






目录
集合
Collection单列集合
每个元素(数据)只包含一个值
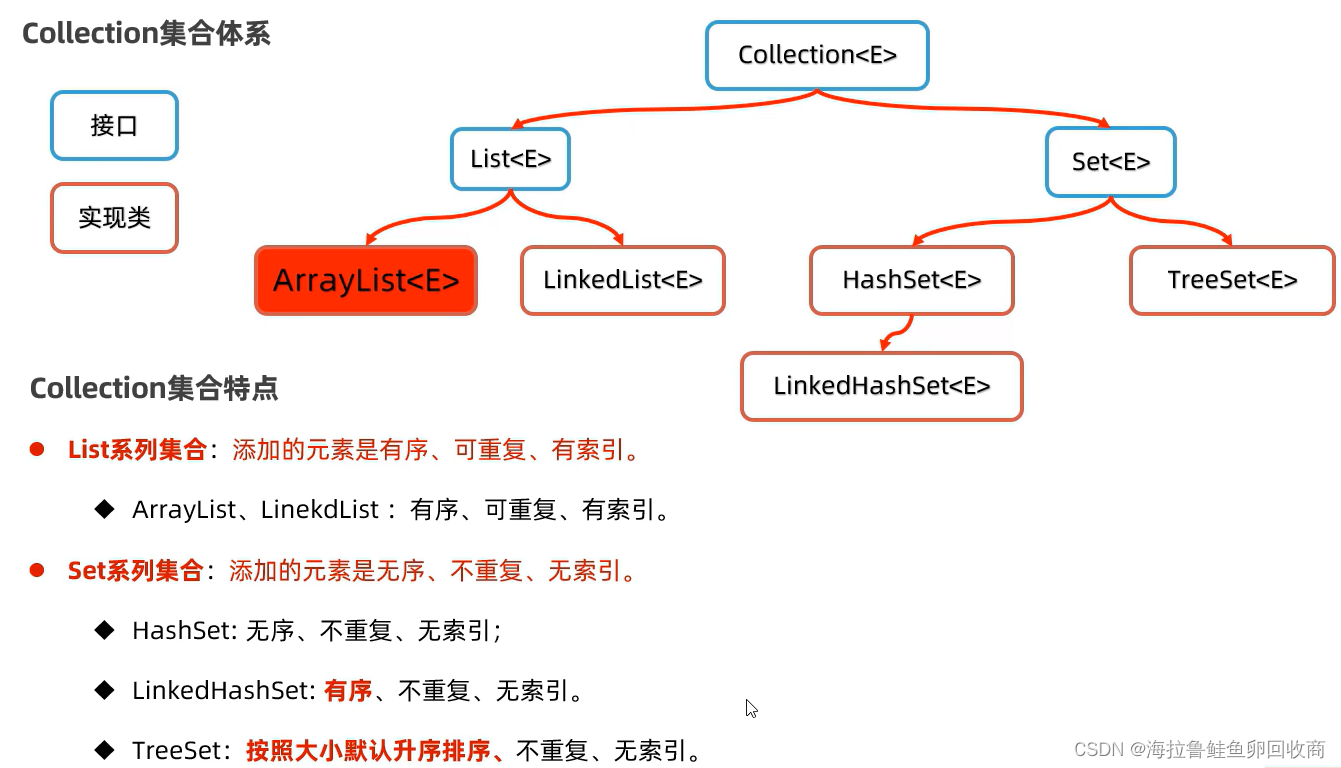
不能new接口哈,要new实现类
Collection的常用方法
Collection作为所有单列结合的祖宗,其方法会被所有子类继承
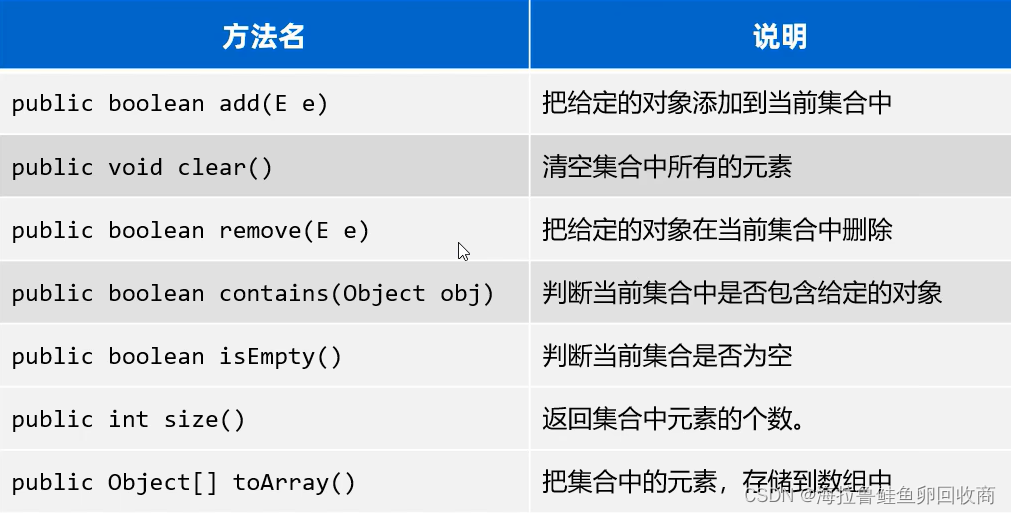
Collection遍历
迭代器
用来遍历集合的专用方式(数组没有迭代器),Iterator

Collection<String> c = new ArrayList<>();
Iterator<String> it = c.iterator();
while(it.hasNext()){
String ele = it.next();
System.out.println(ele);
}next()取元素越界会报异常
增强for循环

快捷:集合名.for
Lambda表达式

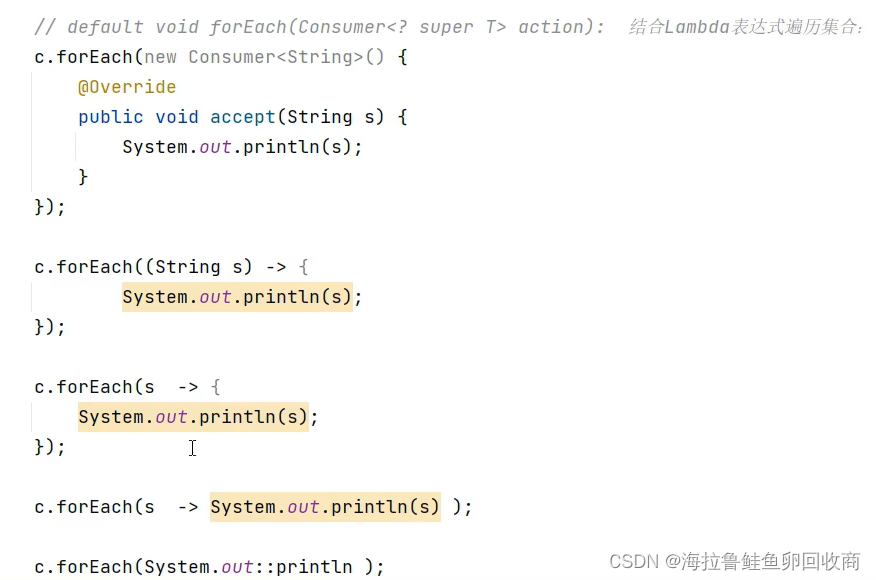
集合中存储的是对象的地址
List集合
支持索引
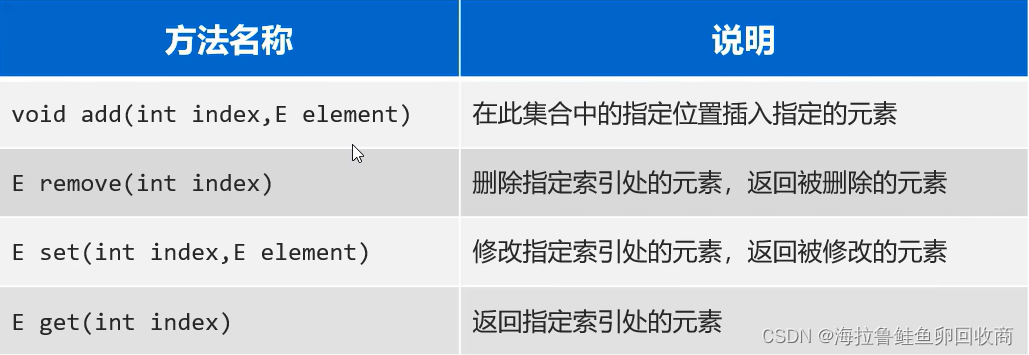
List遍历(有索引)
快捷:List(集合名).fori
ArrayList底层原理
ArrayList和LinkedList底层采用的数据结构(存储、阻值数据的方式)不同,应用场景不同
ArrayList基于数组实现的
查询速度快(根据索引查询数据快
删除效率低:可能要把后面很多数据前移
添加效率极低:可能要把后面很多的数据后移,再添加元素;或者可能需要数组扩容

应用场景:
适合根据索引查询数据,比如根据随机索引取数据
LinkedList底层原理
基于双链表实现的
链表中结点在内存中不连续
单向链表:
查询慢:无论查询哪个数据都要从头开始找
增删相对快(相对于数组而言
双向链表:(LinkedList
查询慢 增删相对较快,对首位元素进行增删改查的速度极快

应用场景:
设计队列:先进先出 后进后出(队列经常要在队尾加,队首减
设计栈:后进先出 先进后出 (push pop
Set集合
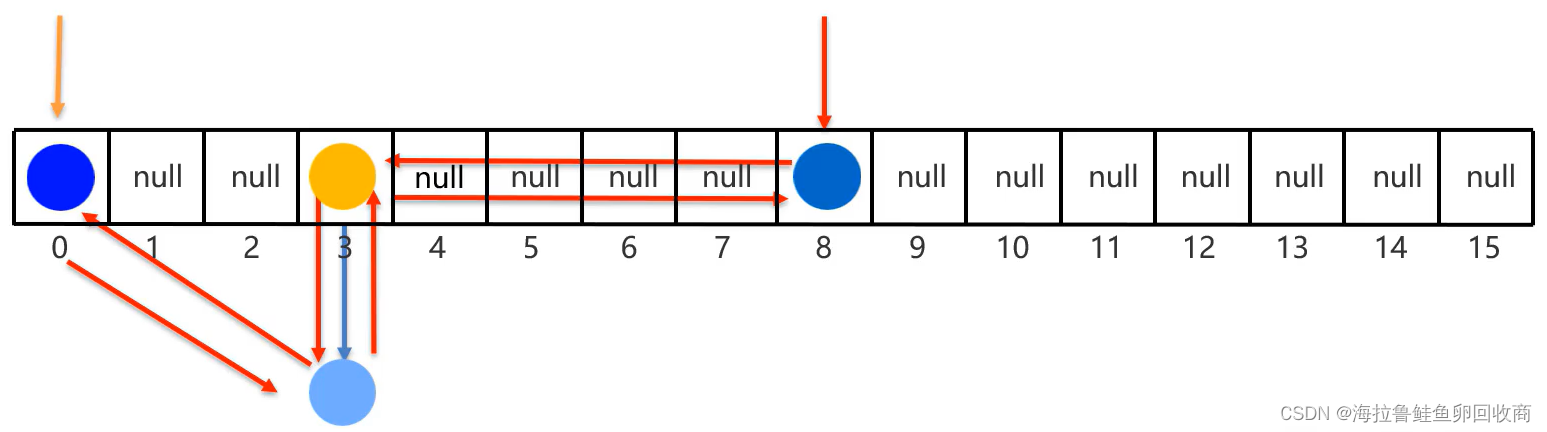
HashSet底层原理
哈希值 int类型的数值,Java中每个对象都有一个哈希值
public int hashCode():返回对象的哈希值
对象哈希值的特点:同一个对象调用hashCode()返回的哈希值相同;不同的对象哈希值一般不同,但也可能相同(哈希碰撞)
基于哈希表实现
哈希表:增删改查性能都较好
JDK8前 哈希表:数组+链表

如果数组快满了,链表会过长,导致查询性能降低 -> 扩容
16 * 0.75 = 12
当12个位置都占满时就会扩容,大约扩容为原来的二倍,再把原数组数据转移到新数组
但可能一个位置的链表很长,故 红黑树出现了
当链表长度超过8,且数组长度>=64,自动将列表转为红黑树
JDK8后 哈希表:数组+链表+红黑树
红黑树:自平衡的二叉树
增删改查性能相对都较好
去重复
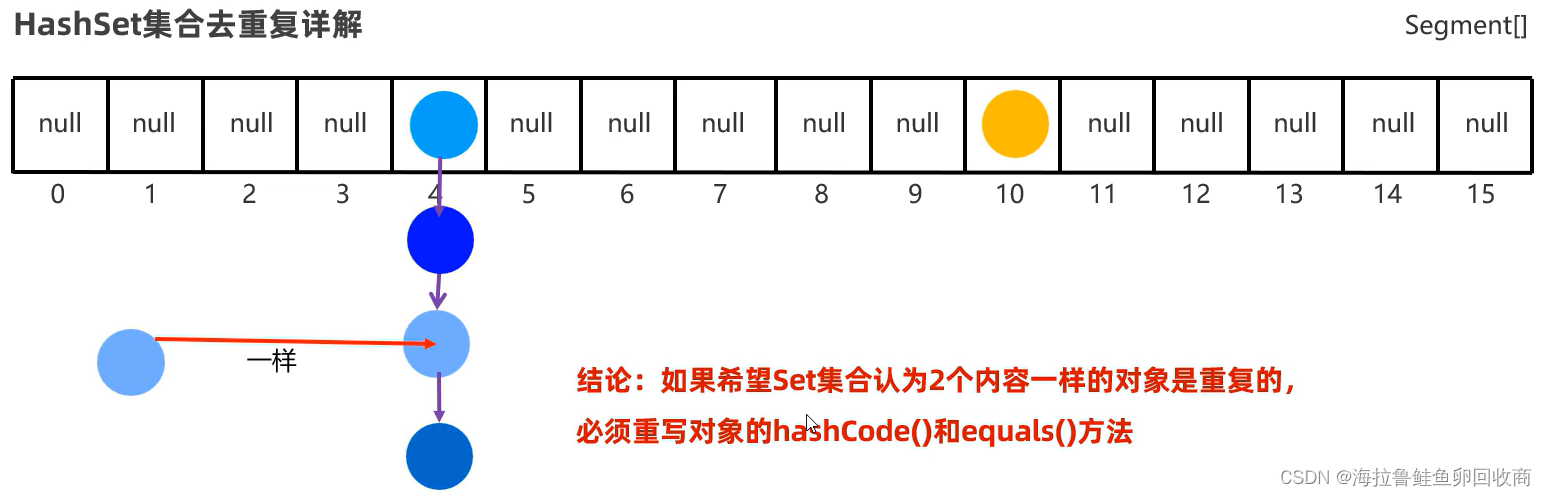
重写hashCode,让他们内容一样就返回相同的哈希值
Generate -> equals() and hashCode()
LinkedHashSet底层原理
基于哈希表(数组+链表+红黑树)实现的
但每个元素都额外多了一个双链表的机制,记录它前后元素的位置
TreeSet底层原理
基于红黑树实现的排序
数值类型:Integer,Double默认按照数值本身的大小进行升序排序
字符串类型:默认按照首字符的编号升序排序
自定义类型:如Student对象,TreeSet默认无法直接排序

方式一
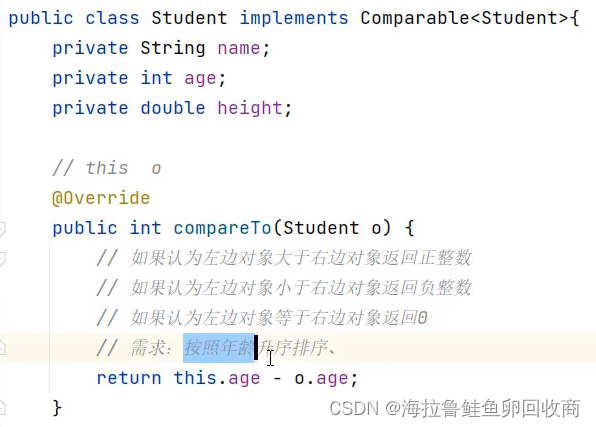
方式二

简化![]()
集合的并发修改异常
使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误

增强for循环 和 forEach没法解决这个问题
可变参数
特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型...参数名称;
特点:可以不传数据给它;可以传一个或同时传多个数据给它;也可以传一个数组给它
好处:常常用来灵活的接收数据
可变参数在方法内部,本质就是一个数组
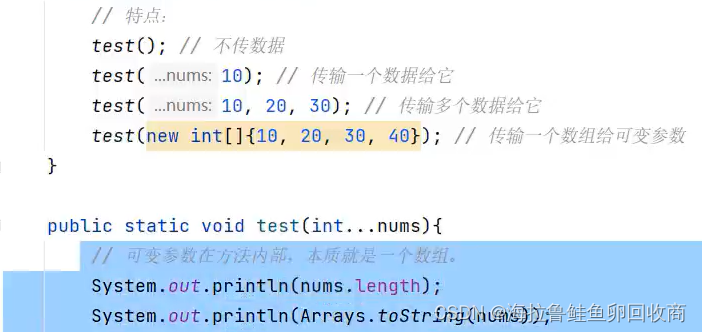
但形参列表中不能有多个可变参数,可变参数要放在形参列表的最后
Collections
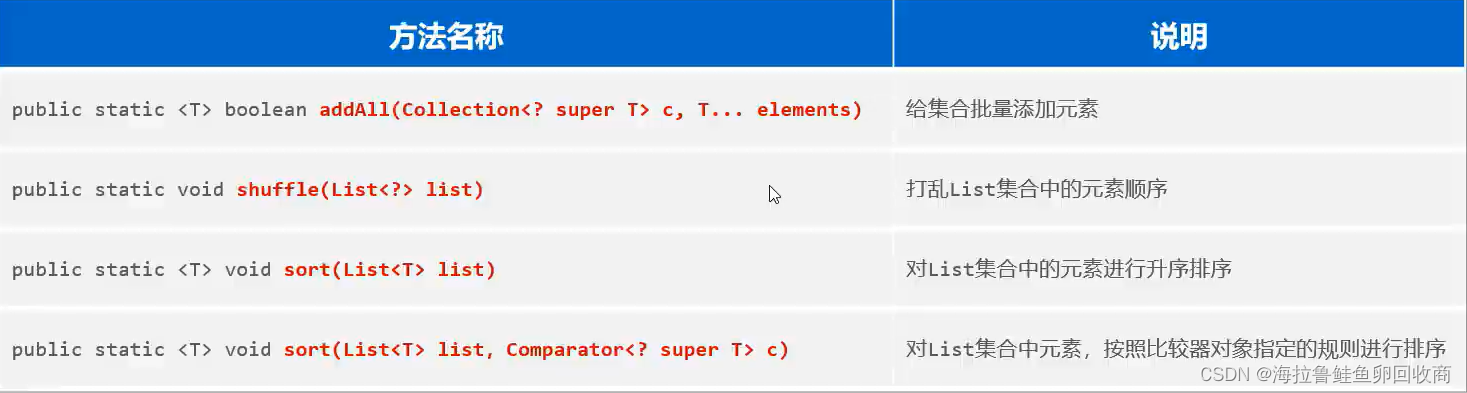
排序

Map双列集合/键值对集合
每个元素包含两个值(键值对)
格式:{key1=value1,key2=value2,key3=value3,...}
每个元素“key=value”是一个键值对/键值对对象/一个Entry对象
键不允许重复,值可以重复,键值一一对应
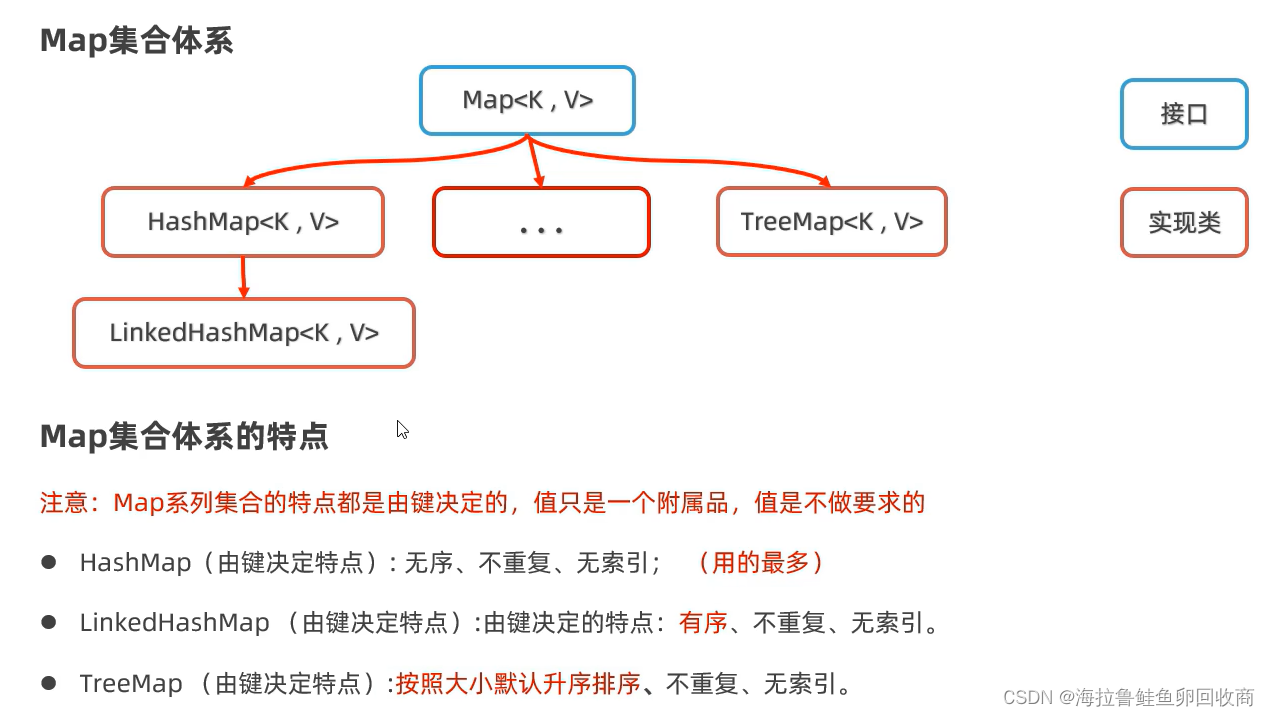
HashMap 不重复,后面重复的数据会覆盖前面的
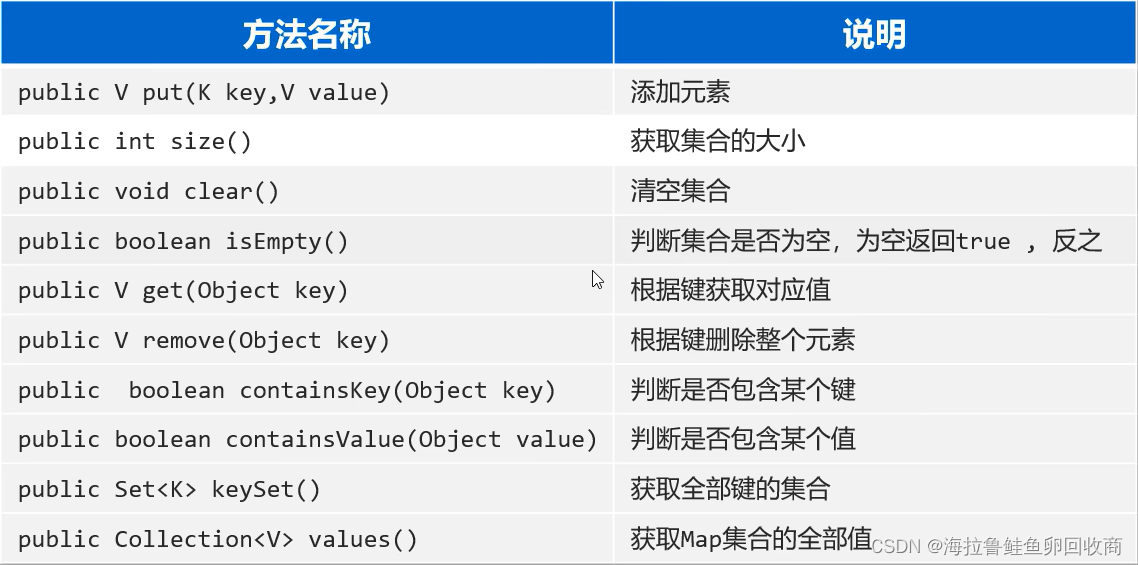
Map常用方法
Map遍历
键找值
先获取Map集合全部的键,再通过遍历键来找值

Set<String> keys = map.keySet();
for(String key : keys){
double value = map.get(key);
System.out.println(key + "----->" + value);
}键值对(难
把“键值对”看成一个整体进行遍历
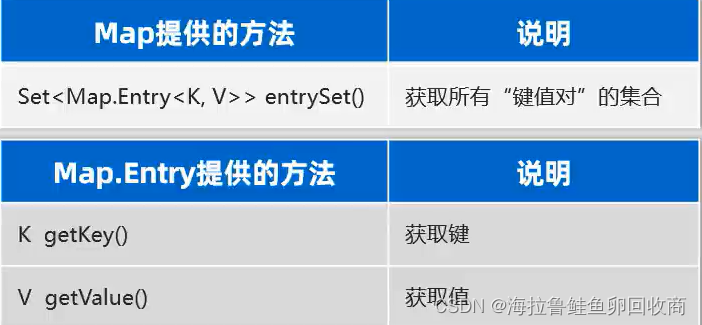
Set<Map.Entry<String,Double>> entries = map.entrySet();
for(Map.Entry<String,Double> entry entries>{
String key = entry.getKey();
double value = entry.getValue();
System.out.println(key + "----->" + value;
}Lambda表达式

map.forEach(k,v) -> {
System.out.println(k + "----->" + v);
}HashMap底层原理
与HashSet一样,基于哈希表实现
实际上,Set系列集合的底层就是基于Map实现的,只是Set集合中的元素要键数据,不要值数据
HashMap的键依赖hashCode方法和equals方法保证键的唯一,存储自定义类型的对象时,重写这两个方法
LinkedHashMap底层原理
基于哈希表实现,每个键值对额外多了一个双链表的机制,记录元素顺序(保证有序)
LinkedHashSet集合的底层原理就是LinkedHashMap
TreeMap底层原理
和TreeMap一样,基于红黑树实现
















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









