




 本文深入解析了环形数组的概念、优势及其实现细节,通过具体的代码示例展示了如何进行高效的数据存取操作,并探讨了其在多线程环境下的表现。
本文深入解析了环形数组的概念、优势及其实现细节,通过具体的代码示例展示了如何进行高效的数据存取操作,并探讨了其在多线程环境下的表现。
一:环形数组
1、概念
**百度百科:**是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流
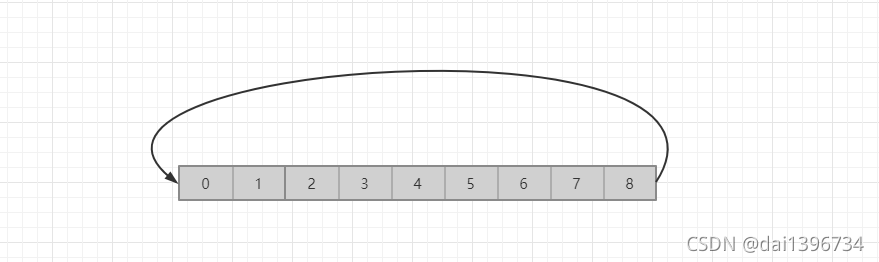
**个人理解:**本身就是一个定长数组,在存储数据时,达到存储上限时会从0继续存储,也就是他在存储数据时是个闭环的过程,举个例子:如下图,假设是个 大小为9字节的数组,当存满了9个字节的数据时,在存入字节时就会从0开始存储,环形数组也称ringbuffer
2、优势
首先是一个先进先出的队列,当取走数据时不需要移动数组中的其他元素,在单消费者单生产者的模型下,不需要加锁,可以更快的存取数据。
3、实现
首先定义一个Ringbuffer的类,成员变量定义如下
unsigned char*m_pBuffer; //数组指针
unsigned int m_nSize; //数组大小
unsigned int m_w_index; //写索引
unsigned int m_r_index; //读索引
成员函数申明如下(主要了解存取):
unsigned int Put(const uint8_t *pBuffer, unsigned int nLen);
unsigned int Get(uint8_t *pBuffer, unsigned int nLen);
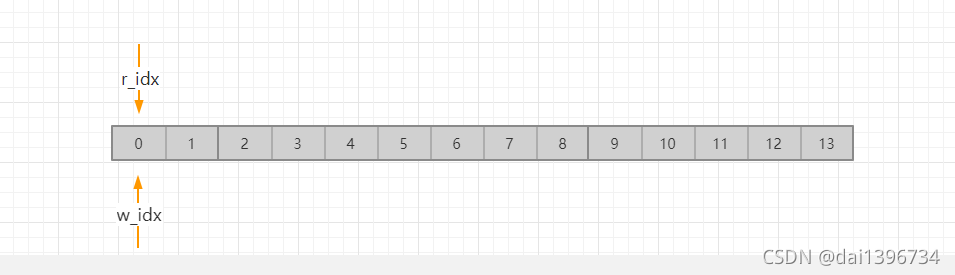
以下图为参考来理解一个ringbuffer的实现,图中r_idx 为读索引,w_idx为写索引,大小为14, 当前为ringbuffer的初始状态。
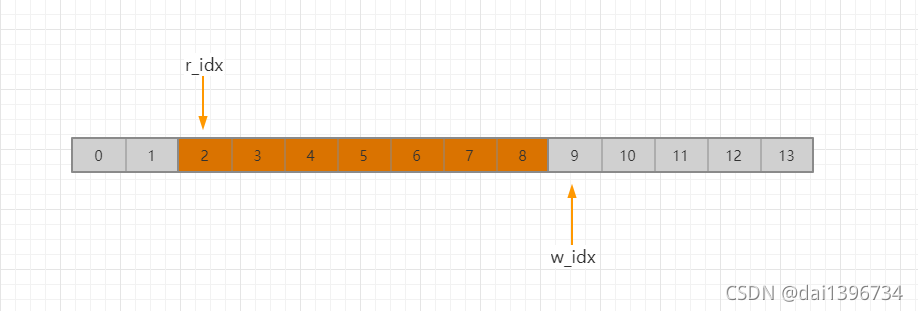
举个例子:当存9个数据,取2个数据时,索引为下图状态
写数据分析
为了去除不必要的边界判断,加入2个前提
1、写入的数据长度大于ringbuffer可写入的长度,则忽略,也就是禁止写入。
2、如果数据长度 >=数组长度(达到容量上限)则禁止写入。
假设写入一个任意长度的数组,那么可能存在如下情况
情况1:写索引>=读索引,待写数据长 <= “右可写入部分”的长度,直接写入整个待写的数据
情况2:写索引>=读索引,待写数据长 > “右可写入部分”的长度,先写入右可写的长度,在把剩下的写入做可写部分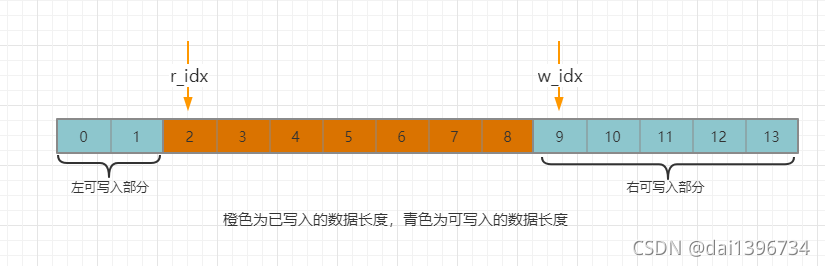 情况3:写索引<读索引,直接写入整个待写的数据
情况3:写索引<读索引,直接写入整个待写的数据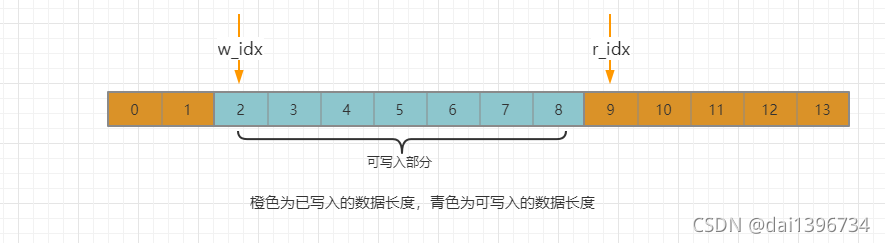
写数据代码实现
/**
* buffer: 待存入的数据指针
* len: 待存入的数据长度
*/
unsigned int RingBuffer::Put(const unsigned char *buffer, unsigned int len)
{
unsigned int cur_r = m_r_index;
unsigned int datalen = m_w_index - cur_r;
//已经满了
if(datalen >= m_nSize)
return 0;
//索引在数组的位置
unsigned int t_w = m_w_index & (m_nSize - 1);
unsigned int t_r = cur_r & (m_nSize - 1);
if(t_w >= t_r){
//情况1
if(len <= (m_nSize-t_w)){
memcpy(m_pBuffer + t_w, buffer, len);
}else{//情况1
memcpy(m_pBuffer + t_w, buffer, (m_nSize-t_w));
memcpy(m_pBuffer , buffer, len - (m_nSize-t_w));
}
}else{
//情况3
memcpy(m_pBuffer + t_w , buffer, len);
}
m_w_index += len;
return len;
}
读数据分析
同样的去除不必要的边界判断,加入2个前提:
1、数据长度 < 待读入的长度,则忽略
2、数据长度为0时(无数据可读),忽略
情况1:写索引>读索引,直接读取
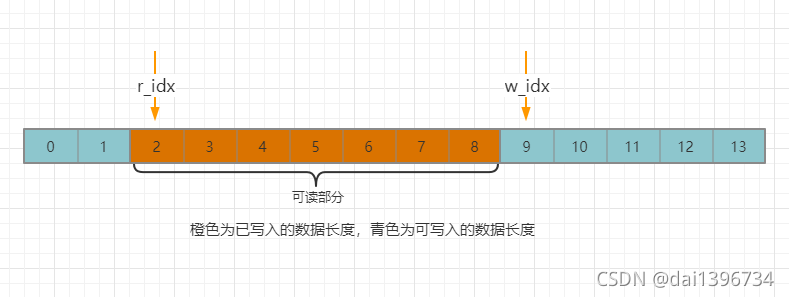
情况2:写索引 <= 读索引,待读数据长 <= “右可读”的长度,直接读取待读长度
情况2:写索引 <= 读索引,待读数据长 > “右可读”的长度,先读取“右可读”的数据,在从“左可读”读取剩余部分
读数据实现
unsigned int RingBuffer::Get(unsigned char *buffer, unsigned int len)
{
unsigned int cur_w = m_w_index;
unsigned int datalen = cur_w - m_r_index;
//空了或小于
if(datalen < len || datalen ==0 )
return 0;
//索引在数组的位置
unsigned int t_w = cur_w & (m_nSize - 1);
unsigned int t_r = m_r_index & (m_nSize - 1);
if(t_w > t_r){
memcpy(buffer,m_pBuffer + t_r, len);
}else{
if(len <= (m_nSize - t_r))
memcpy(buffer,m_pBuffer + t_r, len);
else{
memcpy(buffer,m_pBuffer + t_r, (m_nSize - t_r));
memcpy(buffer+(m_nSize - t_r),m_pBuffer, len - (m_nSize - t_r));
}
}
m_r_index += len;
return len;
}
不加锁分析
现在考虑2个线程,一个读一个写
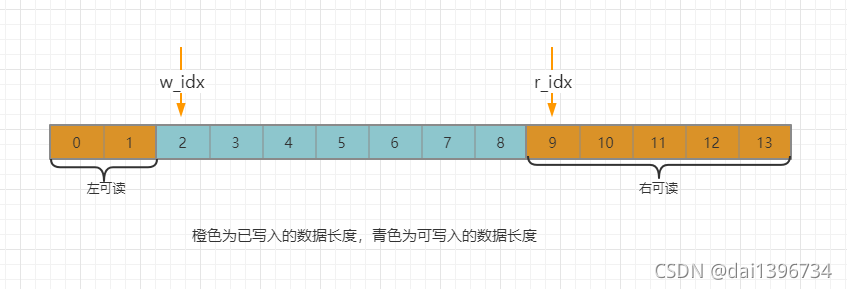
当写数据时,我们会先去获取读索引的值,那么在读线程就有可能改变读索引(读索引只会变大,不会变小),此时的写索引在没获取到读索引值时是保持不变的,那么读索引不可能超过写索引的值的(读线程有判断),所以读索引的值改变范围始终会在下图箭头标注的区间,因此不管什么情况我们会在这个区间内拿到一个读索引,我们就得到一个可写入的数据区间,然后忘里面写数据,假设在写的过程读线程又来修改读索引,怎么办?此时已经无需关心读索引了,因为在此之前我们拿到了一个读索引副本,此后所有的读索引都比这个副本值大,此时无论我们怎么写入这个空间都不会影响到读线程去读数据
同理读数据不加锁分析也一样

多线程就不行了,假如2个线程同时写就有可能对一个地方重复写入


















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











