






该博客记录YOLOv5人员检测部署过程,记录时会先描述每一步的意图,然后再用代码进行实现。
环境为Ubuntu20.04,在docker中运行,还有一些cude,TensorRT环境,之后查准后再记录。
这里先不对YOLOv5模型进行介绍了。
创建Docker环境
sudo docker run --gups all -it --name env_trt -v ${pwd}:/app nvcc.io/nvidia/tensorrt:22.08-py3
//创建容器,名称为env_trt,使用gpu,挂在当前路径到/app下,使用nvcc.io/nvidia/tensorrt:22.08-py3镜像创建(若没有这个镜像会自动下载)
拉取YOLOv5代码
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
git checkout a80dd66efe0bc7fe3772f259260d5b7278aab42f
//这里切换分支,防止出现兼容性问题
//可以切换pip的源,加速下载
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install -r requirements.txt
//安装依赖,部署是不需要这些依赖的,需要检查检查下yolov5是否可以正常运行,所以需要安装一下
导出ONNX模型
在进行深度学习部署时,通常先把使用深度学习框架搭建网络转换为ONNX模型,在这里ONNX模型是一个中间件,TensorRT可以将ONNX模型解析成它可以使用的模型。接下来我们先将使用官方提供的ONNX模型导出代码进行ONNX模型导出,导出后可以通过netron工具可视化导出的ONNX模型。
先使用官方的代码导出onnx模型
python export.py --weights weights/yolov5s.pt --include onnx --simplify --dynamic
使用netron工具可视化
netron yolov5s.onnx
下面为可视化结果:

在这里简单介绍一下yolov5的网络结构,总的来说是骨干网络+输出头,骨干网络用来提取特征没什么好说多的,对于输出头,在三个尺度上输出所检测到的目标,如下图:
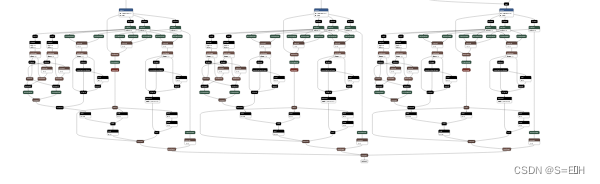
为了提高性能,重写这三个输出头,这三个输出头是用来解码bbox的,网络输出提取到的三个尺度特征[255, 80, 80],[255, 40, 40], [255, 20, 20],这里255=3*(1 + 4 + 80),1:是否有目标的置信度,4:x, y, w, h,它们的原始网络预测值为tx, ty,tw, th,输出头主要就是解码这四个坐标,它们是如何解码的在这里就不详细说了,大致意图是中心坐标是转化格点坐标,预测框的长和宽预测为anchor长和宽的缩放比例,80:80个类别的预测概率。
这种解码方式效率低,将它们删除,直接输出网络预测原始结果。
#在yolo中修改
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
-
- y = x[i].sigmoid()
- if self.inplace:
- y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
- xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
- xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
- wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
- y = torch.cat((xy, wh, conf), 4)
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+ y = x[i].sigmoid()
+ z.append(y)
+ return z
修改完了网络定义,再导出onnx模型如下:
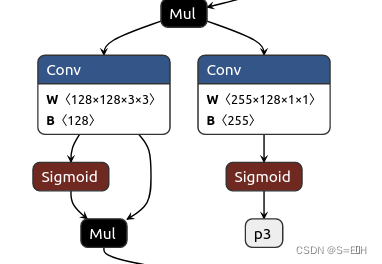
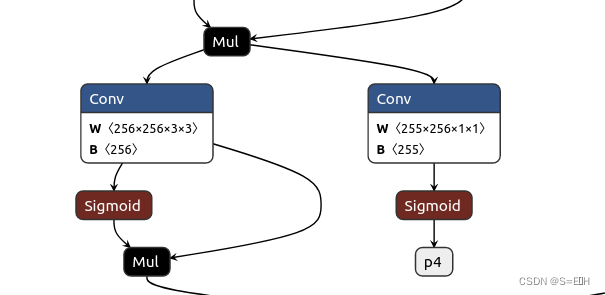
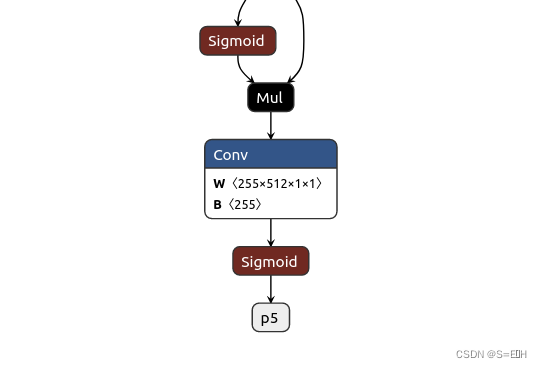
由于图片太大,这里只展示三个输出部分,可以看到没有了复杂的解码部分,只有三个输出p3, p4, p5,为什么是p3, p4, p5?因为导出代码中规定了输出名。
torch.onnx.export(
model,
im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['p3', 'p4', 'p5'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'p3': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,25200,4)
'p4': {
0: 'batch',
2: 'height',
3: 'width'},
'p5': {
0: 'batch',
2: 'height',
3: 'width'}
} if dynamic else None)
output_names={‘p3’, ‘p4’, ‘p5’]规定为输出分别为p3, p4, p5,这是torch.onnx.export的使用方法。
删掉了解码部分,不是需要它而是需要重新写一份效率高的,可以通过自定义一个插件来进行解码,这个插件可以理解为一个算子,先在ONNX模型中添加它的外壳,再实现它的定义。
添加外壳:
decode_plugin = onnx_gs.Node(
op="YoloLayer_TRT",
name="YoloLayer",
inputs=[p3, p4, p5],
outputs=[decode_out_0, decode_out_1, decode_out_2, decode_out_3],
attrs=decode_attrs
)
使用onnx_graphsrugeono工具对onnx模型进行修改,上面的代码就是构造一个外壳,算子名为"YoloLayer_TRT“,输入是p3, p4, p5,输出是decode_out_0,decode_out_1,decode_out_2, decode_out_3。还有其它的细节,目前也不太懂,先把代码放上:
# add yolov5_decoding:
import onnx_graphsurgeon as onnx_gs
import numpy as np
yolo_graph = onnx_gs.import_onnx(model_onnx)
p3 = yolo_graph.outputs[0]
p4 = yolo_graph.outputs[1]
p5 = yolo_graph.outputs[2]
decode_out_0 = onnx_gs.Variable(
"DecodeNumDetection",
dtype=np.int32
)
decode_out_1 = onnx_gs.Variable(
"DecodeDetectionBoxes",
dtype=np.float32
)
decode_out_2 = onnx_gs.Variable(
"DecodeDetectionScores",
dtype=np.float32
)
decode_out_3 = onnx_gs.Variable(
"DecodeDetectionClasses",
dtype=np.int32
)
decode_attrs = dict()
decode_attrs["max_stride"] = int(max(model.stride))
decode_attrs["num_classes"] = model.model[-1].nc
decode_attrs["anchors"] = [float(v) for v in [10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]]
decode_attrs["prenms_score_threshold"] = 0.25
decode_plugin = onnx_gs.Node(
op="YoloLayer_TRT",
name="YoloLayer",
inputs=[p3, p4, p5],
outputs=[decode_out_0, decode_out_1, decode_out_2, decode_out_3],
attrs=decode_attrs
)
yolo_graph.nodes.append(decode_plugin)
yolo_graph.outputs = decode_plugin.outputs
yolo_graph.cleanup().toposort()
model_onnx = onnx_gs.export_onnx(yolo_graph)
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
壳子定义好了,接下来进行实现。
实现插件,有点复杂,感觉还需要学习学习之后才能看懂,先不看了。
模型的构建
创建builder
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));//把builder做成一个智能指针
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
创建网络
//显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
//调用builer的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cerr << "Faild to creat network" << std::endl;
return -1;
}
创建ONNX解析器
//创建onnx解析器,onnxparser
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
//调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
std::cerr << "Faild to parse onnx file" << std::endl;
return -1;
}
配置网络参数
//配置网络参数
//需要告诉tensorrt最终运行时,输入图像的范围,batch size的范围
auto input = network->getInput(0); //获取输入节点
auto profile = builder->createOptimizationProfile(); //创建profile,用于设置输入的动态尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4(1, 3, 640, 640));//设置最小尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4(1, 3, 640, 640));//设置最优尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4(1, 3, 640, 640));//设置最大尺寸
创建config
auto config =std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cerr << "Failed to create config" << std::endl;
return -1;
}
//使用addOptimizationProfile方法添加profile,用于设置输入动态尺寸
config->addOptimizationProfile(profile);
//设置精度,不设置是fp32,设置为fp16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
//设置最大batchsize
buidler->setMaxBatchSize(1);
//设置最大工作空间
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
//创建流,用于设置profile
auto profileStream = samplesCommon::makeCudaSteam();
if (!profileStream)
{
std::cerr << "Faild to create stream" << std::endl;
return -1;
}
config->setProfilesStream(*profileStream);
创建engine
//创建engine,使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cerr << "Failded to create engine" << std::endl;
return -1;
}
序列化保存
//序列化保存
std::ofstream engine_file("./weights/yolov5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
模型的推理
创建模型运行时
//1创建推理运行时
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if (!runtime)
{
std::cerr << "Failed to create runtime" << std::endl;
return -1;
}
反序列化engine
auto plan = load_engine_file(engine_file);
//反序列生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{
std::cerr << "Failed to deserialize enginde" << std::endl;
return -1;
}
读取engine函数,读取一个二进制文件到vector中:
//加载模型文件
std::vector<unsigned char> load_engine_file(const std::string engine_file_path)
{
std::vector<unsigned char> engine_data;
//创建输入流
std::ifstream engine_file(engine_file_path, std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
//计算文件大小
//先把读取位置移动到最后
engine_file.seekg(0, engine_file.end);//偏移量, 初始位置
int length = engine_file.tellg();//获取当前的读取位置,感觉这个写的好麻烦
engine_data.resize(length);
//读取数据到vector中
engine_file.read(reinterpret_cast<char *> (engine_data.data()), length);
return engine_data;
}
创建执行上下文
//3创建执行上下文context
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
std::cerr << "Failed to createt context" << std::endl;
return -1;
}
创建输入输出缓冲区管理器
//4创建输入输出缓冲区
samplesCommon::BufferManager buffers(mEngine);
使用预处理,同时将处理后的输入填充到buffer中的输入中
//输入预处理
process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
process_input
输入frame和(float *)buffers.getDeviceBuffer(kInputTensorName),完成图像的预处理,再传给网络输入
使用cudu_preprocess加速预处理,输入源地址,长,宽和目的地址,长,宽。
cuda_preprocess
预处理中需要完成四个步骤:
通过仿射变换将图像变换为640640,保持原图纵横比,把图片放到640640黑布的中心
bgr to rgb
归一化
改变存储顺序,rgbrgbrgb to rrrgggbbb
这四个步骤通过cuda实现,首先进行仿射变换,在cuda中需要对每个像素进行变换,操作时,在目标像素上进行操作,需要知道原像素的位置
正向变换的过程:
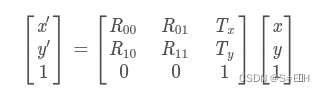
需要得到仿射矩阵的的反变换矩阵,因为需要根据目标像素位置求原像素位置。
int position = blockDim.x * blockIdx.x + threadIdx.x;//在cuda中确定但前线程所在的像素位置
int dx = position % dst_width;//列数
int dy = position / dst_width;//行数
目前已知cuda中目标像素的位置,下面可以根据仿射反变换矩阵求出原像素位置,但这个位置不一定是整数,需要使用双线性插值,根据原像素周围的四个元素来填充目标像素。
cuda_preprocess_init(height * width);//申请gpu内存
void cuda_preprocess_init(int max_image_size)
{
CUDA_CHECK(cudaMalloc((void**)&img_buffer_device, max_image_size * 3);
//CUDA_CHECK是一段宏,固定写法
}
//img_buffer_device是一个全局变量,之后都通过它寻找cuda中的数据
//static uint8_t* img_buffer_device = nullptr;
process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
//传入图像帧和网络输入地址
void process_input(cv::Mat &src, float *input_device_buffer)
{
cuda_preprocess(src.ptr(), src.cols, src.rows, input_device_buffer, kInputW, kInputH);
}
//在cuda_preprocess函数中使用cuda完成预处理的四个步骤
cuda_preprocess(uint8_t *src, int src_width, int src_height, float *dst, int dst_width, int dst_height)
{
//1.把cpu中的图像数据拷贝到gpu中
int img_size = src_width * src_height * 3;
CUDA_CHECK(cudaMemcpy(img_buffer_device, src, img_size, cudaMemcpyHostToDevice));
//2.计算反仿射变换矩阵
//声明变换矩阵的数据类型
AffineMatrix s2d, d2s;
//struct AffineMatrix
//{
// float value[6];
//}
//计算缩放比例
float scale = std::min(dst_weight / (float)src_weight, dst_height / (float)src_height);
//写出正向仿射变换矩阵
s2d.value[0] = scale;
s2d.value[1] = 0;
s2d.value[2] = -sacle * src_width * 0.5 + dst_width * 0.5;
s2d.value[3] = 0;
s2d.value[4] = sacle;
s2d.value[5] = -sacle * src_height * 0.5 + dst_height * 0.5;
//为了使用cv中的计算反变换矩阵函数,构造规定的Mat类型
cv::Mat m2x3_s2d(2, 3, CV_32F, s2d.value);
cv::Mat m2x3_d2s(2, 3, CV_32F, d2s.value);
//计算反变换矩阵
cv::invertAffineTransform(m2x3_s2d, m2x3_d2s);
//把Mat中数据复制出来,供以后使用,cuda中无法直接使用Mat数据,转换到指针的访问方式
memcpy(d2s.value, m2x3_d2s.ptr<float>(0), sizeof(d2s.vlaue));//m2x3_d2s.ptr<float>(0)指向第一行的第一个元素
//计算cuda函数参数threads, blocks
int jobs = dst_width * dst_height;
int threads = 256;
int blocks = ceil(jobs / (float)threads);
//3.进行cuda处理
warpaffine_kernel<<<blocks, threads>>>(
img_buffer_device, src_width * 3, src_width,
src_height, dst, dst_width, dst_height, 128, d2s, jobs);
}
__global__ void warpaffine_kernel(
uint8_t *src, int src_line_size, int src_width,
int src_height, float *dst, int dst_width, int dst_height,
uint8_t const_value_st,
AffineMatrix d2s, int edge)
{
//确定当前线程的位置,如果大于边界就返回
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (positon >= edge) return;
//根据目标位置计算原像素位置
float m_x1 = d2s.value[0];
float m_y1 = d2s.value[1];
float m_z1 = d2s.value[2];
float m_x2 = d2s.value[3];
float m_y2 = d2s.value[4];
float m_z3 = d2s.value[5];
int dx = position % dst_width;
int dy = positon / dst_width;
float src_x = m_x1 * dx + m_y1 * dy + m_z1 + 0.5f;
float src_y = m_x2 * dx + m_y2 * dy + m_z2 + 0.5f;
//双线性插值填充目标像素值
float c0, c1, c2;
//计算出的原像素位置不存在的化用128填充
if (src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height)
{
c0 = const_value_st;
c1 = const_value_st;
c2 = const_value_st;
}
else//存在的话,大概率也不是整数,需要双线性插值
{
int y_low = floorf(src_y);//对float进行向下取整,floor是对double进行向下取整
int x_low = floorf (src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_value[] = {const_value_st, const_value_st, const_value_st};
//计算距离周围四个点的距离
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
//计算周围四个点的占比
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
//多用指针
uint8_t *v1 = const_value;
uint8_t *v2 = const_value;
uint8_t *v3 = const_value;
uint8_t *v4 = const_value;
if (y_low >= 0)
{
if (x_low >= 0)//左上角的点
{
v1 = src + y_low * src_line_size + x_low * 3;
}
if (x_high < src_width)//右上角的点
{
v2 = src + y_low * src_line_size + x_high * 3;
}
}
if (y_high < src_height)
{
if (x_low >= 0)//左下角的点
{
v3 = src + y_high * src_line_size + x_low * 3;
}
if (x_high < src_width)//右下角的点
{
v4 = src + y_high * src_line_size + x_high * 3;
}
}
//加权计算新位置元素的b,g,r
c0 = w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0];
c1 = w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1];
c2 = w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2];
}
//bgr to rgb
float t = c2;
c2 = c0;
c0 = t;
//归一化
c0 = c0 / 255.0f;
c1 = c1 / 255.0f;
c2 = c2 / 255.0f;
//rgbrgbrgb to rrrgggbbb这个为什么需要在看一下,是网络中规定的还是trt中规定的
int area = dst_width * dst_height;
//确定当前目标元素的目的输入地址
float *pdst_c0 = dst + dy * dst_width + dx;
float *pdst_c1 = pdst_c0 + area;
float *pdst_c2 = pdst_c1 + area;
//向后推到r,g,b应该指向的位置,直接进行元素修改,而不是改变指向,因为两份内存是分开的
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
}
执行推理
//5执行推理
context->executeV2(buffers.getDeviceBindings().data());
把buffer拷贝到Host中,并提取模型输出
//拷贝会host
buffers.copyOutputToHost();
//从buffer中获取模型输出
int32_t *num_det = (int32_t *)buffers.getHostBuffer(kOutNumDet);
int32_t *cls (int32_t *)buffers.getHostBuffer(kOutDetcls);
float *conf = (float *)buffers.getHostBuffer(kOutDetScores);
float *bbox = (float *)buffers.getHostBuffer(kOutDetBBoxes);
后处理,执行nms和画图
//执行nms
std::vector<Detection> bboxs;//最后预测的检测框
yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);
// 结束时间,处理一张图像的时间
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
auto time_str = std::to_string(elapsed) + "ms";
auto fps_str = std::to_string(1000 / elapsed) + "fps";
//画图
//遍历检测结果
for (size_t j = 0; j < bboxs.size(); j++)
{
cv::Rect r = get_rect(frame, bboxs[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
}
writer.write(frame);
std::cout<< "处理完" << frame_index << "帧" << std::endl;
if (cv::waitKey(1) == 27)
{
break;
}
















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









