









微分
一元函数的微分定义式如下:
d
y
=
f
′
(
x
)
∗
d
x
dy=f'(x)*dx
dy=f′(x)∗dx
即 垂直变化量 = 斜率(导数) * 水平变化量
微分的含义:用一个线性函数的变化来逼近任意可导函数的变化
梯度
令 z = f(x,y),则z在点p(x,y)处的梯度为 :
▽
f
(
x
,
y
)
=
g
r
a
d
f
(
x
,
y
)
=
(
∂
f
∂
x
,
∂
f
∂
y
)
▽f(x,y) = gradf(x,y) = (\frac{\partial f}{\partial x},\frac{\partial f}{\partial y})
▽f(x,y)=gradf(x,y)=(∂x∂f,∂y∂f)
一元函数的导数是一个标量,表示函数某点切线的斜率;而梯度是一个矢量,是多元函数在某一点处的偏导数构成的矢量。矢量具有方向,所以梯度的方向指向多元函数在该点增长最快的方向。则负梯度方向则是下降最快的方向,因此可以用梯度下降法来优化参数,例如可以利用梯度下降法更新神经网络中的weight:
β
=
β
−
l
r
∗
∂
l
o
s
s
∂
β
\beta =\beta - lr*\frac{\partial loss}{\partial \beta}
β=β−lr∗∂β∂loss
pytorch中,设置了require_grads=True 的tensor可以被计算梯度。在backward过程中会被autograd模块自动计算梯度并保存在 tensor.grad 中。例如:
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
loss.backward()
print(w.grad)
print(b.grad)
Out:
tensor([[0.1022, 0.2449, 0.2776],
[0.1022, 0.2449, 0.2776],
[0.1022, 0.2449, 0.2776],
[0.1022, 0.2449, 0.2776],
[0.1022, 0.2449, 0.2776]])
tensor([0.1022, 0.2449, 0.2776])
但是需要注意的是,大多数时候我们期望计算的都是某个标量(如 loss)对矢量参数(如 weight 和 bias)的梯度,直接使用上面的代码就可以获得期望的参数梯度信息。但是如果要计算的是矢量对矢量的梯度(如 同时计算多个loss的梯度),则必须设置backward 中的gradient 参数,且要保持与待计算梯度的参数具有相同shape.
Tensor.backward(gradient=None, retain_graph=None, create_graph=False, inputs=None)
例如:
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
print("First call\n", inp.grad)
out.backward(torch.ones_like(inp), retain_graph=True)
print("\nSecond call\n", inp.grad)
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print("\nCall after zeroing gradients\n", inp.grad)
Out:
First call
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.],
[4., 4., 4., 4., 8.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
注 意 \textcolor{red}{注意} 注意,此时,pytorch计算得到的并不是真正的梯度,而是Jacobian Product 即 v T ⋅ J \ v^T \cdot J vT⋅J 其中 v为backward中给定的与输入参数相同shape 的 gradient vector 。而 J \ J J 则表示Jacobian matrix ,即
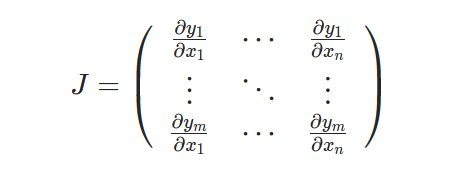
其中,假定输入参数Tensor为 [ x 1 , . . . x n ] \ [x_{1},...x_{n}] [x1,...xn],输出参数Tensor 为 [ y i , . . . y m ] \ [y_{i},...y_{m}] [yi,...ym],则第i 行 表示输出 tensor中的第i 个分量对输入参数tensor的梯度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











