






Python中的requests库主要用于发送HTTP请求并获取响应结果。在现代网络编程中,HTTP请求是构建客户端与服务器之间通信的基础。Python作为一种高级编程语言,其丰富的库支持使得它在网络数据处理领域尤为突出。其中,requests库以其简洁、易用的特点,被广泛应用于Web开发、数据抓取、API交互等场景。
以下是对requests库功能及其在实际使用中的一些典型应用的详细分析:
1. 简化HTTP请求
- 易于上手:requests库提供了简洁明了的API,让用户能够轻松地发送HTTP请求。
- 多种请求方法支持:支持GET、POST、PUT、DELETE等所有常用的HTTP方法。
2. 获取和解析响应
- 响应对象:每次请求都会返回一个包含状态码、响应头、内容等信息的response对象。
- 内容处理:可以方便地获取响应内容,并对内容进行进一步的处理,如JSON解析、文本编码转换等。
3. 灵活的参数配置
- 请求头设置:允许自定义请求头,模拟不同的浏览器或设备。
- Cookies处理:支持通过cookies保持会话状态。
- 代理和认证:支持通过代理访问以及基本/摘要式认证。
4. 异常处理和重试机制
- 异常处理:提供多种异常类型,便于错误捕获和处理。
-会话管理:利用session对象可以更好地管理持久连接和cookies,适合需要发送多个请求的场景。
5. 高级功能
- 文件上传下载:支持直接上传文件作为请求体,或从响应中下载文件。
- SSL证书验证:支持设置是否验证SSL证书,确保数据传输的安全性。
- 超时设置:允许设置请求超时时间,防止因网络延迟导致的程序假死。
除了上述功能外,还有一些值得注意的应用场景:
- Web爬虫开发:requests常用于编写网络爬虫,可以方便地获取网页数据并进行解析。
- API接口测试:对于开发人员来说,requests是测试RESTful API接口的好工具,可以模拟前端发送请求,检查后端响应。
- 自动化测试:在自动化测试脚本中,可以利用requests发送请求并验证返回数据是否符合预期。
以下是一段关于requests的代码:
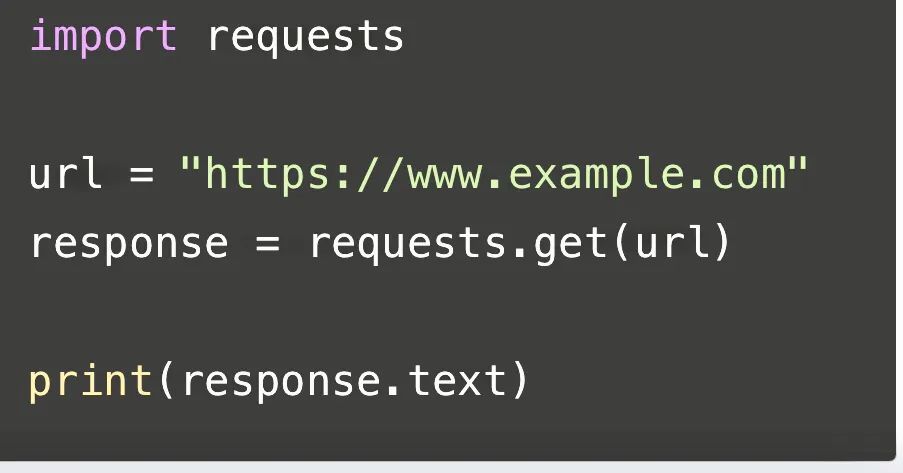
这段代码使用了Python的requests库来发送一个HTTP GET请求到指定的URL(这里是"https://www.example.com"),并将返回的响应内容打印出来。首先,我们导入了requests库,然后定义了一个变量url,存储了要请求的网址。接着,我们使用requests.get()函数发送GET请求,并将返回的响应对象存储在response变量中。最后,我们通过response.text属性获取响应的内容,并使用print()函数将其打印出来。
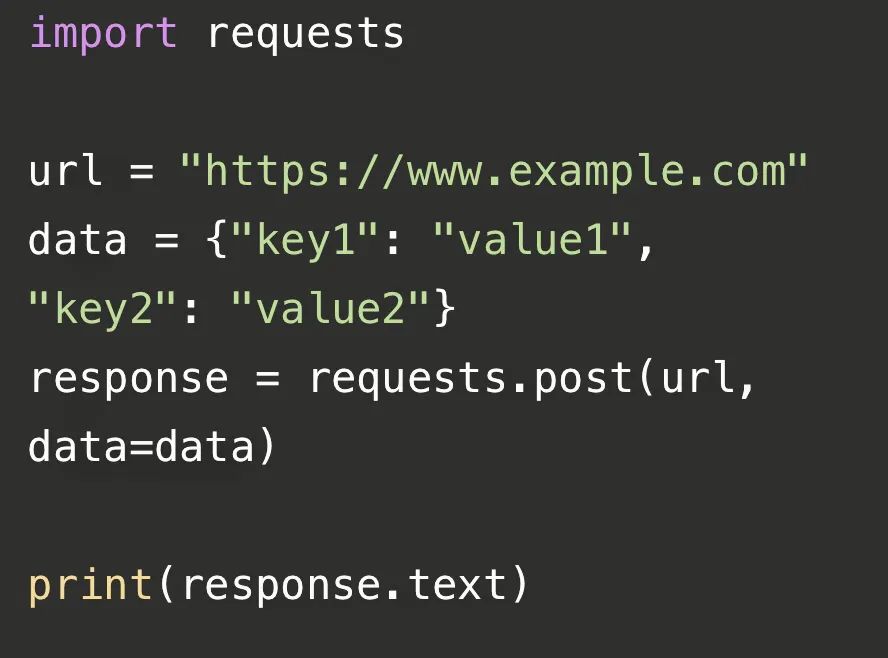
这段代码使用了Python的requests库来发送一个HTTP POST请求到指定的URL(这里是"https://www.example.com"),并将返回的响应内容打印出来。首先,我们导入了requests库,然后定义了一个变量url,存储了要请求的网址。接着,我们创建了一个字典data,其中包含了要发送的数据。然后,我们使用requests.post()函数发送POST请求,并将返回的响应对象存储在response变量中。最后,我们通过response.text属性获取响应的内容,并使用print()函数将其打印出来。
接下来介绍一下requests库在爬虫方面的应用:
Requests库在网络爬虫中的主要应用场景包括数据抓取、模拟登录、文件下载和上传以及会话管理等。具体如下:
1. 数据抓取:Requests库使得发送HTTP请求变得简单,能够方便地从网站上抓取数据。通过GET和POST请求,可以轻松获取网页内容,是数据挖掘和数据分析不可或缺的工具。
2. 模拟登录:在进行需要登录的网站爬取时,Requests库可以处理cookies和session,保持用户的登录状态,自动处理cookies,适用于需要持久连接和多次请求的场景。
3. 文件下载:Requests库支持文件的上传和下载,通过`files`参数上传文件,通过`save_response_content`方法下载文件,这使得从网络资源中获取数据变得十分便捷。
4. 会话管理:使用`requests.Session()`可以创建一个会话,保持某些参数(如cookies、headers)在多个请求之间,这对于需要维持登录状态或连续进行多个请求的爬虫场景非常有用。
5. 异常处理:在进行网络请求时,可能会遇到各种异常如`requests.exceptions.Timeout`等,合理处理这些异常是使用Requests库的难点之一。
6. 超时设置:通过设置timeout参数,可以控制请求的超时时间,防止请求过久无响应,这对爬虫效率和稳定性有重要影响。
7. 代理设置:在爬取网页时,可以通过proxies参数设置代理服务器,增加匿名性,有助于避免被目标网站封锁。
8. JSON数据处理:Requests库支持直接发送和接收JSON数据,使用`json`参数传递JSON数据,或使用`response.json()`解析响应的JSON数据,这在处理API响应时非常有用。
9. 安全性问题:通过`verify`参数可以控制是否验证SSL证书,确保请求的安全性,在处理敏感数据或进行重要操作时,这一点至关重要。
10. 性能优化:Requests库内部使用urllib3库,后者提供了连接池的管理,合理配置可以提升性能。
此外,在使用Requests库进行网络爬虫开发时,还需要注意以下几点:
1. 当请求需要登录或保持登录状态的网站时,需要特别处理cookies和session。
2. 对于频繁的请求,需要考虑设置合理的超时时间和重试策略,以避免因网络波动导致的请求失败。
3. 在处理敏感数据或进行重要操作时,务必注意安全性问题,如SSL证书的验证和HTTP基本认证。
综上所述,Requests库以其简洁易用、功能强大的特点,成为了Python中进行网络数据交互的首选工具。无论是基本的GET和POST请求,还是复杂的异常处理、超时设置、代理使用、Cookies处理、Session会话、JSON数据处理、文件上传下载、安全性问题以及性能优化,Requests库都能提供强大的支持。
以下是一段爬虫代码仅供参考:
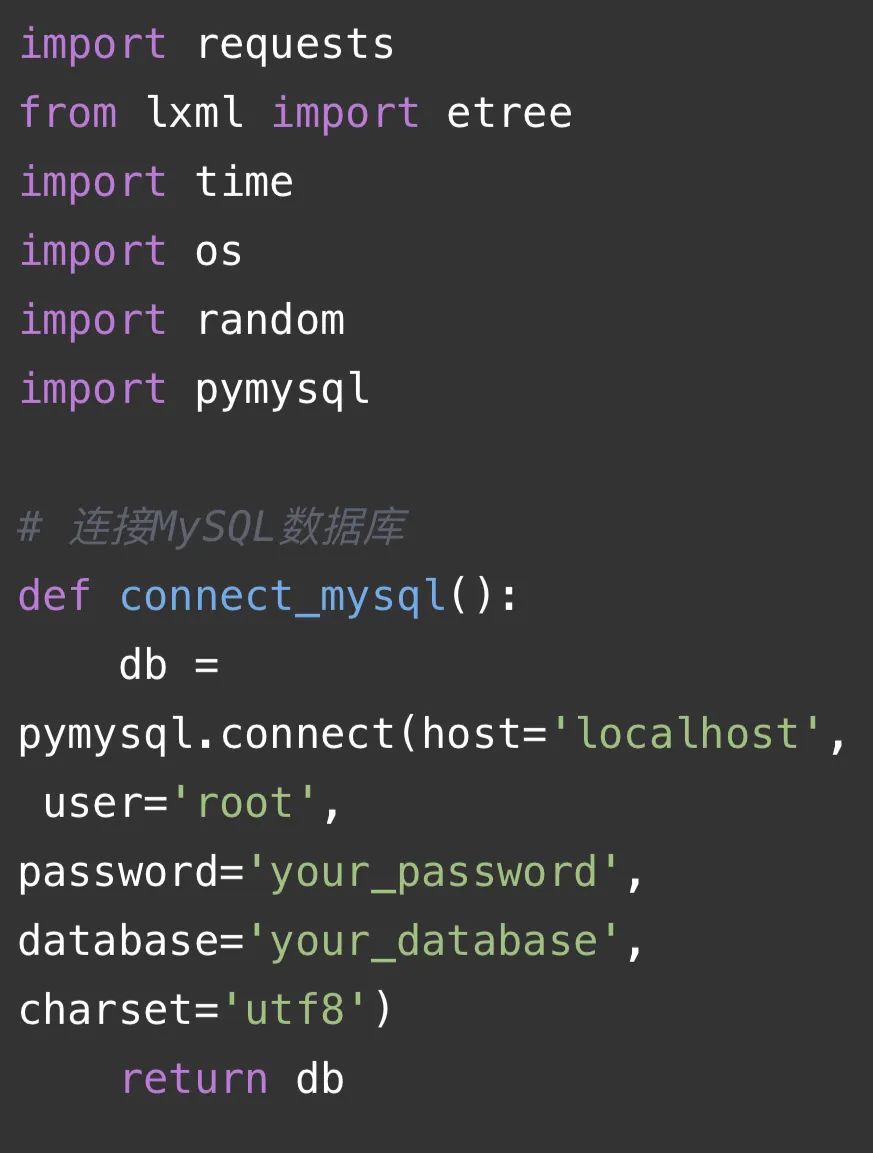
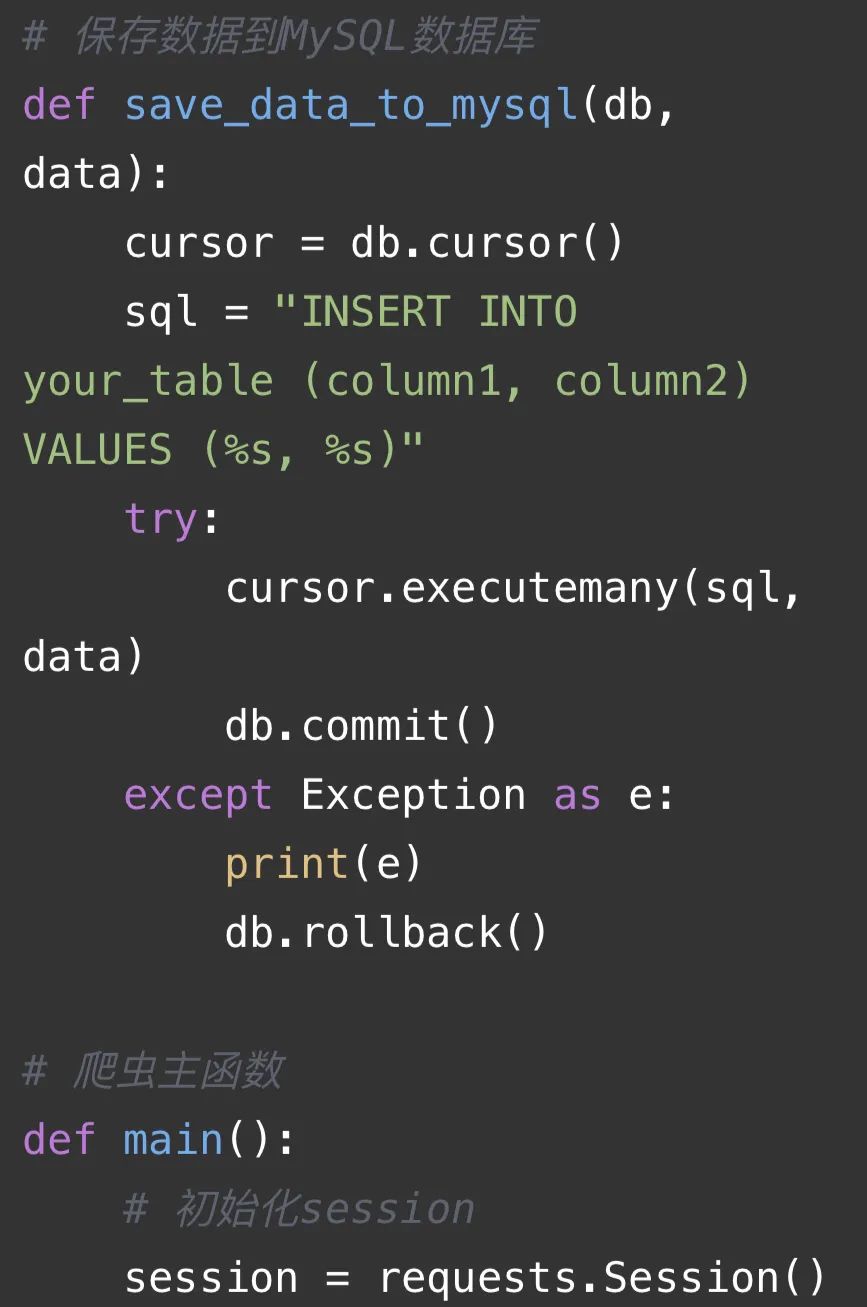

代码解释:
这段代码是一个使用requests库、lxml库、time库、os库和random库的爬虫代码。主要功能如下:
1. 连接MySQL数据库:通过`connect_mysql()`函数连接到MySQL数据库,返回一个数据库连接对象。
2. 保存数据到MySQL数据库:通过`save_data_to_mysql(db, data)`函数将数据保存到MySQL数据库中。其中,`db`是数据库连接对象,`data`是要保存的数据。
3. 爬虫主函数:通过`main()`函数实现爬虫的主要逻辑。
4. 初始化session:使用`requests.Session()`创建一个session对象,用于管理HTTP请求。
5. 设置请求头:定义一个headers字典,包含User-Agent等信息,用于模拟浏览器发送请求。
6. 登录网站:通过POST请求登录网站,获取cookies。
7. 爬取数据:使用GET请求爬取网页数据,并将HTML内容解析为lxml对象。
8. 解析数据:通过XPath表达式提取网页中的相关信息,并将数据存储到一个列表中。
9. 保存数据到MySQL数据库:调用`save_data_to_mysql()`函数将解析得到的数据保存到MySQL数据库中。
10. 关闭数据库连接:在数据保存完成后,关闭数据库连接。
以上的相关应用可以通过小蜜蜂AI的GPT问答获取更多的示例。网址:https://zglg.work。
(文章对你有用的话。记得点赞➕在看哦😯😯😯😯分享知识也是一种美德)
如有学习上的困惑或问题欢迎评论区留言告诉我们,让我们一起解决共同进步:















 1978
1978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









