









PySpider爬虫框架折腾体验
@(进阶)[PySpider,PySpider使用,PySpider体验]
最近在看爬虫类的Python文章,了解到了PySpider这个强大的爬虫框架,就想也体验一番,这次折腾的过程可以说极其曲折、峰回路转,感觉还是有必要写下来和大家分享,同时也表示对我在折腾过程中看到的精彩文章表示感谢。过程中我了解到了PySpider爬虫框架是位牛叉的国人开发的(好吧好多人也不太关心是谁开发的只管用),这个爬虫框架的用法网上也很多,我也是边看文章边折腾的。为什么说是折腾呢,因为还是那句话“开源项目无不折腾”,废话不多说开始正题。
首先还是要说点不是废话的话,要不然会让你有N多个为什么的,PySpider框架支持JS渲染抓取,支持PyQuery选择HTML,下面是它的一个简介:
PySpider 的主要特性
- Python 脚本控制,可以用任何你喜欢的html解析包(内置 PyQuery)
- WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
- 支持 MySQL, MongoDB, SQLite
- 支持抓取 JavaScript 的页面
- 组件可替换,支持单机/分布式部署,支持 Docker 部署
- 强大的调度控制
PySpider作者博客:http://blog.binux.me/
一看这些支持的功能,那就知道是用了不少基础库的。
我的系统环境:Win7,Python2.7(友情提示建议把文章看完了再动手操作)。
首先第一部安装PySpider:
我是一直都用的easy_install来安装的,安装命令很简单:
easy_install pyspider在安装过程中我们可以看到下载安装了那些库,你会看到有我们熟悉的一些名字:
Flask
Flask-Login
Tornado
PyQuery
PyCurl
LXML
CSSselect
….
顺利安装完PySpider这后还要单独安装Phantomjs,Phantomjs有各个平台的版本,下载相应的版本就行。下载解压得到一个Phantomjs.exe文件,把文件拷贝到Python安装目录就行了,我的Python安装目录是:C:\Python27。
现在可以开始把PySpider跑起来了,命令是:
pyspider all成功的话会显示以下提示:
F:\GoRun\Python>pyspider all
[I 160416 11:15:44 result_worker:49] result_worker starting...
Web server running on port 25555
[I 160416 11:15:49 processor:208] processor starting...
[I 160416 11:15:53 tornado_fetcher:508] fetcher starting...
[I 160416 11:16:00 app:76] webui running on 0.0.0.0:5000我们在浏览器打开http://localhost:5000,就可以看到一个界面,点击Create创建项目:
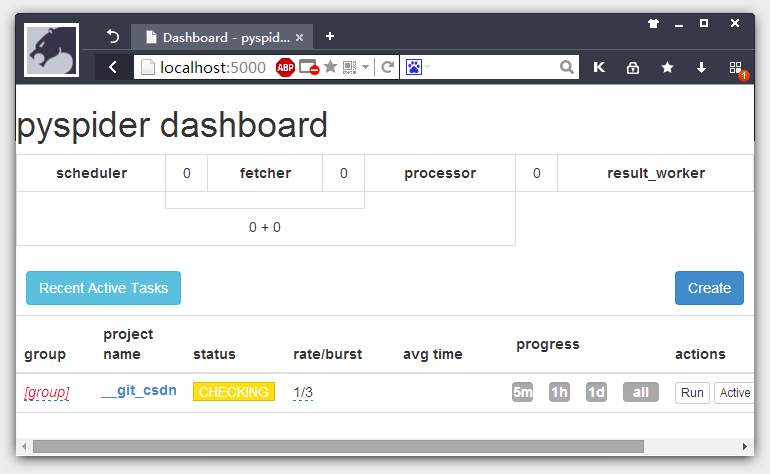
我们以官网Demo页面的例子来测试一下运行环境。把代码放到右边的代码框内Save一下,点左右的Run单步执行调试一下,看有没有问题。
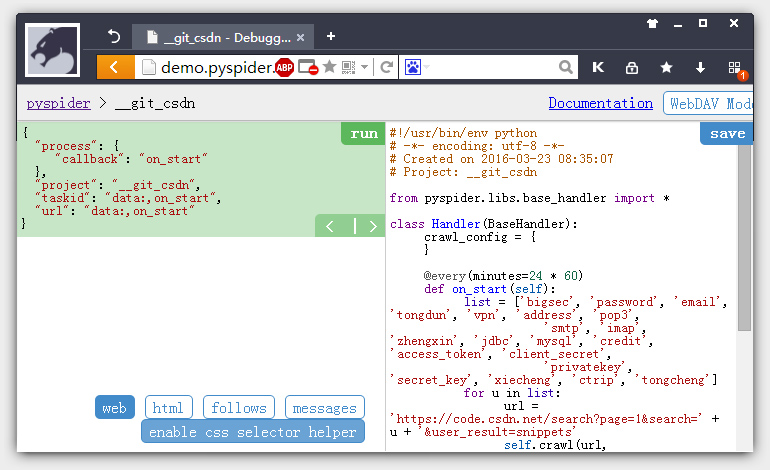
OH!看到证书问题,报HTTP 599: SSL certificate problem错误,确实我们看到我们的爬取的链接是HTTPS类。
HTTP 599: SSL certificate problem: self signed certificate in certificate chain在百度搜索一番,找到了问题所在,说是要在self.crawl加上validate_cert=False代码:
self.crawl(url, callback=method_name) #将所有crawl方法修成下面的
self.crawl(url, callback=method_name, validate_cert=False) #修改后这样就可以忽略SSL证书验证,但是要支持validate_cert=False设置我们还要更新最新版的PySpider来支持。GitHub上PySpider的最新版本是0.4, 这个新版本还没有发布,所以需要手动覆盖,在GitHub下载Zip后把里面的spider文件夹覆盖到PySpider模块所在目录文件夹(当然在覆盖前你可以备份一下),覆盖后我们再RUN测试一下,这次OK了。也别高兴得太早,这只是通过了单步执行测试。返回PySpider主目录点一下项目的RUN,发现cmd一直不断的报同一个错误“connect to scheduler rpc error: error 10061”,这是什么问题呢?又百度一番,结果没搜到有用的信息,把错误粘到StackOverflow搜索也是没有搜到有用的信息,只好又在谷歌去搜一遍。谷歌搜到两个国外的贴子,也是没有解决方案,有一个提到要安装一个RabbitMQ的服务,我把这个服务工个下载下来后,点安装提示要先安Erlang,我就感觉好像不太搭调,虽然GitHub PySpider项目有提到这个东西,但是感觉不是必要安装的。后来感觉太麻烦,就没有再安了。
我又开始去各种搜索,在SegMentFault看到有几个贴子也提到了这个到问题,但问题是也没有解决方案。实在没有办法,想到只有把VM虚拟机里的Debian系统跑起来,尝试一下在Debian环境下的安装。Phantomjs在国内下载起来比较崩溃,几十M的东西,要下一两个小时我也是醉了,GitHub版的又还要自己下源码来编译安装,看了一下编译安装要先搞定相关的编译环境,对于Linux新“菜”来说这样高“逼格”的玩法还是不适合。感觉太麻烦就还是又搜了一下Phantomjs第三方的下载平台,去下载编译好的Phantomjs文件。Phantomjs下载后同样需要放到Python的安装目录下,不过Debian下Python的安装目录稍有不同,是在:/usr/local/lib/python2.7/下。还有PySpider也是要下最新的版本覆盖到PySpider模块所以目录 ,这次我们再来RUN一下看,不过又提示unknown project,网上提示要改一下状态,我也是醉了,改成RUNING后成功执行了。总算折腾完了,PySpider的一些脚步可以参考一些例子学习。对于WIN7平台下的问题,后面我又按不同的关键词去搜了一下,找到了一些PySpider作者回过的关于WIN平台下的10061错误问题,但作者也不是在WIN下开发的,他也没有关于WIN平台下PySpider报10061错误的解决方案,这个相信以后应该可以慢慢找到原因的。关于PySpider的简单体验就写到这里了,有什么疑问和指导欢迎在微信[ioiplay]@我一起共同探讨。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









