU,176个GPU,按照每个CPU的功率为100W,每个GPU的功率为200W进行推算得到此结果。),每小时的能量消耗接近15万千卡,而一个成年人每天的能量消耗也仅仅2500千卡。更何况人在下棋之外还可以做很多其他的事情。
另外还需提及的一个学科是认知科学,其诞生于上世纪50年代的“认知革命”,包括哲学、认知心理学、计算机科学、语言学、人类学和神经科学六个主要领域。其代表纲领为“认知即计算“,通过心理符号表征和对表征结构的操作程序来研究一般的思维和智能。
在今年五月底《Nature Human Behaviour》的论文《What happened to cognitive science?》中,美国加州大学圣地亚哥分校认知科学系具身认知实验室主任(Director of the Embodied Cognition Laboratory)Rafael Núñez等几位专家,对半个世纪以来认知科学的发展进行了一个概括和讨论。图10给出了六个学科中在《认知科学》上论文数量的对比。可以看出,认知心理学占比超过了60%,计算机科学、神经科学和语言学分别占比10%左右,而人类学和哲学却几乎为零。因此,在认知科学领域,并没有形成一个完整统一的学科,而是认知心理学的一枝独秀。
但大量的里程碑式的成果仍然是多学科融合的产物。上世纪60年代兴起的心智计算理论(Computational Theory of Mind),是由认知科学家、脑科学家和哲学家共同提出和推进的。其认为“心智是计算系统,思考是符号操作”。心智计算理论在近二十年受到了前文提到的“体验认知理论”的挑战,而体验认知理论,也融合了认知科学、脑科学和哲学的研究成果。近十年来,认知神经科学和脑科学结合,通过先进的功能核磁共振技术,也为大脑如何产生思想提供了新的实验发现。
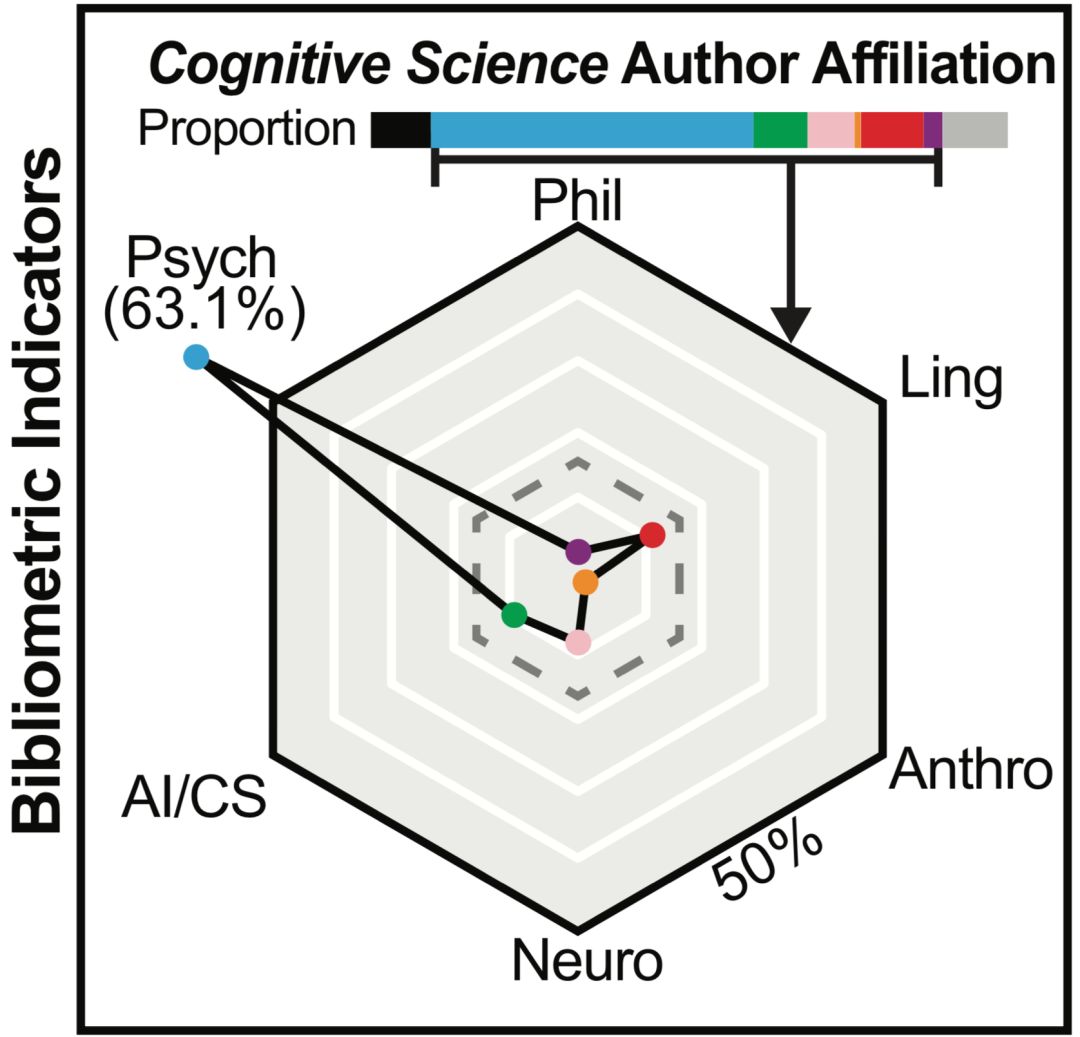
图10 《认知科学》领域论文数量对比
多学科的融合和发展,让认知智能不断进步。在今年7月,我们看到了一项令人激动的技术落地。美国神经科技公司Neuralink的创始人埃隆·马斯克(Elon Musk)16日表示,“脑机接口”(Brain-Computer Interface, BCI)研究取得新进展。公司研发出一种比人类头发丝还细的“线”,可植入人类大脑中,检测神经元活动。目前,研究人员已在猴子身上进行了实验,可以从1500个电极读取信息,让猴子能用大脑控制电脑。
七、结语
认知智能的突破,一定不是由单个技术所完成,而是需要结合多种不同的技术的发展。正如本文中所提到的,自然语言处理与知识图谱结合可以实现一定程度的推理,而知识图谱和深度学习结合可以实现一定程度的可解释性,自然语言处理和深度学习结合,诞生了BERT等强大的语言模型。
在技术之外,在实现认知智能的过程中,还需要考虑一些人文因素,例如如何让机器人具备情感,如何赋予机器人生存的意义(或目标),这些都是目前无法实现的事情。自然语言处理与知识图谱技术,开启了认知智能的大门,但还需要科学家和工程师们的共同努力,才能真正摘得人工智能皇冠上的明珠。
最后以孙中山先生的名言作为本文的结语:“革命尚未成功,同志任需努力。”
参考文献
[1] N. Brown, Superhuman AI for Multiplayer Poker, Science, 2019.
[2] W. Xiong, L. Wu, F. Alleva, J. Droppo, X. Huang, A. Stolcke, The Microsoft 2017 Conversational Speech Recognition System, Microsoft Technical Report MSR-TR-2017-39, arXiv:1708.06073v2, 2017.
[3] K. He, X. Zhang, S. Ren, J. Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, arXiv:1502.01852v1, 2015.
[4] A. Radford, K. Narasimhan, T. Salimans and I. Sutskever. Improving Language Understanding by Generative Pre-training, 2018.
[5] N. Arivazhagan et. al., Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges, arXiv:1907.05019, 2019.
[6]Y. Xu, Y. He and Y. Bi. A Tri-network Model of Human Semantic Processing. Frontiers in psychology, 2017.
[7] J. J. Sylvester. On an Application of the New Atomic Theory to the Graphical Representation of the Invariants and Covariants of Binary Quantics, with Three Appendices, Pure and Applied, 1 (1): 64–90, 1878.
附相关链接:
(1)英国帝国理工学院和剑桥大学研究人员共同组织的AI竞赛
http://www.animalaiolympics.com/
(2)ImageNet评测任务
https://www.kaggle.com/c/imagenet-object-localization-challenge
(3)WaveNet语音合成系统
https://deepmind.com/blog/wavenet-generative-model-raw-audio/
(4)SQuAD阅读理解竞赛
http://stanford-qa.com
(5)Transformer论文:
https://arxiv.org/abs/1706.03762
(6)ELMo论文
https://arxiv.org/abs/1802.05365
(7)BERT论文
https://arxiv.org/abs/1810.04805
(8)XLNet论文
https://arxiv.org/abs/1906.08237
【作者简介】邵浩,上海瓦歌智能科技有限公司总经理,狗尾草科技人工智能研究院院长。日本国立九州大学工学博士。现任上海瓦歌智能科技有限公司总经理,深圳狗尾草智能科技有限公司合伙人,人工智能研究院院长,带领团队打造了聊天机器人产品“公子小白”及AI虚拟生命产品“琥珀•虚颜”的交互引擎。上海市静安区首届优秀人才,兼任中国中文信息学会青年工作委员会委员,中国计算机学会YOCSEF上海学术委员会委员。研究方向为人工智能,共发表论文40余篇,出版了业内第一本聊天机器人著作,主持多项国家级及省部级项目,曾在联合国、WTO、亚利桑那州立大学、香港城市大学等任访问学者。
相约 2019 AI ProCon:邵浩还将于 9 月 7 日 出席 2019 AI开发者大会,与你共同探讨 NLP 技术落地与前沿研究!
(*本文为 AI科技大本营约稿文章,转载请联系微信 1092722531)


60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
-
超全!深度学习在计算机视觉领域的应用一览
-
数十篇推荐系统论文被批无法复现:源码、数据集均缺失,性能难达预期
-
SpanBERT:提出基于分词的预训练模型,多项任务性能超越现有模型!
-
真实揭秘 90 后程序员奔三准备:有人学金融投资,有人想当全栈工程师!
-
Python之父新发文,将替换现有解析器
-
乘势而起,走进2019年风口“边缘计算”
-
天网恢恢!又一名暗网比特币洗钱者被抓了
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









