







etcd-PageWriter分析
在看etcd的代码,看到pageWriter,分析说明一下。
功能介绍
它实现了批量保存,按照页面块(page)的方式来保存
属性介绍
PageWriter结构体如下
type PageWriter struct {
// Writer
w io.Writer
// 一页中已经填满的字节数
pageOffset int
// 每一页多少byte
pageBytes int
// 缓存区中等待写入的字节数
bufferedBytes int
// 缓存区
buf []byte
// 水位线,达到之后就表示缓冲区满了,需要flush缓冲区
bufWatermarkBytes int
}
方法分析
PageWriter提供了两个对外的方法
-
Writer
写入数据。功能简述如下
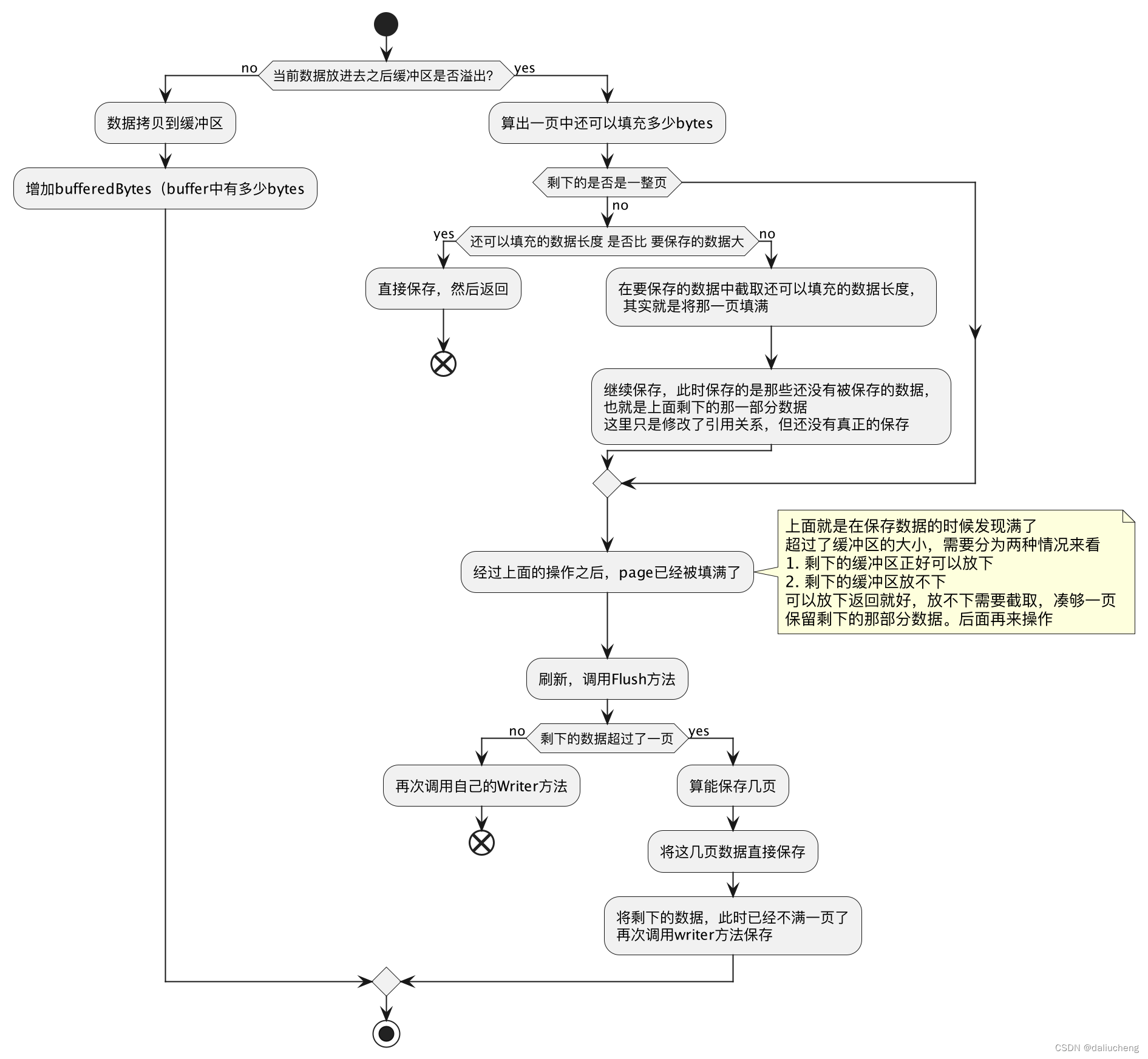
-
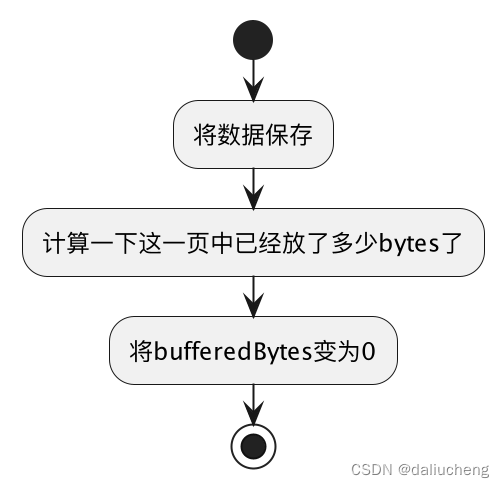
Flush
将buffer中的数据保存。
源码分析
package ioutil
import (
"io"
"go.etcd.io/etcd/client/pkg/v3/verify"
)
var defaultBufferBytes = 128 * 1024 // 128kb
// PageWriter implements the io.Writer interface so that writes will
// either be in page chunks or from flushing.
type PageWriter struct {
w io.Writer
// pageOffset tracks the page offset of the base of the buffer
// 缓冲区中已经使用的偏移量
pageOffset int
// pageBytes is the number of bytes per page
// 每一页能保存多少
pageBytes int
// bufferedBytes counts the number of bytes pending for write in the buffer
// 缓冲区中等待着写的bytes
bufferedBytes int
// buf holds the write buffer
// 缓存区
buf []byte
// bufWatermarkBytes is the number of bytes the buffer can hold before it needs
// to be flushed. It is less than len(buf) so there is space for slack writes
// to bring the writer to page alignment.
// 水位线
bufWatermarkBytes int
}
// NewPageWriter creates a new PageWriter. pageBytes is the number of bytes
// to write per page. pageOffset is the starting offset of io.Writer.
func NewPageWriter(w io.Writer, pageBytes, pageOffset int) *PageWriter {
verify.Assert(pageBytes > 0, "invalid pageBytes (%d) value, it must be greater than 0", pageBytes)
return &PageWriter{
w: w,
pageOffset: pageOffset,
pageBytes: pageBytes,
buf: make([]byte, defaultBufferBytes+pageBytes),
bufWatermarkBytes: defaultBufferBytes,
}
}
func (pw *PageWriter) Write(p []byte) (n int, err error) {
// 是否超过水位线
if len(p)+pw.bufferedBytes <= pw.bufWatermarkBytes {
// no overflow
// 没有超过,直接保存 bufferedBytes是已经使用的buffer
copy(pw.buf[pw.bufferedBytes:], p)
pw.bufferedBytes += len(p)
return len(p), nil
}
// 计算这一页中还有多少可以用的
slack := pw.pageBytes - ((pw.pageOffset + pw.bufferedBytes) % pw.pageBytes)
// 剩下的不是一个完整的页
if slack != pw.pageBytes {
// 看能不能放得下
partial := slack > len(p)
if partial {
// 放得下,但把这放进去不是一个完整的也,因为剩下的可以写的buffer比要放的数据大。
// 要是放不下,那可就在p中扣除slack长度的数字了哦,这里要和下面的copy里面一块看
slack = len(p)
}
// 写
copy(pw.buf[pw.bufferedBytes:], p[:slack])
pw.bufferedBytes += slack
n = slack
p = p[slack:]
if partial {
// 放得下就直接返回,如果在这里强行的flush,可就不是一个完整的页了。
return n, nil
}
}
// 经过上面的操作,这里肯定是一个完整的一页,直接保存
// 能走到这里,说明p中还有数据
if err = pw.Flush(); err != nil {
return n, err
}
// 剩下的数据超过了一页
if len(p) > pw.pageBytes {
// 直接整除,不通过flush保存,直接通过w来保存
pages := len(p) / pw.pageBytes
c, werr := pw.w.Write(p[:pages*pw.pageBytes])
n += c
if werr != nil {
return n, werr
}
// 此时的p就不是一个完整的一页了
p = p[pages*pw.pageBytes:]
}
// 再次调用writer直接保存
c, werr := pw.Write(p)
n += c
return n, werr
}
// Flush flushes buffered data.
func (pw *PageWriter) Flush() error {
_, err := pw.flush()
return err
}
// 通过 bufferedBytes来做下标,保存buffer,将bufferedBytes变为0,并且计算
// 一页已经使用了多少
func (pw *PageWriter) flush() (int, error) {
if pw.bufferedBytes == 0 {
return 0, nil
}
n, err := pw.w.Write(pw.buf[:pw.bufferedBytes])
pw.pageOffset = (pw.pageOffset + pw.bufferedBytes) % pw.pageBytes
pw.bufferedBytes = 0
return n, err
}
问题
-
Flush中
pw.pageOffset = (pw.pageOffset + pw.bufferedBytes) % pw.pageBytes出于什么目的?在前面的Writer方法分析指导,在Writer中调用的时候必须是一页,所以,这里的pageOffset肯定都是0,但实际使用可能会有在writer之后(Writer不满一页),在调用Flush方法,此时pageOffset就不是0了,bufferedBytes求余pageBytes不会为0,为了维持page就需要凑够一页,所以需要保存一下,如果直接置为0的话,那就不是一页了,从数据来是 128KB(一页),128KB(一页),64KB(不满一页),128KB(一页),要是这样的话 page的概念就么有了。
关于博客这件事,我是把它当做我的笔记,里面有很多的内容反映了我思考的过程,因为思维有限,不免有些内容有出入,如果有问题,欢迎指出。一同探讨。谢谢。















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









