






随着手机应用的逐渐频繁,有时候不方便或没时间记录时,我们经常会拍摄一些文档照片来保存一些东西,但是在后期应用时,图片无法修改或整理,比较麻烦,此时选择将图片或PDF扫描件转化为文本文件就成为一种方便快捷的方式。今天达芬奇就同大家分享三款免费图片或PDF转化为文字文本软件,希望满足大家的转换需求。
软件1、白描
下载地址:https://wwf.lanzouw.com/iWQO50fddxyj
比较少见的国产干净简洁的软件;软件简洁纯净,有会员年费可充值,但是免费版本基本就能满足大多数人的使用需求;自称像猫一样灵动的OCR扫描识别神器。具备高准确度的文字识别、表格识别转Excel、批量识别、识别后翻译、文件扫描等功能。此软件提供多个系统版本,可满足移动端,电脑端及网页端需求,考虑真是周到。

下面介绍电脑端使用
步骤1:下载安装后打开软件,如下图所示,选择点击图片,亦可选择PDF文档,如图,自动将PDF文档进行识别,识别速度快,效率高;
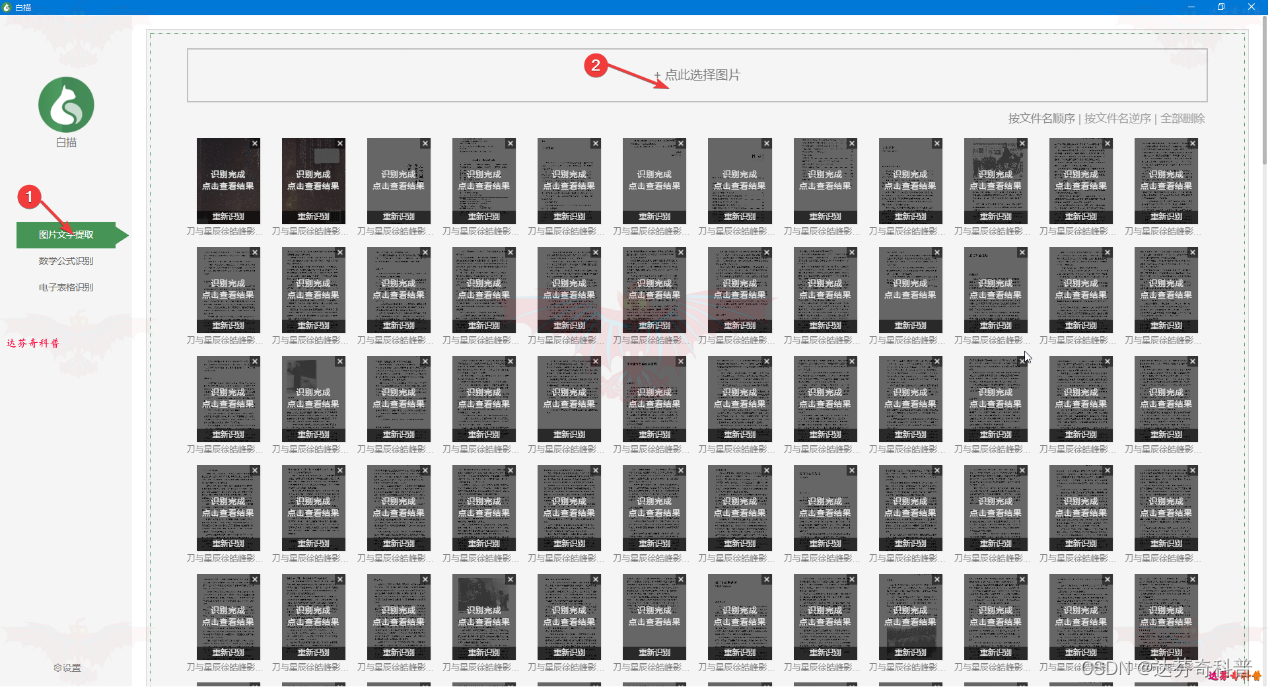
步骤2:如图正在识别中;

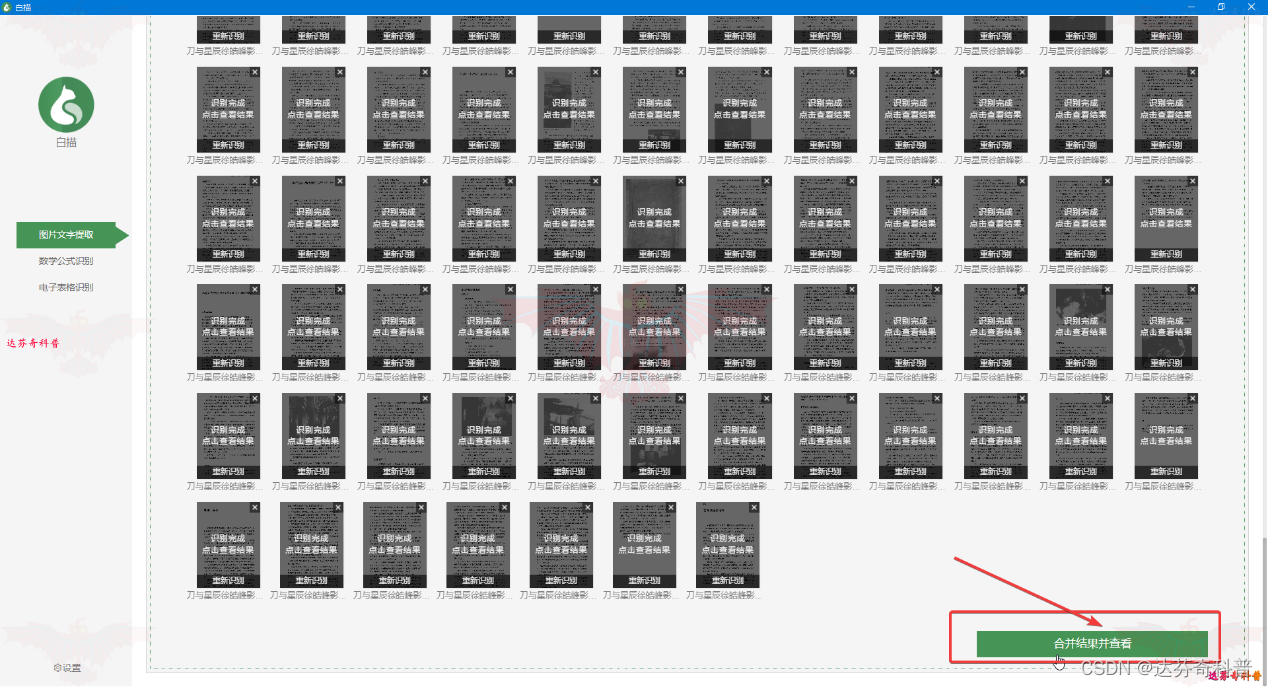
步骤3:如下图,识别结束后,可合并结果进行查看
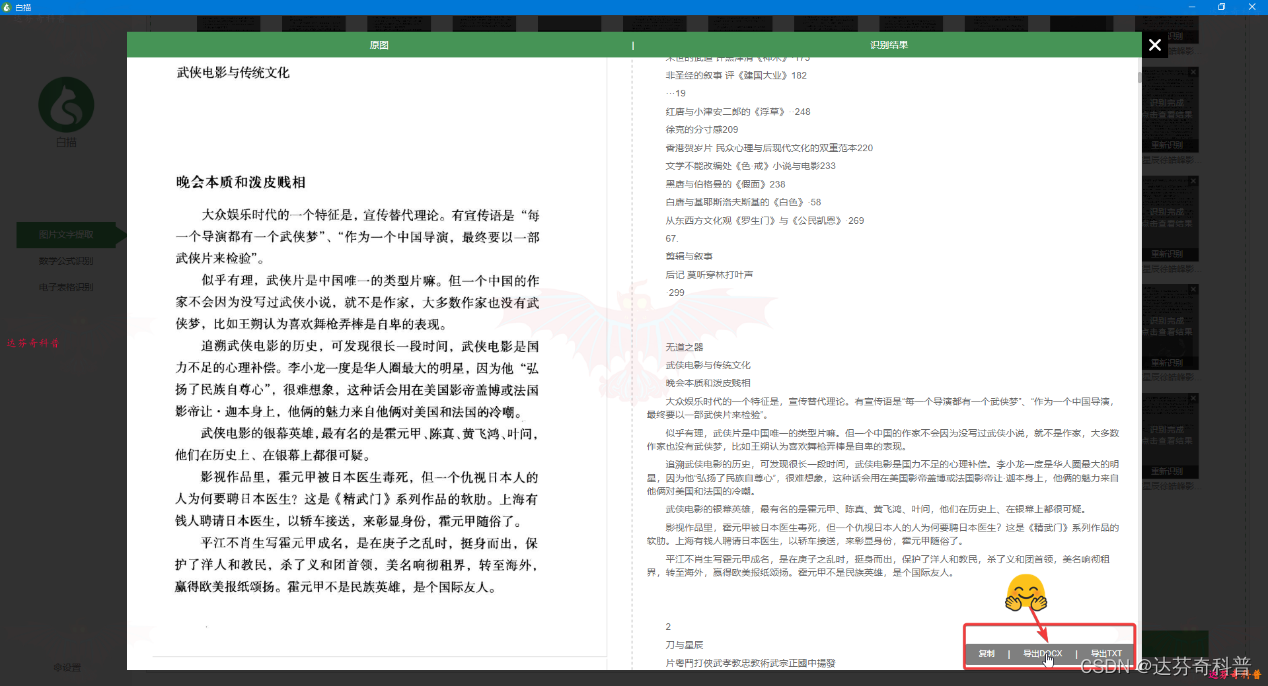
步骤4,如图,合并结果后,可对比查看,且可选择导出为word或txt文档,点击保存即可。
软件2:Image Scan OCR
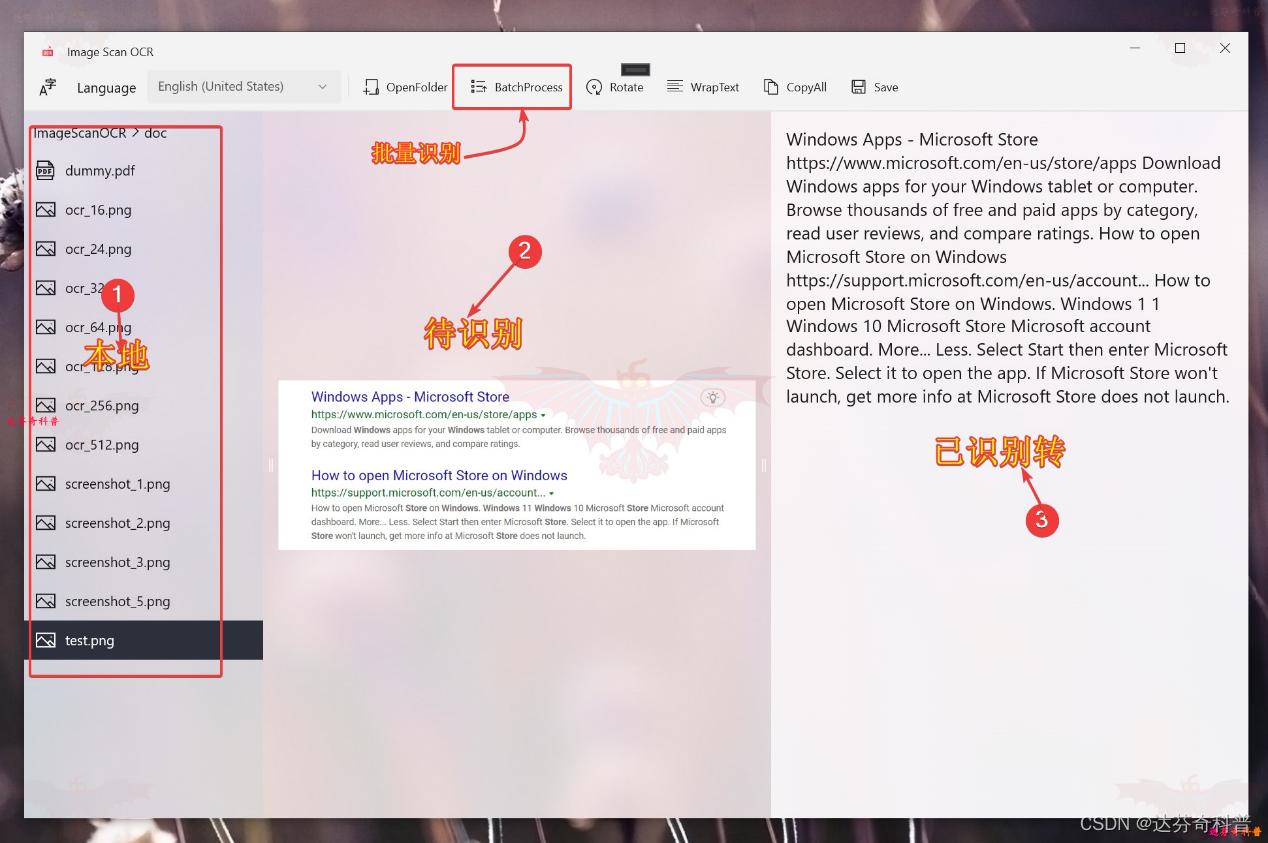
此 Microsoft Store 应用非常适合使用 OCR 批处理文件。 它使用三栏设计,左侧是文件夹,中间是所选文件,右侧是已识别的文本。 图像扫描 OCR 支持图像和 PDF。
首次启动时,必须通过 OpenFolder 菜单项选择一个文件夹。 可以设置一种语言来改进文本识别。 当打开包含许多文件的文件夹时,该应用程序变得非常滞后,建议选择一个空文件夹并将文件拖入其中。 单击批处理时,图像扫描 OCR 将处理当前文件夹中的所有文件。 处理完图像或文档后,可以在右栏中编辑结果,然后将其复制或保存到文本文件中。
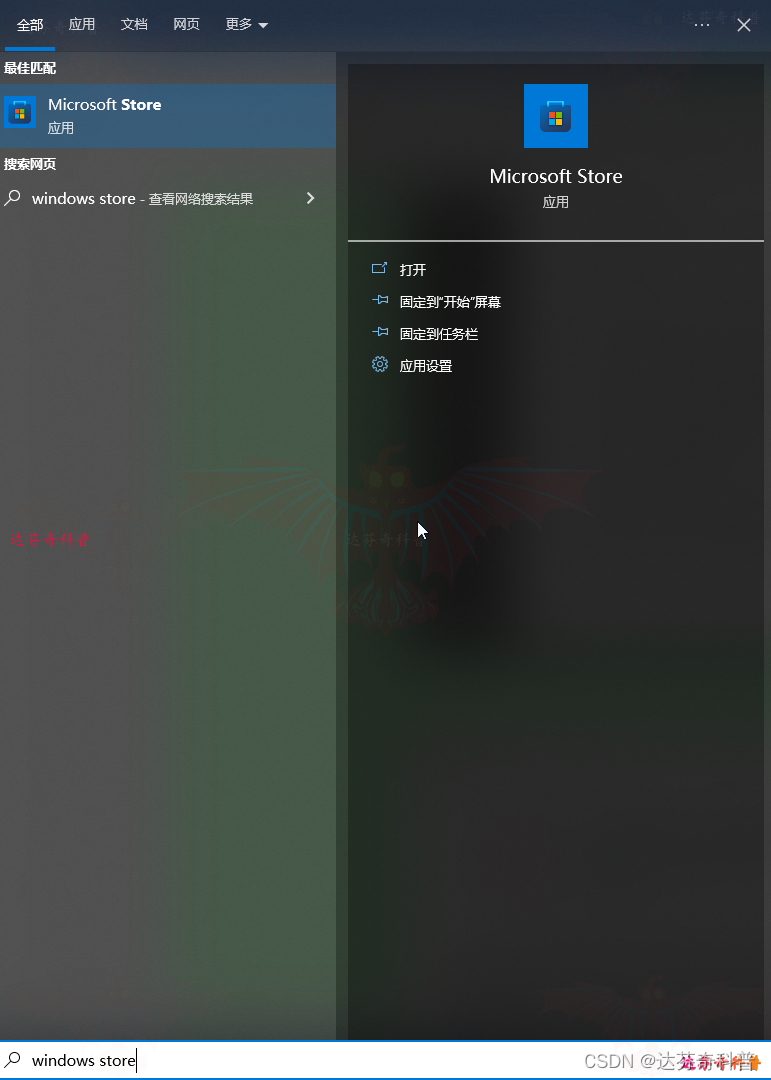
步骤1:按“win+s”快捷键打开搜索框,输入“Microsoft Store”,然后“打开”,进入微软商城;
步骤2,输入”Image Scan OCR”,搜索,即可出现“Image Scan OCR”应用,点击下载,等待安装;
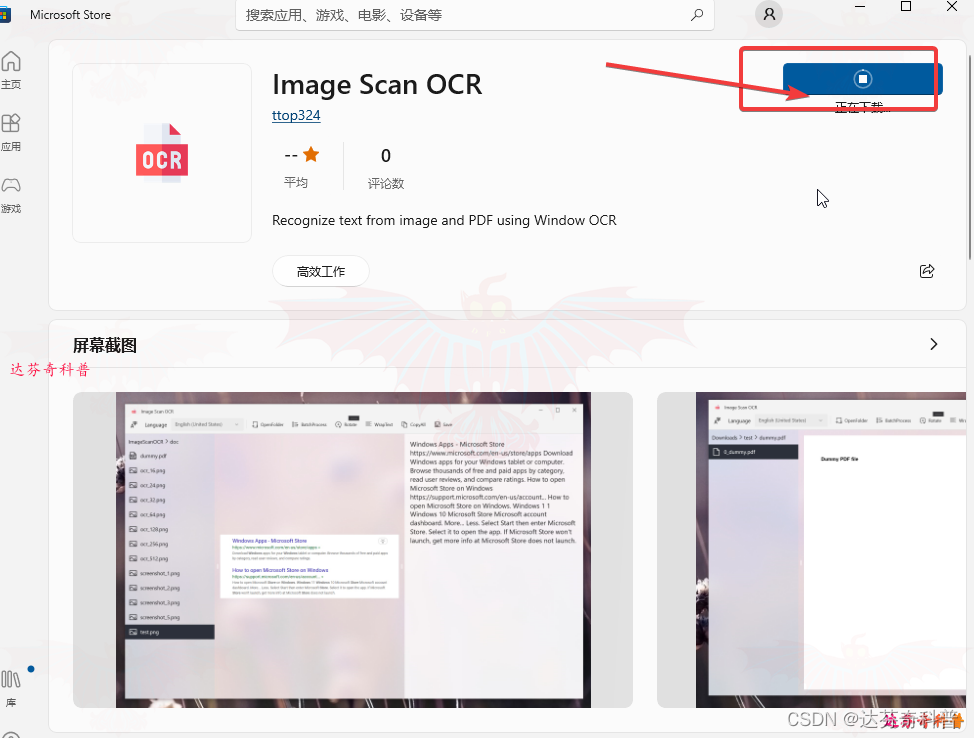
步骤3,下载安装后,打开Image Scan OCR,选择要识别图片的语言“汉语”,
打开“Open Folder”选择或新建要识别的文件夹,
然后,在下图最左栏选择要识别的图片,即可自动进行识别;
可以进行圈选进行部分图片识别,或不选择,进行全部图片识别;
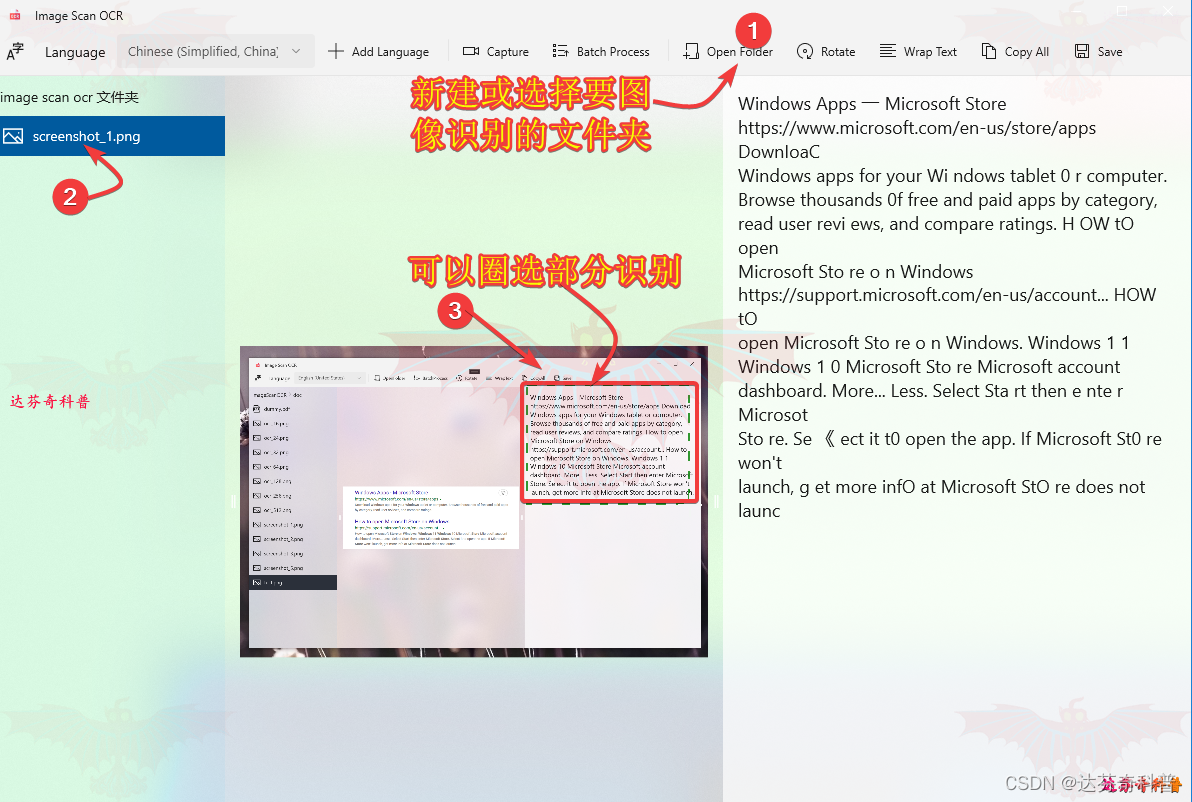
步骤4:可以选择多张图片,进行批量识别转换;
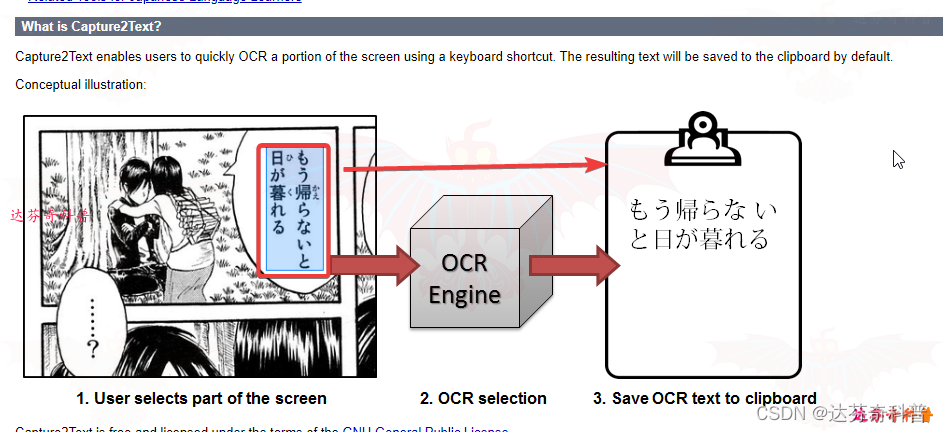
软件3:Capture2Text
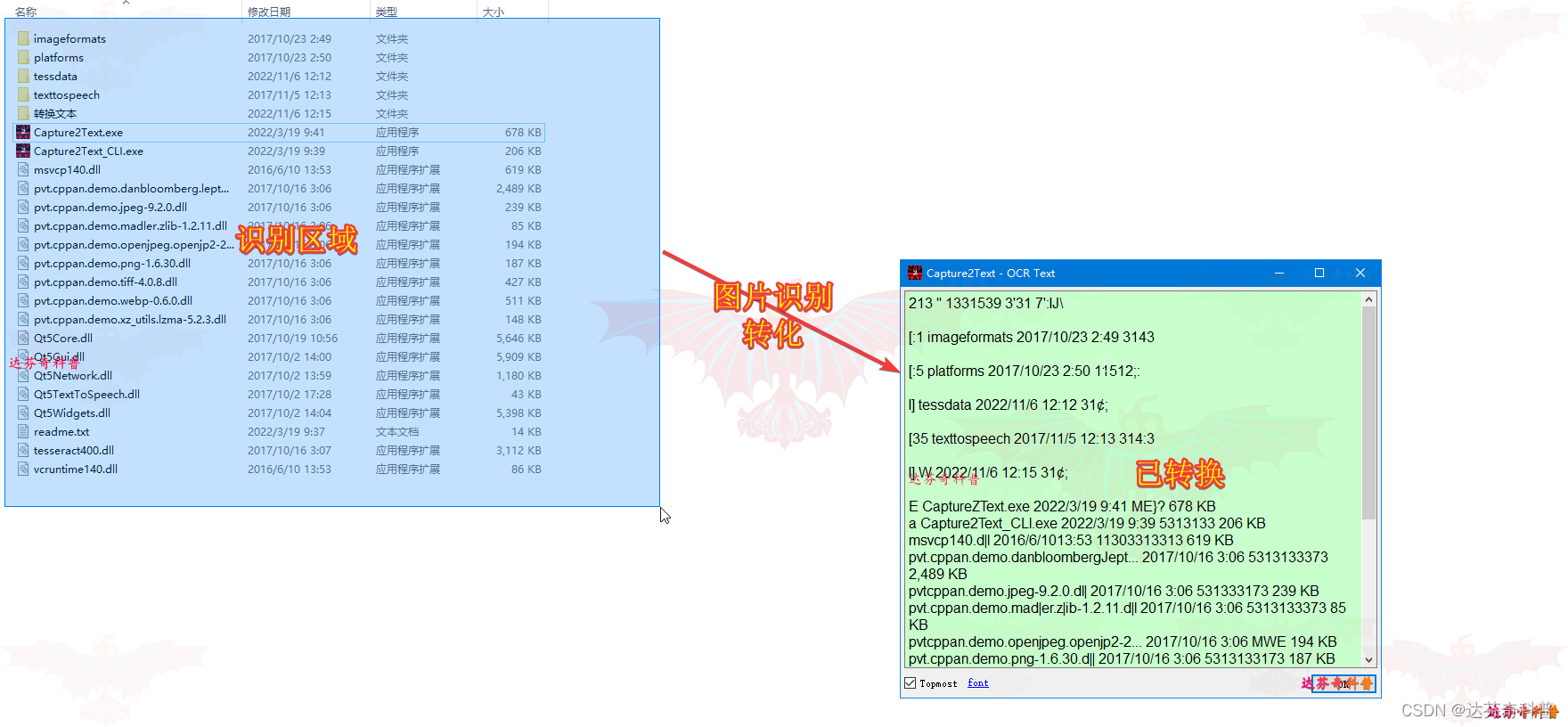
Capture2Text 使用户能够使用键盘快捷键快速图片识别屏幕的一部分。 默认情况下,生成的文本将保存到剪贴板。如下图所示:
使用方法:
步骤1:下载软件;
步骤2:如下图所示,用7-ZIP解压软件包文件“Capture2Text_v4.6.3_64bit.zip”,点击进入软件包解压文件夹;
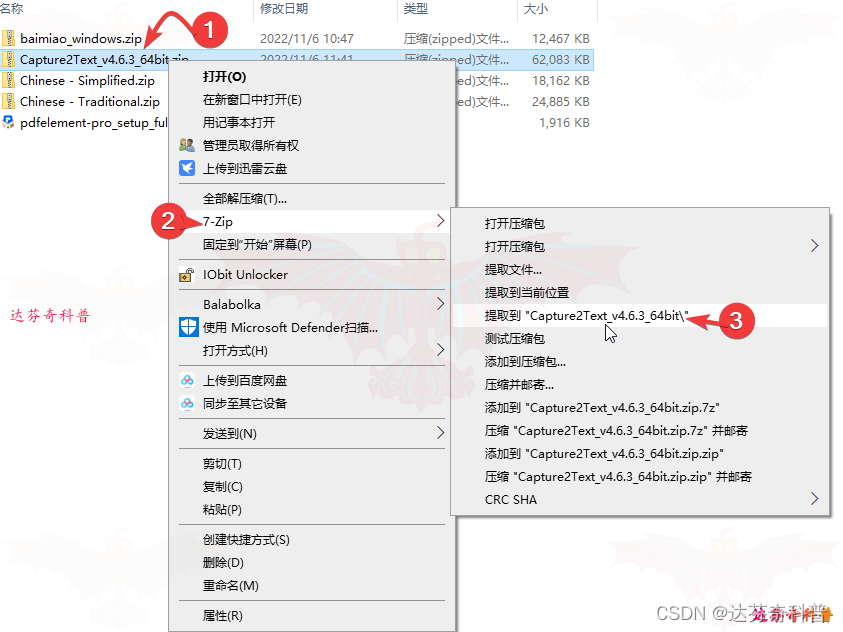
步骤3,双击”Capture2Text.exe”文件,貌似没反应,视线下移到任务栏,可以看到“Capture2Text”图标,右键点击打开菜单栏,选择“Chinese-Simplified”中文简体;
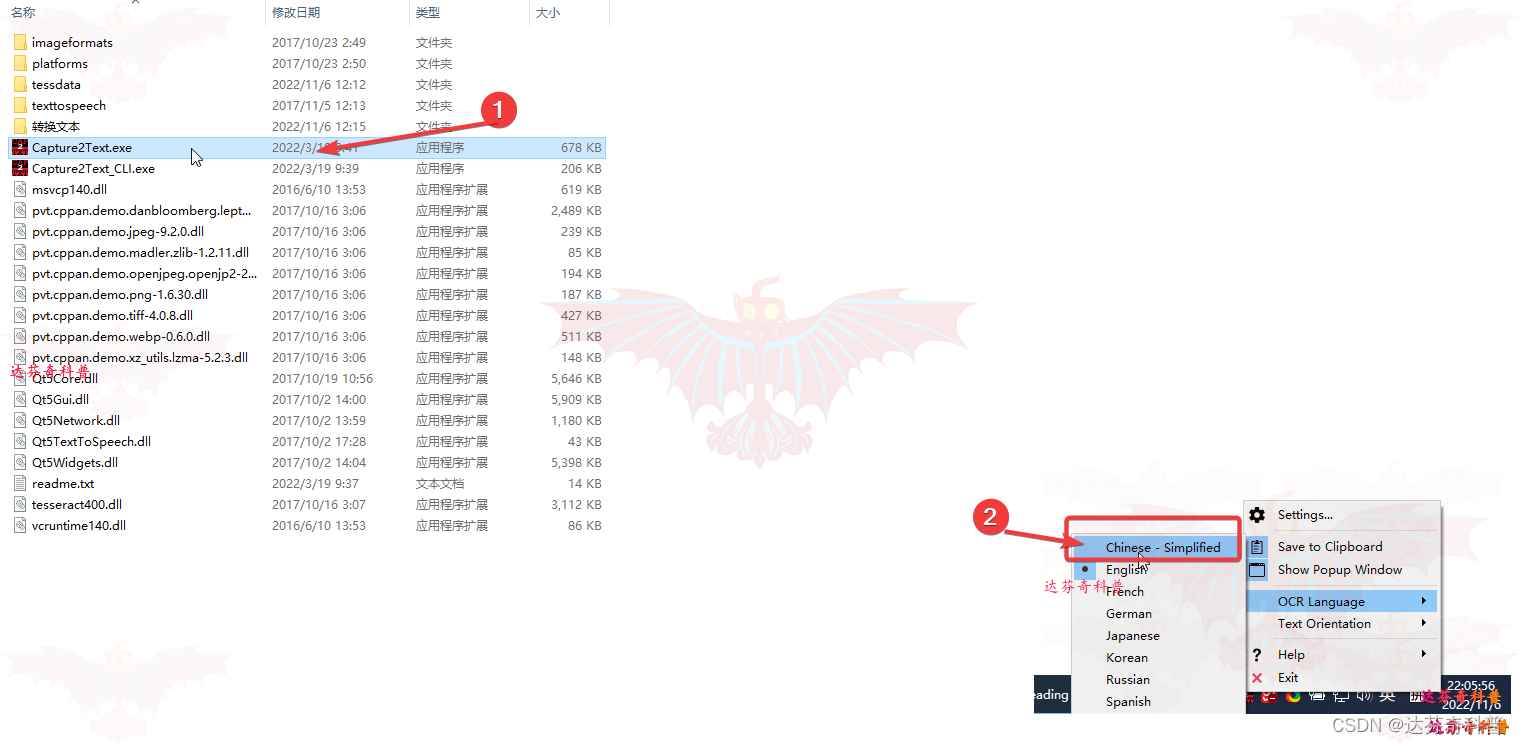
步骤4,打开“Settings”窗口,可见有“hotkeys”(快捷键)设置,预览,OCR1快捷键进行,翻译,语音转换等功能,功能丰富方便;
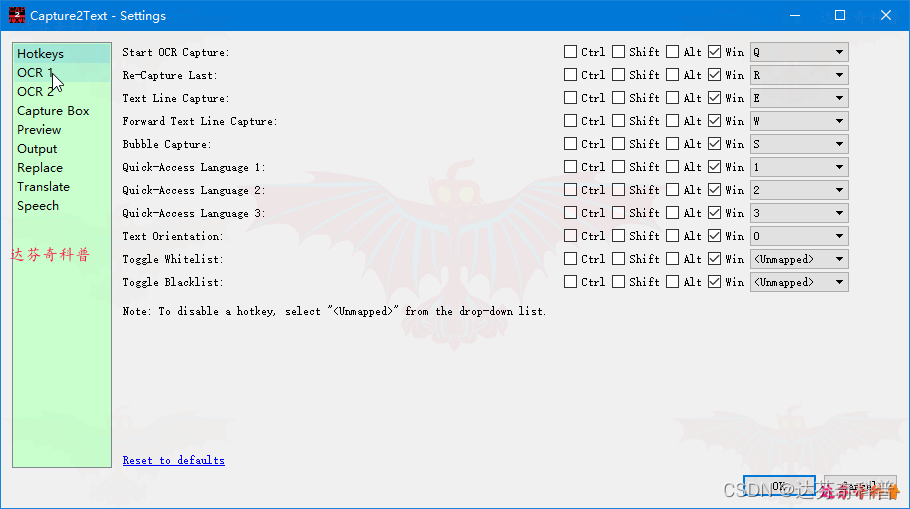
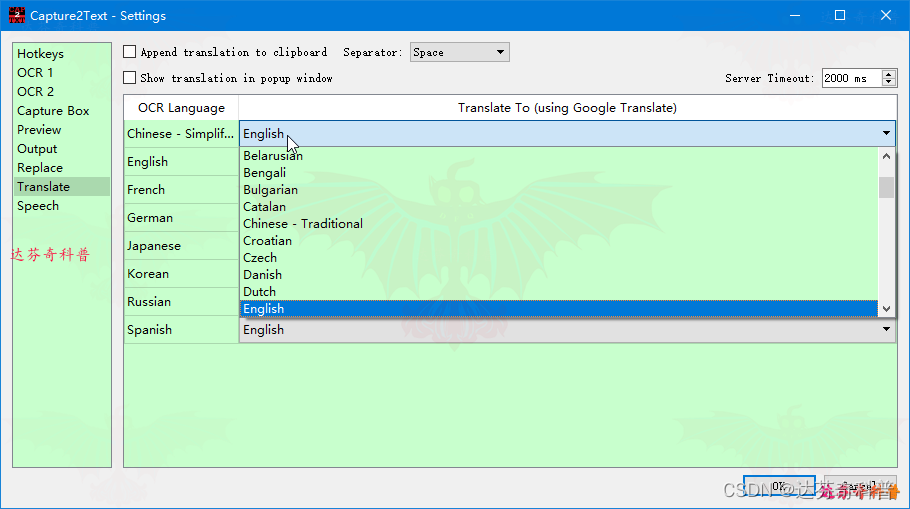
步骤5,按默认快捷键“Win+Q”组合键,如下图,即可选择识别区域,稍等下,即可出现识别文本。
今天的达芬奇分享就到这里啦,大家有任何疑问都可在下方留言,达芬奇会尽可能为每个疑问者解答。如果对你有帮助也请多多转发分享,让更多人看到,帮助更多人🖖 !

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









