






问题2、计算每种车的年销量和平均价(hatchback and sedan 是同一种车的不同车厢类别,如Ford Focus Sedan和Ford Focus Hatchback都属于是Ford Focus,同时Focus是Ford旗下的一个车型)
问题1、问题3链接:
python破某公司数据分析笔试题(一):https://blog.csdn.net/dafeidouzi/article/details/100168562
python破某公司数据分析笔试题(三):https://blog.csdn.net/dafeidouzi/article/details/100170469
开始进入正题,首先导入库,别名
这是接着上一篇博客的,用的是合并后的数据进行相关操作
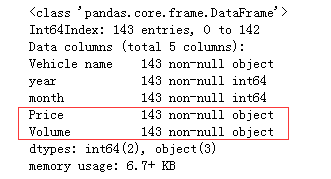
导入合并后的数据,查看数据信息,可以看到该数据没有缺失值,但Price和Volume这两个特征变量显示的是字符串,但事实上这两个特征是数值数据,显然这两个特征是有问题的,原因在于这两个特征数据里面存在着n.a值,故数据类型才会显示为object
老操作,先处理数据,所以这里我打算用均值替换掉Price和Volume中的n.a值,我的做法是先使用.isdigit()识别出不是数值的值,然后将其赋值为0,计算所在列的均值后,将均值赋给原来的n.a值
结果如下:

替换掉n.a值之后,查看数据信息可以看到,Price、Volume这两个特征的数据类型已经改成int类型了
查看数据前5行用的是.head()

查看数据的描述统计信息

1.可以看到汽车价格中均值为19292,最小值为203,而最大值是22367,所以要考虑的是在现实生活中是否存在,是否具有现实意义?如果没有,这个值可能是异常值,后面通过可视化去验证这一猜测。
2.汽车体积的均值为15804,最小值为9559,最大值为170440,同样,Volume中可能存在异常值下面绘制Price、Volume这两个特征的箱线图去看看值的分布,可以看到Price、Volume都存在着一个离群点,而且偏离数据程度十分严重,故可视为异常值


对于异常值的处理,同样我采用的是均值替补的方法

结果如下:可以看到13那一行中对应的Price的值已经由原来的203替换成19291了,同样Volume中的异常值也已经被换成14612了,这里没有截出来

数据处理好之后,就开始进入问题2的操作了,这里再将问题粘贴出来

根据问题2,我的理解是将车类型分为4类:Chevy Cruze、HoNDA CiviC和Honda Civic、Ford Focus Sedan和Ford Focus Hatchback、Focus Hatchbac,我也不知道对不对,单纯是我自己的理解
接着就是从data中提取出这四类车,然后利用count()、mean()计算数量和均值
对于一个类型里面有两种不同的车厢或不同写法的问题,我是将它们分别提取出来,然后使用pd.concat()将它们连接起来,具体操作如下代码:

到这里,问题2的基本操作就完成了,完全靠自己的理解来的,也不懂那里做不好,希望有大佬路过的话,可以指点一下~小豆子在此谢过
















 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









