









并发编程技术是互联网应用开发中必须掌握的知识,本篇文章笔者开始分析线程池,进一步了解Java领域并发编程知识。
上文Java并发编程之Thread知识整理已经介绍了线程的目的和好处,线程池就是为了更好的使用线程,发挥线程最大的价值。
线程池创建的方式有3种:
第一种通过ThreadPoolExecutor的构造函数方法创建。通过ThreadPoolExecutor的最全构造参数来看总共有7个参数。
public ThreadPoolExecutor(int corePoolSize, //核心线程数大小int maximumPoolSize, //最大线程数long keepAliveTime, // 超过核心线程数后的线程存活时间TimeUnit unit, //存活时间单位BlockingQueue<Runnable> workQueue, //任务队列ThreadFactory threadFactory, // 创建线程的工厂RejectedExecutionHandler handler // 拒绝策略处理器) {}
第二种,ScheduledThreadPoolExecutor类的构造器,创建定时,或者一定频率执行的线程池。
public ScheduledThreadPoolExecutor(int corePoolSize,//核心线程数ThreadFactory threadFactory,//创建线程的工厂RejectedExecutionHandler handler //池满拒绝策略)super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue(), threadFactory, handler);}public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, //定时执行的任务long initialDelay,//首次延迟启动时间long period,//定期周期TimeUnit unit//定期周期单位) {if (command == null || unit == null)throw new NullPointerException();if (period <= 0)throw new IllegalArgumentException();ScheduledFutureTask<Void> sft =new ScheduledFutureTask<Void>(command,null, triggerTime(initialDelay, unit), unit.toNanos(period));RunnableScheduledFuture<Void> t = decorateTask(command, sft);sft.outerTask = t;delayedExecute(t);return t;}
第三种使用工厂Executors类的静态方法
//弹性可伸缩的线程池,核心线程大小为0,最大线程数为Integer.MAX_VALUE,只要小于Integer.MAX_VALUE就会创建线程加入线程池,只要线程空余时间大于60s则回收线程资源。可能导致线程创建过多,耗尽系统资源,使用同步队列,不存储任务,没有任务堆积能力,强依赖线程资源public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
// 固定线程大小的线程池,核心线程数和最大线程数都是一样的,//队列是无界的,只要线程数小于核心线程数,就加线程,//只要大于核心线程数,就加入无界队列。线程大小固定,//如果任务执行时间长,可能导致任务堆积过久。public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads,nThreads,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
// 线程大小只有1的线程池,队列采用有界阻塞队列,任务会按提交顺序执行public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
//创建单个定时调度的线程池,这个在中间件中用的比较多,比如rocketmq,dubbo//用于后台执行一些定时操作。public static ScheduledExecutorService newSingleThreadScheduledExecutor() {return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));}
在阿里巴巴出品的Java开发手册中,明确强制不允许使用Executors类创建线程池,因为通过Executors存在耗尽资源的风险。

线程池原理
线程池的存储结构:线程封装在Worker类中,并使用HashSet存储池中的线程
/*** Set containing all worker threads in pool. Accessed only when* holding mainLock.*/private final HashSet<Worker> workers = new HashSet<Worker>();
提交任务到线程池:
java.util.concurrent.ThreadPoolExecutor#execute(Runnable r)流程
// 1、如果当前正在运行的线程数小于核心线程数,启动一个核心线程,将r作为该线程第一个执行的任务//2、如果核心线程数满了,将任务加入任务队列//3、如果任务队列满了,增加非核心线程数,直到达到最大线程数//4、如果达到了最大线程数,则执行拒绝策略RejectedExecutionHandler// AbortPolicy(抛异常,默认)DiscardPolicy(空处理,丢弃)// DiscardOldestPolicy(丢弃(poll)任务队列中的下一个将执行任务-头部任务,并尝试执行当前任务)// CallerRunsPolicy (调用者线程直接调用run方法)public void execute(Runnable command) {if (command == null)throw new NullPointerException();/** Proceed in 3 steps:** 1. If fewer than corePoolSize threads are running, try to* start a new thread with the given command as its first* task. The call to addWorker atomically checks runState and* workerCount, and so prevents false alarms that would add* threads when it shouldn't, by returning false.** 2. If a task can be successfully queued, then we still need* to double-check whether we should have added a thread* (because existing ones died since last checking) or that* the pool shut down since entry into this method. So we* recheck state and if necessary roll back the enqueuing if* stopped, or start a new thread if there are none.** 3. If we cannot queue task, then we try to add a new* thread. If it fails, we know we are shut down or saturated* and so reject the task.*/int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}else if (!addWorker(command, false))reject(command);}
线程池也可以实现预热功能,将核心线程数,预先创建好
java.util.concurrent.ThreadPoolExecutor#prestartCoreThreadjava.util.concurrent.ThreadPoolExecutor#ensurePrestart //至少启动一个线程java.util.concurrent.ThreadPoolExecutor#prestartAllCoreThreads // 启动所有核心线程//控制核心线程的空闲时间java.util.concurrent.ThreadPoolExecutor#allowCoreThreadTimeOut //开启核心线程回收功能(默认不回收)//提交任务2java.util.concurrent.AbstractExecutorService#submit(java.util.concurrent.Callable<T>)// 也是调用了execute 只不过将任务构造成了FutureTaskjava.util.concurrent.FutureTask#FutureTask(java.util.concurrent.Callable<V>)FutureTask实现了Runnable接口的run方法,并且持有了Callable的引用. 提交到线程池的是FutureTask任务。// 线程池会调用这个run方法public void run() {if (state != NEW ||!RUNNER.compareAndSet(this, null, Thread.currentThread()))return;try {Callable<V> c = callable;if (c != null && state == NEW) {V result;boolean ran;try {//调用call方法result = c.call();ran = true;} catch (Throwable ex) {result = null;ran = false;setException(ex);}if (ran)//设置完成状态和结果 Locksupport.unpark对等待结果的线程进行唤醒set(result);}} finally {// runner must be non-null until state is settled to// prevent concurrent calls to run()runner = null;// state must be re-read after nulling runner to prevent// leaked interruptsint s = state;if (s >= INTERRUPTING)handlePossibleCancellationInterrupt(s);}}
线程池提交任务逻辑流程图
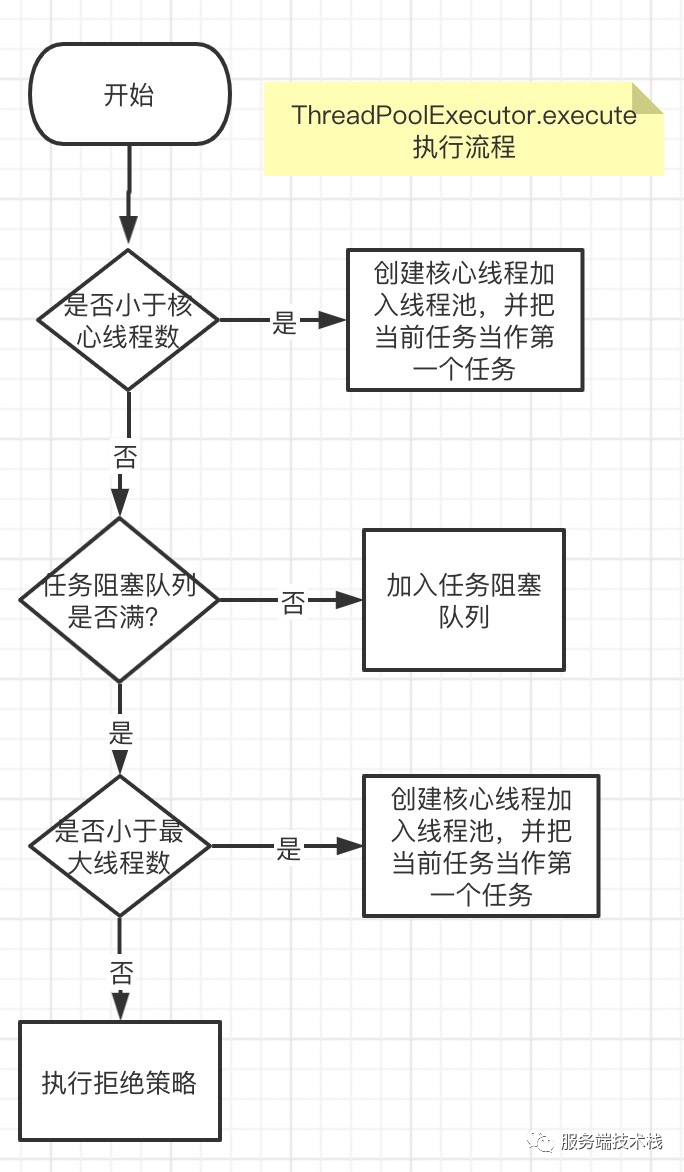
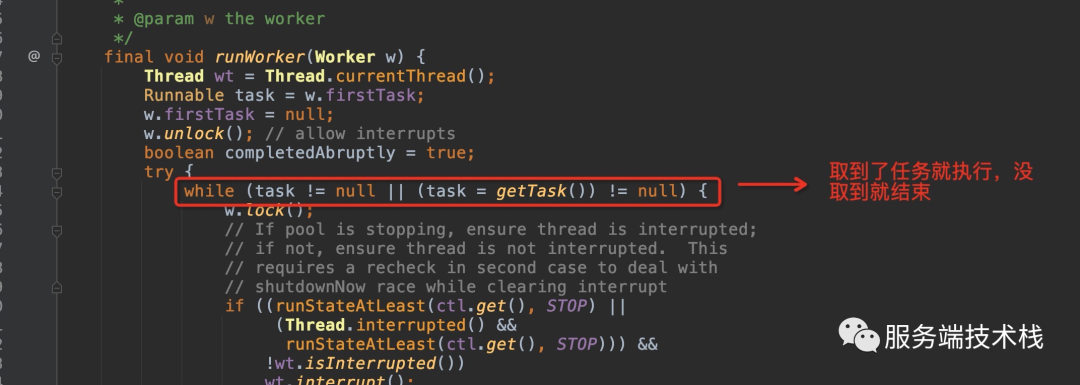
执行任务原理:
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {//不停的获取队列里的任务。while (task != null || (task = getTask()) != null) {w.lock();// If pool is stopping, ensure thread is interrupted;// if not, ensure thread is not interrupted. This// requires a recheck in second case to deal with// shutdownNow race while clearing interruptif ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task); //可以扩展线程池,实现监控Throwable thrown = null;try {//调用run方法,真正的执行任务逻辑task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {afterExecute(task, thrown); //可以扩展线程池,实现监控}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}}
任务包装类Worker :
//继承了aqs 每个任务执行前都需要加锁private final class Workerextends AbstractQueuedSynchronizerimplements Runnable{/*** This class will never be serialized, but we provide a* serialVersionUID to suppress a javac warning.*/private static final long serialVersionUID = 6138294804551838833L;/** Thread this worker is running in. Null if factory fails. */final Thread thread;/** Initial task to run. Possibly null. */Runnable firstTask;/** Per-thread task counter */volatile long completedTasks;/*** Creates with given first task and thread from ThreadFactory.* @param firstTask the first task (null if none)*/Worker(Runnable firstTask) {setState(-1); // inhibit interrupts until runWorkerthis.firstTask = firstTask;this.thread = getThreadFactory().newThread(this);}/** Delegates main run loop to outer runWorker */public void run() {runWorker(this);}// Lock methods//// The value 0 represents the unlocked state.// The value 1 represents the locked state.protected boolean isHeldExclusively() {return getState() != 0;}protected boolean tryAcquire(int unused) {if (compareAndSetState(0, 1)) {setExclusiveOwnerThread(Thread.currentThread());return true;}return false;}protected boolean tryRelease(int unused) {setExclusiveOwnerThread(null);setState(0);return true;}public void lock() { acquire(1); }public boolean tryLock() { return tryAcquire(1); }public void unlock() { release(1); }public boolean isLocked() { return isHeldExclusively(); }void interruptIfStarted() {Thread t;if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {try {t.interrupt();} catch (SecurityException ignore) {}}}}
线程池三种队列选择 :
1、SynchronousQueue 同步器队列 不存储任务 只是传输任务
直接将任务交给线程,没有线程则创建线程(没有堆积队列可以存放任务的能力),会导致线程不断创建,占用系统资源内存cpu,避免有依赖的任务进行锁定,适用于执行时间比较短的任务线程,比如面向c端用户请求接口,可以设置这种队列,最大线程固定,配合设置拒绝策略为调用者线程。
2、LinkedBlockingQueue
无界队列 jdk原生的线程池会导致最大线程数配置没效,队列中一直可以提交任务,如果线程忙碌,则导致线程等待时间过长(任务可能会堆积比较长时间久未执行),很多任务可能没用了,还占用系统资源 内存cpu
3、ArrayBlockingQueue
有界大小,队列满了会创建非核心线程。
使用大队列(任务队列)和小池(核心线程数,最大线程数)可以最小化CPU使用、操作系统资源和上下文切换开销,但是可能会导致人为的低吞吐量(同时处理任务会变少)它们是I/O绑定的),系统可能会为更多的线程安排时间。
使用小队列*通常需要更大的池大小,这会使cpu更忙,但是*可能会遇到不可接受的调度开销,这也会降低吞吐量。
因此队列大小需要配置合适,最大化利用cpu资源,提升系统吞吐量。
经典面试问题线程池大小如何设置:
如果待执行任务的行为差异很大,需要设置多个线程池,从而使每个线程池可以根据各自的工作负载来调整。
考量因素:cpu数量,内存大小,任务是计算密集型,io密集型,还是两者皆可?
假设场景:cpu个数:N, Ucpu 目标cpu的利用率大小(0=<Ucpu<=1). W/C =任务等待时间/任务计算时间。
对于计算密集型任务:将线程池大小设置成N+1时,可以达到最优的利用率
对于包含IO或者其他阻塞操作的任务,由于线程池不会一直执行,因此线程池的规模可以更大,可以估算任务等待时间和计算时间的比值。
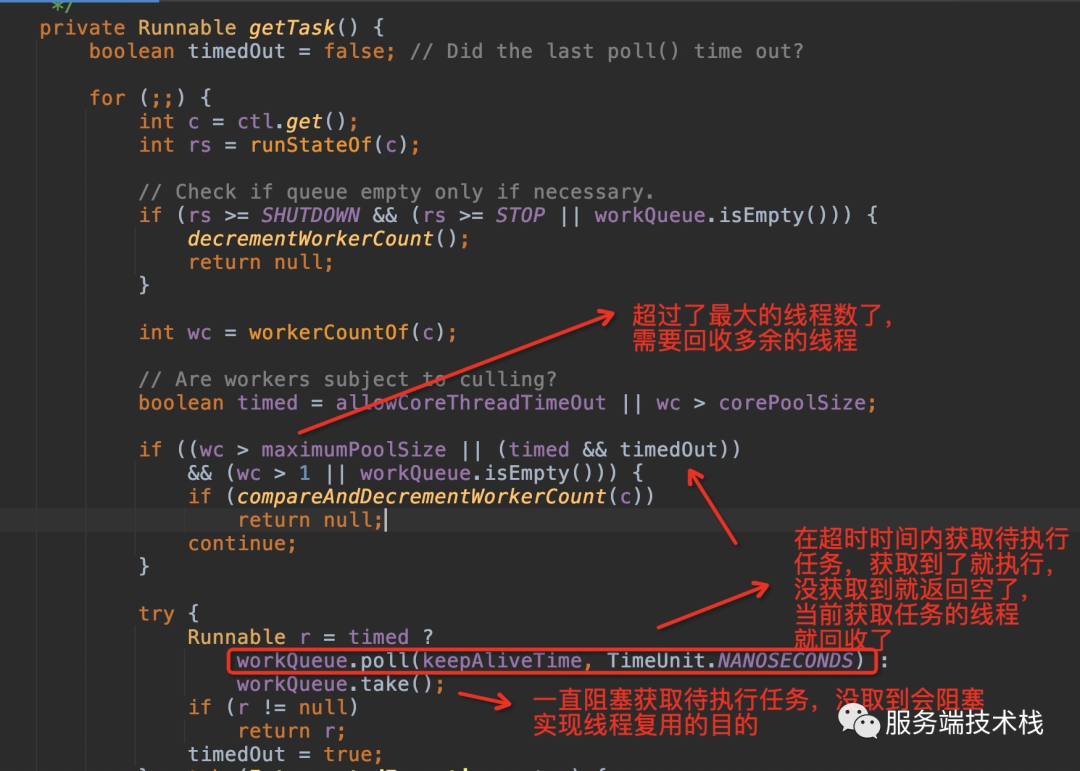
如何实现线程复用的?
1、线程不断取任务队列的任务执行,没取到了就结束这个线程
获取任务实现:
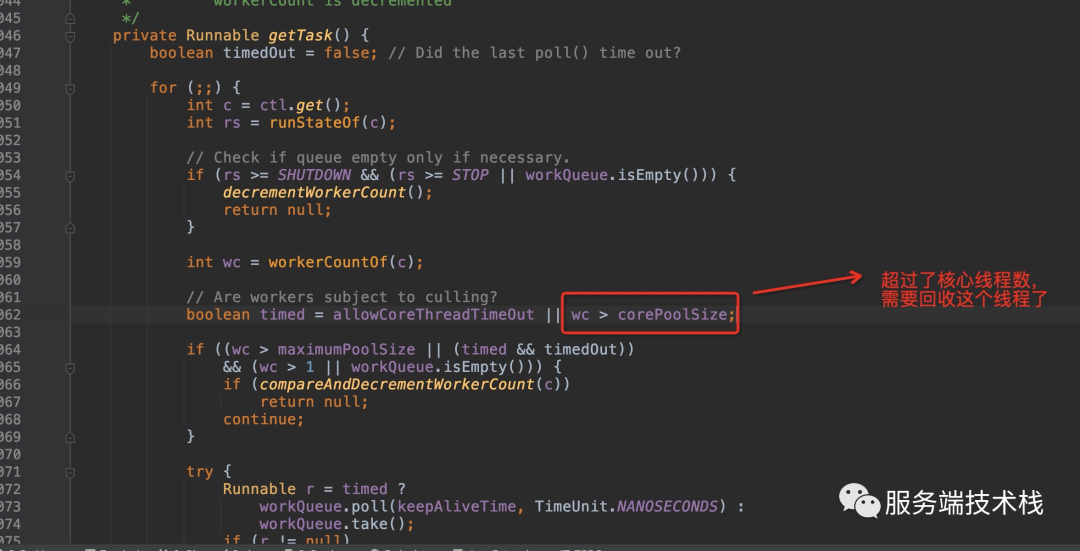
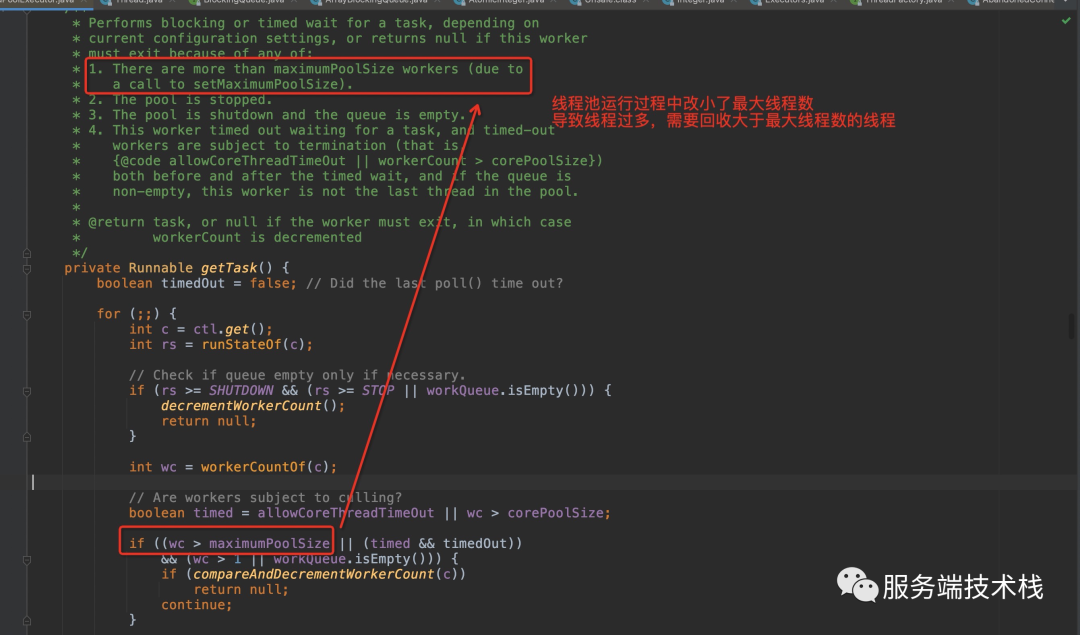
超过核心线程的线程如何回收 :超过了核心线程数了,获取任务会在阻塞等待一定时间后返回。
线程池停止了,也会回收线程:
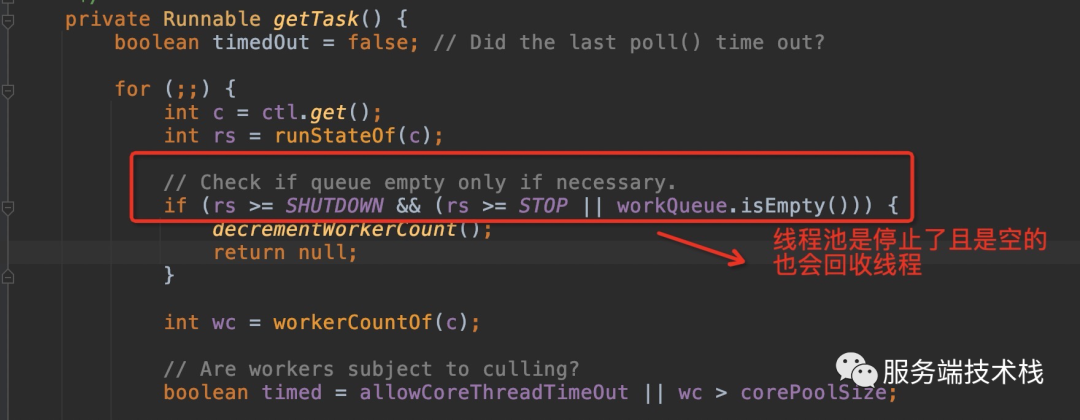
回收线程使用cas机制,保证并发回收问题:
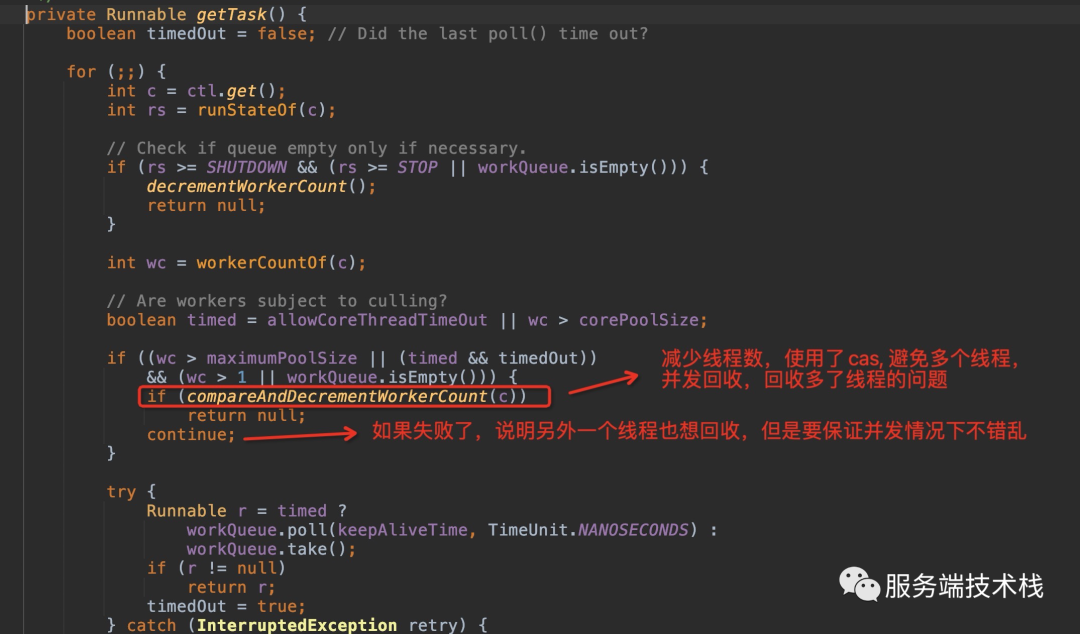
调小了最大线程数,线程池会怎么变化?回收多余的线程
从上面多张代码图可以知道,线程池在获取待执行任务方法里实现了,线程回收,线程复用等核心功能。
线程池的知识还是很多的,本文就介绍这么多了,其实还有线程池的状态相关知识,这块比较复杂,还没理清楚,以后等更清晰了再出文分析。
2022加油,继续学习,坚持就是胜利✌️















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











