







作为Go 语言中的基础数据类型,字符串string在实际的项目开发中也有着很高的使用频率,其底层实现与数组/切片有着密切的联系,所以对比着切片slice学习能更好的掌握两种数据类型的知识点。下面就以go 1.16版本介绍下string的相关知识点。
1 字符串底层数据结构
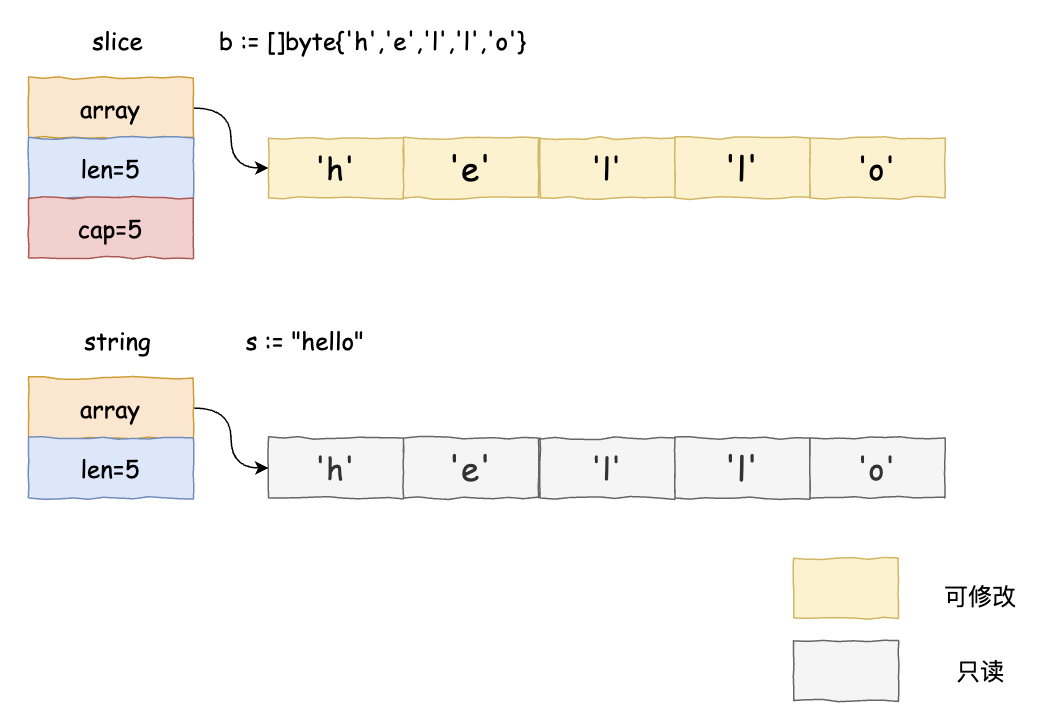
在Go语言中,可以将字符串看成是由字符组成的数组,其底层由
- str:指向存储字符数组的首地址指针
- len:字符数据的长度
组成,其中数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串。对比切片的底层实现,不难发现,两者只是少了一个cap成员变量,但是在使用的性质上却截然不同:
- 字符串申请的数组内存刚好存储下字符数组,不像切片可以提前申请未分配的数组内存空间
- 字符串的数组是一个只读的字节数组,不能通过下标索引赋值去改变字符串的内容(字符串数组虽不能直接修改,但字符串变量能够被重新赋值)
// string底层数据结构在src/runtime/string.go中定义
type stringStruct struct {
str unsafe.Pointer
len int
}
1.1 字符串的只读特性
对于字符串变量,编译器会将其标记成只读数据 SRODATA,假设我们有以下代码,其中包含了一个字符串,当我们将这段代码编译成汇编语言时,就能够看到 hello 字符串有一个 SRODATA 的标记。只读只意味着字符串会分配到只读的内存空间,但是 Go 语言只是不支持直接修改 string 类型变量的内存空间(既无法通过下标修改字符串对应的字符),如果需要实现该功能,则需要先将字符串转换为[]byte,修改完成后再变为string。
func main() {
str := "hello" // 无法通过str[0] = 'j' 去修改字符串
println([]byte(str)) // 只能将其转化为[]byte或者直接全部重新赋值
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...2 字符串的使用
2.1 字符串的赋值
-
双引号声明:它只能用于单行字符串的初始化,如果字符串内部出现双引号,需要使用
\符号避免编译器的解析错误; -
反引号声明:这种方式可以摆脱字符串赋值单行的限制。当使用反引号时,因为双引号不再负责标记字符串的开始和结束,我们可以在字符串内部直接使用
",在遇到需要手写 JSON 或者其他复杂数据格式的场景下非常方便。
// 下述双引号、反引号声明方式具有相同的输出
// hhhh"
// hhh
s := "hhhh\"\n" +
"hhh" // 直接接在上一行最后的输出,双引号之前的空格不影响
s2 := `hhhh"
hhh` // 如果前面有空格,输出时都会被保留2.1.1 双引号声明底层源码
双引号赋值时,编译器使用cmd/compile/internal/syntax.scanner.stdString 方法来解析使用双引号的标准字符串,从这个方法的实现我们能分析出 Go 语言处理标准字符串的逻辑:
-
标准字符串使用双引号表示开头和结尾;
-
标准字符串需要使用反斜杠
\来逃逸双引号; -
标准字符串不能出现隐式换行
\n,既双引号出现在不同的行;
func (s *scanner) stdString() {
ok := true
s.nextch()
for {
if s.ch == '"' {
s.nextch()
break
}
if s.ch == '\\' {
s.nextch()
if !s.escape('"') {
ok = false
}
continue
}
if s.ch == '\n' {
s.errorf("newline in string")
ok = false
break
}
if s.ch < 0 {
s.errorAtf(0, "string not terminated")
ok = false
break
}
s.nextch()
}
s.setLit(StringLit, ok)
}2.1.2 反引号声明底层源码
使用反引号声明的原始字符串的解析规则就非常简单了,cmd/compile/internal/syntax.scanner.rawString 会将非反引号的所有字符都划分到当前字符串的范围中,所以我们可以使用它支持复杂的多行字符串:
func (s *scanner) rawString() {
ok := true
s.nextch()
for {
if s.ch == '`' {
s.nextch()
break
}
if s.ch < 0 {
s.errorAtf(0, "string not terminated")
ok = false
break
}
s.nextch()
}
// We leave CRs in the string since they are part of the
// literal (even though they are not part of the literal
// value).
s.setLit(StringLit, ok)
}2.2 字符串的拼接
拼接也是字符串比较常用的一种操作,常用的方式有: + 号拼接,Join拼接,fmt拼接,Buffer拼接,Builder拼接。
2.2.1 加号拼接
使用加号实现字符串的拼接时,编译器会将该符号对应的 OADD 节点转换成 OADDSTR 类型的节点,随后在 cmd/compile/internal/gc.walkexpr 中调用 cmd/compile/internal/gc.addstr 函数生成用于拼接字符串的代码,最终用于处理拼接操作的函数是runtime.concatstrings:
- 如果需要拼接的非空字符串数量为0,则直接返回空字符串。
- 如果非空字符串的数量为 1 并且当前的字符串不在栈上(不会立马被回收),就可以直接返回该字符串,不需要做出额外操作。
- 其他情况下,先申请一块足够拼接所有字符串的内存,运行时会调用
copy将输入的多个字符串拷贝到目标字符串所在的内存空间。新字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
// concatstrings implements a Go string concatenation x+y+z+...
// The operands are passed in the slice a.
// If buf != nil, the compiler has determined that the result does not
// escape the calling function, so the string data can be stored in buf
// if small enough.
func concatstrings(buf *tmpBuf, a []string) string {
// 预处理:计算总长度并检查有效性
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue // 跳过空字符
}
if l+n < l {
throw("string concatenation too long")
}
l += n // 累加长度
count++ // 计数非空字符串
idx = i // 记录最后一个非空字符串索引
}
if count == 0 {
return "" // 全为空字符串时直接返回
}
// If there is just one string and either it is not on the stack
// or our result does not escape the calling frame (buf != nil),
// then we can return that string directly.
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
// 单字符串直接返回
return a[idx]
}
s, b := rawstringtmp(buf, l) // 分配目标内存
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}2.2.2 Join拼接
Join拼接的方式需要先将待拼接的字符串组成字符串切片,然后调用strings.Join函数,从头到尾遍历,为两个字符串之间添加所需的字符串。该函数的处理逻辑与concatstrings函数及其类似:
- 如果需要拼接的字符串数量为0,则直接返回空字符串。
- 如果字符串数量为1,直接返回该字符串,不需要做出额外操作。
- 其他情况下,先申请一块足够拼接所有字符串的内存(新容量=2*旧容量+所需容量),然后调用append函数进行字符串添加。
// Join concatenates the elements of its first argument to create a single string. The separator
// string sep is placed between elements in the resulting string.
func Join(elems []string, sep string) string {
switch len(elems) {
case 0:
return ""
case 1:
return elems[0]
}
// 计算join完成后,新字符串的整体长度
n := len(sep) * (len(elems) - 1)
for i := 0; i < len(elems); i++ {
n += len(elems[i])
}
var b Builder
b.Grow(n) // 为b一次性分配足够的内存,新容量 = 2*旧容量+n
b.WriteString(elems[0])
for _, s := range elems[1:] {
b.WriteString(sep)
b.WriteString(s)
}
return b.String()
}2.2.3 性能对比
2.2.3.1 一次调用
以下面的测试代码为例,加号拼接与Join函数的效率相近,明显优于fmt,同时可以看到不管是多少个字符串拼接,内存分配次数与加号拼接、Join函数被调用的次数一致(多个加号写在一行,只会调用一次concatstrings函数),fmt更适合于格式化转化成字符串。
func plusOperatorJoin(s string) string {
return s + s + s + s + s + s + s + s + s + s
}
func stringsJoin(s string) string {
ans := []string{s, s, s, s, s, s, s, s, s, s}
return strings.Join(ans, "")
}
func sprintfJoin(s string) string {
return fmt.Sprintf("%s%s%s%s%s%s%s%s%s%s", s, s, s, s, s, s, s, s, s, s)
}
func BenchmarkPlusOperatorJoin(b *testing.B) {
var str = getRandomString(10)
for i := 0; i < b.N; i++ {
plusOperatorJoin(str)
}
}
func BenchmarkStringsJoin(b *testing.B) {
var str = getRandomString(10)
for i := 0; i < b.N; i++ {
stringsJoin(str)
}
}
func BenchmarkSprintfJoin(b *testing.B) {
var str = getRandomString(10)
for i := 0; i < b.N; i++ {
sprintfJoin(str)
}
}
$ go test -bench="Join$" -benchmem tt_test.go
goos: darwin
goarch: arm64
BenchmarkPlusOperatorJoin-8 7285815 140.0 ns/op 1024 B/op 1 allocs/op
BenchmarkStringsJoin-8 6550750 186.4 ns/op 1024 B/op 1 allocs/op
BenchmarkSprintfJoin-8 2602051 476.9 ns/op 1184 B/op 11 allocs/op2.2.3.2 循环调用
如果使用for循环多次调用,则又是不同的结果,从基准测试结果中可以看出Builder、Buffer两种方式的效率会明显优于加号拼接与fmt拼接。
func getRandomString(n int) string {
var tmp = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
ans := make([]uint8, 0, n)
for i := 0; i < n; i++ {
ans = append(ans, tmp[rand.Intn(len(tmp))])
}
return string(ans)
}
func plusOperatorJoin(n int, s string) string {
var ans string
for i := 0; i < n; i++ {
ans = ans + s
}
return ans
}
func sprintfJoin(n int, s string) string {
var ans string
for i := 0; i < n; i++ {
ans = fmt.Sprintf("%s%s", ans, s)
}
return ans
}
func stringBuilderJoin(n int, s string) string {
builder := strings.Builder{}
for i := 0; i < n; i++ {
builder.WriteString(s)
}
return builder.String()
}
func bytesBufferJoin(n int, s string) string {
buffer := new(bytes.Buffer)
for i := 0; i < n; i++ {
buffer.WriteString(s)
}
return buffer.String()
}
func benchmark(b *testing.B, f func(int, string) string) {
var str = getRandomString(100)
for i := 0; i < b.N; i++ {
f(10000, str)
}
}
func BenchmarkPlusOperatorJoin(b *testing.B) {
benchmark(b, plusOperatorJoin)
}
func BenchmarkSprintfJoin(b *testing.B) {
benchmark(b, sprintfJoin)
}
func BenchmarkStringBuilderJoin(b *testing.B) {
benchmark(b, stringBuilderJoin)
}
func BenchmarkBytesBufferJoin(b *testing.B) {
benchmark(b, bytesBufferJoin)
}
go test -bench="Join$" -benchmem tt_test.go
goos: darwin
goarch: arm64
BenchmarkPlusOperatorJoin-8 5 222485842 ns/op 5040446776 B/op 10348 allocs/op
BenchmarkSprintfJoin-8 3 461412930 ns/op 10138715749 B/op 53784 allocs/op
BenchmarkStringBuilderJoin-8 3922 296319 ns/op 5861810 B/op 30 allocs/op
BenchmarkBytesBufferJoin-8 5234 230001 ns/op 4296696 B/op 15 allocs/op
PASS
ok command-line-arguments 7.863s
2.2.3.3 总结
- 在明确需要拼接的字符串数量以及数量不大的情况下,推荐使用+号拼接、
strings.Join拼接,这两者一次操作就能分配全部所需的内存,拼接效率较高 - 如果需要循环或多次进行调用,则
strings.Buidler、bytes.Buffer的性能会更加有优势,因为在内存容量不够时,新容量 = 2*旧容量+n,不像+号拼接每次分配的内存仅够此次拼接使用,余量不够。更加明确的将bytes.Buffer方法性能是低于strings.Builder的,bytes.Buffer转化为字符串时重新申请了一块空间,存放生成的字符串变量,不像strings.Buidler这样直接将底层的[]byte转换成了字符串类型返回,这就占用了更多的空间。 - 函数
fmt.Sprintf还是不适合进行字符串拼接,无论拼接字符串数量多少,性能损耗都很大,更适合字符串格式化;
2.3 字符串与字符切片
由于字符串的只读特性,在需要对字符串进行修改时,通常只有如下两种方式:
- 直接将修改后的字符串重新赋值给之前的变量
- 将字符串转换为[]byte切片,对其修改后,再转换成字符串类型
第二种方法涉及字符串与字符切片之间的两次转换,编译器底层实现时,涉及内存重新分配以及内容的拷贝,效率随着字符长度的增加而降低。由于字符串与切片相近的底层数据结构,有一种高效但不安全的方式,相见2.3.3节。
// 将hello world 改成kello word
s := "hello word"
s = "kello word" // 第一种直接赋值
b := []byte(s) // 第二种先转成[]byte进行修改
b[0] = 'k'
s = string(b)2.3.1 字符切片转字符串
字符切片转换为字符串底层调用的是runtime.slicebytetostring 函数,该函数会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,
- 如果处理的是长度为 0的字符切片,直接返回空字符串""。
- 如果是长度为 1 的字节数组,优化处理过程(核心是避免内存分配与复制),用字节值
*ptr作为索引,定位到staticuint64s中的对应元素(staticuint64s包含所有 256 个可能的字节值(0x00-0xFF)),然后通过stringStructOf获取字符串底层结构(含数据指针和长度)。 - 其他情况,若调用方提供临时缓冲区
buf且其长度>= n,则优先复用该缓冲区;否则调用mallocgc在堆上分配新内存。然后通过memmove将原字节数据复制到新分配/复用的内存。
// slicebytetostring converts a byte slice to a string.
// It is inserted by the compiler into generated code.
// ptr is a pointer to the first element of the slice;
// n is the length of the slice.
// Buf is a fixed-size buffer for the result,
// it is not nil if the result does not escape.
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
// 如果需要处理的切片长度为0,直接返回空字符串
if n == 0 {
// Turns out to be a relatively common case.
// Consider that you want to parse out data between parens in "foo()bar",
// you find the indices and convert the subslice to string.
return ""
}
if raceenabled {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostring))
}
if msanenabled {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
// 如果字符切片长度为1,直接进行底层数据结构之间的转换,避免内存分配和复制
if n == 1 {
// Go 预初始化一个全局数组 staticuint64s,包含所有 256 个可能的字节值(0x00-0xFF)。
p := unsafe.Pointer(&staticuint64s[*ptr])
if sys.BigEndian {
// 大端序 (BigEndian) 需偏移 7 字节(因字符串需取首字节,大端序首字节在高地址)
p = add(p, 7)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = 1
return
}
// 若调用方提供临时缓冲区 buf 且其长度 >= n,则优先复用该缓冲区。
// 否则调用 mallocgc 在堆上分配新内存(GC 托管)。
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = n
// 通过 memmove 将原字节数据复制到新分配/复用的内存。
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return
}2.3.2 字符串转字符切片
当我们想要将字符串转换成 []byte 类型时,需要使用 runtime.stringtoslicebyte 函数,该函数会根据是否传入缓冲区(该缓冲区存在于调用者的栈)以及字符串的长度做出不同的处理:
-
当传入缓冲区时,或者需要转换的字符串长度小于32,它会使用传入的缓冲区存储
[]byte; -
当没有传入缓冲区时,或者需要转换的字符串长度大于32时,运行时会调用
runtime.rawbyteslice创建新的字节切片并将字符串中的内容拷贝过去;
// The constant is known to the compiler.
// There is no fundamental theory behind this number.
const tmpStringBufSize = 32
type tmpBuf [tmpStringBufSize]byte
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
// 优先使用临时缓冲区 (栈内存)
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{} // 清空缓冲区
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s) // 字符串拷贝到字符切片数组中
return b
}2.3.3 unsafe转换
2.3.3.1 万能的 unsafe.Pointer 指针
在 go 中,任何类型的指针 *T 都可以转换为 unsafe.Pointer 类型的指针,它可以存储任何变量的地址。同时,unsafe.Pointer 类型的指针也可以转换回普通指针,而且可以不必和之前的类型 *T 相同。另外,unsafe.Pointer 类型还可以转换为 uintptr 类型,该类型保存了指针所指向地址的数值,从而可以使我们对地址进行数值计算。以上就是强转换方式的实现依据。
2.3.3.2 unsafe指针转换
使用强转换虽然在效率上比安全转换高,但是其不安全性也较高,直接通过底层的转换虽然能改变数据类型,但其底层属性还是会得到保留。例如将string强转为[]byte后,如果直接对[]byte进行修改,会直接panic,因为该数据内存是只读的,不能直接被修改。
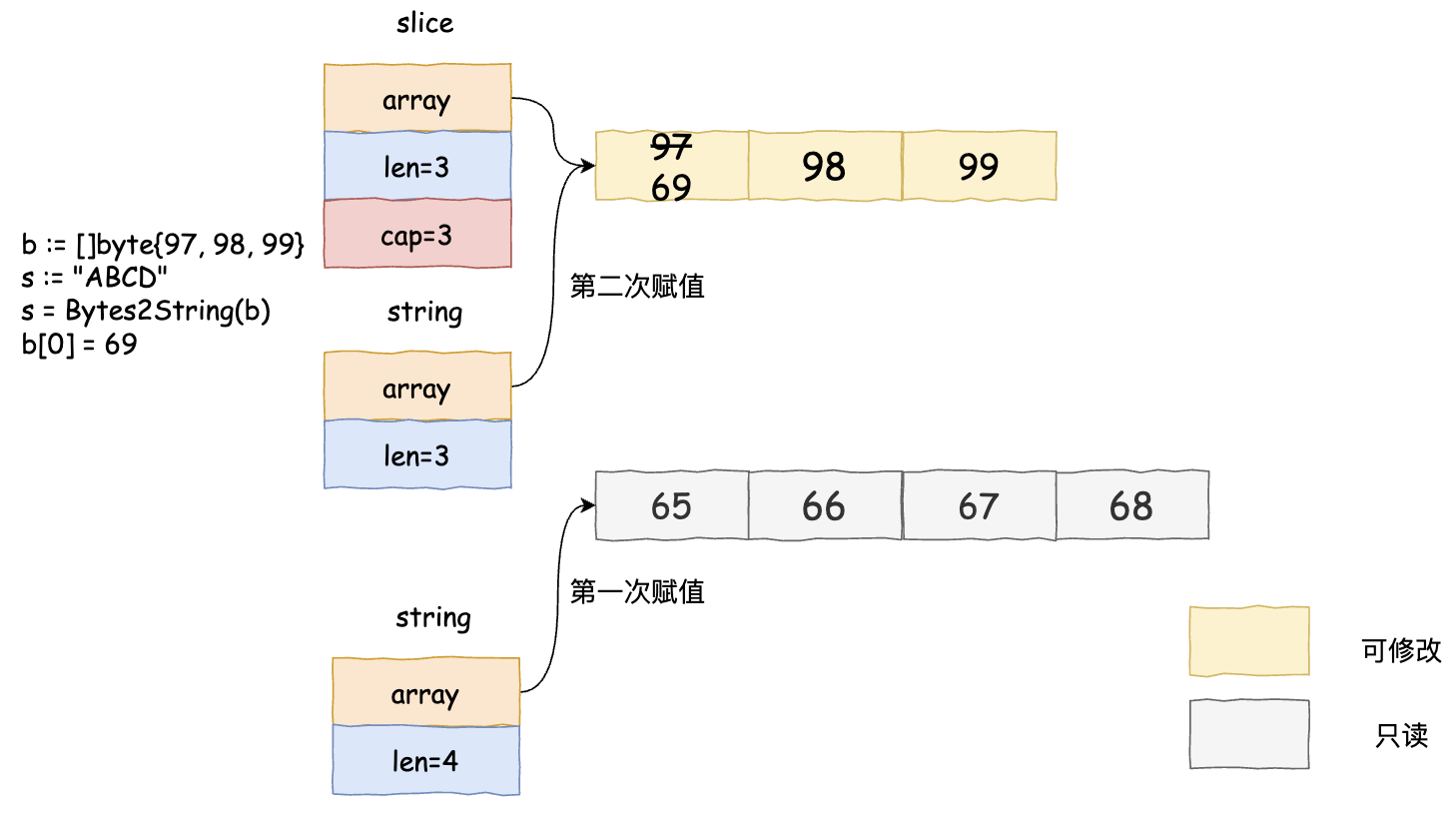
- 使用unsafe指针直接进行字符切片转字符串操作时,由于slice包含string,且两者的前两个成员变量内存布局一致,直接使用unsafe.Pointer转换成string类型即可。
// 字符切片转字符串
func Bytes2String(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
type stringStruct struct {
str unsafe.Pointer
len int
}
func main() {
a := []byte{97, 98, 99}
b := "ABCD"
b = Bytes2String(a)
a[0] = 69
fmt.Println(b) // Ebc
fmt.Println(*(*stringStruct)(unsafe.Pointer(&b))) // {0x1400001c092 3}
fmt.Println(&a[0]) // 0x1400001c092,b的字符数组首地址与a一致
}
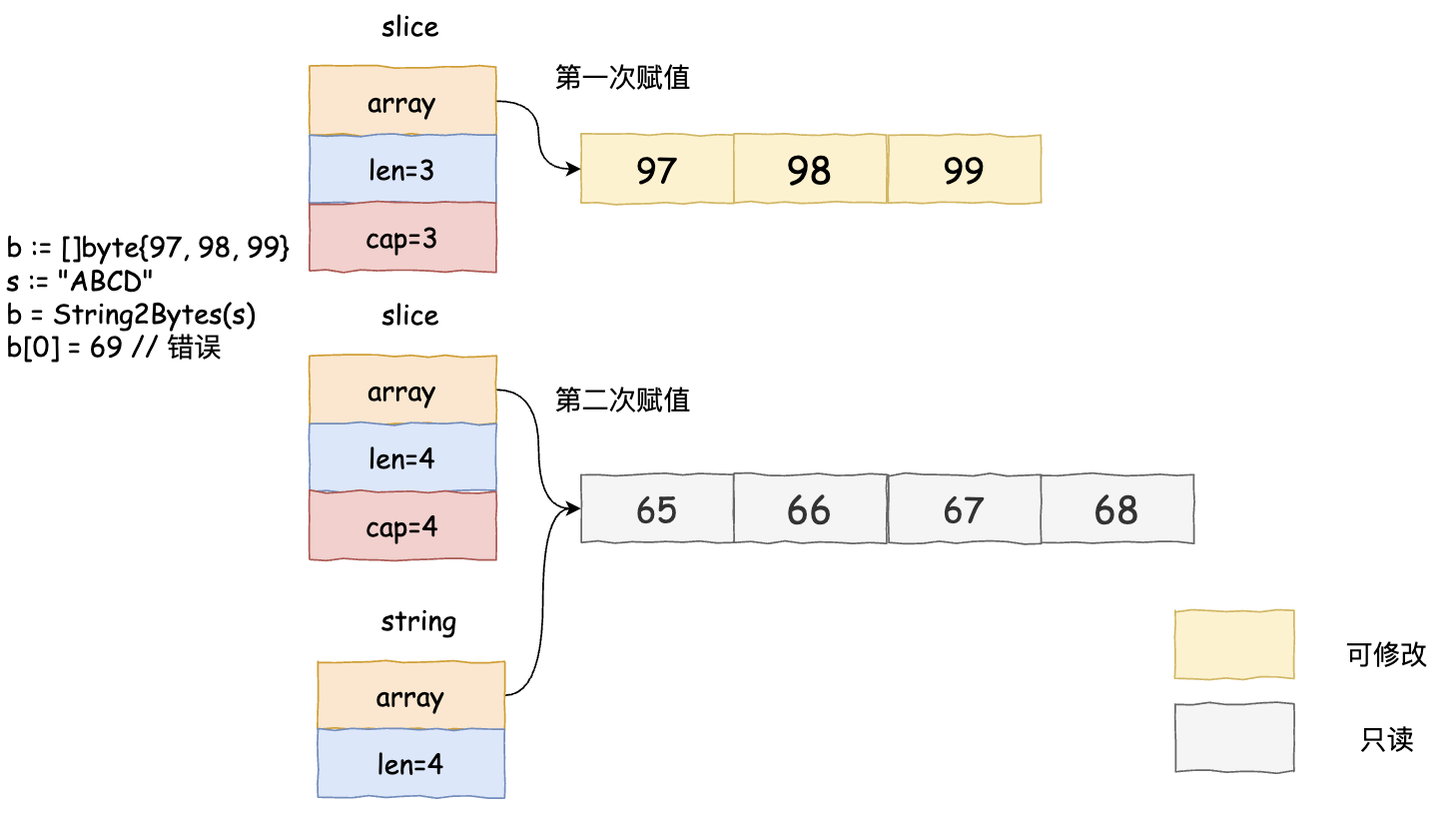
- 字符串转切片时,由于切片底层比字符串串多一个cap成员变量,因此需要使用字符串的len进行补充。此外,需要特别注意的是,字符串指向的底层数组拥有只读特性,就算起转变为了[]byte,也无法通过下标索引对其进行修改!
// 字符串转字符切片
func String2Bytes(s string) []byte {
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func main() {
c := []byte{97, 98, 99}
d := "ABCD"
c = String2Bytes(d)
c[0] = 69 // 直接panic,该地址无法修改
// unexpected fault address 0x104416686
// fatal error: fault
// [signal SIGBUS: bus error code=0x1 addr=0x104416686 pc=0x104416260]
}
2.3.4 性能对比
package main
import (
"bytes"
"testing"
)
// 测试强转换功能
func TestBytes2String(t *testing.T) {
x := []byte("Hello Gopher!")
y := Bytes2String(x)
z := string(x)
if y != z {
t.Fail()
}
}
// 测试强转换功能
func TestString2Bytes(t *testing.T) {
x := "Hello Gopher!"
y := String2Bytes(x)
z := []byte(x)
if !bytes.Equal(y, z) {
t.Fail()
}
}
// 测试标准转换 string() 性能
func Benchmark_NormalBytes2String(b *testing.B) {
x := []byte("Hello Gopher! Hello Gopher! Hello Gopher!")
for i := 0; i < b.N; i++ {
_ = string(x)
}
}
// 测试强转换 []byte 到 string 性能
func Benchmark_Byte2String(b *testing.B) {
x := []byte("Hello Gopher! Hello Gopher! Hello Gopher!")
for i := 0; i < b.N; i++ {
_ = Bytes2String(x)
}
}
// 测试标准转换 []byte 性能
func Benchmark_NormalString2Bytes(b *testing.B) {
x := "Hello Gopher! Hello Gopher! Hello Gopher!"
for i := 0; i < b.N; i++ {
_ = []byte(x)
}
}
// 测试强转换 string 到 []byte 性能
func Benchmark_String2Bytes(b *testing.B) {
x := "Hello Gopher! Hello Gopher! Hello Gopher!"
for i := 0; i < b.N; i++ {
_ = String2Bytes(x)
}
}当字符串的长度超过32时,标准转换需要额外多一次内存分配。
$ go test -bench="." -benchmem
goos: darwin
goarch: amd64
pkg: workspace/example/stringBytes
Benchmark_NormalBytes2String-8 38363413 27.9 ns/op 48 B/op 1 allocs/op
Benchmark_Byte2String-8 1000000000 0.265 ns/op 0 B/op 0 allocs/op
Benchmark_NormalString2Bytes-8 32577080 34.8 ns/op 48 B/op 1 allocs/op
Benchmark_String2Bytes-8 1000000000 0.532 ns/op 0 B/op 0 allocs/op
PASS
ok workspace/example/stringBytes 3.170s
// string 改成 Hello Gopher! 标准转换就不需要再额外进行内存分配了
$ go test -bench="." -benchmem
goos: darwin
goarch: arm64
pkg: stringTest
Benchmark_NormalBytes2String-8 403976871 2.585 ns/op 0 B/op 0 allocs/op
Benchmark_Byte2String-8 1000000000 0.3129 ns/op 0 B/op 0 allocs/op
Benchmark_NormalString2Bytes-8 317796328 3.782 ns/op 0 B/op 0 allocs/op
Benchmark_String2Bytes-8 1000000000 0.3128 ns/op 0 B/op 0 allocs/op
PASS
ok stringTest 4.034s

















 1734
1734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









