







Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
在Pandas中,主要的数据结构是Series(一维数据)和DataFrame(二维数据):
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
目录
1. Pandas安装
与Numpy一样,Pandas可以使用pip或conda进行安装,如果已经安装了anaconda集成开发环境,其中自带numpy与pandas,无需再次安装。
1.1 使用pip安装Pandas
pip install pandas成功安装后,便可通过导入pandas包进行使用:
import pandas as pd1.2 测试示例
import numpy as np
import pandas as pd
s = pd.Series([1,2,3,4,np.nan,6,8])
s
2. Series数据结构
2.1 Serise介绍
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
2.2 series 创建示例
1. 创建一个普通示例,并设置索引值:
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
s
输出结果:
100 a 101 b 102 c 103 d dtype: object
根据索引取出其中元素:
print(s[102])输出结果:
c
2. 使用 key/value 对象,类似字典来创建 Series:
data = {
'user1':100,
'user2':200,
'user3':250,
}
s = pd.Series(data)
s输出结果:

3. 标量创建Series:
s = pd.Series([1,2,3,4,5,6],index=['a','b','c','d','e','f'])
print(s)输出结果:

2.3 Series数据提取(索引)
在Series数据结构中,对于数据的提取,可以采用数组下标索引的方式,也可以采用index参数设置的方式对其元素进行提取。
s = pd.Series([1,2,3,4,5,6],index=['a','b','c','d','e','f'])
s
通过如下索引方式:
s[0]
s[0:3]
s[-3:]#取出最后三个
s['a']
s[['a','c','f']]输出结果为
1
a 1
b 2
c 3
dtype: int64
d 4
e 5
f 6
dtype: int64
1
a 1
c 3
f 6
dtype: int643. DataFrame
3.1 DataFrame介绍
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
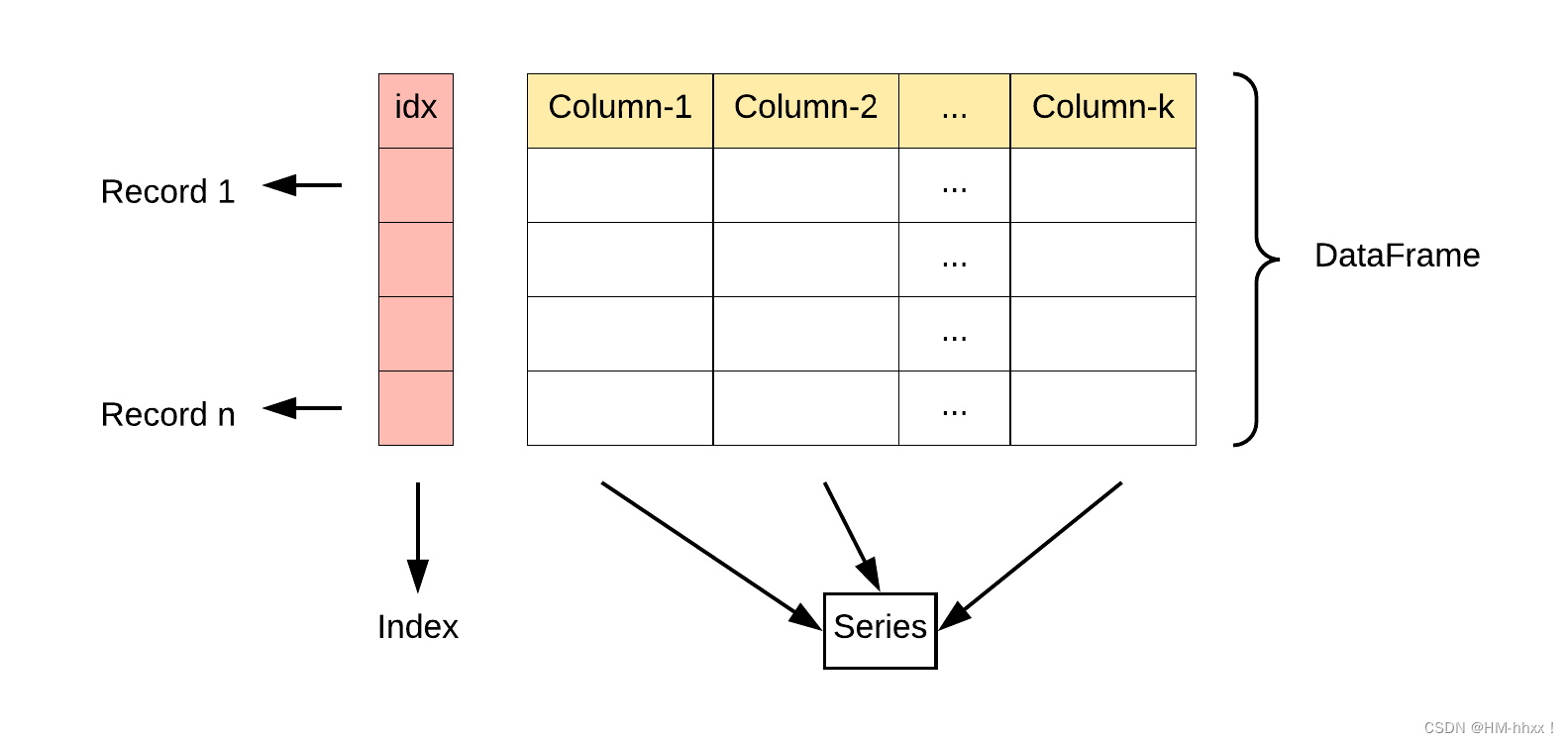
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
3.2 DataFrame创建示例
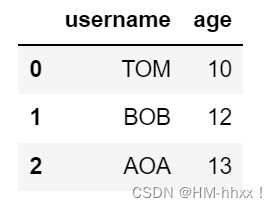
1. 基础表格创建
import pandas as pd
import numpy as np
df = pd.DataFrame()
#2列数据,1列写名字,2列写年龄
data = [['TOM',10],['BOB',12],['AOA',13]]
df = pd.DataFrame(data,columns=['username','age'])输出结果:
2. 使用字典创建
#字典创建dataframe
data = {
"username":['小黑','小白','小刘'],
'income':[1000,2000,3000]
}
df = pd.DataFrame(data,index=[1,2,3])
df输出结果:

3. 使用Series方式创建
d = {
'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3,4],index=['a','b','c','d'])
}
df = pd.DataFrame(d)
df输出结果:
空数据会使用NaN进行填充占位。

3.3 DataFrame数据提取(索引)
如上案例中,要获取第一列数据,可以使用df['one']对其进行获取:

除此之外,还可以使用loc()、iloc()及属性的方式索引数据。
3.4 DataFrame数据操作
3.4.1 添加列数据
在DataFrame中,可以直接使用DataFrame['columns'] = data进行添加:
df['three'] = pd.Series([4,5,6],index=['a','b','c'])
df['four'] = df['one']+df['three']
print(df)
3.4.2 列数据删除
对于整列数据删除,可以使用del或dataframe.pop方式:
del df['four']
df.pop('two')输出结果:

3.4.3 数据追加
dataframe中,可以使用dataframe.append进行数据追加:
d = {
'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([1,2,3,4],index=['a','b','c','d'])
}
df = pd.DataFrame(d)
df2 = pd.DataFrame([[14,15],[15,16]],columns=['one','two'],index=['e','f'])
df = df.append(df2)
print(df)输出结果:

3.4.4 索引删除数据
dataframe中,可以使用dataframe.drop(index)进行数据删除:
例如删除上述数据中以d为索引的行数据:
# 删除以d为索引的数据
df.drop("d")输出结果:
















 3048
3048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











