







 本文探讨了半监督学习在解决大规模无标签数据中的作用,介绍了平滑、聚类和流形假设,以及半监督分类、回归、聚类和降维。主要方法包括基于差异、生成式、判别式和图基方法,其中协同训练和半监督支持向量机是重要实例。文章以半监督分类问题为重点,展望了未来的研究方向。
本文探讨了半监督学习在解决大规模无标签数据中的作用,介绍了平滑、聚类和流形假设,以及半监督分类、回归、聚类和降维。主要方法包括基于差异、生成式、判别式和图基方法,其中协同训练和半监督支持向量机是重要实例。文章以半监督分类问题为重点,展望了未来的研究方向。
昨天阅读了半监督学习的一些综述,整理如下:
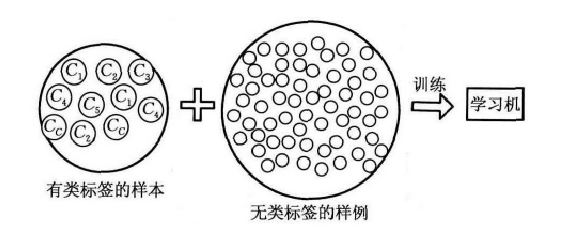
在机器学习的实际应用中,如网页分类、文本分类、基因序列对比、蛋白质功能预测、语音识别、自然语言处理、计算机视觉和基因生物学,很容易找到海量的无类标签的样例,但需要使用特殊设备或经过昂贵且用时非常长的实验过程中进行人工标记才能得到有类标签的样本,由此产生了极少量的有类标签的样本和过剩的无类标签的样例。因此,人们尝试将大量的无类标签的样例加入到有限的有类标签的样本中一起训练进行学习,期望能对学习性能起到改进的作用,于是半监督学习(Semi-Supervised Learning,SSL)产生了,旨在避免数据和资源的浪费,解决监督学习模型泛化能力不强、无监督学习的模型不精确等问题,图1形象地展示了SSL。
1 半监督学习的假设
半监督学习希望利用无类标签的样例帮助改进学习性能,但是需要依赖模型假设才能确保它良好的学习性能。SSL依赖的假设有以下3个:
(1) 平滑假设(Smoothness Assumption)
位于稠密数据区域的两个距离很近的样例的类标签相似,当两个样例北稀疏区域分开时,它们的类标签趋于不同。
(2) 聚类假设(Cluster Assumption)
当两个样例位于同一聚类簇时,它们在很大的概率在有相同的类标签。这个假设的等价定义为低密度分类假设(Low Density Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例划
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









