









BS2(Blob Storage Service)是我们平台的简写,云存储平台主要是为任意格式文件提供临时或者永久的存储服务,用户可以通过调用API,在任何应用、任何时间、任何地点上传和下载数据。
这篇文章不涉及技术细节,主要是一些运营体系的理念。
这篇文章不涉及技术细节,主要是一些运营体系的理念。
发展历程:
由于涉及到公司的保密数据,只能提供作为私有云(部分数据在CDN)的访问量发展历程
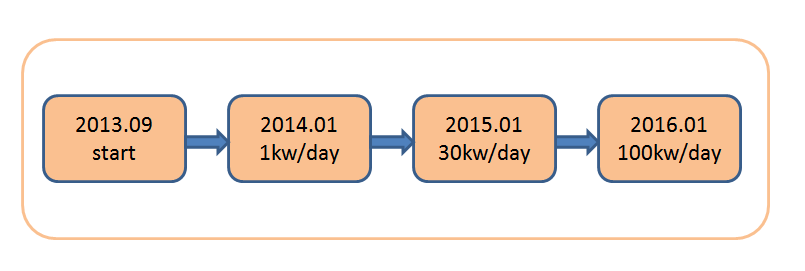
2016.01的峰值:
qps:20k/s
flow: 3GByte/s
系统指标:
上传:99.99%
下载:99.99%
删除:99.99%
基本概念:
平台有几大共性:一是稳定,二是发展,三是提高质量,四是降低成本。
系统指标:
上传:99.99%
下载:99.99%
删除:99.99%
基本概念:
平台有几大共性:一是稳定,二是发展,三是提高质量,四是降低成本。
平台在初期更关注稳定的高速发展,先把摊子铺开,占有市场份额,再考虑优化和节省成本,云存储平台的发展离不开两大核心:
1.稳定的底层文件系统
2.健全的运营体系
下面列举了BS2运营体系从0到1做的一些工作:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
一.用户管理系统
三.自动化
程序的自动化
1.自动化切点:某台机器故障无法则自动摘掉这个IP,又比如连的IP是双线的,电信线路故障了则切换至联通线路
2.自动化拉起:进程出现故障退出时,通过脚本检测并自动拉起,crontab就能很好完成这个任务
3.自动化重启:通常一个机器下面会有多个进程,进程间需要做一定的隔离,做的互不影响,比如某个进程内存异常,一旦超出了阀值,则自动重启并记录下来
自动化部署/升级/回滚
1.如果公司有一套发布系统,那么就会省下很多功夫
2.如果公司没有一套发布系统,则自行利用工具搭建,比如ssh、ansible
日志自动化压缩/删除
1.磁盘的空间是有限的,在有成千上万台机器的情况下,必须依赖定时脚本压缩日志和删除久远的日志,这里要注意压缩的IO使用率,可以通过pv来限制IO
四.易扩展
平台的飞速发展,所以系统架构设计一定是可横向扩展,
当平台不足以支撑当前的业务量的时候,通过快速的增加机房则可以解决问题
五.实时告警
实时告警的重要性就不啰嗦了,简单罗列下我们做的部分监控,监控的手段可以是邮件、短信、微信、图表展示(highcharts和grafana都是不错的选择),根据不同的紧急情况实施不同的策略
1.机房网络丢包实时监控
2.机器磁盘坏盘实时监控
3.机器磁盘空间实时监控
4.机器网卡带宽实时监控
5.上传下载成功率实时监控
6.上传下载速率实时监控
7.上传下载业务实时监控
8.系统重要组件实时监控
9.系统使用的开源软件监控
10.进程占用资源实时监控
六.预警
预警的意思就是根据系统的一些数据提前做出决策,云存储平台主要是三个方面:
九.每日汇总
监控和告警的作用在于处理突发事件,每日汇总更倾向于看一些统计数据,和处理一些告警系统没发现的异常,我们会在每天的凌晨自动对上一天的数据进行多维度分析汇总,并以邮件方式群发
1.系统的整体统计
2.按照功能的统计
3.按照机房的统计
4.按照业务的统计
5.按照协议的统计
6.数据异常的机房、机器、业务
十.数据挖掘
数据挖掘更多是用于决策,
从数据特性可以看到哪些业务飞速发展,有什么特征,比如2015年短视频的爆发等等
2.健全的运营体系
下面列举了BS2运营体系从0到1做的一些工作:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
一.用户管理系统
我们一开始精力并没有放在用户接入平台,全凭手动在数据库插入用户注册数据,
后来逐渐发展,每天都会有新业务方来申请服务,这个时候就考虑着要做一个用户管理系统了,
这也是比较正道的做法,一是腾出人手,二是固化下来的流程肯定比人工靠谱。
二.平台SDK
用户用得最频繁的就是上传、下载、删除,提供标准的SDK有几大好处
1.节省研发人员的答疑时间(用户总会有问不完的问题,调试问题)
2.标准化流程,用户不需要去了解API的细节,傻瓜式服务
3.可以在SDK中嵌入采集模块,根据用户体验数据来调整机房服务,也更好的衡量平台的服务质量,单从服务器采集的数据来评估访问质量是不科学的
三.自动化
程序的自动化
1.自动化切点:某台机器故障无法则自动摘掉这个IP,又比如连的IP是双线的,电信线路故障了则切换至联通线路
2.自动化拉起:进程出现故障退出时,通过脚本检测并自动拉起,crontab就能很好完成这个任务
3.自动化重启:通常一个机器下面会有多个进程,进程间需要做一定的隔离,做的互不影响,比如某个进程内存异常,一旦超出了阀值,则自动重启并记录下来
自动化部署/升级/回滚
1.如果公司有一套发布系统,那么就会省下很多功夫
2.如果公司没有一套发布系统,则自行利用工具搭建,比如ssh、ansible
日志自动化压缩/删除
1.磁盘的空间是有限的,在有成千上万台机器的情况下,必须依赖定时脚本压缩日志和删除久远的日志,这里要注意压缩的IO使用率,可以通过pv来限制IO
四.易扩展
平台的飞速发展,所以系统架构设计一定是可横向扩展,
当平台不足以支撑当前的业务量的时候,通过快速的增加机房则可以解决问题
五.实时告警
实时告警的重要性就不啰嗦了,简单罗列下我们做的部分监控,监控的手段可以是邮件、短信、微信、图表展示(highcharts和grafana都是不错的选择),根据不同的紧急情况实施不同的策略
1.机房网络丢包实时监控
2.机器磁盘坏盘实时监控
3.机器磁盘空间实时监控
4.机器网卡带宽实时监控
5.上传下载成功率实时监控
6.上传下载速率实时监控
7.上传下载业务实时监控
8.系统重要组件实时监控
9.系统使用的开源软件监控
10.进程占用资源实时监控
六.预警
预警的意思就是根据系统的一些数据提前做出决策,云存储平台主要是三个方面:
1.机房空间预警,根据磁盘增长曲线,估算出何时需要扩容或者新建机房
2.机房带宽预警,根据带宽增长曲线,估算出何时需要增加带宽资源,比如绑定多网卡和升级交换机等等手段
3.机房qps预警,根据qps增长曲线,结合现有的机房qps能力,估算出何时需要扩容或者新建机房
七.机房调度
七.机房调度
用户路由到哪个机房,有两个基本的原则,一是就近访问,二是同ISP访问,
这样去调配用户只是最基本的做法,网络环境往往很复杂,不能一概而论,
所以分析用户的访问数据就至关重要,既要按地区分析,也要按运营商分析,
根据数据得哪些用户访问质量好哪些用户访问质量差,再作出最优的决策。
八.运营系统
运营系统的核心有两点:
固化重复劳动
简单举个例子,业务方希望提供近一个月的访问数据,包括成功率,访问速率,文件大小分布,不同类型的文件的访问质量,用户的分布,如果没有一个分析系统,那么靠人力去整理这些数据就会非常耗时,所以做了很多一键分析功能,下面罗列了一些比较重要的
1.一键分析机房的访问量、成功率、流量、容量、速率等等
2.一键分析业务的访问量、成功率、流量、容量、速率等等
3.一键分析系统组件的成功率与性能,这些数据很好的支撑了后期的架构优化
快速响应故障
故障有很多种情况,常见的有机房网络故障,系统组件异常,用户要求立刻刷新缓存,修复文件等等,不管是什么故障,宗旨是快速响应快速处理,在有几十个机房几千台机器的前提下,要做到十分钟内解决问题,如果分析系统不够强大,是不能做到的,这些分析都依赖于数据的采集,根据平台的特性来做,这里列举了一些重要的手段,
1.一键分析机房成功率与速率,直接定位到机器并定位原因
2.一键分析业务的成功率与速率,直接定位到机器并定位原因
3.一键分析系统组件的成功率,直接定位到机器并定位原因
4.一键清除缓存(应急手段)
5.一键删除文件(应急手段,比如有违规文件)
这是我比较满意的一套系统,从零开始,已经发展至上一百个分析功能
监控和告警的作用在于处理突发事件,每日汇总更倾向于看一些统计数据,和处理一些告警系统没发现的异常,我们会在每天的凌晨自动对上一天的数据进行多维度分析汇总,并以邮件方式群发
1.系统的整体统计
2.按照功能的统计
3.按照机房的统计
4.按照业务的统计
5.按照协议的统计
6.数据异常的机房、机器、业务
十.数据挖掘
数据挖掘更多是用于决策,
从数据特性可以看到哪些业务飞速发展,有什么特征,比如2015年短视频的爆发等等















 1289
1289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









