









字符集
简介
比特(bit)是计算机处理的最小单位,值为0或者1,一个字节包含8个bit,最大值(11111111)为255,最小值(00000000)为0;一个字节能代表256个数字,二个字节可以表示65563个数字,更多的字节可以有更多种组合,就可以表示更大的数值范围,整数可以这样存,那么字符呢?
一堆二进制0或者1,无论怎么也算不出A,那就通过数字中转一下,只要给A指定一个数值编号,要存储A时就存储这个数值,要读取时按照这个映射关系找到这个字符,像这样收录 许多字符然后给他们一一编号,得到一个字符编号对照表,这就是字符集。
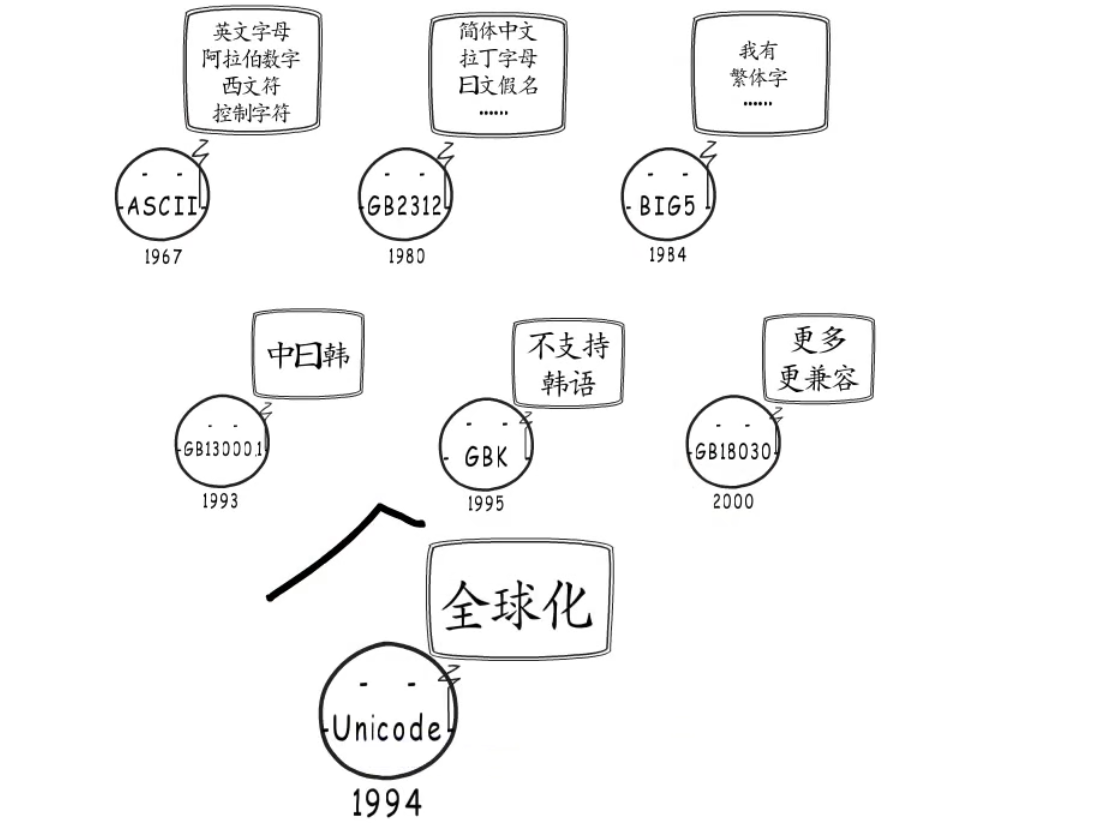
字符集相关的发展历程如下:
-
ASCII字符集ASCII字符集只收录了128个字符,其扩展字符集也只有256个。 -
由于
ASCII里没有汉字,所以出现了GB2312字符集 -
由于
GB2312里没有繁体字,所以出现了BIG5字符集 -
Unicode字符集但是
BIG5还有许多字符没有被收录,与其不断的推出收录更多字符的的字符集,莫不如本着全球化统一标准的目的,制作一个通用字符集,Unicode学术学会就是这样做的,这个字符集就是Unicode;Unicode字符集于1990年开始研发并于1994年正式公布,实现了跨语言跨平台的文本转换与处理。
下图为字符集发展历程:
编码
定长编码
所谓定长编码就是用固定的长度去存储编译字符,最常见的定长编码例子就是:ASCII码。
在ACSII中将一个字符表示成8位特定的二进制数,举例说明如下:
| 字符 | 十进制 | 二进制 |
|---|---|---|
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| C | 67 | 01000011 |
定长编码的优点是简单、高效,不需要额外的数据协商和传输开销。但是,它也有一些缺点。首先,它不够灵活,不能适应变长的数据结构和协议。其次,它浪费空间,因为某些数据元素可能没有充分利用其分配的固定长度。
例如:
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母"A"用ASCII编码是十进制的65,二进制的01000001;
字符"0"用ASCII编码是十进制的48,二进制的00110000;
汉字"中"已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的 01001110 00101101。
你可以猜测,如果把ASCII编码的"A"用Unicode编码,只需要在前面补0就可以,因此,"A"的Unicode编码是00000000 01000001。
如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以出现了变长编码。
变长编码
变长编码(Variable-length encoding)是指在编码时,不同的符号可能占用不同的比特位数。它的主要特点是可以提高编码效率,因为在实际应用中不同的符号的出现频率可能是不同的(小编号少占字节,大编号多占字节)。如果使用固定长度编码,则会浪费很多比特,降低数据传输效率。
在计算机科学中,常见的变长编码有霍夫曼编码、算术编码、游程编码等。在文本编码中,UTF-8 也是一种变长编码。
对于 UTF-8 编码,一个字符所占用的字节数是变化的,可以是 1、2、3 或 4 个字节,具体取决于字符的 Unicode 编码值。因此,UTF-8 是一种非常常用的变长编码方式。UTF-8编码模版格式如下:
| 占用字节数 | 十进制编码范围 | 模版 |
|---|---|---|
| 1字节 | [0, 127] | 0xxxxxxx |
| 2字节 | [128,2047] | 110xxxxx 10xxxxxx |
| 3字节 | [2048, 65535] | 1110xxxx 10xxxxxx 10xxxxxx |
| 4字节 | [65536, 2097151] | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5字节 | [2097152, 67108863] | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6字节 | [67108863, 2147483647] | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
根据上述UTF-8字符编码,归纳总结说明下字节模版的使用:
-
对于单字节字符,最高位为 0,后面7位为这个字符的
Unicode码例如:字母
e,属于标准ASCII码,标准ASCII码兼容UTF-8编码,两者是在0-127编码对应的值是一致的。字母e的~编码为101, 该编码在【0,127】范围呢属于单字节字符,按照规则属于用对应模版0xxxxxxx,现将101转为二进制:1100101,则UTF-8编码为:01100101,UNICODE编码为:U+0065,如下图所示: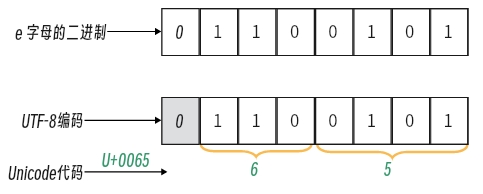
-
对于
n字节字符(n> 1),第一个字节的前n位均为1,第n+1位为0,后面n-1字节的前两位均为10,剩下的位则为这个字符的Unicode码。例如汉字:
好,Unicode编码十进制编码为:22909,该编码十进制在在[2048, 65535]范围内,属于3字节长度编码,使用三字节模版1110xxxx 10xxxxxx 10xxxxxx,将十进制22909 转为二进制转为二进制1011001 01111101,最终得到UTF-8编码为:,UNICODE编码为:U+597D,如图:
UTF-8字符的判定
Go语言实现了UTF-8编码验证算法用于检查UTF-8编码数据,主要基于UTF-8的可变长编码特点设计了验证算法,UTF-8编码使用1到4个字节为每个字符编码,ASCII标准编码部分跟UTF-8编码一致,占用长度为1个字节。ASCII除了标准编码以外,则UTF-8使用自己的编码。
在Go中检验字符串是否为符合UTF-8规则的函数为:utf8.ValidString,源码如下:
func ValidString(s string) bool {
// 遍历字符串 s,每次取 8 个字节
for len(s) >= 8 {
// 将这 8 个字节转化为两个 uint32 类型的整数,然后判断是否有非 ASCII 字符
first32 := uint32(s[0]) | uint32(s[1])<<8 | uint32(s[2])<<16 | uint32(s[3])<<24
second32 := uint32(s[4]) | uint32(s[5])<<8 | uint32(s[6])<<16 | uint32(s[7])<<24
if (first32|second32)&0x80808080 != 0 {
break
}
s = s[8:]
}
n := len(s)
for i := 0; i < n; {
si := s[i]
if si < RuneSelf {
i++
continue
}
x := first[si]
// 如果该字符的 x 值是 xx,说明该字符不合法,返回 false
if x == xx {
return false
}
size := int(x & 7)
if i+size > n {
return false
}
accept := acceptRanges[x>>4]
// 如果该字符的下一个字符不在该字符的合法范围内,返回 false
if c := s[i+1]; c < accept.lo || accept.hi < c {
return false
} else if size == 2 {
// 如果该字符长度为 2,直接跳到下一个字符
} else if c := s[i+2]; c < locb || hicb < c {
// 如果该字符长度为 3,判断第三个字符是否在合法范围内
return false
} else if size == 3 {
// 如果该字符长度为 4,判断第三个和第四个字符是否在合法范围内
if c := s[i+3]; c < locb || hicb < c {
return false
}
}
i += size
}
return true
}
初看代码看似简单,但细看有点迷茫,因为代码设计非常巧妙,下面我们一步一步来拆分代码流程。
函数流程大致为:
- 遍历字符串
s,每次取8个字节编码数据判断其中是否存在非ASCII编码 (标准ASCII) 的数据
为什么每次取8个字节呢?为什么不一个一个字节取去判断呢?
在现实环境中,在校验一篇长篇英文文章的场景下(验证大量标准ASCII编码数据),如果验证算法采用单个字符比较的方式检查编码,直到循环检查完整个数据,算法的运行耗时大,性能有待提升。
针对UTF-8编码验证算法中处理标准ASCII编码字符检查次数多、运行耗时大的问题,可以利用并行化编程思想,一次同时处理多个标准ASCII编码字符的检查,减少比较的次数,加快验证速度,提升算法性能。 Go语言的UTF-8验证算法应用了基于并行化编程思想的算法优化方案,一次同时检查8个标准ASCII编码,大大提升了算法的运行性能。 那如下实现一次同时检查8个标准ASCII编码呢?这时候位运算就显示出它的特点来了。
那如何处理同时8个标准ASCII编码的检验呢?
我们知道单个标准ASCII编码字符十进制最大的值为127(即0x80),最简单的办法直接比较字符编码的十进制值大小,如下:
const (
RuneSelf = 0x80 //定义0x80为常量 RuneSelf
)
n := len(s)
for i := 0; i < n; {
si := s[i]
if si < RuneSelf {
i++
}
}
如果值小于 0x80即为ASCII编码,但还有一种办法就是利用位运算。
将要比较的字符转为二进制模式,再跟0x80(10000000 )的二进制进行 & 运算,如果符合ASCII标准,则结果为0,如果结果不是0,则这个字符并不是标准ASCII编码范围内,则进行其他类型检测。
而8个如何处理呢?举个例子说明golang中是怎么处理的吧!例如:字符串 “ABCDEFGH你好世界“ , 我们要同时检查8个标准ASCII编码,则流程如下:
-
每次取8个字节数据进行操作,此处首8个字节数据为:
ABCDEFGH, ASCII码以及二进制如下: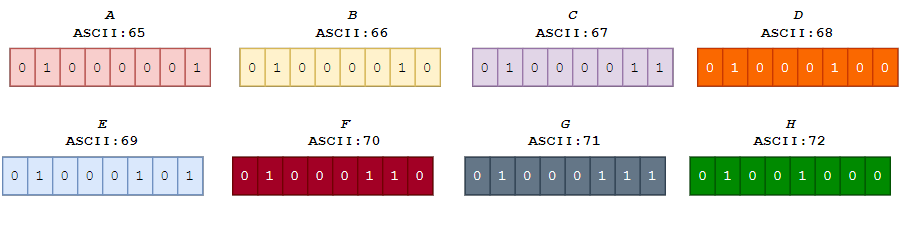
-
将取到的8字节数据按每4个字节组成一组组成一个
unit32的整数,此处ABCD组成一个4字节(32bit)二进制数据first32, 而EFGH组成另外一个4字节二进制数据second32, 方法如下first32 := A | B << 8 | C << 16 | D << 24 second32 := E | F << 8 | G << 16 | H << 24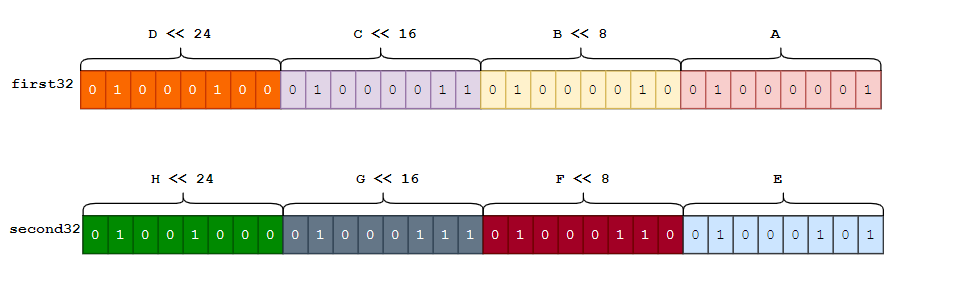
-
将两组4字节的二进制数据进行
|操作(first32 |second32),并最将终结果中的每个字节数据与0x80进行&操作,四个字节则与0x80808080进行&运算,如果值为0,则8字节数据全部为标准ASCII编码,否则这些字符中含有其他非标准ASCII编码数据。(first32|second32)&0x80808080 -
如果该字节数据编码非标准
ASCII编码(超出127范围),检查是否符合UTF-8编码的其他码点规则UTF-8编码码点判断规则如下:-
UTF-8最多可用到6个字节,其有效bit数为31,而一般文字以及符号编码都用到了1-4字节 -
0xC0(192),0xC1(193),0xF5—0xFF(245-255)不会出现在UTF8编码中 -
首字节不会存在
0x80—0xBF(128-191)范围,而次字节范围必须在0x80—0xBF(128-191)范围内 -
首字节值为 0xE0(224),次字节取值必须在 0xA0 - 0xBF(160-191)之间
-
首字节值为 0xED(237),次字节取值必须在 0x80 - 0x9F(128-159)之间
-
首字节值为 0xF0 (240),次字节取值必须在 0x90 - 0xBF(144-191)之间
-
首字节值为 0xF4 (244),次字节取值必须在 0x80 - 0x8F(128-143)之间
根据这些规则,
Go语言定义出了次字节取值范围的acceptRanges变量以及一些常用的相关变量:const( // UTF-8字符的次字节的一般取值范围,即UTF-8编码模版中[110xxxxx 10xxxxxx]的 10XXXXXX的最大值和最小值 locb = 0b10000000 // UTF-8字符的次字节最小取值128,十六进制表示为0x80 hicb = 0b10111111 //UTF-8字符的次字节最大取值191,十六进制表示为0xBF ) // acceptRange 给出次字节的取值范围 type acceptRange struct { lo uint8 // 次字节最小取值 hi uint8 // 次字节最大取值 } var acceptRanges = [16]acceptRange{ //普通字符次字节取值范围[128-191],范围之外为无效编码(即二进制位不是以 10 开头) 0: {locb, hicb}, /** 三字节特殊字符(首字节为 0xE0[ASCII:224])的次字节 1:如果次字节低于 0xA0(ASCII:160) 则该字符应该用两个字节表示,而不是三个字节 2:如果次字节高于 hicb(ASCII:191) 则该字节为无效编码(即二进制位不是以 10 开头) */ 1: {0xA0, hicb}, /** 三字节特殊字符(首字节为 0xED[ASCII:237])的次字节 1:如果次字节低于 locb(ASCII:128) 则该字节为无效编码(即二进制位不是以 10 开头) 2:如果次字节高于 0x9F(ASCII:159) 则该字符为代理区字符([ED(237) A0(160) 80(128)] - [ED(237) BF(191) BF(191)]) */ 2: {locb, 0x9F}, /** 四字节特殊字符(首字节为 0xF0[ASCII:240])的次字节 1:如果次字节低于 0x90(ASCII:144) 则该字符应该用三个字节表示,而不是四个字节。 2:如果次字节高于 hicb(ASCII:191) 则该字节为无效编码(即二进制位不是以 10 开头) */ 3: {0x90, hicb}, /** 四字节特殊字符(首字节为 0xF4[ASCII:244])的次字节 1:如果次字节低于 locb(ASCII:128) 则该字节为无效编码(即二进制位不是以 10 开头) 2:如果次字节高于 0x8F(ASCII:143) 则该字符超出 Unicode 范围(超出 MaxRune) */ 4: {locb, 0x8F}, }除了定义上述变量以外,
Go还将编码值为【0-255】范围内的所有首字节编码根据字节长度以及次字节取值范围等信息进行进行分类, 这样可以根据UTF-8首字节就能很快确定该编码的字节长度以及次字节等信息。首字节编码分为:
xx、as、s1、s2、s3、s4、s5、s6、s7九类,用十六进制常量的高位和低位分别表示。高位:“次字节取值范围列表” 的索引,如果高位是
F则表示字符是单字节字符低位:字符的编码长度,如果高位是
F则低位表示单字节字符的状态:0(有效)、1(无效)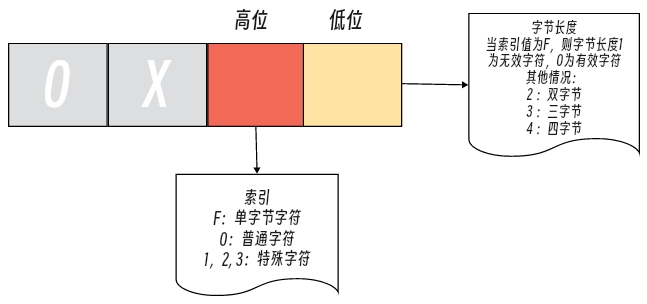
分类代码如下:
const( xx = 0xF1 //无索引,长度1,表示无效 UTF-8编码 as = 0xF0 //无索引,长度1,表示普通标准ASCII字符(ASCII编码 0-127范围内) s1 = 0x02 //索引值0,长度2, 表示普通 "双字节字符"的首字节 s2 = 0x13 //索引值1,长度3, 表示特殊 "三字节字符"的首字节 s3 = 0x03 //索引值0,长度3, 表示普通 "三字节字符"的首字节 s4 = 0x23 //索引值2,长度3, 表示特殊 "三字节字符"的首字节 s5 = 0x34 //索引值3,长度4, 表示特殊 "四字节字符"的首字节 s6 = 0x04 //索引值0,长度4, 表示普通 "四字节字符"的首字节 s7 = 0x44 //索引值4,长度4, 表示特殊 "四字节字符"的首字节 ) var first = [256]uint8{ // 1 2 3 4 5 6 7 8 9 A B C D E F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x00-0x0F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x10-0x1F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x20-0x2F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x30-0x3F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x40-0x4F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x50-0x5F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x60-0x6F as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x70-0x7F // 1 2 3 4 5 6 7 8 9 A B C D E F xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0x80-0x8F xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0x90-0x9F xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xA0-0xAF xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xB0-0xBF xx, xx, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, // 0xC0-0xCF s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, // 0xD0-0xDF s2, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s4, s3, s3, // 0xE0-0xEF s5, s6, s6, s6, s7, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xF0-0xFF } -
除了 utf8.ValidString 函数外,其实 utf8.Valid函数判断也类似。
String底层原理
结构体
当查看string类型的变量所占的空间大小时,会发现是16字节(64位机器)。
str := "hello"
fmt.Println(unsafe.Sizeof(str)) // 16
为什么会是16字节呢,我们来底层一看究竟。
字符串(string)是 Go 语言提供的一种基础数据类型,它是一个不可变的字符序列。
实际上,string 是一个结构体, Go 1.17 及之前版本中定义的字符串底层结构为:
// file: /runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
在 Go 1.18 中引入的字符串底层结构,它与 stringStruct 基本相同,但是将指向字符串数据的指针类型从 unsafe.Pointer 改为了 uintptr,使得更方便地在不同平台上进行字符串内存地址的转换,定义为:
// file: /reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}
Data:一个指针,指向存储实际字符串的内存地址,该内存地址存储着的值是个[]byte类型切片。64位机器下占8个字节。Len: 字符串的长度。64位机器下占8个字节。与切片类似,在代码中我们可以使用len()函数获取这个值。注意,len存储实际的字节数,而非字符数。所以对于非单字节编码的字符,结果可能让人疑惑。后面会详细介绍多字节字符。
需要注意的是,stringStruct 和 StringHeader 虽然定义方式不同,但它们所表示的字符串底层结构是等价的。在 Go 1.18 及之后版本中,可以通过 (*StringHeader)(unsafe.Pointer(&str)) 将字符串转换为 StringHeader,然后进行底层操作。
我们通过下面程序:
package main
import "fmt"
func main() {
s := "hello"
fmt.Println(s)
}
执行 go build -gcflags=-S main.go 查看 hello 字符串底层结构的内存存储的信息为:
go build -gcflags=-S main.go
......
go:string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
......
从上述编译信息可以看出,
-
字符串的存储是实际上是一片连续的内存空间;
-
如上信息
go:string."hello" SRODATA dupok size=5,SRODATA该标识代表只读,意味着字符串会分配到只读的内存空间,是一个不可改变的字节序列,不可修改; -
由于只读的特性,字母相同字符串
l都被存储为同一个地址上,可以得出相同字符串面值常量通常对应同一个字符串常量;
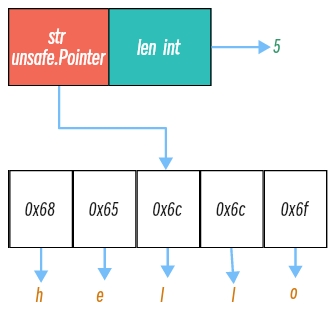
根据信息,得hello字符串的的存储结构图:
String修改
Go中的字符串符合Unicode标准,并且采用UTF-8编码。字符串底层其实也是byte类型切片。通过下面的示例,打印查看具体的字节内容:
package main
import (
"fmt"
)
func main() {
s := "hello"
for _, v := range s {
fmt.Println(v)
}
}
运行上述程序,打印结果为:
104
101
108
108
111
上面代码打印的内容,就是每一个字符所表示的字节码,既然字符串底层是由byte组成的切片,那可以用下标方式去修改字符串吗?如下示例:
func main() {
s := "hello"
s[0] = 72
fmt.Println(s)
}
通常听string不能修改,其实就是指的上面代码这种方式。通过这种方式修改会报错::cannot assign to s[0] (value of type byte) 。
为什么Go中的字符串不能通过下标的方式来进行修改呢? 这是因为字符串的结构所决定的,string结构如下:
type stringStruct struct {
str unsafe.Pointer
len int
}
Go中的字符串的数据结构体是由一个指针和长度组成的结构体,该指针指向的一个切片才是真正的字符串值。
那我们要想通过下标的方式去修改值该怎么办呢?这时候,就需要通过切片的方式来定义,然后在转成字符串,如下:
func main() {
s := []byte("hello")
s[0] = 'H'
fmt.Println(string(s))
}
//output Hello
上面分析了为什么字符串不能使用下标去赋值,回过来解答一下日常开发中的赋值方式,示例如下:
func main() {
s := "hello"
s = "Hello"
fmt.Println(s)
}
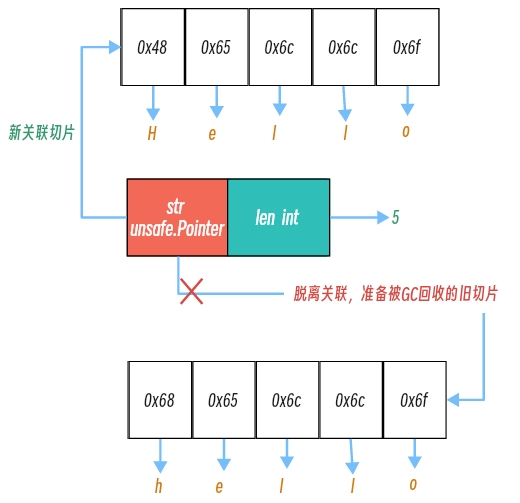
那为什么这种场景下又可以给字符串重新赋值呢? 这是因为,在Go的底层其实是新创建了一个[]byte{}类型的切片,将变量s中的指针指向了新的内存空间地址(也就是这里的Hello)。原有的hello内存空间会随着垃圾回收机制被回收掉。
如下图:
除了Go语言外,很多编程语言的字符串也都是不可变的,这种不可变的特性可以保证我们不会引用到意外发生改变的值。
String 解析
在定义字符串的时候,我们经常会有下面两种写法:
s := "hello"
s := `hello`
一种是使用 双引号包含字符串,另外一种是反引号包含字符串,两种定时方式都能实现字符串的定义,但这两种定义有啥不同呢?
这里面就涉及到了解析器会在词法分析阶段解析不同模式定义的字符串的不同处理方式,但最终都是词法分析阶段会对源文件中的字符串进行切片和分组,将原有无意义的字符流转换成 Token 序列。如下:
// go/src/cmd/compile/internal/syntax/scanner.go
func (s *scanner) next() {
...
switch s.ch {
...
case '"':
s.stdString()
case '`':
s.rawString()
...
解析器会使用 s.stdString() 和 s.rawString()分别来解析双引号和反引号的字符串。
双引号解析
解析双引号的标准字符串是由 cmd/compile/internal/syntax/scanner.go 中的stdString方法来处理的:
// cmd/compile/internal/syntax/scanner.go
func (s *scanner) stdString() {
//定义一个标记,表示字符串字面量是否解析成功
ok := true
//获取下一个字符,并将其存储在s.ch中
s.nextch()
//进入一个无限循环,直到遇到字符串结束符(")或出现错误
for {
//如果当前字符是字符串结束符,则跳出循环
if s.ch == '"' {
s.nextch()
break
}
//如果当前字符是转义符(\),则跳过该字符并调用escape()方法解析转义字符
if s.ch == '\\' {
s.nextch()
if !s.escape('"') {
ok = false
}
continue
}
//如果当前字符是换行符,则输出错误信息并设置解析标记为false
if s.ch == '\n' {
s.errorf("newline in string")
ok = false
break
}
//如果当前字符小于0(即已经到达文件尾),则输出错误信息并设置解析标记为false
if s.ch < 0 {
s.errorAtf(0, "string not terminated")
ok = false
break
}
//获取下一个字符,并将其存储在s.ch中
s.nextch()
}
//据解析标记设置字符串字面量的类型和值。如果解析成功,则类型为StringLit,值为当前扫描位置到结束位置的字符串;否则类型也为StringLit,但值为空字符串
s.setLit(StringLit, ok)
}
从上述代码可以得出 Go 语言处理标准字符串的逻辑:
-
标准字符串使用双引号表示开头和结尾;
-
标准字符串需要使用反斜杠
\来逃逸双引号; -
标准字符串不能出现如下所示的隐式换行
\n,例如下列写法是错误的:str := "start end"
反引号解析
使用双引号和其它语言没有什么大的区别,如果字符串内部出现双引号,要使用 \ 进行转义;但使用反引号则不需要,方便进行更加复杂的数据类型,比如 Json:
s := `{"name": "sween", "age": 18}`
使用反引号声明的原始字符串的解析规则就 cmd/compile/internal/syntax/scanner.go 中的rawString方法来处理,它也支持使用复杂的多行字符串:
// cmd/compile/internal/syntax/scanner.go
func (s *scanner) rawString() {
ok := true
s.nextch() //获取下一个字符,并将其存储在s.ch中
for {
if s.ch == '`' { // 如果是反引号,表示原生字符串结束
s.nextch() // 继续获取下一个字符
break // 跳出循环
}
if s.ch < 0 { // 如果扫描到输入结束,表示原生字符串未结束
s.errorAtf(0, "string not terminated") // 报错,提示原生字符串未结束
ok = false
break
}
s.nextch() // 继续获取下一个字符,即原生字符串的内容
}
s.setLit(StringLit, ok) // 将扫描出的原生字符串内容设置为当前词法元素
}
func (s *scanner) setLit(kind LitKind, ok bool) {
s.nlsemi = true
s.tok = _Literal
s.lit = string(s.segment())
s.bad = !ok
s.kind = kind
}
无论是标准字符串还是原始字符串都会被标记成 StringLit 并传递到语法分析阶段。
String 拼接
字符串可以通过+进行拼接,示例 :
package main
import "fmt"
func main() {
s := "hello, go" + "lang"
fmt.Println(s)
}
输出结果: golang。
底层编译器是如何实现这个功能的呢?
在编译阶段构建抽象语法树时,等号右边的"hello, go" + "lang"会被解析为一个字符串相加的表达式(AddStringExpr)节点,该表达式的操作op为OADDSTR。相加的各部分字符串被解析为节点Node列表,并赋给表达式的List字段:
// go/src/cmd/compile/internal/ir/expr.go
// An AddStringExpr is a string concatenation Expr[0] + Exprs[1] + ... + Expr[len(Expr)-1].
type AddStringExpr struct {
miniExpr
List Nodes
Prealloc *Name
}
func NewAddStringExpr(pos src.XPos, list []Node) *AddStringExpr {
n := &AddStringExpr{}
n.pos = pos
n.op = OADDSTR
n.List = list
return n
}
在构建抽象语法树时,会遍历整个语法树的表达式,在遍历的过程中,识别到操作Op的类型为OADDSTR,则会调用walkAddString对字符串加法表达式进行进一步处理::
// go/src/cmd/compile/internal/walk/expr.go
func walkExpr(n ir.Node, init *ir.Nodes) ir.Node {
...
n = walkExpr1(n, init)
...
return n
}
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
...
case ir.OADDSTR:
return walkAddString(n.(*ir.AddStringExpr), init)
...
}
...
}
walkAddString能帮助我们在编译期间选择合适的函数对字符串进行拼接,该函数会根据带拼接的字符串数量选择不同的逻辑:
- 如果小于或者等于
5个,那么会调用 则会调用运行时的字符串拼接concatstring2-concatstring5函数 等一系列函数; - 如果超过
5个,那么会选择runtime.concatstrings传入一个数组切片;
func walkAddString(n *ir.AddStringExpr, init *ir.Nodes) ir.Node {
// 获取参数数量
c := len(n.List)
// 如果参数数量小于 2,直接报错退出
if c < 2 {
base.Fatalf("walkAddString count %d too small", c)
}
// 初始化 buf 节点,如果字符串中没有转义字符且字符串长度小于 32 字节,则分配栈空间
buf := typecheck.NodNil()
if n.Esc() == ir.EscNone {
sz := int64(0)
for _, n1 := range n.List {
if n1.Op() == ir.OLITERAL {
sz += int64(len(ir.StringVal(n1)))
}
}
if sz < tmpstringbufsize {
buf = stackBufAddr(tmpstringbufsize, types.Types[types.TUINT8])
}
}
// 构建参数列表,包含 buf 节点和所有字符串节点
args := []ir.Node{buf}
for _, n2 := range n.List {
args = append(args, typecheck.Conv(n2, types.Types[types.TSTRING]))
}
// 根据参数数量选择调用的 runtime 函数
var fn string
if c <= 5 {
fn = fmt.Sprintf("concatstring%d", c)
} else {
fn = "concatstrings"
t := types.NewSlice(types.Types[types.TSTRING])
slice := ir.NewCompLitExpr(base.Pos, ir.OCOMPLIT, t, args[1:])
slice.Prealloc = n.Prealloc
args = []ir.Node{buf, slice}
slice.SetEsc(ir.EscNone)
}
// 构造调用 runtime 函数的节点
cat := typecheck.LookupRuntime(fn)
r := ir.NewCallExpr(base.Pos, ir.OCALL, cat, nil)
r.Args = args
r1 := typecheck.Expr(r)
// 递归处理节点
r1 = walkExpr(r1, init)
r1.SetType(n.Type())
return r1
}
其实无论使用 concatstring2-concatstring5 中的哪一个,最终都会调用 runtime.concatstrings ,它会先对遍历传入的切片参数,再过滤空字符串并计算拼接后字符串的长度:
// go/src/runtime/string.go
const tmpStringBufSize = 32
type tmpBuf [tmpStringBufSize]byte
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}
concatstrings 函数的作用是将多个字符串连接成一个字符串,并返回这个连接后的字符串。这个函数接收两个参数:一个是指向缓冲区的指针 buf,另一个是要连接的字符串数组 a。
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
// 循环遍历字符串数组a
for i, x := range a {
n := len(x)
if n == 0 { // 如果字符串为空,跳过此次循环
continue
}
if l+n < l { // 判断连接后的字符串长度是否超出int类型的表示范围
throw("string concatenation too long")
}
l += n // 累加字符串长度
count++ // 累加连接的字符串数量
idx = i // 记录最后一个非空字符串在数组中的索引
}
// 如果连接的字符串数量为0,返回空字符串
if count == 0 {
return ""
}
// 如果连接的字符串数量为1并且buf不为nil或者最后一个非空字符串不在栈上,返回最后一个非空字符串
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
// 如果需要连接的字符串数量大于1或者buf不为nil,创建一个新的字符串
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x) // 将字符串x的内容拷贝到b中
b = b[len(x):] // 更新b的位置
}
return s // 返回连接后的字符串
}
类型转换
-
string 转换成 []byte
-
标准模式 - []byte(string)
当我们想要将字符串转换成
[]byte类型时,一般标准模式是使用[]byte(string), 而转换内部则使用了runtime.stringtoslicebyte函数。runtime.stringtoslicebyte底层的实现如下:const tmpStringBufSize = 32 type tmpBuf [tmpStringBufSize]byte func stringtoslicebyte(buf *tmpBuf, s string) []byte { //声明一个 []byte 类型的变量 b,用来存储转换后的字节切片 var b []byte //判断传入的临时缓冲区是否为 nil,且字符串 s 的长度是否小于等于缓冲区的长度。 //如果是,则将缓冲区清空并重置,然后将缓冲区的前 len(s) 个字节切出来,赋值给变量 b; //否则,调用 rawbyteslice 函数分配一个新的字节切片,并将其赋值给变量 b。 if buf != nil && len(s) <= len(buf) { *buf = tmpBuf{} b = buf[:len(s)] } else { b = rawbyteslice(len(s)) } //将字符串 s 的内容拷贝到变量 b 中 copy(b, s) return b } // rawbyteslice 分配一个指定大小的字节数组 func rawbyteslice(size int) (b []byte) { // 计算数组需要的容量 cap := roundupsize(uintptr(size)) // 从堆上分配内存 p := mallocgc(cap, nil, false) // 如果容量不等于大小,则清空超出部分的内存 if cap != uintptr(size) { memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size)) } // 将分配的内存转换为字节数组类型 *(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)} return } -
强制转换模式
强制转换模式则是使用了
unsafe.Pointer以及string和slice在reflect包中对应的结构体reflect.StringHeader和reflect.SliceHeader的特性:import ( "fmt" "reflect" "unsafe" ) func String2Bytes(s string) []byte { sh := (*reflect.StringHeader)(unsafe.Pointer(&s)) bh := reflect.SliceHeader{ Data: sh.Data, Len: sh.Len, Cap: sh.Len, } return *(*[]byte)(unsafe.Pointer(&bh)) } func main() { s := "ABCDEFG" fmt.Println(String2Bytes(s)) }强制转换模式,能很直观的体现
unsafe.Pointer,reflect.StringHeader和reflect.SliceHeader等相关知识点,在此作为知识的深入探讨。
-
-
[]byte 转换成 string
-
标准模式 - string(bytes)
string(bytes)是最常用的将byte处于成string的方法,是标准的一种办法,其内部实现要使用runtime.slicebytetostring函数:func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string { // 如果长度为0,直接返回空字符串 if n == 0 { return "" } ...... // 如果长度为1,则直接返回一个字符串 if n == 1 { p := unsafe.Pointer(&staticuint64s[*ptr]) if goarch.BigEndian { p = add(p, 7) } return unsafe.String((*byte)(p), 1) } var p unsafe.Pointer // 如果 buf 不为 nil 且长度足够,可以直接使用 buf if buf != nil && n <= len(buf) { p = unsafe.Pointer(buf) } else { // 否则需要分配内存 p = mallocgc(uintptr(n), nil, false) } // 将 ptr 指向的内容复制到分配的内存中 memmove(p, unsafe.Pointer(ptr), uintptr(n)) return unsafe.String((*byte)(p), n) } -
强制转换模式
从
string和slice的运行时表达可以看出,除了SilceHeader多了一个int类型的Cap字段,Date和Len字段是一致的。所以,它们的内存布局是可对齐的,这说明我们就可以直接通过unsafe.Pointer进行转换。func main() { s := []byte{77, 89, 90} fmt.Println(*(*string)(unsafe.Pointer(&s))) }
-
对于标准转换,无论是从[]byte转string还是string转[]byte都会涉及底层数组的拷贝。而强转换是直接替换指针的指向,从而使得string和[]byte指向同一个底层数组。这样,当然后者的性能会更好。
但是Go是一门类型安全的语言,而安全的代价就是性能的妥协。但是,性能的对比是相对的,这点性能的妥协对于现在的机器而言微乎其微。另外强转换的方式,会给我们的程序带来极大的安全隐患。
在你不确定安全隐患的条件下,尽量采用标准方式进行数据转换。
当程序对运行性能有高要求,同时满足对数据仅仅只有读操作的条件,且存在频繁转换(例如消息转发场景),可以使用强转换。
String大致内容就到此~
参考资料
Draven https://draveness.me/golang/
幼麟实验室 https://space.bilibili.com/567195437
https://www.zhangshengrong.com/p/yOXDZvJyaB/














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









