







1 Hadoop HA 介绍
1.1 namenode 高可用集群
HDFS集群中如果只有一个namenode,那么如果namenode机器宕机则会导致整个集群不可用,所以,Hadoop提供HDFS高可用HA方案:HDFS集群中有两个namenode处在两台独立的机器上,一个处于active状态(对外提供服务),一个处于standby状态(不对外提供服务),用于同步active namenode的状态,进行备份,以防active namenode失败时可以迅速切换。
组件有:
- Active NameNode
- Standby NameNode
- ZKFailoverController
- Zookeeper集群
- 共享存储系统
- Datanode
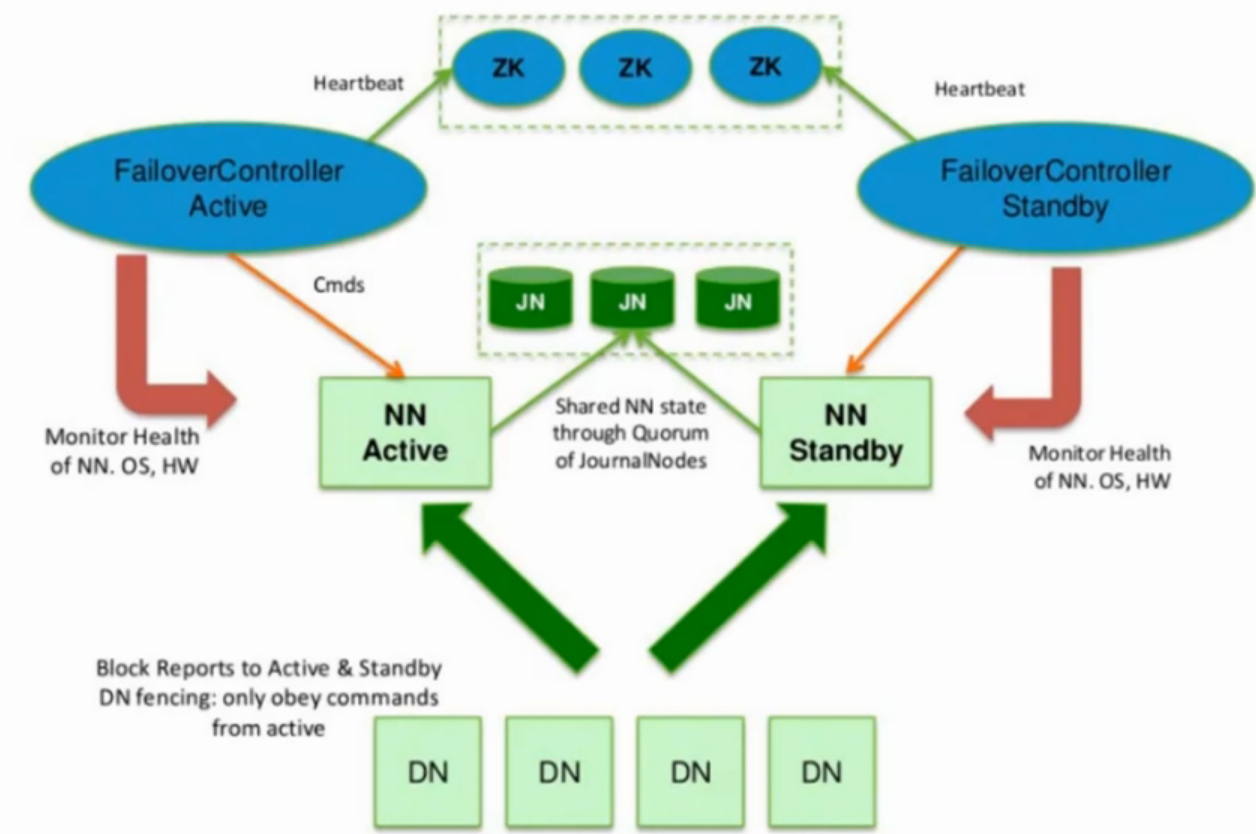
为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。当Active Node上更新了namespace,它将记录修改日志发送给JNS的多数派。Standby noes将会从JNS中读取这些edits,并持续关注它们对日志的变更。Standby Node将日志变更应用在自己的namespace中,当failover发生时,Standby将会在提升自己为Active之前,确保能够从JNS中读取所有的edits,即在failover发生之前Standy持有的namespace应该与Active保持完全同步。
为了支持快速failover,Standby node持有集群中blocks的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个Namenode的地址,同时和它们都建立心跳链接,并把block位置发送给它们。
处理流程为:集群启动后一个NameNode处于Active状态,并提供服务,处理客户端和DataNode的请求,并把editlog写到本地和share editlog(这里是QJM)中。另外一个NameNode处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与Active节点的状态同步。为了实现Standby在Active挂掉后迅速提供服务,需要DataNode同时向两个NameNode汇报,使得Stadnby保存block to DataNode信息,因为NameNode启动中最费时的工作是处理所有DataNode的blockreport。为了实现热备,增加FailoverController和Zookeeper,FailoverController与Zookeeper通信,通过Zookeeper选举机制,FailoverController通过RPC让NameNode转换为Active或Standby。
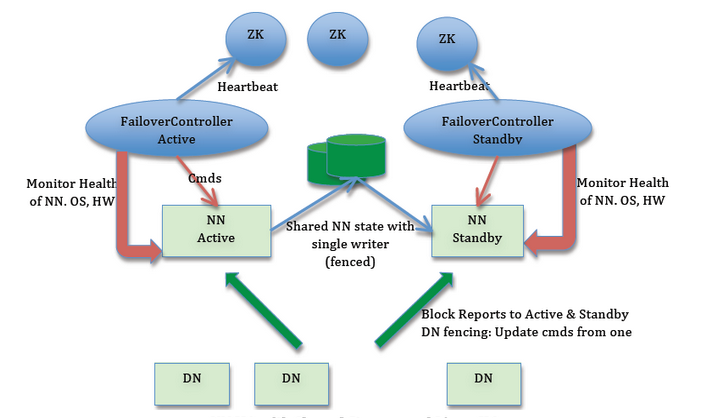
1.2 namenode 主备切换
主备切换流程图:
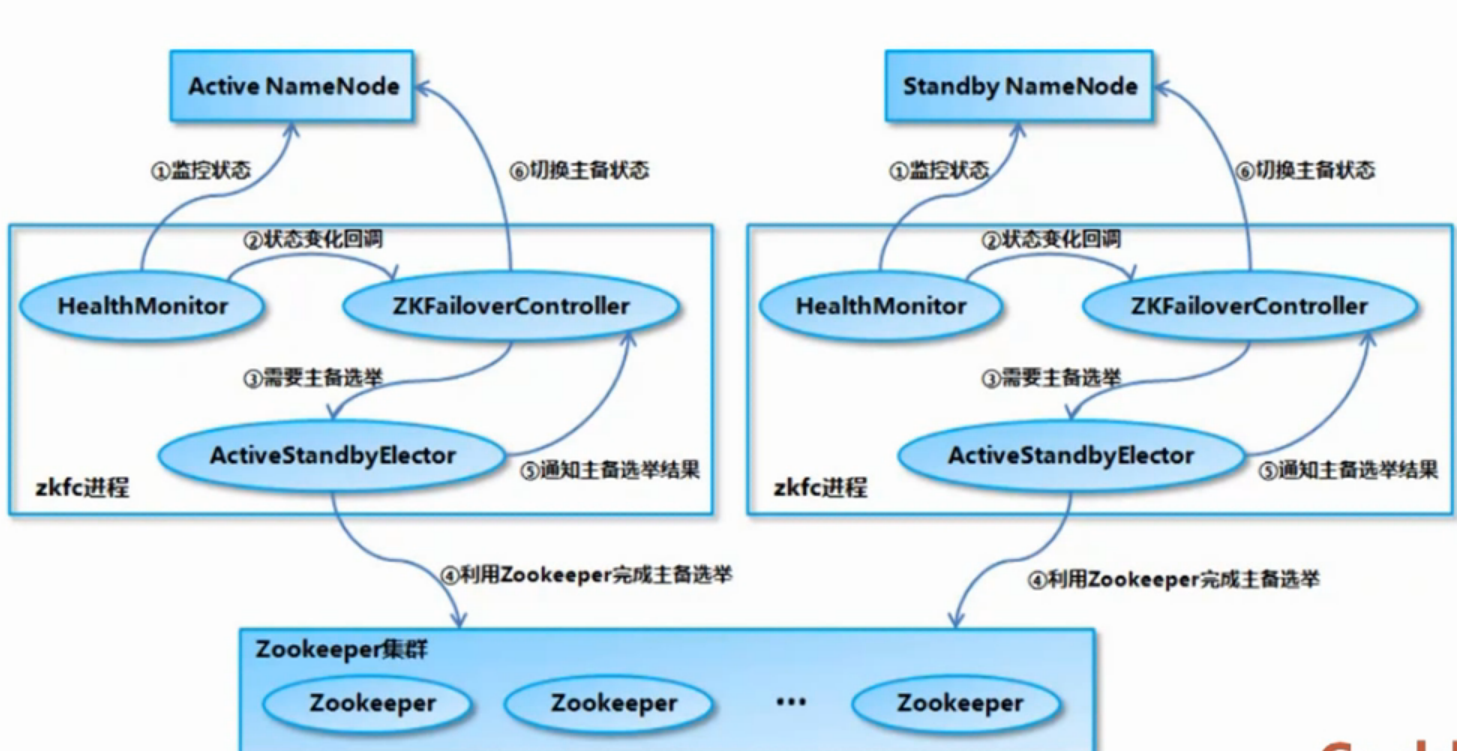
1.3 namenode的共享存储
架构图:















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









