







IO包中的其它类
Properties
可以和流操作关联的集合对象
Map
|--Hashtable
|--Properties
Properties:该集合不需要泛型,因为该集合中的键值对都是String类型。
1、存入键值对:setProperty(key,value);
2、获取指定键对应的值:value getProperty(key);
3、获取集合中所有键元素: Enumeration PropertyNames(); 在jdk1.6版本给该类提供一个新方法。Set<String> stringPropertyNames();
4、列出该集合中的所有键值对,可以通过参数打印流指定列出到目的地。
list(PrintStream); list(PrintWriter); 例:list(System.out):将集合的键值对打印到控制台 list(new PrintStream("prop.txt")):将集合中的键值存储到prop.txt文件中。
5、可以将流中的规则数据加载进行集合,并称为键值对。 load(InputStream):jdk1.6版本。提供了新方法。load(Reader):注意:流中的数据要是"键=值"的规则数据。
6、可以将集合中的数据进行指定目的的存储。
store(OutputStream,String comment)方法。 jdk1.6版本。提供了新的方法。store(Writer,string comment):使用该方法存储 会带着存储的时间。
打印流
PrintStream:是一个字节打印流,System.out对应的类型就是PrintStream。它的构造函数可以接收三种数据类型的值。
1、字符串路径。
2、File对象。
3、OutputStream.
PrintWriter:是个一个字符打印流。构造函数可以接收四种类型的值。
1、字符串路径。
2、File对象。对于1,2类型的数据,还可以指定编码表。也就是字符集。
3、OutputStream
4、Writer 对于3,4类型的数据可以指定字自动刷新。主要:该自动刷新值为true时,只有三个方法可以用:println,printf,format。
如果想要既有自动刷新,又可以执行编码。
Printer pw = new PrintWriter(new OutputStreamWriter(new FileOutputStream("a.txt"),"utf-8"),true);
//如果想要提高效率。还要使用打印方式
Printer pw = new PrintWriter(new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a.txt"),"utf-8")),true);
管道流
PipedInputStream
PipedOutputStream
特点:读取管道流和写入管道流可以进行链接。链接方式:
1、通过两个流对象的构造函数。
2、通过两个对象的connect方法。
通常两个流在使用时,需要加入多线程技术,也就是让读写同时运行。注意:对于read方法。该方法是阻塞式的,也就是没有数据的情况,该方法会等待。
示例1:PipedInputStream和PipedOutputStream:输入输出可以直接进行连接,通过结合线程使用
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStream
{
public static void main(String[] args) throws Exception
{
PipedInputStream input = new PipedInputStream();
PipedOutputStream output = new PipedOutputStream();
input.connect(output);
new Thread(new Input(input)).start();
new Thread(new Output(output)).start();
}
}
class Input implements Runnable
{
private PipedInputStream in;
Input(PipedInputStream in)
{
this.in = in;
}
public void run()
{
try
{
byte[] buf = new byte[1024];
int len = in.read(buf);
String s = new String(buf,0,len);
System.out.println("s="+s);
in.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
class Output implements Runnable
{
private PipedOutputStream out;
Output(PipedOutputStream out)
{
this.out = out;
}
public void run()
{
try
{
out.write("hi,管道来了!".getBytes());
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
RandomAccessFile
该对象并不是流体系中的一员。该对象中封装了字节流,同时还封装了一个缓冲区(字节数组),通过内部的指针来操作数组中的数据。
该对象的特点:
1、该对象只能操作文件,所以构造函数接收两种类型的参数。a,字符串路径 b,File对象。
2、该对象既可以对文件进行读取,也可以写入。在进行对象实例化时,必须要指定的该对象的操作模式,r rw等。
该对象中有可以直接操作基本数据类型的方法。该对象最有特点的方法:
skipBytes():跳过指定的字节数。
seek():指定指针的位置。
getFilePointer():获取指针的位置。
通过这些方法,就可以完成对一个文件数据的随机访问。想读哪里就读哪里,想往哪里写就往哪里写。
该对象功能,可以度数据,可以写入数据,如果写入位置已有数据,会发生数据覆盖。也就是可以对数据进行修改。
在使用该对象时,建议数据都是有规则的。或者是分段的。
注意:该对象在实例化时,如果要操作的文件不存在,会自动建立。如果要操作的文件存在,则不会建立,如果存在文件有数据。那么在没有指定指针位置的情况下,写入数据,会将文件开头的数据覆盖
可以用于多线程的下载,也就是通过多线程往一个文件中同时存储数据。
示例1:
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileDemo
{
public static void main(String[] args) throws IOException
{
writeFile();
}
//使用RandomAccessFile对象写入一下人员信息,比如姓名和年龄
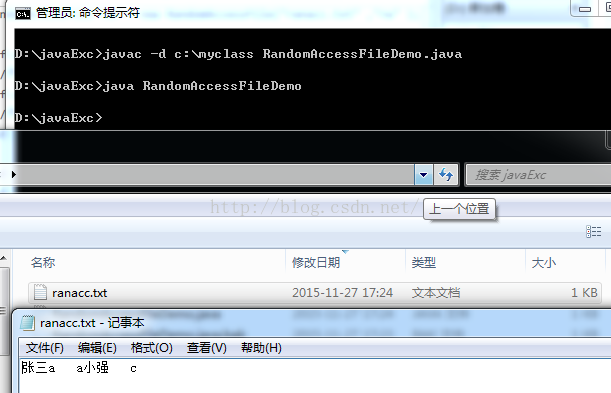
public static void writeFile() throws IOException
{
//如果文件不存在,则创建,如果文件存在,不创建
RandomAccessFile raf = new RandomAccessFile("ranacc.txt","rw");
raf.write("张三".getBytes());
//使用write方法之写入最后一个字节
raf.write(97);
//使用writeInt方法写入四个字节(int类型)
raf.writeInt(97);
raf.write("小强".getBytes());
raf.writeInt(99);
raf.close();
}
}
示例2:
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileDemo
{
public static void main(String[] args) throws IOException
{
readFile();
}
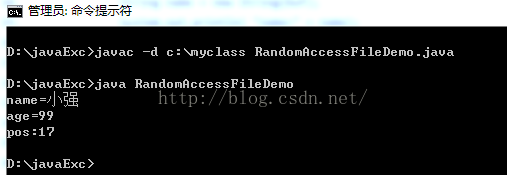
public static void readFile() throws IOException
{
RandomAccessFile raf = new RandomAccessFile("ranacc.txt","r");
//通过seek设置指针的位置
raf.seek(9);//随机的读取,只要指定指针的位置即可
byte[] buf = new byte[4];
raf.read(buf);
String name = new String(buf);
System.out.println("name="+name);
int age = raf.readInt();
System.out.println("age="+age);
System.out.println("pos:"+raf.getFilePointer());
raf.close();
}
}
示例3:
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileDemo
{
public static void main(String[] args) throws IOException
{
randomWrite();
}
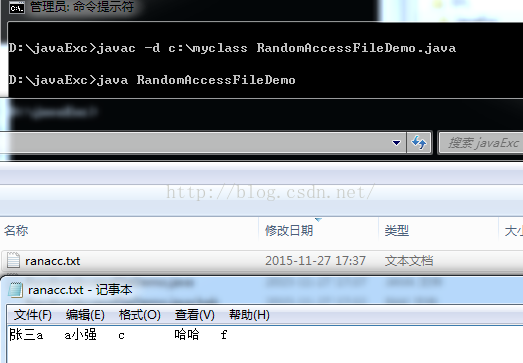
public static void randomWrite() throws IOException
{
RandomAccessFile raf = new RandomAccessFile("ranacc.txt","rw");
raf.seek(3*8);//往指定的位置写入数据
raf.write("哈哈".getBytes());
raf.writeInt(102);
raf.close();
}
}
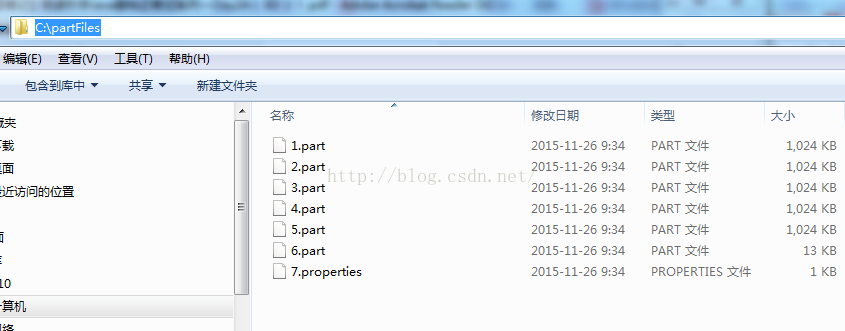
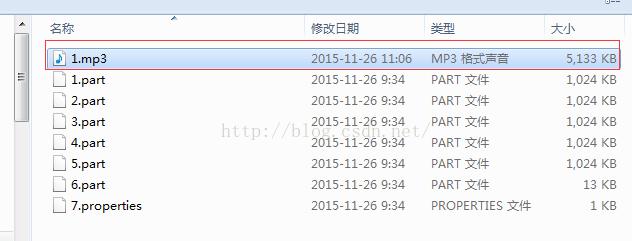
需求:文件切割器
//如果要一个对文件数据切割。一个读取对应多个输出
FileInputStream fis = new FileInputStream("1.mp3");
FileOutputStream fos = null;
byte[] buf = new byte[1024*1024];//是一个1M的缓冲区
int lne = 0;
int count = 1;
while((len=fis.read(buf))!=-1)
{
fos = new FileOutputStream((count++)+".part");
fos.write(buf,0,len);
fos.close();
}
fis.close();
//这样就是将1.mp3文件切割成了多个碎片文件。
想要合并使用SequenceInputStream即可。
对于切割后,合并是需要的一些源文件信息。
可以通过配置文件进行存储。该配置可以通过键=值的形式存在。
然后通过Properties对象进行数据的加载和获取代码:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
class SplitFileDemo
{
private static final int SIZE = 1024*1024;
public static void main(String[] args) throws IOException
{
File file = new File("1.mp3");
splitFile(file);
}
public static void splitFile(File file)throws IOException
{
//用读取流关联文件
FileInputStream fis = new FileInputStream(file);
//定义一个1M的缓冲区
byte[] buf = new byte[SIZE];
//创建目的
FileOutputStream fos = null;
int len = 0;
int count = 1;
//切割文件时,必须记录被切割文件的名称,以及切割出来的碎片文件的个数,以方便合并
//这个信息是为了进行扫描,使用键值对的方式,用到了properties对象。
Properties prop = new Properties();
File dir = new File("c:\\partFiles");
if(!dir.exists())
dir.mkdirs();
while((len = fis.read(buf))!=-1)
{
fos = new FileOutputStream(new File(dir,(count++)+".part"));
fos.write(buf,0,len);
fos.close();
}
//将被切割文件的信息保存到prop集合中
prop.setProperty("partcount",count+"");
prop.setProperty("filename",file.getName());
fos = new FileOutputStream(new File(dir,count+".properties"));
//将prop集合中的数据存储到文件中
prop.store(fos,"save file info");
fis.close();
fos.close();
}
}
系列流:也称为合并流。
SequenceInputStream
特点:可以将多个读取流合并成一个流。这样操作起来很方便
原理:其实就是将每一个读取流对象存储到一个集合中。最后一个流对象结尾作为这个流的结尾
两个构造函数
1、SequenceInputStream(InputStream in1,InputStream in2) 可以两个读取流合并成一个流
2、SequenceInputStream(Enumeration<? extends InputStream> en) 可以将枚举中的多个流合并成一个流
作用:可以用于多个数据合并。
P.S.
因为Enumeration是Vector中特有的取出方式。而Vector被ArrayList取代。所以ArrayList集合更高效一些。那么如何获取Enumeration呢?
//方式一:Collections.enumeration方法
public static <T> Enumeration<T> enumeration(final Collection<T> c) {
return new Enumeration<T>() {
private final Iterator<T> i = c.iterator();
public boolean hasMoreElements() {
return i.hasNext();
}
public T nextElement() {
return i.next();
}
};
}
//方式二:自己实现
ArrayList<FileInputStream> al = new ArrayList<FileInputStream>();
for(int x=1;x<4;x++)
al.add(new FileInputStream(x+".txt"));
Iterator<FileInputStream> it = al.iterator();
Enumeration<FileInputStream> en = new Enumeration<FileInputStream>()
{
public boolean hasMoreElements()
{
return it.hasNext();
}
pubic FileInputStream nextElement()
{
return it.next();
}
}
//多个流就变成了一个流,这就是数据源。
SequenceInputStream sis = new SequenceInputStream(en);
//创建数据目的。
FileOutputStream fos = new FileOutputStream("4.txt");
byte[] buf = new byte[1024*1024];
int len = 0;
while((len = sis.read(buf))!=-1)
{
fos.write(buf,0,len);
}
fos.close();
sis.close();代码:(需求:文件合并)
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FilenameFilter;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.Iterator;
import java.util.Properties;
public class MergeFileDemo
{
private static final int SIZE = 1024*1024;
public static void main(String[] args) throws IOException
{
File file = new File("c:\\PartFiles");
mergeFile(file);
}
public static void mergeFile(File dir) throws IOException
{
//获取指定目录下的配置文件对象
File[] files = dir.listFiles(new SuffixFilter(".properties"));
if(files.length!=1)
throw new RuntimeException(dir+",该目录下没有properties扩展名的文件或者不唯一");
//记录配置文件对象
File confile = files[0];
//获取该文件中的信息
Properties prop = new Properties();
FileInputStream fis = new FileInputStream(confile);
prop.load(fis);
String filename = prop.getProperty("filename");
int count = Integer.parseInt(prop.getProperty("partcount"));
//获取该目录下的所有碎片文件
File[] partFiles = dir.listFiles(new SuffixFilter(".part"));
if(partFiles.length!=(count-1))
throw new RuntimeException("碎片文件不符合要求,个数不对!应该是"+count+"个");
//将碎片文件和流对象关联并存储到集合中
ArrayList<FileInputStream> al = new ArrayList<FileInputStream>();
for(int x = 1;x<=partFiles.length;x++)
{
al.add(new FileInputStream(partFiles[x-1]));
}
final Iterator<FileInputStream> it = al.iterator();
//将多个流合并成一个序列流
Enumeration<FileInputStream> en = Collections.enumeration(al);
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream(new File(dir,filename));
byte[] buf = new byte[1024*1024];
int len = 0;
while((len=sis.read(buf))!=-1)
{
fos.write(buf,0,len);
}
fos.close();
sis.close();
}
}
class SuffixFilter implements FilenameFilter
{
private String suffix;
public SuffixFilter(String suffix)
{
this.suffix = suffix;
}
public boolean accept(File dir,String name)
{
return name.endsWith(suffix);
}
}
对象系列化
ObjectInputStream
ObjectOutputStream
可以通过这两个流对象直接操作已有对象并将对象进行本地持久化存储。存储后的对象可以进行网络传输。
两个对象的特有方法:
ObjectInputStream Object readObject():该方法抛出异常:ClassNotFountException。
ObjectOutputStream void writeObject(Object):被写入的对象必须实现一个接口:Serializable 否则会抛出:NotSerializableException
Serializable:该接口其实就是一个没有方法的标记接口。
用于给类指定一个UID。该UID是通过类中的可序列化成员的数字签名运算出来的一个long型的值。
只要是这些成员没有变化,那么该值每次运算都一样。
该值用于判断被系列化的对象和类文件是否兼容。
如果被系列化的对象需要被不同的类版本所兼容。可以在类中自定义UID。定义方式:static final long serialVersionUID=42L;
注意:对应静态的成员变量,不会被系列化。对应非静态页不想被系列化的成员而言,可以通过transient关键字修饰。通常,这两个地响成对使用。
示例1:
import java.io.Serializable;
import java.io.ObjectOutputStream;
import java.io.IOException;
import java.io.FileOutputStream;
class Person implements Serializable
{
private String name;
private int age;
public Person(String name,int age)
{
this.name = name;
this.age=age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}
public class SerDemo
{
public static void main(String[] args) throws IOException
{
Person p = new Person("张三",18);
ObjectOutputStream ops = new ObjectOutputStream(new FileOutputStream("abcd.txt"));
ops.writeObject(p);
}
}
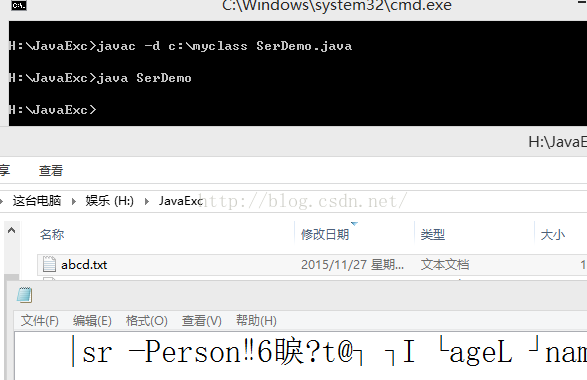
示例2:
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.io.IOException;
public class SerDemo
{
public static void main(String[] args) throws Exception
{
readObj();
}
public static void readObj() throws Exception
{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("abcd.txt"));
Person p = (Person)ois.readObject();
System.out.println(p.getName()+":"+p.getAge());
ois.close();
}
}

如果修改Person类中的属性修饰符public就会抛如下异常。再反系列化的时候会抛异常
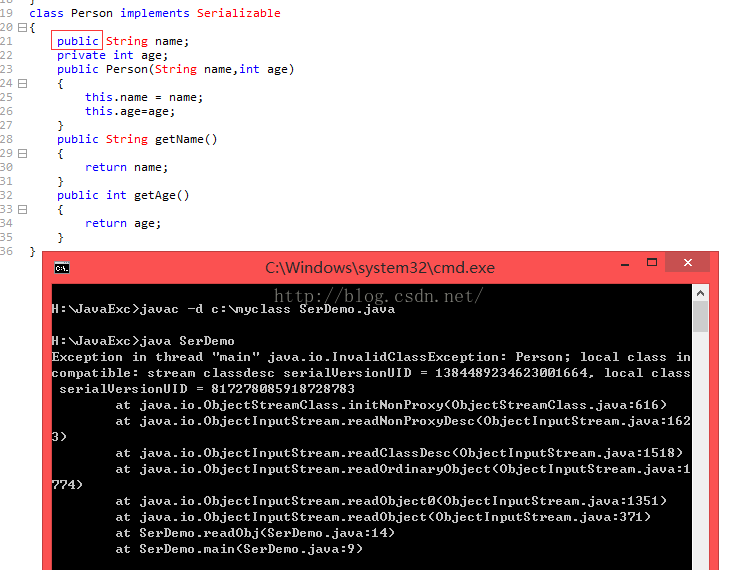
原因分析:Serializable:用于给被系列化的类加入ID号,用于判断类和对象是否同一个版本。


为Person类添加系列号属性。此时,再将Person类中属性修饰修改public,也不会出现异常。
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.Serializable;
public class SerDemo
{
public static void main(String[] args) throws Exception
{
/*Person p = new Person("张三",18);
ObjectOutputStream ops = new ObjectOutputStream(new FileOutputStream("abcd.txt"));
ops.writeObject(p);*/
readObj();
}
public static void readObj() throws Exception
{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("abcd.txt"));
Person p = (Person)ois.readObject();
System.out.println(p.getName()+":"+p.getAge());
ois.close();
}
}
class Person implements Serializable
{
private static final long serialVersionUID=27;
public String name;
public int age;
public Person(String name,int age)
{
this.name = name;
this.age=age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}操作基本数据类型的流对象
DateInputstream
操作基本数据类型的方法:
int readInt():一次读取四个字节,并将其转成int值。
boolean readBoolean():一次读取一个字节。
short readShort();
long readLong();
剩下的数据类型一样。
String readUTF():按照utf-8修改版读取字符。注意,它只能读writeUTF()写入的字符数据。
DataOutputStream
操作基本数据类型的方法:
writeInt(int):一次写入四个字节。注意和write(int)不同。write(int)只能将整数的最低一个8位写入。剩余三个8位丢弃。
writeBoolean(boolean);
writeShort(short);
writeLong(long);剩余的数据类型也一样。
writeUTF(String):按照utf-8修改版将字符数据进行存储。只能通过readUTF读取。
通常只要操作基本数据类型的数据。就需要通过DataStream进行包装。通常成对使用。
示例1:
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
class DataStreamDemo
{
public static void main(String[] args) throws IOException
{
writeData();
}
public static void writeData() throws IOException
{
DataOutputStream dos = new DataOutputStream(new FileOutputStream("data.txt"));
dos.writeUTF("你好");
dos.close();
}
}
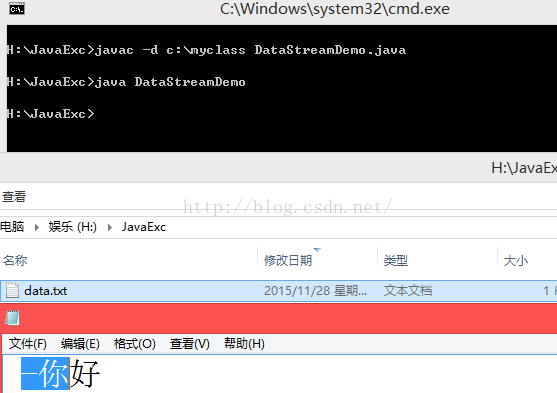
示例2:
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.IOException;
class DataStreamDemo
{
public static void main(String[] args) throws IOException
{
readData();
}
public static void readData() throws IOException
{
DataInputStream dis = new DataInputStream(new FileInputStream("data.txt"));
String str = dis.readUTF();
System.out.println(str);
dis.close();
}
}
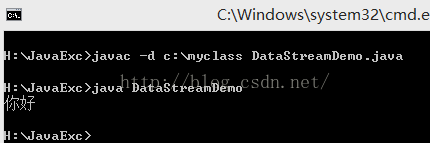
操作数组的流对象
1、操作字节数组
ByteArrayInputStream
ByteArrayOutputStream
toByteArray();
toString();
writeTo(OutputStream);
2、操作字符数组
CharArrayReader
CharArrayWriter
对于这些流,源是内存。目的也是内存。
而且这些流并未调用系统资源。使用的就是内存中的数组。所以这些在使用的时候不需要close。
操作数组的读取流的写入流,在构造函数可以使用空参数。因为它内置了一个可变长度数组作为缓冲区。
这几个流的出现其实就是通过流的读写思想在操作数组。
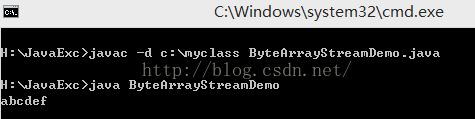
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
public class ByteArrayStreamDemo
{
public static void main(String[] args) throws IOException
{
ByteArrayInputStream bis = new ByteArrayInputStream("abcdef".getBytes());
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int ch = 0;
while((ch=bis.read())!=-1)
{
bos.write(ch);
}
System.out.println(bos.toString());
}
}
编码转换
编码表的由来:计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字表示,并一一对应,形成一张表,这就是编码表。
常见的编码表
ASCII:美国标准信息交换码,用一个字节的7位可以标识。
ISO8859-1:拉丁码表。欧洲码表,用一个字节的8位标识。
GB2312:中国的中文编码表。
GBK:中国的中文编码表升级,融合了更多的中文文字符号。
Unicode:国际标准码,融合了多种文字。
所有文字都用两个字节表示,Java语言使用就是Unicode
UTF-8:最多用三个字节来表示一个字符。
编码转换:
字符串-->字节数组:编码。通过getBytes(charset);
字符数组-->字符串:编码。通过String类型的构造函数完成。String(byte[],charset);
如果编错了,没救!
如果编对了,解错了,有可能还有救!
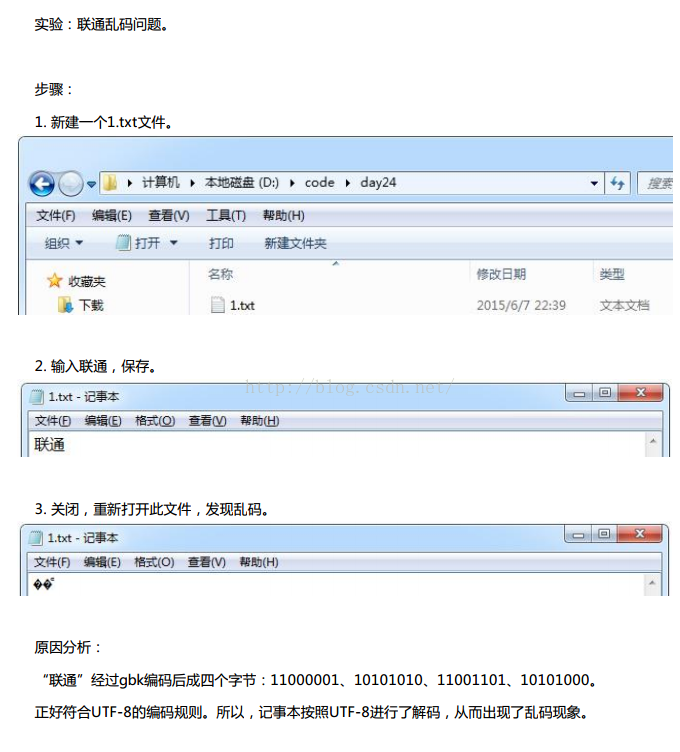
String s= "你好";
//编码。byte[] b = s.getBytes("GBK");
//解码。
String s1 = new String(b,"iso8859-1");
System.out.println(s1);//????
//想要还原。
/*对s1先进行一次解码码表的编码。获取原字节数组。然后再对原字节数据进行指定编码表的解码*/
byte[] b1 = s1.getBytes("iso8859-1");
String s2 = new String(b1,"gbk");
System.out.println(s2);//你好。
这种情况在tomcat服务器会出现。
因为tomcat服务器默认是iso8859-1的编码表。
所以客户端通过浏览器向服务端通过get提交方式提交中文数据时,服务端获取会使用ISO8859-1进行中文数据的解码。会出现乱码。这时必须对获取的数据进行iso8859-1编码。然后再按照页面指定的编码进行解码即可
而对于post提交,这种方法也通用。但是post有更好的解决方案。request.setCharacterEncoding("utf-8");即可。所以建立客户端提交试用post提交方式。















 1841
1841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









