








👉腾小云导读
业务系统复杂性一直是令开发者头痛的问题。复杂的不是增加一个需求需要耗费多少时间,而是在增加一个需求后带来的蝴蝶效应:其它功能会不会受到影响、要如何去找到这些影响,最终如何实现系统正常运行......功能之间隐秘增加的耦合、不可避免的代码腐化在导致业务复杂性增加。大家都在说的软件开发提效到底在提什么?程序员日常工作中应该如何提升开发效率?敏捷开发、瀑布流式开发孰是孰非?欢迎阅读。
👉看目录,点收藏
1 业务背景与目标
2 软件开发提效
3 业务系统复杂的根本原因
3.1 功能之间隐蔽增加的耦合
3.2 不可避免的代码腐化
4 总结
01
业务背景与目标
我依然非常清晰地记得去年的某个时候,我所在团队 Leader 曾讲过一段话:
”我担忧的是,我们团队规模的扩张并不是因为用户规模或营收规模的增长,仅仅是因为我们有越来越多的事情要做导致人手紧缺。”
这个担忧相信很多开发者都能感同身受,也许你所在的团队也正面临同样的问题:为什么用户规模或者营收规模不增加,事情反而越来越多呢?出现这个现象的原因其实也不难想到:由于业务规模停滞或者下滑,产品侧不得不做更多的事情来止住颓势甚至想要以此力挽狂澜。要么是不断地拓展产品的边界,在一个应用里加入更多的功能,也就是所谓的交付更多的用户价值,从而吸引更多潜在用户;要么是不断地优化现有功能,例如通过排版来从心理学角度提高用户停留时长和点击率,亦或是进一步优化产品的交互流程,也就是所谓的提升用户体验,从而提升口碑,稳固用户基本盘。
这些要做的事情对应到开发侧,那自然就是有更多的需求。一个需求不能提升指标,那就要两个;一个策略效果不及预期,那下次就得 A、B 两个策略同时做实验。看起来,这势必会加剧团队开发人员的压力。

大版本上线前同时赶多个需求.gif
所以 Leader 希望开发团队能够提升效率,提升需求的吞吐率。但问题是,需求的增多,就一定要伴随着开发团队人力的增多吗?
对其他行业来说,这个问题的答案是显而易见的。你要修更多的房子,势必要更多的工人;你要送更多的物资,势必需要更多的车;你要打赢一波团战,势必需要更多的队友…然而这个问题到了软件行业,答案却变得模糊了。
因为软件行业有个特有的性质——几乎 0 成本的可复用性。某项功能别人实现了,那其他人就能立刻拿过来用。这对于建筑等行业,那真的就是降维打击。即使工地要修 10 栋一模一样的宿舍楼,它也得一栋一栋地修,每一栋的人力和物力都是一样的。而对于软件行业,你只需要修一栋,剩下的 9 栋就是 0 成本的复制粘贴。
那对于一个在软件工程上有追求的团队来说,大家不是一直在追求可复用吗?前期开发了那么多需求和功能,想必也沉淀了非常多的能力吧?如果有那么多能力可以 0 成本复用,那后续是不是开发效率会大大提高?
因此对很多人来说,理想中的软件开发团队,随着功能的不断增多,开发成本应该至少保持一个线性的关系。而且如果引入了一些重大的新技术,开发成本的线性增长率还会更低。
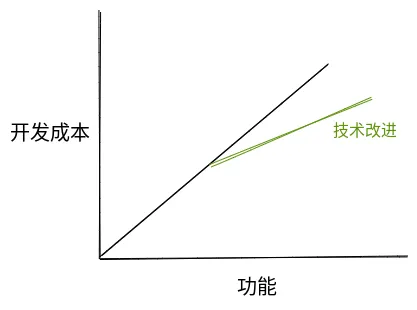
这种 functionalities-cost 的线性关系对很多团队来说是习以为常的。在很多团队的项目管理中,每次迭代的需求数量都应不少于上次迭代,否则就需要复盘。而对于开发效率的提升,则可以用本次迭代的需求数量较之前有多少比例的提升来判断。如果团队有一个好的技术架构和合理的模块划分方案,考虑到可复用性可以减少成本,functionalities-cost 的关系会更平缓。类似这样:
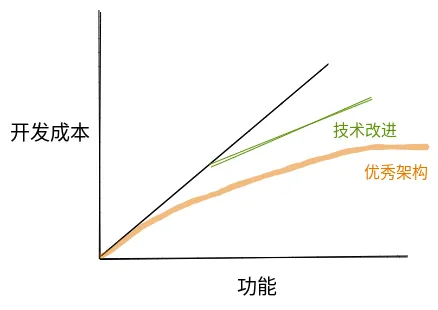
然而,现实可能会给你沉重一击。如果你去问问一线的开发人员,他们可能会告诉你真实的感受是这样的:
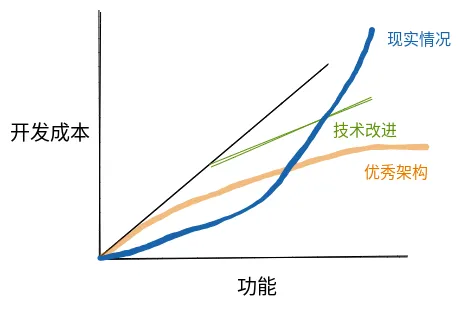
随着向系统中添加越来越多的功能,实现每个功能会变得越来越困难而不是越来越简单。复用?基本不存在的。像上图中的绿色线性关系都不太可能实现,更不必说优秀架构理想中类似于对数函数的曲线了。
过去 20 年中,软件开发行业中部分人推崇敏捷开发,其终极目标也不过是为了追求上图中的黑色线条这种线性关系——也就是现在很多团队习惯的,每个迭代完成固定数量的需求。在敏捷团队看来,你必须要付出很多额外的努力,不断地提取知识和重构,才有可能维持住这种恒定的需求吞吐率。然而现实是很多团队什么都没做,却对这种稳定的吞吐率习以为常了。到底是敏捷开发那一套是画蛇添足,还是 996 太好用了?这是一个值得深思的问题。
那到底为什么现实世界中的 functionalities-cost 曲线是一个指数型,而不是理想中的线性或者对数型呢?这其实涉及到软件模型的根本复杂性问题。在展开讲这个概念之前,我们先讲一些软件开发的现状。
02
软件开发提效
过去一年,许多的公司都在大力推动降本增效。一般降本增效理解为降本和增效两件事情,但过去一年大部分公司大部分还是降本。也许作为开发者的你,过去的一年被拉进了无数的“成本归属群”,收到了来自中台的各种账单。对中台来说,确实是降本了,不过这些降掉的本又加到了业务方头上。
所以项目组内部肯定也要做各种降本,比如更精细化地使用服务器和存储资源,投入更多精力去关注云上账单,该省的省。在需求的技术评审环节加上成本预估,让那些提极低的 ROI 需求的产品经理知难而退。上面这些手段都是降本。
更进一步地讲,就是减少不必要的浪费。这种减少浪费的降本手段在短期很有用,但很快就会达到收益天花板。更大的收益还是要提升效率,但增效相关的工作,也许你感知到的是寥寥无几。
其实说到软件开发的增效,大多数人首先想到的就是工程效能(EP),也就是开发工具。利用各种好用的工具,来提升写代码、构建服务以及协同开发的效率。例如拥有可以极速处理几百 G 大仓的代码托管平台,拥有高度可配置的流水线来自动化一些日常繁琐的构建任务,有良好设计的 RPC 开发框架,还有先进的可观测平台,还有无数其他的效能平台……
这一切的一切,最终目标或许大家也经常听到——让程序员可以专注于业务的开发。但问题是,在整个软件的开发中,到底是业务开发工作量的占比高,还是非业务开发工作量占比高?
IBM 大型机之父、图灵奖得主、软件行业圣经《人月神话》的作者 Fred P. Brooks ,在他的一篇著名的文章 《没有银弹:软件工程的本质性与附属性工作》 中提到:
把一个复杂的软件系统分成两个部分:。
|
如果你对上面提到的《没有银弹》感兴趣,可以在公众号后台回复「银弹」,领取离线PDF阅读材料。
开发软件的目的,就是要交付某项功能。那么这项功能的 Essential Complexity 就是不可避免的。即使你消除了所有的Accidental Complexity,Essence Complexity 依然存在。
所以没有银弹,No Silver Bullet。
回到上面的问题,我们可以发现:EP 和各种中台为开发者提供工具和服务,其实就是在尽量减少 Accidental Complexity。然后让大家可以专注于业务本身的开发,也就是 Essence Complexity。如果二八法则适用于大部分的现实场景,那么在软件开发中,到底 Accident Complexity 是八还是 Essence Complexity是八?如果 Essence Complexity 是八。那我们一直只在 EP 上做文章,是否有点“隔靴搔痒”?
对于这个问题,我个人很喜欢《凤凰项目》这本书中的一种思考方法:当你遇到比较复杂想不清楚的问题时,你可以假设你有一个无所不能的魔法棒,它能实现你的任何愿望。所以你不用纠结具体问题怎么解决,你可以直接想象“你期望的状态是什么”。所以,假如开发者也有这么一个魔法棒,魔法棒挥一下,公司的各种基础设施和工具立刻达到了太阳系的顶级水准,几万 PB 的大仓毫秒级克隆,用罗永浩的 TNT 口述就是能得到业界最牛的 CI Pipeline、业界最顶级的观测系统、最顶级的发布系统,全是顶级。不过然后呢?即使IT 和 EP 系统已经到了完美的程度,还是不得不面对这样一个现实:终于可以专注于开发业务了。但是业务到底怎么开发呢?
无数现实中的例子,由于业务建模的不合理、由于需求的仓促上线、由于接口设计的不合理、由于各种无谓的耦合……建立在最牛的基础设施之上的业务系统,一段时间之后又将变成一座废山。代码看得令人眩晕,改功能不知道去哪里改,不知道会影响哪些功能,不知道需要改动的点是否都被覆盖到了,改个小功能要改无数的地方……

然后,functionality-cost 曲线又变成了这样。
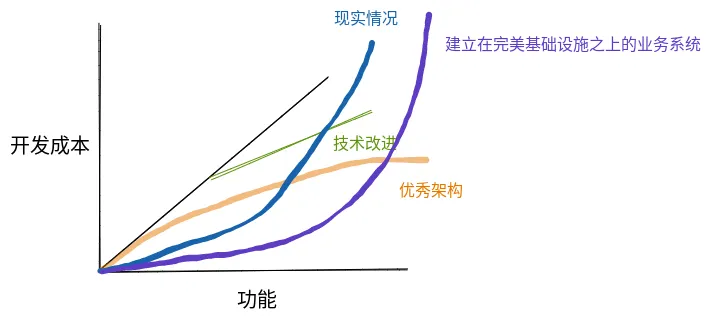
不管基础设施多么优秀,业务代码依然是废山。所以只靠工具提效是远远不够的,还需要关注业务本身,Essential Complexity。
这种想法其实大家早就该有,毕竟真正交付用户价值,帮助项目组赚钱给大家发工资、发奖金的,就是这段业务代码。只是业务类型千千万,又必须时刻根据市场反馈去变化,看起来永远是个开放命题。所以对于大部分人来说,在业务中去归纳一些 pattern,远比去做一些 scope 较为固定的工具要困难和难以落地,这可能也是很多开发者喜欢做工具或者 infra 、而不喜欢做业务的重要原因。因为业务看起来真的太缥缈了,似乎没什么可总结和沉淀的。并且,很多人会错误的估计业务系统的复杂性,总觉得做业务开发就是单纯的增删查改,没什么技术含量。
对业务复杂性的错误认知和低估,会进一步加剧废山的形成,从而让 functionality-cost 曲线变得更加陡峭。接下来我们聊聊业务系统复杂的根本原因。
03
业务系统复杂的根本原因
结合过去参与过的很多业务系统开发以及近期阅读书籍的一些思考,抛开人的原因(假设人都是理智的有追求的),个人认为导致业务系统复杂的根本原因有两个:功能之间隐秘增加的耦合、不可避免的代码腐化。
3.1 功能之间隐蔽增加的耦合
相信绝大部分开发者在项目一开始的时候,都有一颗“整洁架构”的心,都希望把代码写好。尤其是项目一开始,需求做的飞快,每天几千行代码也不在话下。大家会关注函数的颗粒度,会关注模块的划分和职责是否单一,也会关注单元测试情况和代码的可测性。即使这样,随着时间推移,大家还是会发现代码改起来越来越痛苦——总会牵一发而动全身,或者明明是修改功能 A,却不得不关注功能B是否受影响。这是为什么呢?
答案就是——耦合。很多人一说到耦合,就会心生厌恶。确实,很多时候不合理的耦合是万恶之源。但是耦合又是不可避免的。因为 Essential Complexity的存在。如果某个功能本来就需要多个模块共同参与,不论你怎么分解这些模块,只有把它们“集成”到一起,才能实现有意义的功能。把它们集成到一起,A 依赖于 B、B 又依赖 C、C 又会反馈给 A,这不就是耦合吗?
软件工程中有句话每个人都烂熟于心:高内聚,低耦合。但很多人只记住了后面三个字:低耦合,却忘记了前面的三个字:高内聚。
在高内聚的边界内,各个模块是不是就是强耦合的呢?即使你认真的进行架构设计去拆分模块,这种耦合也是难以避免的。下面我们举两个例子。
某团队开发了一个社区类应用。社区应用大家应该也用过不少,大体架构是差不多的,一般都会包含如下业务模块:
资讯:可以简单理解为 feeds 流,主要以左文右图的方式来展示。
社区:用户开放交流的地方,可以类比于新浪微博或者 twitter,用户可以发带图片的内容。
评论区:资讯、动态都可以发评论。
……
上述这几个模块都是比较独立的业务,产品形态也有差异,因此一般都会由不同的小 Team 来负责。
有一天,产品经理希望做一个新功能,叫作“名片系统”。简单来说就是,它允许用户自定义自己头像后展示哪些名片或者标签(可以有多个),以突显身份特征,例如:
这个需求其实初看起来没有多复杂,闭上眼睛琢磨大概就能想到。首先需要做一个配置页面让用户选择要展示的标签并保存起来,同时需要在 App 中各种需要展示头像的位置去读取用户的相关配置,来让客户端进行展示。看起来不难对吧?
但是再深入想一想,你就会发现其实并没有想象的那么简单。如果没有意识到由 Essential Complexity 引入的耦合,开发者很可能在排期的时候少估算了天数,最后不得不需要用各种“责任感”、“Ownership”这种精神力量通过加班来尽量保证不 delay。下面我们来看看为什么。
首先配置页面需要从不同的系统去获取用户拥有的标签。例如用户勋章,需要从成就系统去获取“连续签到 30 天”,“连续创作一周”之类的成就,会员信息需要从会员系统获取,主要就是用户会员的 VIP 等级。个人/企业认证,类似于微博的黄 V 和蓝 V,需要从认证系统去获取。
这里的重点不是要去不同的系统查数据麻烦,重点是这里引入了新的耦合。这些原本设计之初毫不相关的概念,被这个需求关联在一起了。这种后来的再建立关联关系,任谁在系统设计之初也不可能在架构层面去设计。并且,考虑到产品功能的完整性,这会带来一个问题,就是这个需求会变得很长尾。
后续如果一个负责资讯板块的产品经理想要增强平台优质内容的丰富度,要做一个签约作者的体系。这时开发者除了要让推荐系统对该签约作者发的内容在推荐流量上做些倾斜调整,还不能忘了要到和那个需求「基本没啥关系」的名片系统上来做些修改,从而让这部分用户能对外展示自己是“签约作者”的标签。
后续只要是和身份相关的内容,都会和这个功能耦合。当然,也许有人会说:“其实也可以不全支持,又不是不能用。”

周五傍晚产品经理找你改需求.gif
但是这就会带来负向的用户体验,进一步引发的负面舆论处理不及时,很可能这个需求的收益反而不如它带来的负面影响。
除了上述配置端,展示端其实也被耦合了。原本资讯的 feed 流、社区的动态列表、评论区以及资讯详情页的作者头像展示部分的样式都是不一样的。有的只展示一个名字,有的展示名字加头像,有的还要展示个人简介等等。
但现在它们都要额外考虑名片的展示,问题是有的场景位置不够,放不下那么多标签怎么办?哪个标签更重要?有没有权重?到底是名片系统统一来处理每个场景展示什么标签,还是各自场景自行决定?这也是个两难的选择。如果分发逻辑做在名片系统,那每增加一个露出场景,名片系统也要跟着改。如果是不同场景各自负责,那它们除了实现自己的逻辑,还不能忘了名片系统。但不论怎么选,这里也引入了强耦合。
并且即使这次梳理完了所有的现有场景,开发者把所有的位置都改一遍,这就完了吗?显然没有,它是一个长尾的需求。后续只要是某个需求涉及到展示用户头像,是不是就需要考虑名片?万一这个需求开发者之前没参与过名片需求的开发怎么办,他怎么知道要考虑名片?免不了上线后又是一通紧急 bug fix…很多开发者怕的不是这个功能本身有多复杂,怕的就是不知道改了这里会影响其他什么地方,或者别的地方也需要一起改。

bug.gif
我们可以看到,当系统变得复杂,功能之间会逐渐产生耦合,它们的关联关系也会变得复杂。这些无意间引入的耦合,会给后续所有的需求开发增加一些额外的负担。
所以,当你在做新需求时,还必须考虑它和一些旧的特性怎么结合。当系统的功能不断膨胀,这些额外负担会不断增加,想让每个迭代的需求吞吐率还能保持恒定简直是痴人说梦,更别说想象中的需求交付速度越来越快了。
再举个例子。做App肯定都希望看到用户的裂变增长,引流就是一件非常重要的事情,尤其是从微信这个巨大的流量池引流。我们想把App上部分优质的内容分享到微信,这样就能在微信中裂变传播,吸引更多的用户来下载和安装。这个非常合理的需求,其实也引入了业务上的强耦合。
大部分手机App都是用原生的方式开发,例如 IOS 用 Swift/OC、Android用 Java/KT。但微信中只能分享 H5 的 Web 页面。这就意味着同样一个需求,除了要用原生做一遍,还需要用 H5 再做一遍。不仅如此,由于分享到微信的H5 页面,用户打开后肯定都是没有登录态,因此还需要让 H5 依赖的后台接口支持无登录态调用。
实际上,这没那么好支持。有些接口逻辑强依赖于用户登录态怎么办?例如查看资讯详情的接口,接口内部除了要返回资讯内容,还要记录用户的浏览记录,还需要给资讯的浏览量+1。如果你没有关注资讯的作者,可能头像旁边要展示一个关注按钮……这些都需要依赖于用户的登录态才能完成。因此在没有登录态的情况下,就必须阉割一部分现有功能。
那要怎么阉割呢?在原接口中各种 if else?太 bad taste 了,不仅代码乱成一锅粥,统一的鉴权网关也很难处理。最好就是新开接口专门处理来自 H5 的调用,把它当成另一个独立的需求,而不是强行和之前的接口逻辑写在一起。但这还不够,还有很多问题,例如像文章浏览量这种数据怎么处理?没有登录态,就没法对浏览量进行去重。如果每次请求都累加,就会被灰产利用来刷数据。如果不累加,似乎对作者又不太公平?这可能会导致产品侧需要同时记录有效浏览量和无登录态浏览量,这又是一个新需求了。

尝试调整一些逻辑.gif
此后,如果一个功能页要支持分享到微信,客户端要做一版完整的双端接口,H5 要做一版简化的。后台要给客户端提供一套接口,还要给 H5 提供一套无登录态的定制版接口。就这样一个分享到微信的功能,它又变成了长尾的需求,还让后续所有的开发者工作量乘以 2 。
这些是技术架构不合理或者代码写得不好导致的吗?显然不是,这就是随着产品功能不断叠加,各种 Essential Complexity 带来的天然耦合导致的。到项目后期,每新增一个变更,除了修改这个变更本身,可能还要修改和它耦合的n+1 个位置。而且没有办法通过软件上的优化来消除这种复杂性,因为复杂性是不灭的。工程上的任何架构或者设计模式的引入,只会把复杂性从一个位置转移到另一个位置,但永远不会消失,No Silver Bullet。
3.2 不可避免的代码腐化
除了业务本身的耦合带来的复杂性,代码腐化也是另一个让业务系统变得复杂的重要原因。
相信大部分开发者都经历过这样的心路路程:
| 项目刚开始时雄心勃勃:维护前人的废山是无奈,从零开始,要让大家看看什么才是整洁架构的时代! 开发过程中:时间都是倒排,CR别人的代码就是 5 秒后在企微回复一个 d。需求改来改去,业务逻辑扭扭曲曲,辛苦写好的单测又失效了,算了不装了,为什么跟自己过不去呢? 后期:呐,搞出废山大家都不想的咯,这次不算,下次一定,我煮碗面给你吃 |
尝试CR别人的代码.gif
作者自己就是一个很典型的例子。大学毕业刚工作时,我负责维护了一个非常夸张的项目,没有任何文档,一个 PHP 文件几万行、一个函数上千行、一个接口能返回几种完全不同的 JSON 作为 response。每天还有几十号人在疯狂 push代码。仓库不断膨胀,每次修改个功能,心中都是一万个不情愿,一不小心就会出现线上事故,至今我对 PHP 等没有类型的语言开发项目还心有余悸。
后来有个机会从零开始负责一个公司重量级的运营系统的开发,内心非常的激动。终于可以按照自己工作之余看书学到的最佳实践方法来构建项目了,这下要让所有人刮目相看。开发过程中,也是恪尽职守,每天晚饭后都花至少1个小时拉着团队另外几个开发人员做 Code Review,经常还争执得面红耳赤,对 Bad Taste 坚决抵制。
项目整体推进得很顺利,上线后取得了很大的成功,只是后来由于组织架构变动,去了另一个团队,不再负责那个项目了。不过本人一直觉得,自己给接盘方打下了一个非常好的基础,对方一定会感谢自己……直到一年后的某天,和一个同事无意间聊起来,他们就负责了我之前的那个项目(他不知道我之前负责那个项目)。本以为能从他那得到些正向的评价,结果全是吐槽,诸如代码看不懂、风格奇葩、扩展困难等等。最后补了一句,后来实在受不了,他们重写了。
这就是发生在作者身上的真实故事,一个满腔热血,熟读《整洁架构》《重构》《设计模式》《领域驱动》 《演进式架构》的人,从零开始开发系统,却依然避免不了旧代码走向腐化,成了后人口中的废山始作俑者。

偶然间看见自己多年前写的代码.gif
到底代码是如何腐化的?这是一个非常大的话题,这里就不展开了,因为上述提到的书中几乎都是讲这些 Bad Taste 和相应的应对之道的,作者也没有能力和自信能比它们讲得更清楚。因此,本文只讲为什么我觉得这种腐化是不可避免的。
核心原因:架构设计和模块抽象只能面向当下,它天然是短视的或者说是有局限性的。这种局限性即使是最优秀的架构师也是无法逾越的。
说到这个问题,先讲两个常见的开发模式。大家可能听过,现在更提倡敏捷开发而不是瀑布流式的开发。但到底什么是敏捷,什么是瀑布流呢?
瀑布流式开发
瀑布流就是上个世纪比较传统的开发模式。甲方提需求,我要做一个什么样的软件,它要包含哪些功能 。软件公司作为乙方,来承接甲方的需求。它首先需要有人去调研甲方的需求,具象化每个功能点,然后形成最终的需求文档和性能要求文档。当甲方对需求认可并签字后,就进入了架构师的设计阶段。这个阶段架构师能够看到所有的需求,他拥有全局的视角,然后进行架构设计、方案设计和模块的拆分。最后根据架构师的设计,开发部门就分模块进行开发。开发完成之后进入测试阶段,测试完成后再交给甲方去验收,验收通过就正式交付。
这就是瀑布流式的开发。必须前一步做完再交给下一步,就像瀑布一样顺流而下。这种开发方式现在看来是不好的,因为这种开发方式周期很长,动辄就是以6 个月甚至 1 年起步,很多大项目甚至要 3 年以上。但商场如战场,形势瞬息万变,等你做出来,黄花菜都凉了,再好的软件又有什么用呢?
很多软件工程的书上都讲过“项目失败”的案例,大多就是这种用瀑布流开发方式开发的项目,由于开发周期太长,预算严重超支,或者还没做完就发现市场已经不需要了,或者还没做完发现技术方案已经过时了等等。并且,瀑布流式开发实际上在后期有非常多的问题。大家现在开发完一个小需求之后多方一起联调都觉得痛苦,你能想象某个大型项目,等所有的功能开发完再去测试会有多少问题吗!即使好不容易处理完项目本身的问题,甲方验收时还有更大的麻烦:“当初说的做 XXX,但是你们做出来是 YYY,根本不是我要的,不满足需求”。这又会涉及大量的返工,进一步让项目延期。
因为瀑布流这种开发方式太过于笨重,无法适应现代软件交付速度的预期,中间有大量的人力空转和内耗,所以后来一群大佬在一起做了一个“敏捷宣言”,提倡敏捷开发流程。敏捷开发其实就是对瀑布流式开发做出了修改,之前是收集好所有需求,再来做整体设计,再来开发,最后测试。任何一个环节出问题,都会导致后续环节出问题。比如需求没整理对,那后续所有工作都白搭。架构没设计好,开发就会很痛苦。开发的代码难以测试,那测试进展就非常缓慢。
敏捷开发
敏捷开发的解决方法就是小步快跑。先做最重要的部分。如果要造汽车,我先做发动机和4个轮子,只在驾驶员那绑个凳子,让它能够先跑起来。等跑起来了,再去逐步完善其它地方。我先做个后视镜,如果没人关心那就这样了,不继续投入了。我再试下给车加个挡风玻璃。如果市场反应非常好,那就加大投入继续优化,除了前挡,四周上下都给围上。我再试下多加几个凳子,市场反应炸裂,那就加大投入,把凳子换成沙发......
这就是敏捷开发。小步快跑,在迭代中识别出更重要的需求,这样才能快速响应市场的变化。
但这里需要纠正很多人对敏捷开发的一个误区。听到敏捷开发,大家总以为这种方式能提高开发效率和开发速度。其实不对。从上面的例子你应该可以看明白,敏捷交付的是半成品,它的解决方案就是不要一口吃个大胖子。小步快跑,做一点交付一点。
如果从完成品的角度来讲,敏捷并不会提高交付速度,甚至它会更慢。你可以很直接地看到,这种开发方式缺失了对整体目标的把控,设计上天然有欠考虑的地方,后期要改就得花更多的成本。
但是敏捷的优势在于,它能够快速捕捉市场机会,让自己活下来,活下来才有机会谈成本,再找到性价比高的地方去优化。
很多人曾经都在想,自己团队能否尝试一下敏捷开发?其实,现在不就已经是了吗?虽然在流程上和国外提倡的敏捷开发存在较大差异,可以称之为“中华田园敏捷开发”,但确实也是敏捷开发。现在互联网公司基本上都是快节奏的发布,做App 都是先发 MVP 版本,然后再持续优化。每个迭代,产品经理都是只提几个有限的需求,开发也只开发这几个需求就上线。然后就进入不断堆功能的小步快跑阶段,缝缝补补又一年。产品经理也会用各种方式尝试去识别功能的收益,埋点、报表、同比环比等等。
聊了这么多关于瀑布流式开发和敏捷开发,这和代码不可避免的腐化有什么关系呢?
其实当大家知道现在这种“中华田园式敏捷开发”后,马上就能意识到,每次大家在做技术方案设计时,能拿到的信息仅仅是宏大视图中的小小一角,根本没有全貌,并不能像瀑布流开发那样拿到产品的整体视图。仅仅凭借这一点点信息,再牛的架构师设计出来的方案也是有局限性的,这也是为什么前面说架构设计和模块抽象只能面向当下,它天然是短视的。这不是人的问题,这是开发方式的问题。当然,现实情况是,这种局部的需求,很多人也没有去做设计。拿到需求,直接从 controller 开始写代码解析入参,然后 service 组合一下RPC 和 DB 调用,DAO 再实现几个数据库查询就可以了。根据作者的经验,这种情况甚至能占到 80%以上。在一个项目中只有少量的局部架构设计+这些架构设计还不一定合理+80%以上任何设计都没有+有上千种让代码难以阅读的编码方式,如果说代码不腐化,你信吗?
这里再举个例子。
有个后台管理系统需要做权限管理功能,所以开发者基于业界常见的 RBAC 模型开发了一个权限管理模块。在做方案设计时,大家一直比较关注可复用性,因为后续可能有别的系统也需要权限管理。
其实办法也很简单,在模型中加入了租户的概念( appid ),所有的 Role 表和 Access 表都带上 appid 字段。这样,不同业务就可以自定义自己的 Role 和 Access 而不干扰其它的业务。这个设计按理说也还可以,只要是基于 RBAC 模型的权限管理,后续分配几个 appid就可以用了。
然而,两周后的一个需求直接就来打脸了。这个需求也要做权限管理,它表面上看也是基于 RBAC 模型的,但是有细微的区别。简单说,这个需求类似于游戏里的帮派管理,帮主有所有权限。他还能够设置任意多个管理组,比如副帮主、长老、堂主等;管理组成员可以管理帮派成员。管理组之间也有权重,权重高的管理组可以管理权重低的管理组,比如副帮主可以管理所有长老和堂主,长老可以管理所有堂主。
看起来依然是基于 RBAC 模型,不同管理组就是不同 Role 。但是这里最大的区别就是,原始的 RBAC、Role 之间是互相无感知的,不同 Role 不需要知道别的 Role 的存在,它只需要知道它有哪些 Access。但是对于这个需求,Role 之间需要建立关系,有优先级,高级的 Role 可以管理低级的 Role。
这种 Role 之间的关联关系,在一开始设计 RBAC 模块时是没想到的,所以大家当时的设计只能应对当时的需求,扩展性也只是多租户,而对于新的需要修改模型的功能就无能为力了。这也是为什么说在“中华田园敏捷开发”中,架构设计总是短视的。

功能先上了再说.gif
后来大家进行了一个小复盘,为什么设计的通用权限管理第一个需求,就没法复用?大家为后台管理设计的模型,谁能想到产品要做帮派管理。虽然扩展性设计只考虑多租户也确实过于简单了,但是如果考虑更多扩展性,工时是不是也会增加呢,会不会又有过度设计的嫌疑呢?……后来,那个业务又只能重新开发一套了,当然里面还包含很多其它性能优化。因为它们的请求量比较大,各种数据要缓存到 Redis。而一开始的面向后台管理系统的 RBAC,一天也没几个人用,每次都直接读 mysql。
这样的例子其实还有很多,就不一一列举了。大家也可以想想自己项目中的通用 XXX 系统,看看到底通不通用。很多时候看似类似的需求,其 Essential Complexity 是很不一样的,对应的软件建模也是有区别的。盲目地追求复用,在函数后不断地加参数,可能适得其反。
说到复用,开源界在国外有两个比较形象的说法:Free as Beer、Free as Puppy。
有些“可复用的能力”是像啤酒一样免费的 Free as Beer,拿来就喝不给钱。
还有些“可复用的能力”是像小狗一样免费。虽然你免费获得了一只可爱的小狗,在收获短暂的快乐后,你需要各种铲屎、各种照护。到底快乐多还是负担多,就看你是不是爱狗人士了。
那些在设计之初就没有经过精心考虑的“通用系统”,对于用户来说就是 Free as Puppy。要用只得捏着鼻子用,后续要改动加功能还很困难。其实也不复杂,不如…...造个轮子吧——Yet Another Shit Comes!
当然也不是所有的系统都是短视的。业界也有很多 Free as Beer 的系统。这些系统大多都是面向特定的场景,例如 ERP、CRM,以及云上各种 Saas Paas。要注意的是,它们都是面向特定场景的产品,有明确的边界。只有这样它们才能在内部进行充分的建模,从而构建出符合特定场景的通用产品。
因此建议各位开发者在想着做“通用”的时候,先想想自己的“通用”指什么、边界在哪里。一般来说,你要做的东西业界或者公司都有同类产品,你为什么不用?那些你不愿意用的产品,它其实也是想做通用的,但是你有没有想过为什么它没有达到目的呢?你去做的话,你有自信可以让你的东西 Free as Beer 吗?请想清楚了再动手。
通过上面的例子,我们可以看到,腐化除了来自开发者低质量的代码,更核心的是来自于系统架构的腐化。而在“中华田园敏捷开发”的这种开发方式下,需求本身就是零散的,目标也是模糊的。在没有全局视图的情况下,架构自然就是有局限的,只能适应当下。而随着项目的发展,只能适应当下的架构就会失效。
如果意识不到这个问题,后续在这种失效的架构上进行任何修修补补和魔改可能都会进一步加剧它的腐化,导致代码更难以看懂。
04
总结
由于 Essential Complexity 的存在,No Silver Bullet。为了快速响应市场的“中国田园敏捷开发”的开发方式,带来不可避免的代码腐化。难道这就是程序员的黑暗森林吗?
其实程序员并不害怕 Essential Complexity。只要状态好,日敲千行代码不在话下。程序员最害怕的还是代码腐化。很多设计上的决策和代码为什么要这么写,是内隐的( Tacit Knowledge ),它只存在于最开始的开发者脑中,随着那个人的遗忘或者离开,这些内隐知识将永久丢失。所以通过文档沉淀内隐知识对于项目是非常重要的。道理各位开发者都懂,但谁又愿意费劲写文档呢?
因此,代码腐化+文档缺失,会极大地增加后续的开发者认知负担,使得某些功能的流程难以辨认,不知道从何下手。应对方法也很直接,要做的就是代码防腐以及知识沉淀,但这些恰好又是很多人嫌麻烦又不愿做的地方。毕竟人都是自私的,谁愿意干前人栽树后人乘凉的事呢,多堆点需求帮业务挣钱拿个五星去晋升不香吗,我为啥要防腐为啥要写文档?
并且,做代码防腐通过事前做一点 EPC 是远远不够的,它只能提升代码质量的一点点下限。结构性的腐化,只能靠重构。而重构说白了,就是事后诸葛亮。
当你拥有了更多的信息后再回过头来看当时设计的局限性,然后再来对之前的设计进行归纳总结,该分离的分离,该提取公因式的就提取公因式。根据近期的经验再预测未来产品的发展方向,再去刻意设计一些灵活性。

大神重构代码.gif
但重构的收益到底是什么?重构完能带来多少需求吞吐率的提升,能给出数据吗?讲不出收益,怎么和产品去 battle 和管理层要时间呢?
代码腐化就是技术债务,但是债务不总是有害的。也许历来每年贷款在北京、上海、深圳投资房产的人,甚至会后悔杠杆没拉满。所以技术债务也不是什么洪水猛兽,它甚至是时代的红利。但是债务总要还。例如现在大家想还房贷都还不了还要排队。那到底什么时候适合偿还技术债务,偿还多少合适,具体怎么还呢?
文档总是过时的。写的信息量太少没人看,想看的部分没人写,改了代码还要同步改文档容易忘记怎么办?写文档太费事怎么办?如果你感兴趣,欢迎留言评论,我们会继续推出关于业务复杂性的下篇。
以上是本次分享全部内容,欢迎大家在评论区分享交流。
如果觉得内容有用,欢迎转发~在公众号后台回复「银弹」,领取Fred P. Brooks (IBM 大型机之父、图灵奖得主)所著 《没有银弹:软件工程的本质性与附属性工作》。
-End-
原创作者|刘德恩
技术责编|刘德恩















 3607
3607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









