







一 模型评估

对于这两种误差,测试误差能够反映学习方法对未知的测试数据集的预测能力,是学习中的重要概念,通常将学习方法对未知数据的预测能力称为泛化能力(generalization ability)。
二 泛化能力和过拟合问题
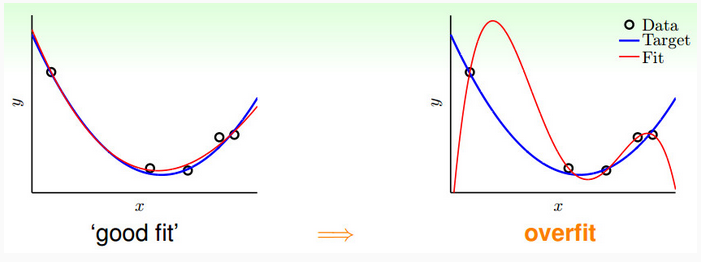
过拟合是指学习时选择的模型所包含的参数过多,以至于出现一模型对已知参数预测得很好,但对未知参数预测得很差的现象。以一维的回归分析为例,如果用高阶多项式去拟合数据,比如有五个数据点,用四次多项式去拟合,如果让该多项式曲线均通过这几个数据点的话,如图2所示,则只有唯一解。这种情况可能使得训练误差很小,但是实际的真实误差就可能很大,这说明学习模型的泛化能力很差(bad generalization),对未知数据的预测能力很差。
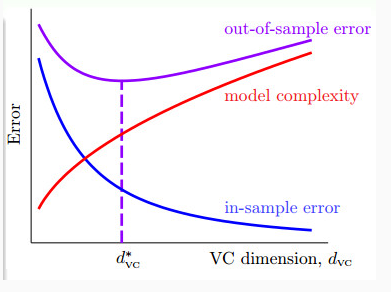
从上面这个图可以看出,测试误差有一个先降后升的趋势,如果定义测试误差曲线的最低点为dvc为最佳vc维,那么随着横坐标向右移,训练误差下降,测试误差上升,当测试误差过大时就产生了过拟合的现象(over fitting);而如果从最佳vc维向左移,这样造成了欠拟合(under fitting)。
造成过拟合成因有:模型的vc维过高,模型复杂度(model complexity)过高;数据中的噪声,如果完全拟合的话,也许与真实情景的偏差更大;数据量有限,使得模型无法真正了解整个数据的真实分布。
三 模型选择
模型选择旨在避免过拟合并提高模型的预测能力,比较典型的方法有正则化和交叉验证。
1 正则化
一般形式如下所示
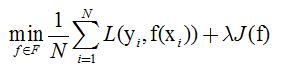
其中,第1项是经验风险,第2项是正则化项,可以为参数向量的范数。 为调整两者之间关系的系数。第1项的经验风险较小时模型可能比较复杂(有多个非零参数),这时第二项模型复杂度会较大,正则化的作用就是选择经验风险与模型复杂度同时较小的模型。
2 交叉验证
交叉验证的基本思想就是重复使用数据,把给定的数据进行切分,将切分的数据分成训练集合测试集,在此基础上反复进行训练、测试以及模型选择。
(1) 简单交叉验证
随机划分数据为两部分:训练集和测试集。将训练集在各种条件(比如不同的参数)下训练模型,从而得到不同的训练模型。利用每个模型分别对测试集进行测试,选出测试误差最小的模型。
(2) S折交叉验证(S-fold cross validation)
随机将数据划分为S个互不相同的子集,然后利用S-1个子集的数据训练模型,利用余下的子集测试模型。将这一过程重复进行S次,最后选出S次评测中平均测试误差最小的模型。
(3) 留一交叉验证
留一交叉验证为S折交叉验证的特殊情况,即S=N(N为样本容量),往往在数据缺乏的时候使用。
引用:
1 作者Jason Ding http://www.open-open.com/lib/view/open1423572428467.html
2 李航 《统计学习方法》














 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









